Recognition: 2 theorem links
· Lean TheoremLow-Cost Detection of Degraded Voice Clones via Source-Output Acoustic Consistency
Pith reviewed 2026-05-12 01:54 UTC · model grok-4.3
The pith
Simple source-output acoustic consistency measures detect degraded voice clones at 77 to 85 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
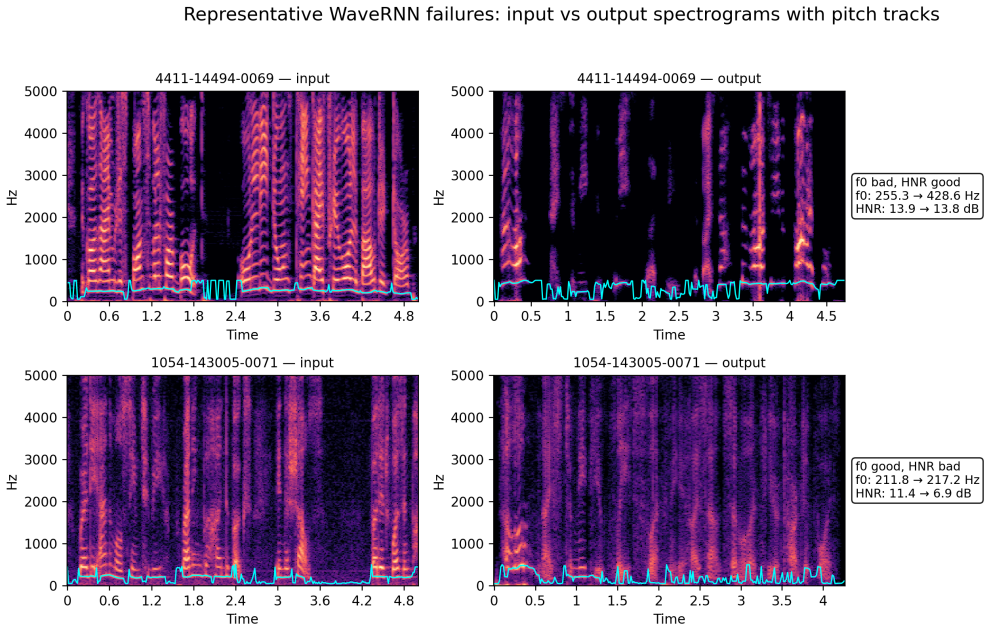
Motivated by source-filter models of speech, simple consistency checks on median fundamental frequency and harmonics-to-noise ratio between source and cloned speech identify human-labeled degraded outputs from WaveRNN at 85.2 percent accuracy and from HiFi-GAN at 80 percent accuracy through asymmetric thresholding in feature space, outperforming vocal tract length and capturing non-overlapping failure patterns.
What carries the argument
Asymmetric thresholding applied to input-output differences in median fundamental frequency (f0), vocal tract length (VTL), and harmonics-to-noise ratio (HNR) as lightweight, interpretable acoustic consistency measures.
If this is right
- f0 and HNR measures can serve as a lightweight first-pass filter to reject failed voice clones before they reach users in time-sensitive applications.
- The two measures detect partly distinct failure patterns, so they are not redundant.
- Threshold-based screening works across the tested vocoders without requiring model retraining.
- Vocal tract length consistency is less effective than f0 or HNR for this task.
- Interpretable acoustic screens support quick decisions in settings that must avoid degraded synthetic speech.
Where Pith is reading between the lines
- Combining f0 and HNR thresholds could cover more failure modes than either measure alone.
- The approach may reduce reliance on heavier machine-learning detectors in voice-synthesis pipelines.
- Similar consistency checks could apply to other interactive speech systems where source fidelity matters.
- Real-world clinical logs would provide a direct test of whether the reported accuracies hold outside the two-vocoder lab samples.
Load-bearing premise
That human-labeled degraded samples from only two vocoders capture the main failure modes that appear in real clinical use and that the chosen features keep their accuracy without retuning thresholds for new systems.
What would settle it
A test set from a third vocoder or from actual clinical recordings that contains many perceptually degraded clones yet passes the f0 and HNR thresholds at rates well above the reported false-negative levels.
Figures


read the original abstract
Recent advances in generative speech have increased the need for automatic detection of obviously failed synthetic outputs. This is particularly important in clinical settings such as AVATAR therapy, in which schizophrenia patients engage with a computer-generated representation of their hallucinated voices and degraded synthesis may disrupt immersion and therapeutic engagement. We investigate whether low-dimensional, interpretable source-output acoustic features can provide a lightweight first-pass detector of degraded voice-cloning outputs. Motivated by source-filter models of speech, we first test median fundamental frequency (f0) as a source-related consistency measure, and compare it with vocal tract length (VTL) as a filter-related measure and Harmonics-to-Noise Ratio (HNR) as a noise-related descriptor. Human-labeled voice-cloning samples generated with two vocoder families, WaveRNN (n=54) and HiFi-GAN (n=40), were evaluated using an asymmetric thresholding procedure in the input-output feature space. For WaveRNN, f0 and HNR both achieved 85.2% accuracy, outperforming VTL (64.8%). For HiFi-GAN, HNR achieved 80.0% accuracy, followed by f0 at 77.5% and VTL at 67.5%. Sample-level overlap and spectrographic inspection showed that f0 and HNR capture partly distinct failure patterns, rather than providing redundant rankings of the same samples. These results show that simple source-output acoustic consistency measures can provide useful first-pass detection of degraded voice clones, and support the use of interpretable threshold-based screening in applications where failed synthetic speech must be rejected quickly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using low-dimensional source-output acoustic consistency measures—median fundamental frequency (f0), vocal tract length (VTL), and harmonics-to-noise ratio (HNR)—as an interpretable first-pass detector for degraded voice clones. Motivated by source-filter models, it evaluates asymmetric input-output thresholding on human-labeled samples from two vocoders (WaveRNN, n=54; HiFi-GAN, n=40), reporting accuracies of 85.2% (f0 and HNR) for WaveRNN and 80% (HNR) for HiFi-GAN, with f0 and HNR shown to capture partly distinct failure patterns via overlap analysis and spectrographic inspection. The work targets clinical use cases such as AVATAR therapy where quick rejection of poor synthetic speech is needed.
Significance. If the results hold under broader validation, the approach offers a lightweight, transparent alternative to black-box detectors for screening failed voice clones, leveraging interpretable features grounded in speech production models. The concrete accuracies on labeled sets and the demonstration that f0 and HNR provide complementary information are positive aspects that could support rapid deployment in constrained clinical environments. However, the modest sample sizes and restriction to two vocoders limit the assessed significance for real-world generalization.
major comments (3)
- [Abstract] Abstract: The reported accuracies (85.2% for WaveRNN, 80% for HiFi-GAN) rest on small human-labeled sets (n=54, n=40) with no cross-validation, bootstrap confidence intervals, or threshold sensitivity analysis; this directly affects the reliability of the 'useful first-pass detection' claim given the free parameters in the asymmetric thresholds.
- [Abstract] Abstract: Labeling criteria for 'degraded' samples and the exact procedure for determining asymmetric thresholds on f0, VTL, and HNR (including whether tuning occurred on held-out data) are not specified; without these, it is unclear whether the method requires per-vocoder retuning or overfits the tested failure modes.
- [Abstract] Abstract: No evaluation is performed on actual AVATAR-therapy audio or synthesis pipelines beyond WaveRNN and HiFi-GAN; this is load-bearing for the clinical applicability claim, as the motivating deployment failure modes may differ from those in the reported samples.
minor comments (2)
- [Abstract] The abstract references 'sample-level overlap' between f0 and HNR but provides no numerical quantification (e.g., percentage of samples where both flag degradation); adding this would clarify the distinct-patterns claim.
- Consider including a summary table of per-feature accuracies, true-positive rates, and threshold values to improve readability of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our work on interpretable detection of degraded voice clones. We address each major point below, providing clarifications from the manuscript where possible and indicating revisions to improve transparency and address concerns about statistical robustness and applicability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported accuracies (85.2% for WaveRNN, 80% for HiFi-GAN) rest on small human-labeled sets (n=54, n=40) with no cross-validation, bootstrap confidence intervals, or threshold sensitivity analysis; this directly affects the reliability of the 'useful first-pass detection' claim given the free parameters in the asymmetric thresholds.
Authors: The modest sample sizes reflect the practical constraints of obtaining human-labeled degraded samples, as noted in the referee's significance assessment. We agree that the absence of bootstrap confidence intervals and threshold sensitivity analysis limits the strength of the reliability claims. In the revised manuscript, we will add bootstrap-derived confidence intervals for the reported accuracies and include a sensitivity analysis demonstrating how performance varies across reasonable threshold choices. Cross-validation is inherently limited by the small n and the nature of the labeled data, but these additions will better quantify uncertainty around the 80-85% accuracy figures. revision: yes
-
Referee: [Abstract] Abstract: Labeling criteria for 'degraded' samples and the exact procedure for determining asymmetric thresholds on f0, VTL, and HNR (including whether tuning occurred on held-out data) are not specified; without these, it is unclear whether the method requires per-vocoder retuning or overfits the tested failure modes.
Authors: We acknowledge that the abstract does not detail these elements, which affects reproducibility. The full manuscript describes the labeling as human identification of perceptually obvious degradations (e.g., pitch jumps, excessive noise, or timbre artifacts), but we agree more explicit criteria and the precise asymmetric threshold derivation process should be stated. Thresholds were chosen from the observed input-output difference distributions on the labeled samples to favor high specificity for rejection, without separate held-out tuning. In revision, we will expand the methods section with the exact labeling protocol, threshold selection rationale, and discussion of potential per-vocoder adaptation to mitigate concerns about overfitting to the tested vocoders. revision: yes
-
Referee: [Abstract] Abstract: No evaluation is performed on actual AVATAR-therapy audio or synthesis pipelines beyond WaveRNN and HiFi-GAN; this is load-bearing for the clinical applicability claim, as the motivating deployment failure modes may differ from those in the reported samples.
Authors: We concur that testing on real AVATAR-therapy pipelines would provide more direct evidence for the motivating clinical scenario. The present study deliberately uses controlled outputs from two established vocoders to isolate source-output consistency effects on documented failure modes. Access to proprietary clinical synthesis systems and patient audio raises ethical and logistical barriers that prevented such evaluation here. In the revised discussion, we will explicitly frame this as a limitation, emphasize the proof-of-concept nature of the results, and outline requirements for future clinical validation while retaining the claim that the approach offers a lightweight screening option grounded in source-filter principles. revision: partial
Circularity Check
No circularity: empirical threshold evaluation on held-out labels
full rationale
The paper reports an empirical detector based on source-output acoustic consistency (median f0, VTL, HNR) computed on human-labeled degraded samples from WaveRNN and HiFi-GAN vocoders. Asymmetric input-output thresholding is applied and accuracies are measured directly on the labeled sets (n=54 and n=40). No derivation, equation, or first-principles claim is presented that reduces to a fitted parameter by construction; the thresholds are chosen from the same data distribution but the evaluation remains a standard held-out performance measurement. No self-citations are load-bearing for the central claim, and the source-filter motivation is a standard reference rather than a self-referential ansatz. The logic is self-contained as a practical screening method without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- asymmetric thresholds on f0, VTL, HNR
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
f0 and HNR both achieved 85.2% accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION Recent advances in generative artificial intelligence have led to the widespread use of synthetic speech in applications such as conver- sational agents, speech-to-speech translation, audiobook and dub- bing production, personalized voice cloning, augmentative and al- ternative communication, digital avatars, and social robots. The challenge ...
-
[2]
RELA TED WORK In speech synthesis and voice conversion research, quality and nat- uralness are still most commonly assessed through subjective lis- tening tests, especially Mean Opinion Score (MOS) [8]. While recent work has introduced automatic, non-intrusive predictors of perceived speech quality [9, 10], these methods generally target overall quality e...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
PRESENT APPROACH We therefore asked, as a first step, whether fundamental frequency alone could provide a useful low-cost indicator of vocoder fail- ure. Specifically, we tested whether source–output consistency in medianf 0 was sufficient to distinguish outputs judged by hu- man listeners as acceptable from those judged as degraded because of audible art...
-
[4]
METHOD 4.1. Datasets and V ocoder Architectures To evaluate the proposed pitch-based evaluation of the synthesis output, a dataset of human-labeled audio samples was utilized. Source utterances were drawn from the LibriSpeech ASR corpus, a large-scale audiobook-based dataset of read English speech, and were used to generate the synthesized samples later l...
-
[5]
RESULTS The goal of this analysis was to validate a low-cost, interpretable method for detecting degraded voice-cloning outputs from sim- ple source–output acoustic features. We first report the reliability of the human labels used as ground truth, and then evaluate the threshold-based classifiers forf 0, HNR, and VTL across the two vocoder families. 5.1....
-
[6]
DISCUSSION The present results show that a simple thresholding procedure ap- plied to low-dimensional acoustic features can provide a useful first-pass detector of degraded voice-cloning outputs. Across both vocoders,f 0 and HNR were the two most informative features, whereas VTL was consistently less discriminative. This suggests that synthesis failures ...
-
[7]
CONCLUSION Overall, our results show that a simple asymmetric thresholding procedure in the input–output feature space can recover human judgments of synthesis quality with useful accuracy. Among the three features,f 0 and HNR were consistently the most informa- tive, while VTL was weaker across both vocoders. The results fur- ther indicate thatf 0 and HN...
-
[8]
T. K. Craig, M. Rus-Calafell, T. Ward, J. P. Leff, M. Huckvale, E. Howarth, R. Emsley, and P. A. Garety, “A V ATAR therapy for auditory verbal hallucinations in people with psychosis: a single-blind, randomised controlled trial,”The Lancet Psychiatry, vol. 5, no. 1, pp. 31–40, 2018, publisher: The Author(s). Published by Elsevier Ltd. This is an Open Acce...
-
[9]
Suicide attempts in schizophre- nia: the role of command auditory hallucinations for sui- cide
J. Harkavy-Friedman, D. Kimhy, E. Nelson, D. Venarde, D. Malaspina, and J. Mann, “Suicide attempts in schizophre- nia: the role of command auditory hallucinations for sui- cide.”The Journal of clinical psychiatry., vol. 64, no. 8, pp. 871–874, 2003
work page 2003
-
[10]
Reattribution of Auditory Hallucinations Throughout Avatar Therapy: A Case Series,
S. Giguère, M. Beaudoin, L. Dellazizzo, K. Phraxayavong, S. Potvin, and A. Dumais, “Reattribution of Auditory Hallucinations Throughout Avatar Therapy: A Case Series,” Reports, vol. 8, no. 3, p. 113, Jul. 2025. [Online]. Available: https://pmc.ncbi.nlm.nih.gov/articles/PMC12285938/
work page 2025
-
[11]
Digital A V ATAR therapy for distressing voices in psychosis: the phase 2/3 A V ATAR2 trial,
P. A. Garety, C. J. Edwards, H. Jafari, R. Emsley, M. Huckvale, M. Rus-Calafell, M. Fornells-Ambrojo, A. Gumley, G. Haddock, S. Bucci, H. J. McLeod, J. McDonnell, M. Clancy, M. Fitzsimmons, H. Ball, A. Montague, N. Xanidis, A. Hardy, T. K. J. Craig, and T. Ward, “Digital A V ATAR therapy for distressing voices in psychosis: the phase 2/3 A V ATAR2 trial,”...
work page 2024
-
[12]
Avatar Therapy: an audio-visual dialogue system for treating auditory hallucina- tions,
M. Huckvale, J. Leff, and G. Williams, “Avatar Therapy: an audio-visual dialogue system for treating auditory hallucina- tions,” inInterspeech, 2013, pp. 392–396
work page 2013
-
[14]
The sound of hallucinations: Toward a more convincing emulation of internalized voices,
——, “The sound of hallucinations: Toward a more convincing emulation of internalized voices,” inHuman Factors in Computing Systems (CHI). New Orleans, LA: ACM, Apr. 2022. [Online]. Available: https://dl.acm.org/ doi/10.1145/3491102.3501871
-
[15]
A review on subjective and objective evalu- ation of synthetic speech,
E. Cooper, W.-C. Huang, Y . Tsao, H.-M. Wang, T. Toda, and J. Yamagishi, “A review on subjective and objective evalu- ation of synthetic speech,”Acoustical Science and Technol- ogy, vol. 45, no. 4, pp. 161–183, 2024
work page 2024
-
[16]
W. C. Huang, E. Cooper, Y . Tsao, H.-M. Wang, T. Toda, and J. Yamagishi, “The V oiceMOS Challenge 2022,” inInterspeech 2022. ISCA, Sep. 2022, pp. 4536–
work page 2022
-
[17]
Available: https://www.isca-archive.org/ interspeech_2022/huang22f_interspeech.html
[Online]. Available: https://www.isca-archive.org/ interspeech_2022/huang22f_interspeech.html
-
[18]
G. Mittag, B. Naderi, A. Chehadi, and S. Möller, “NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,” inInterspeech 2021. ISCA, Aug. 2021, pp. 2127–
work page 2021
-
[19]
Available: https://www.isca-archive.org/ interspeech_2021/mittag21_interspeech.html
[Online]. Available: https://www.isca-archive.org/ interspeech_2021/mittag21_interspeech.html
-
[20]
Evolution of human vo- cal production,
A. A. Ghazanfar and D. Rendall, “Evolution of human vo- cal production,”Current Biology, vol. 18, no. 11, pp. R457– R460, 2008
work page 2008
-
[21]
Perceptual scaling of voice iden- tity: Common dimensions for different vowels and speak- ers,
O. Baumann and P. Belin, “Perceptual scaling of voice iden- tity: Common dimensions for different vowels and speak- ers,”Psychological Research, vol. 74, no. 1, pp. 110–120, 2010
work page 2010
-
[22]
Information conveyed by voice quality,
J. Kreiman, “Information conveyed by voice quality,”The Journal of the Acoustical Society of America, vol. 155, no. 2, pp. 1264–1271, Feb. 2024, publisher: AIP Publishing
work page 2024
-
[23]
Norm-based coding of voice identity in human auditory cor- tex,
M. Latinus, P. McAleer, P. E. G. Bestelmeyer, and P. Belin, “Norm-based coding of voice identity in human auditory cor- tex,”Current Biology, vol. 23, no. 12, pp. 1075–1080, 2013
work page 2013
-
[24]
Bone conduction facilitates self-other voice discrimination,
P. Orepic, O. A. Kannape, N. Faivre, and O. Blanke, “Bone conduction facilitates self-other voice discrimination,”Royal Society Open Science, vol. 10, no. 2, Feb. 2023, publisher: The Royal Society
work page 2023
-
[25]
Efficient neural audio synthesis,
N. Kalchbrenneret al., “Efficient neural audio synthesis,” inProceedings of the 35th International Conference on Ma- chine Learning (ICML), 2018
work page 2018
-
[26]
Hifi-gan: Generative adver- sarial networks for efficient and high fidelity speech synthe- sis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adver- sarial networks for efficient and high fidelity speech synthe- sis,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020
work page 2020
-
[27]
Introducing parselmouth: A python interface to Praat,
Y . Jadoul, B. Thompson, and B. de Boer, “Introducing parselmouth: A python interface to Praat,”Journal of Pho- netics, vol. 71, 2018
work page 2018
-
[28]
P. Boersma and D. Weenink,Praat: doing phonetics by computer, 2024, computer program, Version 6.4.0. [Online]. Available: http://www.praat.org/
work page 2024
-
[29]
T. F. Quatieri,Principles of Discrete-Time Speech Process- ing. Upper Saddle River, NJ: Prentice Hall, 2001, explains F0 estimation and voiced/unvoiced classification standards
work page 2001
-
[30]
P. Boersma and D. Weenink,Praat Manual: Harmonicity, 2026, accessed: 2026-04-03. [Online]. Available: https: //praat.org/manual/Harmonicity.html
work page 2026
-
[31]
An introduction to roc analysis,
T. Fawcett, “An introduction to roc analysis,”Pattern recog- nition letters, vol. 27, no. 8, pp. 861–874, 2006. 7
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.