Recognition: no theorem link
Neuroscience-Inspired Analyses of Visual Interestingness in Multimodal Transformers
Pith reviewed 2026-05-12 01:29 UTC · model grok-4.3
The pith
Multimodal transformers encode human-derived visual interestingness in structured form across their layers without explicit training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
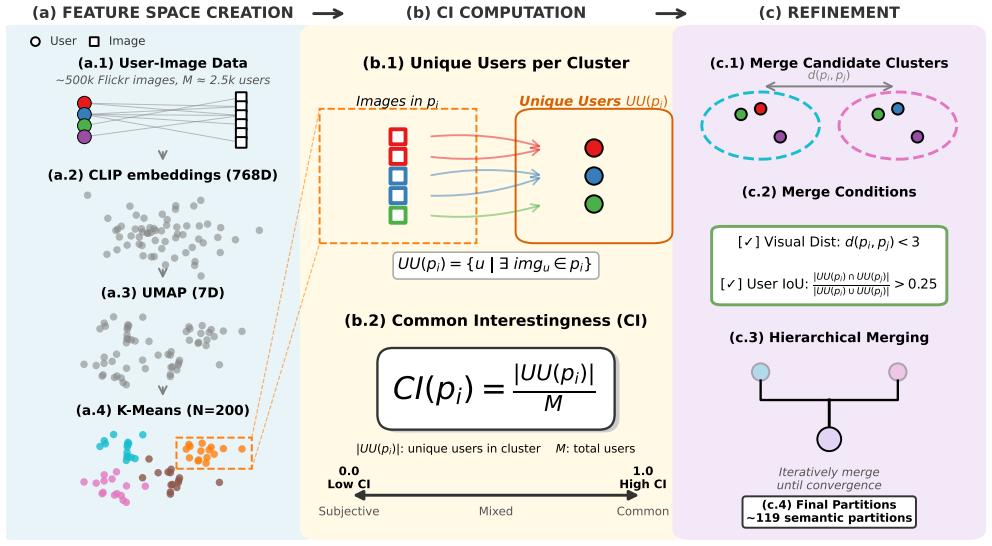
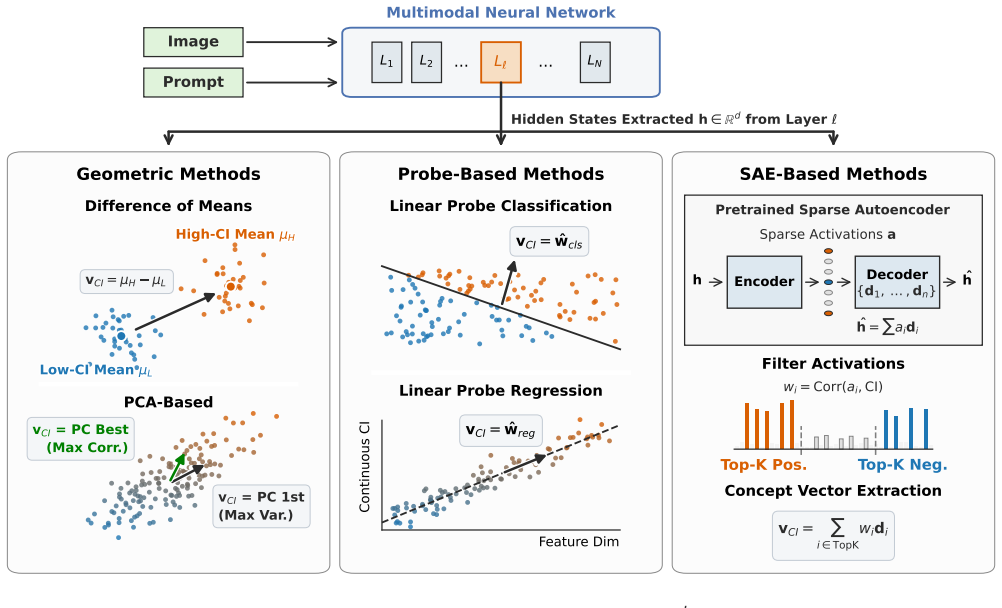
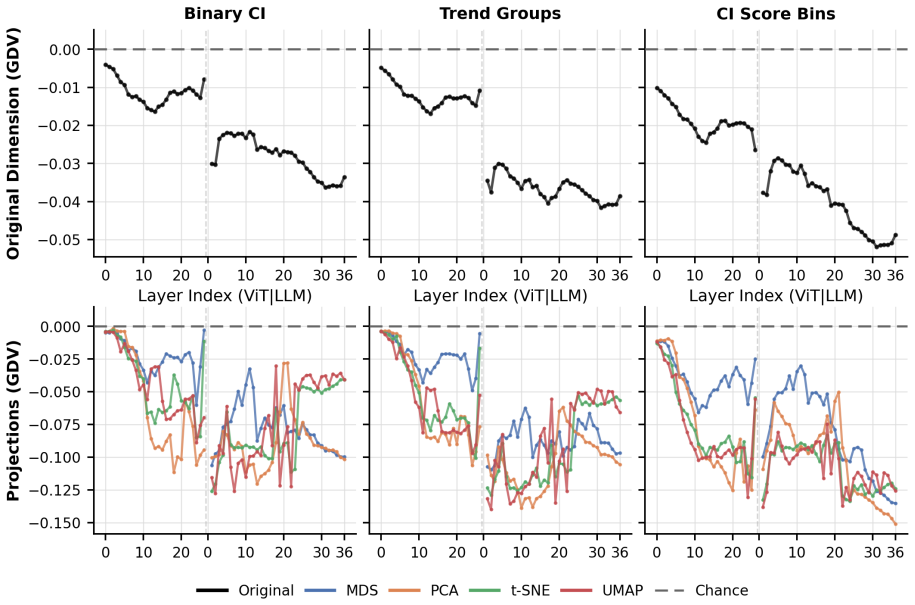
Analyses of Qwen3-VL-8B reveal that Common Interestingness information is linearly decodable from final-layer embeddings, indicating alignment with human-derived measures of visual interestingness. Dimensionality reduction and Generalized Discrimination Value analyses show CI-related hidden representations emerge in intermediate vision transformer layers and become progressively more distinguishable across language model layers. Concept vectors obtained through geometric, probe, and Sparse Auto-Encoder methods converge in higher layers according to representational similarity analysis, demonstrating a robust and structured encoding of visual interestingness without explicit supervision.
What carries the argument
Layer-wise application of linear decodability probes, Generalized Discrimination Value (GDV), and representational similarity analysis to track the emergence and convergence of Common Interestingness (CI) representations in vision and language transformer components.
Load-bearing premise
The pre-defined Common Interestingness score from Flickr engagement data accurately captures intrinsic visual interestingness rather than popularity, image quality, or platform biases.
What would settle it
Linear decoders trained on the embeddings would fail to predict held-out CI scores above chance, or GDV values would show no systematic increase in distinguishability from intermediate vision layers onward.
Figures




read the original abstract
Human attention is the gateway to conscious perception, memory and decision-making. However, its role in modern transformer models remains largely unexplored. As these systems increasingly influence what people see, prefer and buy, the question arises as to whether they encode principles of human interest or merely exploit large-scale correlations. Addressing this issue is crucial for understanding cognition and ensuring the responsible use of AI in communication and marketing. In order to address this issue, the concept of visual interest was examined within the multimodal vision-language-model Qwen3-VL-8B, using a pre-defined Common Interestingness (CI) score derived from large-scale human engagement data on the photo-sharing platform Flickr. Here, we analyzed internal representations across vision and language components using methods from the neurosciences. Our analyses revealed that CI information is linearly decodable from final-layer embeddings, indicating that it is aligned with human-derived measures of visual interestingness. Dimensionality reduction and Generalized Discrimination Value (GDV) analyses demonstrate that CI-related hidden representations emerge in intermediate vision transformer layers and becomes progressively more distinguishable across language model layers. Concept vectors derived using geometric, probe, and Sparse Auto-Encoder based methods converge in higher layers, as confirmed by representational similarity analysis. This indicates a robust and structured encoding of visual interestingness without explicit supervision. Future work will seek to identify shared computational principles linking human brain dynamics and transformer architectures, with the ultimate goal of uncovering the organizing mechanisms that give rise to attention and interest in both biological and artificial systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines visual interestingness in the multimodal transformer Qwen3-VL-8B by analyzing its internal representations with neuroscience-inspired tools. It uses a pre-defined Common Interestingness (CI) score computed from large-scale Flickr engagement data as the target variable. Linear decoding, dimensionality reduction, Generalized Discrimination Value (GDV) trajectories, and representational similarity analysis of concept vectors (obtained via geometric, probing, and Sparse Auto-Encoder routes) are applied across vision and language layers. The central claims are that CI information is linearly decodable from final-layer embeddings, that CI-related structure emerges in intermediate vision-transformer layers and grows progressively distinguishable through the language-model stack, and that the three families of concept vectors converge in higher layers, indicating unsupervised, structured encoding of human-derived visual interest.
Significance. If the quantitative results and controls hold, the work would supply evidence that multimodal transformers spontaneously align internal representations with human visual interestingness without any supervision on that variable. Such a finding would strengthen the case for using representational-similarity and decoding methods from neuroscience to interpret emergent properties in large vision-language models and could inform both cognitive modeling and the design of more transparent multimodal systems.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the manuscript relies on a Flickr-derived CI score as the sole human-interest proxy yet reports no controls, partial correlations, or matched-subset analyses for known confounds (image aesthetics, resolution, upload timing, social-network effects, or platform promotion). Without such checks, the reported linear decodability and layer-wise GDV increases could reflect low-level visual statistics rather than genuine alignment with intrinsic interestingness.
- [Abstract] Abstract: all claims of linear decodability, progressive distinguishability, and concept-vector convergence are stated without any numerical values, error bars, statistical tests, layer indices, or sample sizes. This absence prevents assessment of effect magnitude or robustness and is load-bearing for the central emergence claim.
- [Results] Results (GDV and RSA sections): the progressive increase in distinguishability across language-model layers and the convergence of geometric/probe/SAE concept vectors are presented without baseline comparisons (e.g., shuffled labels, random embeddings, or control tasks) or explicit layer-by-layer statistics, leaving open whether the observed trajectories exceed what would be expected from generic depth-dependent specialization.
minor comments (2)
- [Abstract] Abstract: subject-verb agreement error in 'CI-related hidden representations emerge ... and becomes progressively more distinguishable'; 'representations' is plural, so 'become' is required.
- [Abstract / Methods] Notation: the acronym 'GDV' is introduced without an explicit expansion or reference on first use; a brief parenthetical definition would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify how to strengthen the presentation and robustness of our findings on the alignment between multimodal transformer representations and human visual interestingness. We address each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the manuscript relies on a Flickr-derived CI score as the sole human-interest proxy yet reports no controls, partial correlations, or matched-subset analyses for known confounds (image aesthetics, resolution, upload timing, social-network effects, or platform promotion). Without such checks, the reported linear decodability and layer-wise GDV increases could reflect low-level visual statistics rather than genuine alignment with intrinsic interestingness.
Authors: We agree that explicit controls for potential confounds are necessary to support the interpretation that the decoded structure reflects human-derived interestingness rather than low-level image properties. In the revised manuscript we will add partial-correlation analyses that control for image aesthetics (using established computational metrics), resolution, and available metadata on upload timing. We will also report results on matched subsets where images are equated on these variables, and include these controls in both the Methods and Results sections with appropriate statistical reporting. revision: yes
-
Referee: [Abstract] Abstract: all claims of linear decodability, progressive distinguishability, and concept-vector convergence are stated without any numerical values, error bars, statistical tests, layer indices, or sample sizes. This absence prevents assessment of effect magnitude or robustness and is load-bearing for the central emergence claim.
Authors: We accept that the abstract must convey quantitative information to allow readers to evaluate the strength of the claims. The revised abstract will include the key numerical results: linear decoding accuracy (with standard error), GDV values and their layer-wise increases (with statistical tests), specific layer indices where structure emerges, and the number of images and layers analyzed. Error bars and p-values will be stated where they support the reported effects. revision: yes
-
Referee: [Results] Results (GDV and RSA sections): the progressive increase in distinguishability across language-model layers and the convergence of geometric/probe/SAE concept vectors are presented without baseline comparisons (e.g., shuffled labels, random embeddings, or control tasks) or explicit layer-by-layer statistics, leaving open whether the observed trajectories exceed what would be expected from generic depth-dependent specialization.
Authors: We acknowledge that baseline controls and layer-wise statistics are required to demonstrate that the reported trajectories are specific to the CI variable rather than generic consequences of depth. In the revision we will add shuffled-label and random-embedding baselines for both GDV and RSA analyses, together with layer-by-layer statistical tests (e.g., repeated-measures ANOVA or paired t-tests with appropriate multiple-comparison correction). These controls and statistics will be presented in the Results text and in updated figures. revision: yes
Circularity Check
No circularity: post-hoc decoding of external CI score
full rationale
The paper applies standard post-hoc neuroscience methods (linear probes, GDV, dimensionality reduction, RSA, concept vectors via probes/SAE) to the frozen embeddings of a pre-trained Qwen3-VL model. The CI target is a pre-defined external score computed from Flickr engagement data and is never used for model training, fine-tuning, or parameter optimization. No equations, predictions, or uniqueness claims reduce to fitted inputs or self-citations by construction. The derivation chain consists entirely of observational measurements on independent data, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear decodability from embeddings indicates meaningful alignment with the target concept
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.12837 , year=
Cognition spaces: natural, artificial, and hybrid , author=. arXiv preprint arXiv:2601.12837 , year=
-
[2]
The Platonic Representation Hypothesis
The platonic representation hypothesis , author=. arXiv preprint arXiv:2405.07987 , year=
-
[3]
Human vision and electronic imaging XVIII , volume=
The effect of familiarity on perceived interestingness of images , author=. Human vision and electronic imaging XVIII , volume=. 2013 , organization=
work page 2013
-
[4]
Proceedings of the 21st ACM international conference on Multimedia , pages=
Visual interestingness in image sequences , author=. Proceedings of the 21st ACM international conference on Multimedia , pages=
-
[5]
Proceedings of the IEEE international conference on computer vision , pages=
The interestingness of images , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[6]
Advances in neural information processing systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[7]
International journal of computer vision , volume=
Imagenet large scale visual recognition challenge , author=. International journal of computer vision , volume=. 2015 , publisher=
work page 2015
-
[8]
Proceedings of the IEEE Conference on computer vision and pattern recognition , pages=
Emotional attention: A study of image sentiment and visual attention , author=. Proceedings of the IEEE Conference on computer vision and pattern recognition , pages=
-
[9]
Multimodal approaches for emotion recognition: a survey , author=. Internet Imaging VI , volume=. 2005 , organization=
work page 2005
-
[10]
Cognitive neuroscience , volume=
Predictive coding, precision and synchrony , author=. Cognitive neuroscience , volume=. 2012 , publisher=
work page 2012
-
[11]
Philosophical transactions of the Royal Society B: Biological sciences , volume=
Predictive coding under the free-energy principle , author=. Philosophical transactions of the Royal Society B: Biological sciences , volume=. 2009 , publisher=
work page 2009
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Visual Interestingness Decoded: How GPT-4o Mirrors Human Interests , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
Understanding aesthetics with language: A photo critique dataset for aesthetic assessment , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
European Conference on Computer Vision , pages=
Commonly interesting images , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[15]
The chinese room , author=
-
[16]
PLoS computational biology , volume=
Could a neuroscientist understand a microprocessor? , author=. PLoS computational biology , volume=. 2017 , publisher=
work page 2017
-
[17]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking , author=. arXiv preprint arXiv:2601.04720 , year=
work page internal anchor Pith review arXiv
-
[19]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
- [20]
-
[21]
Quantifying the separability of data classes in neural networks , author=. Neural Networks , volume=. 2021 , publisher=
work page 2021
-
[22]
Predictive coding and stochastic resonance as fundamental principles of auditory phantom perception , author=. Brain , volume=. 2023 , publisher=
work page 2023
-
[23]
A statistical method for analyzing and comparing spatiotemporal cortical activation patterns , author=. Scientific reports , volume=. 2018 , publisher=
work page 2018
-
[24]
arXiv preprint arXiv:2501.08145 , year=
Refusal behavior in large language models: A nonlinear perspective , author=. arXiv preprint arXiv:2501.08145 , year=
-
[25]
Journal of Neurophysiology , volume=
The Bayesian brain: world models and conscious dimensions of auditory phantom perception , author=. Journal of Neurophysiology , volume=. 2024 , publisher=
work page 2024
-
[26]
Deep learning based decoding of single local field potential events , author=. NeuroImage , volume=. 2024 , publisher=
work page 2024
-
[27]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general intelligence: Early experiments with gpt-4 , author=. arXiv preprint arXiv:2303.12712 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [28]
-
[29]
Cognitive Computation , volume=
Interpreting black-box models: a review on explainable artificial intelligence , author=. Cognitive Computation , volume=. 2024 , publisher=
work page 2024
-
[30]
Frontiers in systems neuroscience , volume=
Representational similarity analysis-connecting the branches of systems neuroscience , author=. Frontiers in systems neuroscience , volume=. 2008 , publisher=
work page 2008
-
[31]
Representational similarity analysis of object population codes in humans, monkeys, and models , author=. Visual population codes: towards a common multivariate framework for cell recording and functional imaging , year=
-
[32]
arXiv preprint arXiv:2208.10576 , year=
Different spectral representations in optimized artificial neural networks and brains , author=. arXiv preprint arXiv:2208.10576 , year=
-
[33]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[34]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[35]
Revisiting Multimodal Positional Encoding in Vision-Language Models
Revisiting Multimodal Positional Encoding in Vision-Language Models , author=. arXiv preprint arXiv:2510.23095 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
work page 2020
-
[37]
Workshop on Job Scheduling Strategies for Parallel Processing , pages=
Architecture of the slurm workload manager , author=. Workshop on Job Scheduling Strategies for Parallel Processing , pages=. 2023 , organization=
work page 2023
-
[38]
Transactions on Machine Learning Research , year=
Mechanistic Interpretability for AI Safety-A Review , author=. Transactions on Machine Learning Research , year=
-
[39]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=. 2022 , publisher=
work page 2022
-
[40]
Understanding intermediate layers using linear classifier probes , author=
-
[41]
Designing and Interpreting Probes with Control Tasks , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[42]
A practical review of mechanistic interpretability for transformer-based language models , author=. arXiv preprint arXiv:2407.02646 , year=
-
[43]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Attribution Patching Outperforms Automated Circuit Discovery , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[45]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[46]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
work page 2024
-
[47]
The Twelfth International Conference on Learning Representations , year=
Sparse autoencoders find highly interpretable features in language models , author=. The Twelfth International Conference on Learning Representations , year=
-
[48]
arXiv preprint arXiv:2506.18167 , year=
Understanding reasoning in thinking language models via steering vectors , author=. arXiv preprint arXiv:2506.18167 , year=
-
[49]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review arXiv
-
[50]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[51]
Probing ranking llms: Mechanistic interpretability in information retrieval , author=. arXiv e-prints , pages=
-
[52]
arXiv preprint arXiv:2405.15454 , year=
Linearly controlled language generation with performative guarantees , author=. arXiv preprint arXiv:2405.15454 , year=
-
[53]
arXiv preprint arXiv:2512.17639 , year=
Linear Personality Probing and Steering in LLMs: A Big Five Study , author=. arXiv preprint arXiv:2512.17639 , year=
-
[54]
Tutorials in quantitative methods for psychology , volume=
A review of multidimensional scaling (MDS) and its utility in various psychological domains , author=. Tutorials in quantitative methods for psychology , volume=
-
[55]
Encyclopedia of cognitive science , volume=
Multidimensional scaling , author=. Encyclopedia of cognitive science , volume=. 2002 , publisher=
work page 2002
-
[56]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Umap: Uniform manifold approximation and projection for dimension reduction , author=. arXiv preprint arXiv:1802.03426 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
International conference on image and signal processing , pages=
Considerably improving clustering algorithms using UMAP dimensionality reduction technique: a comparative study , author=. International conference on image and signal processing , pages=. 2020 , organization=
work page 2020
-
[58]
Journal of machine learning research , volume=
Visualizing data using t-SNE , author=. Journal of machine learning research , volume=
-
[59]
" understanding ai": Semantic grounding in large language models , author=. arXiv preprint arXiv:2402.10992 , year=
-
[60]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
The case of CAUSE: neurobiological mechanisms for grounding an abstract concept , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2018 , publisher=
work page 2018
-
[61]
Prediction, Syntax and Semantic Grounding in the Brain and Large Language Models , author=. bioRxiv , pages=. 2025 , publisher=
work page 2025
-
[62]
IEEE transactions on image processing , volume=
NIMA: Neural image assessment , author=. IEEE transactions on image processing , volume=. 2018 , publisher=
work page 2018
-
[63]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[64]
The Core Of The Scientific Method , author=. Authorea Preprints , year=
- [65]
-
[66]
IEEE transactions on pattern analysis and machine intelligence , volume=
State-of-the-art in visual attention modeling , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2012 , publisher=
work page 2012
-
[67]
DeepGaze II: Reading fixations from deep features trained on object recognition
DeepGaze II: Reading fixations from deep features trained on object recognition , author=. arXiv preprint arXiv:1610.01563 , year=
-
[68]
Proceedings of the ieee/cvf international conference on computer vision , pages=
DeepGaze IIE: Calibrated prediction in and out-of-domain for state-of-the-art saliency modeling , author=. Proceedings of the ieee/cvf international conference on computer vision , pages=
- [69]
-
[70]
Progress in brain research , volume=
Building the gist of a scene: The role of global image features in recognition , author=. Progress in brain research , volume=. 2006 , publisher=
work page 2006
-
[71]
International journal of computer vision , volume=
Modeling the shape of the scene: A holistic representation of the spatial envelope , author=. International journal of computer vision , volume=. 2001 , publisher=
work page 2001
-
[72]
Neural mechanisms of rapid natural scene categorization in human visual cortex , author=. Nature , volume=. 2009 , publisher=
work page 2009
-
[73]
How long to get to the “gist” of real-world natural scenes? , author=. Visual cognition , volume=. 2005 , publisher=
work page 2005
-
[74]
Empirical studies of the arts , volume=
Cognitive appraisals and interest in visual art: Exploring an appraisal theory of aesthetic emotions , author=. Empirical studies of the arts , volume=. 2005 , publisher=
work page 2005
-
[75]
Psychological science , volume=
The briefest of glances: The time course of natural scene understanding , author=. Psychological science , volume=. 2009 , publisher=
work page 2009
-
[76]
Trends in cognitive sciences , volume=
Object vision in a structured world , author=. Trends in cognitive sciences , volume=. 2019 , publisher=
work page 2019
-
[77]
Trends in cognitive sciences , volume=
Neuroaesthetics , author=. Trends in cognitive sciences , volume=. 2014 , publisher=
work page 2014
-
[78]
Perspectives on psychological science , volume=
Neuroaesthetics: The cognitive neuroscience of aesthetic experience , author=. Perspectives on psychological science , volume=. 2016 , publisher=
work page 2016
- [79]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.