Recognition: 2 theorem links
· Lean TheoremNormalization Equivariance for Arbitrary Backbones, with Application to Image Denoising
Pith reviewed 2026-05-15 06:50 UTC · model grok-4.3
The pith
Any neural network becomes exactly normalization-equivariant when wrapped with input normalization followed by output denormalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Every normalization-equivariant function admits an exact factorization consisting of affine normalization of the input, application of an arbitrary backbone, and the corresponding denormalization of the output. The Wrapped Normalization Equivariance wrapper implements this factorization and therefore parameterizes the full class of NE functions. When the wrapper is placed around existing CNN or transformer backbones for blind image denoising, the resulting models exhibit improved robustness to noise-level mismatch between training and test data with no measurable increase in GPU runtime.
What carries the argument
The WNE wrapper, which estimates affine parameters from the input, applies any unmodified backbone, and applies the inverse affine transform to the output; the supporting theorem states that this factorization is necessary and sufficient for normalization equivariance.
If this is right
- Any existing CNN or transformer backbone can be converted into an NE model without altering its layers or attention mechanisms.
- Blind denoising accuracy remains stable when the test noise variance differs from the training variance.
- Runtime cost stays identical to the unmodified backbone, avoiding the slowdowns seen in layer-wise NE constructions.
- Standard components such as softmax attention and LayerNorm become compatible with NE without replacement.
- The same wrapper structure applies to any image-to-image task where input scaling and shifting are the dominant distribution shifts.
Where Pith is reading between the lines
- The factorization suggests that similar input-output wrappers could be designed for other forms of equivariance or invariance without redesigning network layers.
- In deployment, the normalization statistics could be estimated from a small calibration set rather than per-image, potentially extending the method to video or batch settings.
- The approach may reduce the need for task-specific architectural constraints in other robustness problems such as super-resolution under varying illumination.
- If the normalization step is replaced by a learned but still parameter-free estimator, the method could adapt to shifts that are not purely affine.
Load-bearing premise
Affine normalization using global scale and shift parameters will match the distribution shifts that actually occur in the target task, and enforcing exact NE will improve performance on those shifts instead of introducing new artifacts.
What would settle it
A concrete function that satisfies the NE property yet cannot be recovered exactly by any choice of backbone inside the normalize-apply-denoise wrapper, or a blind-denoising experiment where the wrapped model shows no gain or a clear drop in PSNR under noise-level mismatch.
Figures


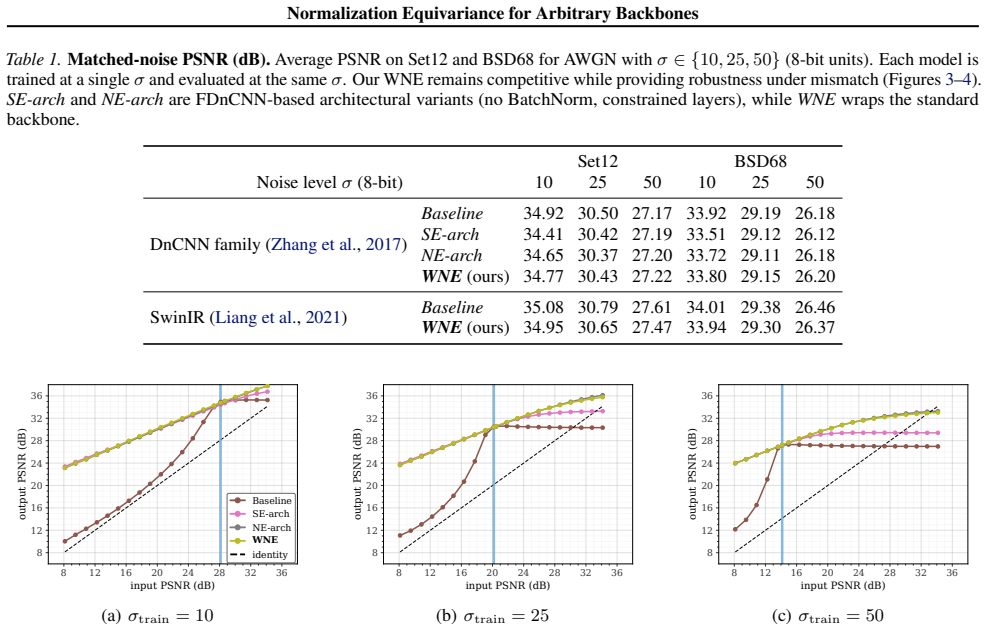

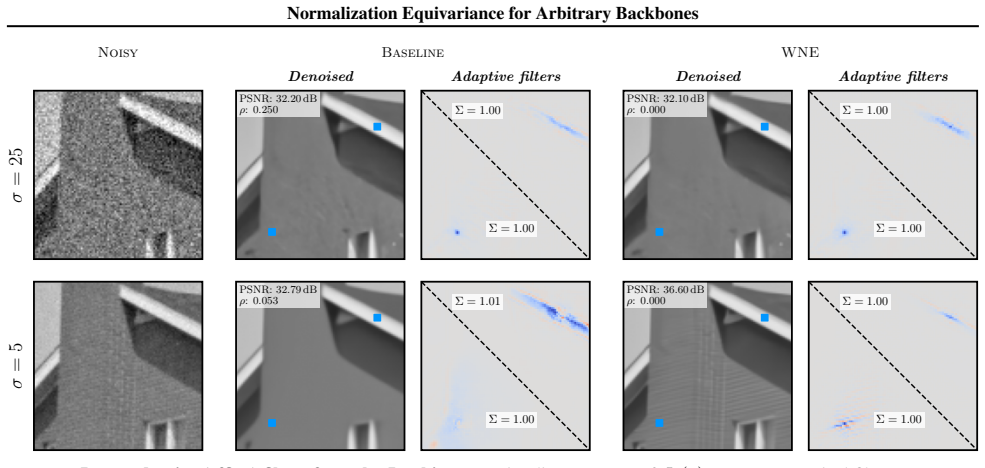













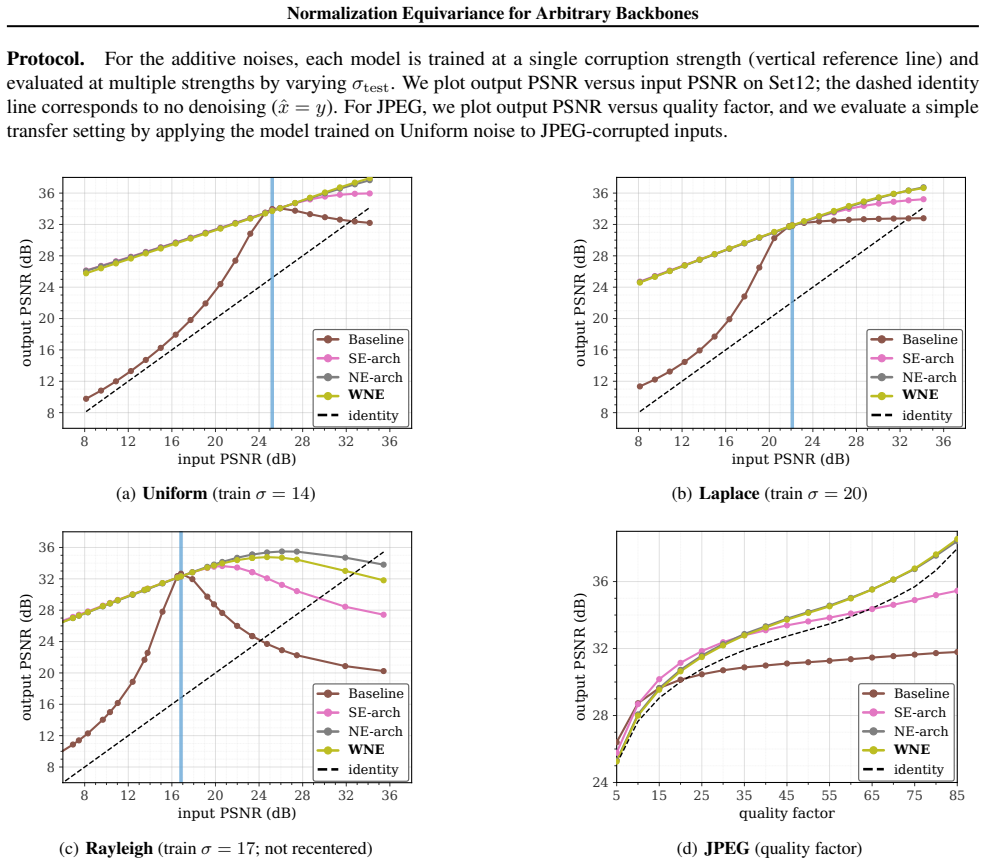
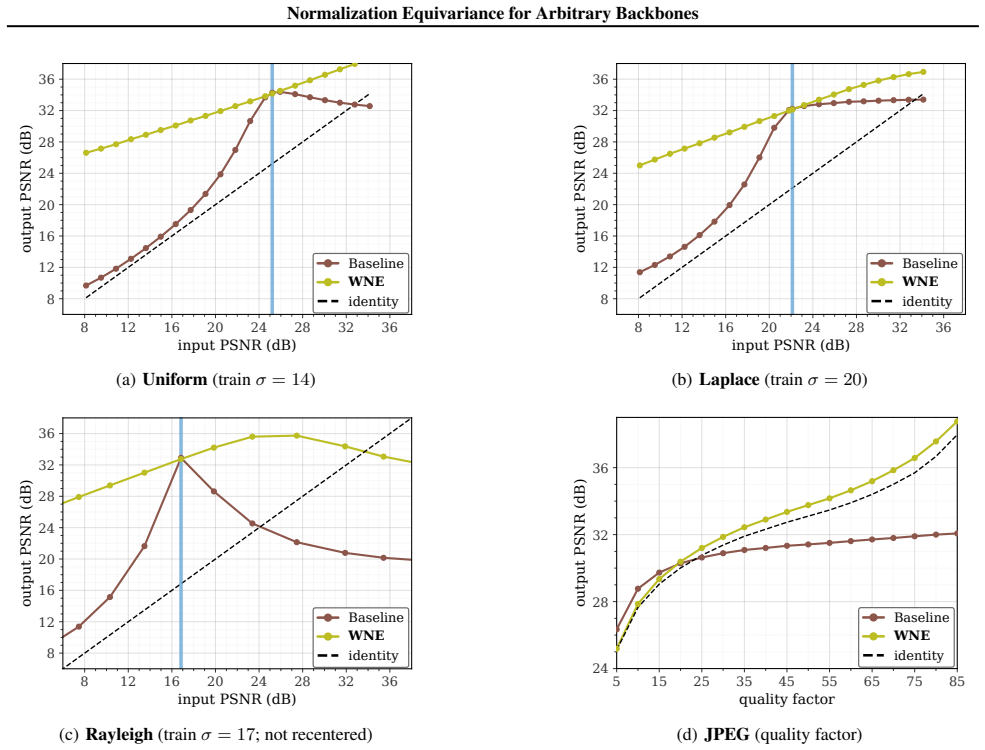
read the original abstract
Normalization Equivariance (NE) is a structural prior that improves robustness to distribution shift in image-to-image tasks. A function $f$ is normalization equivariant iff $f(a y + b\mathbf{1}) = a f(y) + b\mathbf{1}$ for all $a>0$ and $b\in\mathbb{R}$. Existing NE methods constrain every internal layer to NE-compatible operations. These constraints add runtime cost and exclude standard transformer components such as softmax attention and LayerNorm. We introduce Wrapped Normalization Equivariance (WNE), a parameter-free wrapper that normalizes the input, applies any backbone, and denormalizes the output. We prove every NE function admits this factorization, so the wrapper exactly parameterizes the class of NE functions. On blind denoising, wrapping CNN and transformer architectures improves robustness under noise-level mismatch with no measurable GPU overhead, while architectural NE baselines are up to $1.6\times$ slower.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Wrapped Normalization Equivariance (WNE), a parameter-free wrapper that normalizes the input, applies an arbitrary backbone network g, and denormalizes the output to enforce normalization equivariance (NE), defined as f(ay + b1) = a f(y) + b1 for a > 0. It proves that every NE function admits an exact factorization of this form, so the wrapper parameterizes the full class of NE maps. On blind image denoising, WNE-wrapped CNN and transformer backbones improve robustness to noise-level mismatch relative to standard and layer-constrained NE baselines, with no measurable GPU overhead.
Significance. If the factorization proof is correct, the result is significant because it removes the need to redesign internal layers for NE compatibility, thereby allowing standard transformer components (softmax attention, LayerNorm) to be used in NE settings for the first time. The parameter-free construction and exact parameterization are clear strengths. The reported denoising gains under distribution shift, if reproducible, would demonstrate practical utility for robustness in image-to-image tasks without runtime cost.
major comments (2)
- [§3.1] §3.1, the factorization proof: while the forward direction (any g yields an NE map) follows by direct substitution, the converse (every NE f factors exactly through the wrapper) relies on the specific choice of per-image mean/std normalization; the manuscript should explicitly verify that the recovered g is well-defined and independent of the particular affine parameters used in the definition.
- [§4.3] §4.3, Table 3 (blind denoising results): the reported PSNR improvements under noise-level mismatch are shown for a single test noise range; it is unclear whether the gains remain consistent when the mismatch distribution is broadened or when the backbone is trained on a wider noise schedule, which is load-bearing for the robustness claim.
minor comments (3)
- [§2] §2, Eq. (1): the notation b1 for the constant vector should be clarified as b times the all-ones vector to avoid ambiguity with scalar multiplication.
- [Figure 2] Figure 2: the diagram of the WNE wrapper would benefit from an explicit arrow showing the denormalization step and a note that μ, σ are computed from the input only.
- [§4.1] §4.1: the experimental protocol for the architectural NE baselines (which layers are constrained) should be stated more precisely so that the 1.6× slowdown comparison is reproducible.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation for minor revision, and the constructive comments on the factorization and experimental scope. We address each major comment below.
read point-by-point responses
-
Referee: [§3.1] §3.1, the factorization proof: while the forward direction (any g yields an NE map) follows by direct substitution, the converse (every NE f factors exactly through the wrapper) relies on the specific choice of per-image mean/std normalization; the manuscript should explicitly verify that the recovered g is well-defined and independent of the particular affine parameters used in the definition.
Authors: We thank the referee for this observation. In the converse direction of Theorem 1, the recovered backbone is defined by g(z) := [f(σ z + μ 1) − μ 1]/σ, where μ and σ are the per-image mean and standard deviation of the original input y. Because f is assumed to be NE, substituting any other pair (a, b) in place of (σ, μ) yields an identical g; the difference cancels exactly by the equivariance identity. We will insert a short clarifying paragraph immediately after the proof statement in the revised §3.1 that explicitly demonstrates this independence. revision: yes
-
Referee: [§4.3] §4.3, Table 3 (blind denoising results): the reported PSNR improvements under noise-level mismatch are shown for a single test noise range; it is unclear whether the gains remain consistent when the mismatch distribution is broadened or when the backbone is trained on a wider noise schedule, which is load-bearing for the robustness claim.
Authors: We agree that the robustness claim would be strengthened by testing a wider range of mismatch distributions. The single range reported in Table 3 follows the conventional blind-denoising protocol (training on σ ∈ [0, 50], testing on σ ∈ [0, 100]). In the revision we will add a supplementary table containing results for two additional mismatch regimes: (i) training on [0, 25] and testing on [0, 150], and (ii) training on the full [0, 100] schedule and testing on [0, 200]. These will confirm that the WNE gains persist under broadened mismatch. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines Normalization Equivariance directly as the functional equation f(ay + b1) = a f(y) + b1. It then proves that every NE function factors exactly as denormalize ∘ g ∘ normalize. This identity is obtained by direct substitution: normalize the input, apply f to the normalized domain, and recover the output scale and shift; the converse holds by the same substitution. No parameters are fitted, no self-citations are load-bearing for the factorization, and no ansatz or uniqueness theorem is smuggled in. The wrapper is parameter-free and the equivalence is an immediate consequence of the given definition, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A function f is normalization equivariant iff f(a y + b 1) = a f(y) + b 1 for all a > 0 and b real.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean and Foundation/ArithmeticFromLogic.leanwashburn_uniqueness_aczel; embed_injective; embed_eq_pow echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Characterization 1. A function f is normalization-equivariant iff there exists g:M→R^d such that f(y)=std(y)g(TNE(y))+μ(y)1 for std(y)>0 (and f(y)=μ(y)1 when std(y)=0).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection; RCLCombiner_isCoupling_iff refines?
refinesRelation between the paper passage and the cited Recognition theorem.
WNE is parameter-free; it exactly parameterizes the NE class without constraining internal layers.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abdelhamed, A., Lin, S., and Brown, M. S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 1692--1700, 2018
work page 2018
-
[2]
Agustsson, E. and Timofte, R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pp.\ 126--135, 2017
work page 2017
-
[3]
A review of image denoising algorithms, with a new one
Buades, A., Coll, B., and Morel, J.-M. A review of image denoising algorithms, with a new one. Multiscale Modeling & Simulation, 4 0 (2): 0 490--530, 2005
work page 2005
-
[4]
Image denoising by sparse 3-d transform-domain collaborative filtering
Dabov, K., Foi, A., Katkovnik, V., and Egiazarian, K. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Transactions on image processing, 16 0 (8): 0 2080--2095, 2007
work page 2080
-
[5]
Desai, A. D., Ozturkler, B. M., Sandino, C. M., Boutin, R., Willis, M., Vasanawala, S., Hargreaves, B. A., R \'e , C., Pauly, J. M., and Chaudhari, A. S. Noise2Recon : Enabling SNR -robust MRI reconstruction with semi-supervised and self-supervised learning. Magnetic Resonance in Medicine, 90 0 (5): 0 2052--2070, 2023. doi:10.1002/mrm.29759
-
[6]
Weighted nuclear norm minimization with application to image denoising
Gu, S., Zhang, L., Zuo, W., and Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 2862--2869, 2014
work page 2014
-
[7]
Learning normalized image densities via dual score matching
Guth, F., Kadkhodaie, Z., and Simoncelli, E. Learning normalized image densities via dual score matching. In Advances in Neural Information Processing Systems, volume 38, 2025
work page 2025
-
[8]
Hendriksen, A. A., Pelt, D. M., and Batenburg, K. J. Noise2Inverse : Self-supervised deep convolutional denoising for tomography. IEEE Transactions on Computational Imaging, 6: 0 1320--1335, 2020. doi:10.1109/TCI.2020.3019647
-
[10]
Normalization-equivariant neural networks with application to image denoising
Herbreteau, S., Moebel, E., and Kervrann, C. Normalization-equivariant neural networks with application to image denoising. Advances in Neural Information Processing Systems, 36: 0 5706--5728, 2023
work page 2023
-
[11]
Hong, T., Xu, X., Hu, J., and Fessler, J. A. Provable preconditioned plug-and-play approach for compressed sensing MRI reconstruction. IEEE Transactions on Computational Imaging, 10: 0 1476--1488, 2024
work page 2024
-
[12]
Self-supervised deep unrolled reconstruction using regularization by denoising
Huang, P., Zhang, C., Zhang, X., Li, X., Dong, L., and Ying, L. Self-supervised deep unrolled reconstruction using regularization by denoising. IEEE Transactions on Medical Imaging, 43 0 (3): 0 1203--1213, 2024. doi:10.1109/TMI.2023.3332614
-
[13]
Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pp.\ 448--456. PMLR, 2015
work page 2015
-
[14]
K., Zhang, Y., Bengio, Y., and Ravanbakhsh, S
Kaba, S.-O., Mondal, A. K., Zhang, Y., Bengio, Y., and Ravanbakhsh, S. Equivariance with learned canonicalization functions. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 15546--15566. PMLR, 2023. URL https://proceedings.mlr.press/v202/kaba23a.html
work page 2023
-
[15]
Kadkhodaie, Z. and Simoncelli, E. Stochastic solutions for linear inverse problems using the prior implicit in a denoiser. Advances in Neural Information Processing Systems, 34: 0 13242--13254, 2021
work page 2021
-
[16]
Kadkhodaie, Z., Guth, F., Simoncelli, E. P., and Mallat, S. Generalization in diffusion models arises from geometry-adaptive harmonic representations. In International Conference on Learning Representations, 2024
work page 2024
-
[17]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Kim, T., Kim, J., Tae, Y., Park, C., Choi, J.-H., and Choo, J. Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=cGDAkQo1C0p
work page 2022
-
[18]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015
work page 2015
-
[19]
Noise2Noise : Learning image restoration without clean data
Lehtinen, J., Munkberg, J., Hasselgren, J., Laine, S., Karras, T., Aittala, M., and Aila, T. Noise2Noise : Learning image restoration without clean data. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 2971--2980. PMLR, 2018
work page 2018
-
[21]
SwinIR : Image restoration using Swin transformer
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., and Timofte, R. SwinIR : Image restoration using Swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pp.\ 1833--1844, 2021
work page 2021
-
[22]
Lim, B., Son, S., Kim, H., Nah, S., and Lee, K. M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pp.\ 136--144, 2017
work page 2017
-
[23]
Liu, J., Sun, Y., Eldeniz, C., Gan, W., An, H., and Kamilov, U. S. RARE : Image reconstruction using deep priors learned without groundtruth. IEEE Journal of Selected Topics in Signal Processing, 14 0 (6): 0 1088--1099, 2020. doi:10.1109/JSTSP.2020.2998402
-
[24]
Non-stationary transformers: Exploring the stationarity in time series forecasting
Liu, Y., Wu, H., Wang, J., and Long, M. Non-stationary transformers: Exploring the stationarity in time series forecasting. Advances in Neural Information Processing Systems, 35: 0 9881--9893, 2022
work page 2022
-
[25]
Swin transformer: Hierarchical vision transformer using shifted windows
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pp.\ 10012--10022, 2021
work page 2021
-
[26]
Waterloo exploration database: New challenges for image quality assessment models
Ma, K., Duanmu, Z., Wu, Q., Wang, Z., Yong, H., Li, H., and Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Transactions on Image Processing, 26 0 (2): 0 1004--1016, 2017
work page 2017
-
[27]
Martin, D., Fowlkes, C., Tal, D., and Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision , volume 2, pp.\ 416--423. IEEE, 2001
work page 2001
-
[28]
Mohan, S., Kadkhodaie, Z., Simoncelli, E. P., and Fernandez-Granda, C. Robust and interpretable blind image denoising via bias-free convolutional neural networks. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HJlSmC4FPS
work page 2020
-
[29]
Mondal, A. K., Panigrahi, S. S., Kaba, O., Rajeswar Mudumba, S., and Ravanbakhsh, S. Equivariant adaptation of large pretrained models. In Advances in Neural Information Processing Systems, volume 36, pp.\ 50293--50309. Curran Associates, Inc., 2023
work page 2023
-
[30]
PyTorch : An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. PyTorch : An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32: 0 8026--8037, 2019
work page 2019
-
[31]
Rudin, L. I., Osher, S., and Fatemi, E. Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena, 60 0 (1--4): 0 259--268, 1992
work page 1992
-
[33]
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13 0 (4): 0 600--612, 2004
work page 2004
-
[34]
W., Arora, A., Khan, S., Hayat, M., Khan, F
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S., and Yang, M.-H. Restormer : Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 5728--5739, 2022
work page 2022
-
[35]
Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising
Zhang, K., Zuo, W., Chen, Y., Meng, D., and Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Transactions on Image Processing, 26 0 (7): 0 3142--3155, 2017
work page 2017
-
[36]
Plug-and-play image restoration with deep denoiser prior
Zhang, K., Li, Y., Zuo, W., Zhang, L., Van Gool, L., and Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 0 (10): 0 6360--6376, 2022
work page 2022
-
[37]
Instance Normalization: The Missing Ingredient for Fast Stylization
Instance Normalization: The Missing Ingredient for Fast Stylization , author =. arXiv preprint arXiv:1607.08022 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in Neural Information Processing Systems , volume =
Normalization-Equivariant Neural Networks with Application to Image Denoising , author =. Advances in Neural Information Processing Systems , volume =
-
[39]
Mutual Information and Minimum Mean-Square Error in
Guo, Dongning and Shamai, Shlomo and Verd. Mutual Information and Minimum Mean-Square Error in. IEEE Transactions on Information Theory , volume =. 2005 , publisher =
work page 2005
-
[40]
Lehtinen, Jaakko and Munkberg, Jacob and Hasselgren, Jon and Laine, Samuli and Karras, Tero and Aittala, Miika and Aila, Timo , booktitle =. 2018 , publisher =
work page 2018
-
[41]
Hendriksen, Allard A. and Pelt, Dani. IEEE Transactions on Computational Imaging , volume =. 2020 , doi =
work page 2020
-
[42]
Desai, Arjun D. and Ozturkler, Batu M. and Sandino, Christopher M. and Boutin, Robert and Willis, Marc and Vasanawala, Shreyas and Hargreaves, Brian A. and R. Magnetic Resonance in Medicine , volume =. 2023 , doi =
work page 2023
-
[43]
Liu, Jiaming and Sun, Yu and Eldeniz, Cihat and Gan, Weijie and An, Hongyu and Kamilov, Ulugbek S. , journal =. 2020 , doi =
work page 2020
-
[44]
IEEE Transactions on Medical Imaging , volume =
Self-Supervised Deep Unrolled Reconstruction Using Regularization by Denoising , author =. IEEE Transactions on Medical Imaging , volume =. 2024 , doi =
work page 2024
-
[45]
Proceedings of the 40th International Conference on Machine Learning , series =
Equivariance with Learned Canonicalization Functions , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
work page 2023
-
[46]
Advances in Neural Information Processing Systems , volume =
Equivariant Adaptation of Large Pretrained Models , author =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
work page 2023
-
[47]
Proceedings of the 36th International Conference on Machine Learning , series =
Batson, Joshua and Royer, Lo. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
work page 2019
-
[48]
Krull, Alexander and Buchholz, Tim-Oliver and Jug, Florian , booktitle =
-
[49]
Zhang, Kai and Zuo, Wangmeng and Zhang, Lei , journal =
-
[50]
Network: Computation in Neural Systems , volume =
The Statistics of Natural Images , author =. Network: Computation in Neural Systems , volume =. 1994 , publisher =
work page 1994
-
[51]
International Conference on Learning Representations , year =
Robust and Interpretable Blind Image Denoising via Bias-Free Convolutional Neural Networks , author =. International Conference on Learning Representations , year =
-
[52]
Towards Robust Image Denoising with Scale Equivariance , author =. 2025 , eprint =
work page 2025
-
[53]
arXiv preprint arXiv:2402.15352 , year =
On normalization-equivariance properties of supervised and unsupervised denoising methods: a survey , author =. arXiv preprint arXiv:2402.15352 , year =
-
[54]
Understanding Generalizability of Diffusion Models Requires Rethinking the Hidden
Li, Xiang and Dai, Yixiang and Qu, Qing , year =. Understanding Generalizability of Diffusion Models Requires Rethinking the Hidden. 2410.24060 , archiveprefix =
-
[55]
Score-Based Generative Models Learn Manifold-Like Structures with Constrained Mixing , author =. 2023 , eprint =
work page 2023
-
[56]
Advances in Neural Information Processing Systems , volume =
Improved Techniques for Training Score-Based Generative Models , author =. Advances in Neural Information Processing Systems , volume =
-
[57]
Diffusion Models as Cartoonists! The Curious Case of High Density Regions , author =. 2024 , eprint =
work page 2024
-
[58]
Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu , booktitle =
- [59]
-
[60]
Zhang, Kai and Zuo, Wangmeng and Gu, Shuhang and Zhang, Lei , booktitle =. Learning Deep
- [61]
-
[62]
Multiscale Modeling & Simulation , volume =
A Review of Image Denoising Algorithms, with a New One , author =. Multiscale Modeling & Simulation , volume =
-
[63]
Physica D: Nonlinear Phenomena , volume =
Nonlinear Total Variation Based Noise Removal Algorithms , author =. Physica D: Nonlinear Phenomena , volume =
-
[64]
International Conference on Learning Representations , year =
Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift , author =. International Conference on Learning Representations , year =
-
[65]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Plug-and-Play Image Restoration with Deep Denoiser Prior , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , publisher =
work page 2022
-
[66]
Proceedings of the 32nd International Conference on Machine Learning , series =
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , author =. Proceedings of the 32nd International Conference on Machine Learning , series =. 2015 , publisher =
work page 2015
-
[67]
Deep Residual Learning for Image Recognition , author =. Proceedings of the
-
[68]
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and others , journal =
-
[69]
A Database of Human Segmented Natural Images and Its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics , author =. Proceedings of the Eighth. 2001 , organization =
work page 2001
-
[70]
IEEE Transactions on Image Processing , volume =
Waterloo Exploration Database: New Challenges for Image Quality Assessment Models , author =. IEEE Transactions on Image Processing , volume =. 2017 , publisher =
work page 2017
-
[71]
Agustsson, Eirikur and Timofte, Radu , booktitle =
-
[72]
Enhanced Deep Residual Networks for Single Image Super-Resolution , author =. Proceedings of the
-
[73]
International Conference on Learning Representations , year =
Adam: A Method for Stochastic Optimization , author =. International Conference on Learning Representations , year =
-
[74]
Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining , booktitle =
-
[75]
Advances in Neural Information Processing Systems , volume =
Non-Stationary Transformers: Exploring the Stationarity in Time Series Forecasting , author =. Advances in Neural Information Processing Systems , volume =
-
[76]
Provable Preconditioned Plug-and-Play Approach for Compressed Sensing
Hong, Tao and Xu, Xiaojian and Hu, Jason and Fessler, Jeffrey A , journal =. Provable Preconditioned Plug-and-Play Approach for Compressed Sensing. 2024 , publisher =
work page 2024
-
[77]
Zamir, Syed Waqas and Arora, Aditya and Khan, Salman and Hayat, Munawar and Khan, Fahad Shahbaz and Yang, Ming-Hsuan , booktitle =
-
[78]
Advances in Neural Information Processing Systems , volume =
Stochastic Solutions for Linear Inverse Problems Using the Prior Implicit in a Denoiser , author =. Advances in Neural Information Processing Systems , volume =
-
[79]
SIAM Journal on Imaging Sciences , volume =
Image Denoising: The Deep Learning Revolution and Beyond---A Survey Paper , author =. SIAM Journal on Imaging Sciences , volume =. 2023 , doi =
work page 2023
-
[80]
Advances in Neural Information Processing Systems , volume =
Normalize Filters! Classical Wisdom for Deep Vision , author =. Advances in Neural Information Processing Systems , volume =
-
[81]
arXiv preprint arXiv:2510.11964 , year =
Normalization-Equivariant Diffusion Models: Learning Posterior Samplers From Noisy And Partial Measurements , author =. arXiv preprint arXiv:2510.11964 , year =
-
[82]
Advances in Neural Information Processing Systems , volume =
Learning Normalized Image Densities via Dual Score Matching , author =. Advances in Neural Information Processing Systems , volume =
-
[83]
International Conference on Learning Representations , year =
Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representations , author =. International Conference on Learning Representations , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.