Recognition: 2 theorem links
· Lean TheoremDiffVQE: Hybrid Diffusion Voice Quality Enhancement Under Acoustic Echo and Noise
Pith reviewed 2026-05-12 01:24 UTC · model grok-4.3
The pith
DiffVQE is the first reproducible diffusion-based model for joint acoustic echo control and speech denoising that beats the leading discriminative method in quality and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hybrid diffusion model trained on the URGENT Challenge dataset delivers better joint acoustic echo control and denoising than the prior leading discriminative model DeepVQE, while also reducing computational complexity and model size.
What carries the argument
The hybrid diffusion process that learns to generate clean speech from inputs degraded by echo and noise.
If this is right
- DiffVQE achieves stronger echo cancellation and denoising than DeepVQE on the chosen dataset.
- The diffusion model requires lower computational complexity than the baseline.
- Model size is reduced while maintaining or improving performance.
- A reproducible diffusion baseline is established for acoustic echo cancellation tasks.
Where Pith is reading between the lines
- Making the model causal could open the door to real-time deployment in live communication devices.
- The same diffusion framework might extend to other combined audio degradations such as reverberation or packet loss.
- Success here suggests diffusion models could become competitive defaults for joint enhancement problems rather than separate modules.
Load-bearing premise
Training a diffusion model on the URGENT Challenge dataset will reliably deliver superior joint echo and noise performance compared to strong discriminative baselines like DeepVQE.
What would settle it
Evaluating both DiffVQE and DeepVQE on the same URGENT Challenge test set and finding no gain in objective metrics such as echo return loss enhancement or perceptual speech quality scores.
Figures


read the original abstract
Acoustic echo and background noise pose challenges on speech enhancement in hands-free systems and speakerphones. Discriminatively trained end-to-end methods represent a powerful solution for joint acoustic echo control (AEC) and denoising. However, with the advent of generative methods, diffusion-based approaches have seen remarkable performance in speech enhancement tasks. In this work, to the best of our knowledge, we provide the first (still non-causal) diffusion-based AEC model (DiffVQE) that is reproducible in terms of topology, training data, and training framework. So far, without employing diffusion, Microsoft's discriminative DeepVQE model has been shown to excel any of the ICASSP 2023 AEC Challenge entries achieving remarkable performance. Using data from the Interspeech 2025 URGENT Challenge for a diverse, high-quality training dataset, our DiffVQE excels DeepVQE both in echo and noise control performance, as well as in computational complexity and model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DiffVQE as the first reproducible (non-causal) diffusion-based model for joint acoustic echo control (AEC) and denoising. It claims that, when trained on the Interspeech 2025 URGENT Challenge dataset, DiffVQE outperforms Microsoft's earlier discriminative DeepVQE model in echo/noise control performance while also improving computational complexity and model size.
Significance. If the performance claims are substantiated with matched-data controls and quantitative results, the work would be significant for demonstrating that hybrid diffusion models can be applied effectively to AEC tasks, potentially yielding smaller and more efficient solutions than purely discriminative approaches. The explicit emphasis on reproducibility of topology, data, and framework is a clear strength.
major comments (1)
- [Abstract] Abstract: The central claim that DiffVQE 'excels DeepVQE both in echo and noise control performance, as well as in computational complexity and model size' is load-bearing for the paper's contribution, yet the abstract provides no metrics, tables, ablation studies, or experimental details to support it. In addition, DeepVQE predates the URGENT Challenge; without a matched-data evaluation (e.g., retraining or re-evaluating DeepVQE on the identical URGENT dataset), gains cannot be attributed to the diffusion architecture rather than differences in training data quality and diversity.
minor comments (1)
- [Abstract] Abstract: The qualifier '(still non-causal)' is mentioned but not elaborated; a brief discussion of latency implications for hands-free applications would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the concerns point by point below and will revise the manuscript to strengthen the presentation of results and clarify the experimental comparisons.
read point-by-point responses
-
Referee: The central claim that DiffVQE 'excels DeepVQE both in echo and noise control performance, as well as in computational complexity and model size' is load-bearing for the paper's contribution, yet the abstract provides no metrics, tables, ablation studies, or experimental details to support it.
Authors: We agree that the abstract should be more self-contained. In the revised version we will insert the key quantitative results (ERLE, PESQ, STOI deltas, parameter count, and real-time factor) that are already reported in the experimental section, so that the central claim is immediately supported by numbers. revision: yes
-
Referee: In addition, DeepVQE predates the URGENT Challenge; without a matched-data evaluation (e.g., retraining or re-evaluating DeepVQE on the identical URGENT dataset), gains cannot be attributed to the diffusion architecture rather than differences in training data quality and diversity.
Authors: We acknowledge the limitation. Our current comparison evaluates the publicly released DeepVQE checkpoint on the URGENT test set while DiffVQE is trained on the URGENT training partition; this guarantees identical test conditions but does not control for training-data differences. We will add an explicit statement of this protocol in the revised manuscript, qualify the attribution of gains, and note that retraining DeepVQE on the URGENT data would be a valuable future experiment. The reproducibility of DiffVQE itself on the URGENT corpus remains a distinct contribution. revision: partial
Circularity Check
No circularity in empirical performance claims
full rationale
The paper's central claims rest on training a diffusion model (DiffVQE) on the URGENT Challenge dataset and reporting empirical superiority over the prior DeepVQE model in echo/noise control, complexity, and size. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or described claims. The reproducibility statement and 'first diffusion-based AEC' positioning are factual assertions about the work, not tautological reductions. Dataset differences in the DeepVQE comparison raise validity concerns but do not create circularity by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
score-based diffusion ... Itô SDE ... denoising score matching objective JSM ... single-step ... J = J_CC(Ŝcond,S) + J_CC(Ŝ,S) + α J_SM
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid diffusion approach ... DiffVQE ... outperforms DeepVQE in echo control ... model complexity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Predominantly in noise reduction tasks, gen- erative approaches have gained significant traction
Introduction Speech enhancement has undergone a significant paradigm shift in recent years. Predominantly in noise reduction tasks, gen- erative approaches have gained significant traction. Previ- ously, many approaches utilized some form of mean squared error (MSE) loss either in time domain or in frequency do- main to train discriminative masked-based d...
work page 2025
-
[2]
DiffVQE: Hybrid Diffusion Voice Quality Enhancement Under Acoustic Echo and Noise
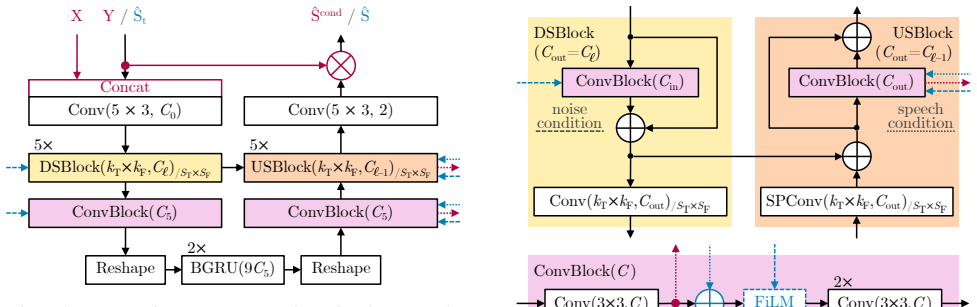
Methods 2.1. Data representation and framework overview An overview of our hands-free system is given in Fig. 1. The far-end signalx(n)with sample indexnis transmitted to the near-end and played back by a loudspeaker. Loudspeaker non- linearities are modeled byx ′(n) =f NL(x(n)). The micro- phone receivesx ′(n)as an echod(n) =h 1(n)∗x ′(n), with h1(n)bein...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experimental setup 3.1. Datasets and framework To generate a diverse set of samples, our proposedDiffVQEis trainedon a dataset comprising speech and noise sources from the Interspeech 2025 URGENT Challenge [19]. As generative methods benefit highly from high quality ground truth targets in training, we exclude the CommonV oice 19.0 [28] dataset. We furthe...
work page 2025
-
[4]
Besides the AECMOS metrics, we include Table 1:Model performance onD val in all three conditions
Experimental evaluation and discussion In Table 1, we show results of our proposedDiffVQEvari- ants as well as from the retrainedDeepVQEbaseline onD val for all conditions. Besides the AECMOS metrics, we include Table 1:Model performance onD val in all three conditions. Best performance is indicated in bold, second best is underlined. DT STFE STNE Avg. Me...
work page 2023
-
[5]
Conclusions In this work, we proposed a novel hybrid score-based diffusion approach to voice quality enhancement under acoustic echo and noise. It is one of the first diffusion-based acoustic echo con- trol (AEC) methods (still non-causal), being smaller, less com- plex and faster than the so-far SOTADeepVQE. Our proposed DiffVQEapproaches excelDeepVQEin ...
-
[6]
Speech Enhancement with Score-Based Generative Models in the Complex STFT Do- main,
S. Welker, J. Richter, and T. Gerkmann, “Speech Enhancement with Score-Based Generative Models in the Complex STFT Do- main,” inProc. of Interspeech, Incheon, Korea, Sep. 2022, pp. 2928–2932
work page 2022
-
[7]
StoRM: A Diffusion-Based Stochastic Regeneration Model for Speech Enhancement and Dereverberation,
J.-M. Lemercier, J. Richter, S. Welker, and T. Gerkmann, “StoRM: A Diffusion-Based Stochastic Regeneration Model for Speech Enhancement and Dereverberation,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 31, pp. 2724–2737, Jul. 2022
work page 2022
-
[8]
Speech Enhancement and Dereverberation With Diffusion- Based Generative Models,
J. Richter, S. Welker, J.-M. Lemercier, B. Lay, and T. Gerkmann, “Speech Enhancement and Dereverberation With Diffusion- Based Generative Models,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351–2364, 2023
work page 2023
-
[9]
Universal Score-based Speech Enhancement with High Content Preserva- tion,
R. Scheibler, Y . Fujita, Y . Shirahata, and T. Komatsu, “Universal Score-based Speech Enhancement with High Content Preserva- tion,” inProc. of Interspeech, Kos, Greece, Sep. 2024, pp. 1165– 1169
work page 2024
-
[10]
Y . Fu, R. Shi, M. Sach, W. Tirry, and T. Fingscheidt, “EffDiffSE: Efficient Diffusion-Based Frequency-Domain Speech Enhance- ment with Hybrid Discriminative and Generative DNNs,” inProc. of WASPAA, Tahoe City, CA, USA, Oct. 2025, pp. 1–5
work page 2025
-
[11]
E. Indenbom, N.-C. Ristea, A. Saabas, T. Parnamaa, J. Guzvin, and R. Cutler, “DeepVQE: Real Time Deep V oice Quality En- hancement for Joint Acoustic Echo Cancellation, Noise Suppres- sion and Dereverberation,” inProc. of Interspeech, Dublin, Ire- land, Aug. 2023, pp. 3819–3823
work page 2023
-
[12]
E. H ¨ansler and G. Schmidt,Acoustic Echo and Noise Control: A Practical Approach. Wiley, 2004
work page 2004
-
[13]
Frequency-Domain Adaptive Kalman Fil- ter for Acoustic Echo Control in Hands-Free Telephones,
G. Enzner and P. Vary, “Frequency-Domain Adaptive Kalman Fil- ter for Acoustic Echo Control in Hands-Free Telephones,”Signal Processing, vol. 86, no. 6, pp. 1140–1156, Jun. 2006
work page 2006
-
[14]
E. Seidel, G. Enzner, P. Mowlaee, and T. Fingscheidt, “Neural Kalman Filters for Acoustic Echo Cancellation: Comparison of Deep Neural Network-Based Extensions,”IEEE Signal Process- ing Magazine, vol. 41, no. 4, pp. 24–38, Jan. 2024
work page 2024
-
[15]
End-to-End Deep Learning-Based Adaptation Control for Linear Acoustic Echo Cancellation,
T. Haubner, A. Brendel, and W. Kellermann, “End-to-End Deep Learning-Based Adaptation Control for Linear Acoustic Echo Cancellation,”IEEE Transactions on Audio, Speech, and Lan- guage Processing, vol. 32, pp. 227–238, Oct. 2023
work page 2023
-
[16]
Low- Complexity Acoustic Echo Cancellation with Neural Kalman Fil- tering,
D. Yang, F. Jiang, W. Wu, X. Fang, and M. Cao, “Low- Complexity Acoustic Echo Cancellation with Neural Kalman Fil- tering,” inProc. of ICASSP, Rhodes Island, Greece, Jun. 2023, pp. 7846–7850
work page 2023
-
[17]
A Progressive Neural Network for Acoustic Echo Cancellation,
Z. Chen, X. Xia, S. Sun, Z. Wang, C. Chen, and G. Xie, “A Progressive Neural Network for Acoustic Echo Cancellation,” in Proc. of ICASSP, Rhodes Island, Greece, Mar. 2023, pp. 12 579– 12 580
work page 2023
-
[18]
Efficient High- Performance Bark-Scale Neural Network for Residual Echo and Noise Suppression,
E. Seidel, P. Mowlaee, and T. Fingscheidt, “Efficient High- Performance Bark-Scale Neural Network for Residual Echo and Noise Suppression,” inProc. of ICASSP, Seoul, Korea, Apr. 2024, pp. 1386–1390
work page 2024
-
[19]
A Hybrid Approach for Low- Complexity Joint Acoustic Echo and Noise Reduction,
S. S. Shetu, N. Kumar Desiraju, J. M. Martinez Aponte, E. A. P. Habets, and E. Mabande, “A Hybrid Approach for Low- Complexity Joint Acoustic Echo and Noise Reduction,” inProc. of IWAENC, Aalborg, Denmark, Sep. 2024, pp. 349–353
work page 2024
-
[20]
EchoFree: Towards Ultra Lightweight and Efficient Neural Acoustic Echo Cancellation,
X. Li, B. Kang, Z. Wang, Z. Zhang, M. Liu, Z. Fu, and L. Xie, “EchoFree: Towards Ultra Lightweight and Efficient Neural Acoustic Echo Cancellation,”arXiv, no. 2508.06271, Aug. 2025
-
[21]
Convergence and Per- formance Analysis of Classical, Hybrid, and Deep Acoustic Echo Control,
E. Seidel, P. Mowlaee, and T. Fingscheidt, “Convergence and Per- formance Analysis of Classical, Hybrid, and Deep Acoustic Echo Control,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2857–2870, May 2024
work page 2024
-
[22]
FSD: Acoustic Echo Cancellation with Fewer Step Diffusion,
Y . Liu, L. Wan, Y . Huang, M. Sun, C. Zhao, Z. Ni, X. Mei, Y . Shi, and F. Metze, “FSD: Acoustic Echo Cancellation with Fewer Step Diffusion,” inProc. of NeurIPS – Workshops, Vancouver, BC, Canada, Dec. 2024, pp. 1–6
work page 2024
-
[23]
UR- GENT Challenge: Universality, Robustness, and Generalizability for Speech Enhancement,
W. Zhang, R. Scheibler, K. Saijo, S. Cornell, C. Li, Z. Ni, J. Pirkl- bauer, M. Sach, S. Watanabe, T. Fingscheidt, and Y . Qian, “UR- GENT Challenge: Universality, Robustness, and Generalizability for Speech Enhancement,” inProc. of Interspeech, Kos, Greece, Sep. 2024, pp. 4868–4872
work page 2024
-
[24]
Interspeech 2025 URGENT Speech Enhancement Challenge,
K. Saijo, W. Zhang, S. Cornell, R. Scheibler, C. Li, Z. Ni, A. Ku- mar, M. Sach, Y . Fu, W. Wang, T. Fingscheidt, and S. Watanabe, “Interspeech 2025 URGENT Speech Enhancement Challenge,” inProc. of Interspeech, Rotterdam, Netherlands, Aug. 2025, pp. 858–862
work page 2025
-
[25]
H. Lugo Girao, E. Seidel, P. Mowlaee, Z. Zhao, and T. Fingscheidt, “DiffVQE Supplement,” https://ifnspaml.github. io/DiffVQE-Demo/, 2026
work page 2026
-
[26]
Score-Based Generative Modeling through Stochastic Differential Equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Er- mon, and B. Poole, “Score-Based Generative Modeling through Stochastic Differential Equations,” inProc. of ICLR, Virtual Event, Austria, May 2021, pp. 1–36
work page 2021
-
[27]
Reverse-Time Diffusion Equation Models,
B. D. O. Anderson, “Reverse-Time Diffusion Equation Models,” Stochastic Processes and their Applications, vol. 12, no. 3, pp. 313–326, May 1982
work page 1982
-
[28]
A Connection Between Score Matching and Denois- ing Autoencoders,
P. Vincent, “A Connection Between Score Matching and Denois- ing Autoencoders,”Neural Computation, vol. 23, no. 7, pp. 1661– 1674, Jul. 2011
work page 2011
-
[29]
Adversarial Score Matching and Improved Sampling for Image Generation,
A. Jolicoeur-Martineau, R. Pich ´e-Taillefer, I. Mitliagkas, and R. T. des Combes, “Adversarial Score Matching and Improved Sampling for Image Generation,” inProc. of ICLR, May 2021, pp. 1–9
work page 2021
-
[30]
A Consolidated View of Loss Functions for Supervised Deep Learning-Based Speech Enhancement,
S. Braun and I. Tashev, “A Consolidated View of Loss Functions for Supervised Deep Learning-Based Speech Enhancement,” in Proc. of Conference on Telecommunications and Signal Process- ing (TSP), Brno, Czech Republic, Jul. 2021, pp. 72–76
work page 2021
-
[31]
Elucidating the De- sign Space of Diffusion-Based Generative Models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the De- sign Space of Diffusion-Based Generative Models,” inProc. of NeurIPS, New Orleans, LA, USA, Dec. 2022, pp. 1–13
work page 2022
-
[32]
W. Shi, J. Caballero, F. Husz ´ar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang, “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network,” inProc. of CVPR, Las Vegas, NV , USA, Jun. 2016, pp. 1874–1883
work page 2016
-
[33]
Com- mon V oice: A Massively-Multilingual Speech Corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Com- mon V oice: A Massively-Multilingual Speech Corpus,” inProc. of LREC, Marseille, France, May 2020, pp. 4218–4222
work page 2020
-
[34]
Less is More: Data Curation Matters in Scaling Speech Enhancement,
C. Li, W. Zhang, W. Wang, R. Scheibler, K. Saijo, S. Cornell, Y . Fu, M. Sach, Z. Ni, A. Kumar, T. Fingscheidt, S. Watanabe, and Y . Qian, “Less is More: Data Curation Matters in Scaling Speech Enhancement,” inProc. of ASRU, Honululu, HI, USA, Dec. 2025, pp. 1–8
work page 2025
-
[35]
DNSMOS: A Non- Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A Non- Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,” inProc. of ICASSP, Toronto, ON, Canada, Jun. 2021, pp. 6493–6497
work page 2021
-
[36]
ICASSP 2024 Speech Signal Improvement Chal- lenge,
N. C. Ristea, A. Saabas, R. Cutler, B. Naderi, S. Braun, and S. Branets, “ICASSP 2024 Speech Signal Improvement Chal- lenge,”IEEE Open Journal of Signal Processing, vol. 6, pp. 238– 246, Jan. 2025
work page 2024
-
[37]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inProc. of Interspeech, Incheon, Korea, Sep. 2022, pp. 4521–4525
work page 2022
-
[38]
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,” inProc. of In- terspeech, Brno, Czech Republic, Aug. 2021, pp. 2127–2131
work page 2021
-
[39]
TorchAudio-Squim: Reference-less Speech Quality and Intelligibility Measures in TorchAudio,
A. Kumar, K. Tan, Z. Ni, P. Manocha, X. Zhang, E. Henderson, and B. Xu, “TorchAudio-Squim: Reference-less Speech Quality and Intelligibility Measures in TorchAudio,” inProc. of ICASSP, Rhodes Island, Greece, May 2023, pp. 1–5
work page 2023
-
[40]
Pyroomacoustics: A Python Package for Audio Room Simulations and Array Process- ing Algorithms,
R. Scheibler, E. Bezzam, and I. Dokmanic, “Pyroomacoustics: A Python Package for Audio Room Simulations and Array Process- ing Algorithms,” inProc. of ICASSP, Calgary, AB, Canada, Apr. 2018, pp. 1–5
work page 2018
-
[41]
ICASSP 2023 Acoustic Echo Cancellation Challenge,
R. Cutler, A. Saabas, T. Parnamaa, M. Purin, E. Indenbom, N.-C. Ristea, J. Guˇzvin, H. Gamper, S. Braun, and R. Aichner, “ICASSP 2023 Acoustic Echo Cancellation Challenge,”arXiv, Sep. 2023
work page 2023
-
[42]
TIMIT Acoustic-Phonetic Con- tinuous Speech Corpus,
J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pal- lett, N. L. Dahlgren, and V . Zue, “TIMIT Acoustic-Phonetic Con- tinuous Speech Corpus,” Linguistic Data Consortium, Philadel- phia, PA, USA, 1993
work page 1993
-
[43]
ETSI,Speech Processing, Transmission and Quality Aspects (STQ); Speech Quality Performance in the Presence of Back- ground Noise; Part 1: Background Noise Simulation Technique and Background Noise Database, European Telecommunications Standards Institute, Sep. 2008, Tech. Rep. ETSI EG 202 396-1
work page 2008
-
[44]
A Binaural Room Impulse Response Database for the Evaluation of Dereverberation Al- gorithms,
M. Jeub, M. Sch ¨afer, and P. Vary, “A Binaural Room Impulse Response Database for the Evaluation of Dereverberation Al- gorithms,” inProc. of Int. Conf. on Digital Signal Processing, Santorini-Hellas, Greece, Jul. 2009, pp. 1–5
work page 2009
-
[45]
The Generalized Correlation Method for Estimation of Time Delay,
C. Knapp and G. Carter, “The Generalized Correlation Method for Estimation of Time Delay,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 24, no. 4, pp. 320–327, Jan. 2003
work page 2003
-
[46]
AEC- MOS: A Speech Quality Assessment Metric for Echo Impair- ment,
M. Purin, S. Sootla, M. Sponza, A. Saabas, and R. Cutler, “AEC- MOS: A Speech Quality Assessment Metric for Echo Impair- ment,” inProc. of ICASSP, Singapore, Singapore, May 2022, pp. 901–905
work page 2022
-
[47]
ITU,Rec. P .862: Perceptual Evaluation of Speech Quality (PESQ), International Telecommunication Union, Telecommuni- cation Standardization Sector (ITU-T), Feb. 2001
work page 2001
-
[48]
Evaluation Metrics for Generative Speech Enhancement Methods: Issues and Perspectives,
J. Pirklbauer, M. Sach, K. Fluyt, W. Tirry, W. Wardah, S. M ¨oller, and T. Fingscheidt, “Evaluation Metrics for Generative Speech Enhancement Methods: Issues and Perspectives,” inProc. of 15th ITG Conference on Speech Communication, Aachen, Germany, Sep. 2023, pp. 265–269
work page 2023
-
[49]
An Algorithm for Predicting the In- telligibility of Speech Masked by Modulated Noise Maskers,
J. Jensen and C. H. Taal, “An Algorithm for Predicting the In- telligibility of Speech Masked by Modulated Noise Maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 24, no. 11, pp. 2009–2022, 2016
work page 2009
-
[50]
P.808 Multilingual Speech Enhancement Testing: Ap- proach and Results of URGENT 2025 Challenge,
M. Sach, Y . Fu, K. Saijo, W. Zhang, S. Cornell, R. Scheibler, C. Li, A. Kumar, W. Wang, Y . Qian, S. Watanabe, and T. Fin- gscheidt, “P.808 Multilingual Speech Enhancement Testing: Ap- proach and Results of URGENT 2025 Challenge,”arXiv, no. 2507.11306, Jul. 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.