Recognition: 2 theorem links
· Lean TheoremBeyond Penalization: Diffusion-based Out-of-Distribution Detection and Selective Regularization in Offline Reinforcement Learning
Pith reviewed 2026-05-12 02:09 UTC · model grok-4.3
The pith
Diffusion models detect out-of-distribution actions in offline RL and selectively regularize them instead of applying uniform penalties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
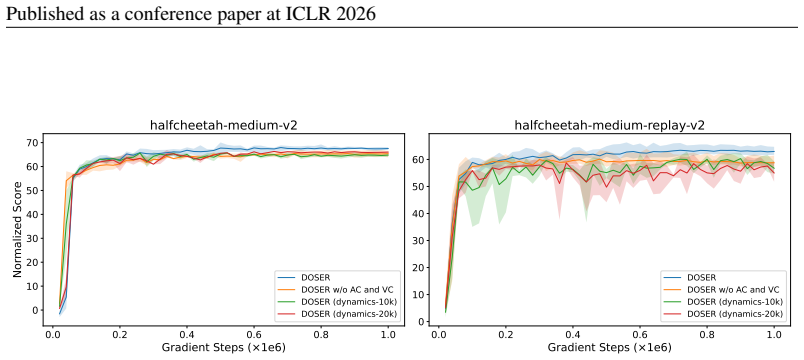
DOSER trains two diffusion models to capture the behavior policy and state distribution, using single-step denoising reconstruction error as a reliable OOD indicator. During policy optimization, it distinguishes between beneficial and detrimental OOD actions by evaluating predicted transitions, selectively suppressing risky actions while encouraging exploration of high-potential ones. It proves that DOSER is a gamma-contraction admitting a unique fixed point with bounded value estimates and provides an asymptotic performance guarantee relative to the optimal policy under model approximation and OOD detection errors.
What carries the argument
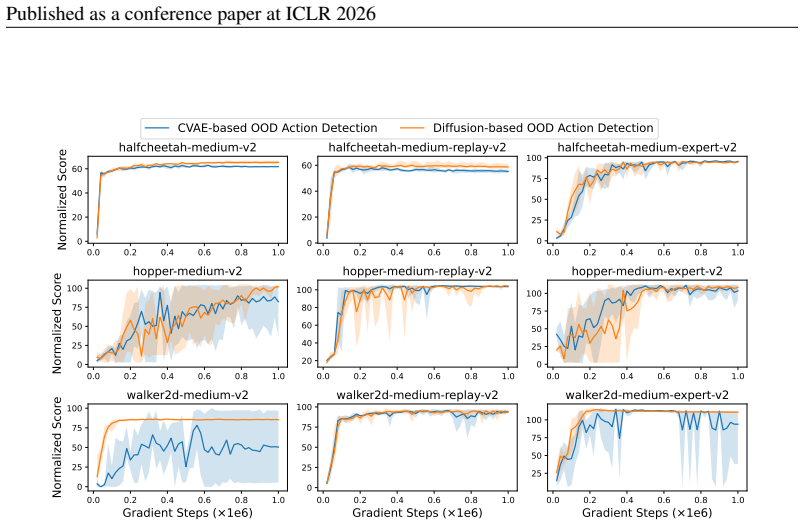
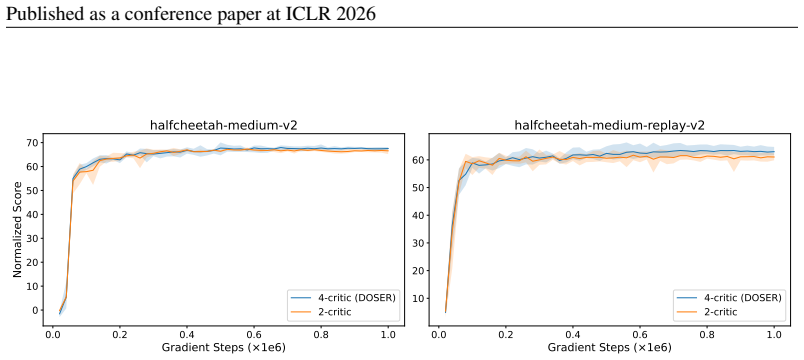
The DOSER framework: dual diffusion models combined with single-step denoising reconstruction error for OOD detection and transition evaluation for selective regularization during policy updates.
If this is right
- DOSER is a gamma-contraction and therefore admits a unique fixed point with bounded value estimates.
- An asymptotic performance guarantee holds relative to the optimal policy under bounded model approximation and OOD detection errors.
- The method attains higher returns than prior penalization approaches across extensive offline RL benchmarks.
- Gains are largest on suboptimal datasets where uniform penalization overly restricts exploration.
Where Pith is reading between the lines
- The selective mechanism may allow offline policies to exploit limited data more effectively than purely conservative methods.
- The diffusion-based OOD signal could be adapted to detect distribution shifts in other sequential decision problems.
- Combining the selective regularization with model-based planning might further improve sample efficiency in low-data regimes.
Load-bearing premise
The single-step denoising reconstruction error accurately identifies OOD actions and that evaluating predicted transitions can reliably separate beneficial from detrimental OOD actions without introducing new errors that break the contraction or performance bounds.
What would settle it
A benchmark run or controlled experiment in which the denoising reconstruction error shows no reliable correlation with actual out-of-distribution status, or in which DOSER produces lower returns than uniform penalization baselines on standard offline RL datasets.
Figures










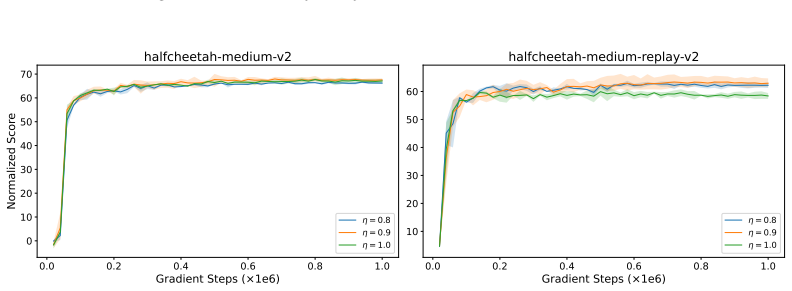

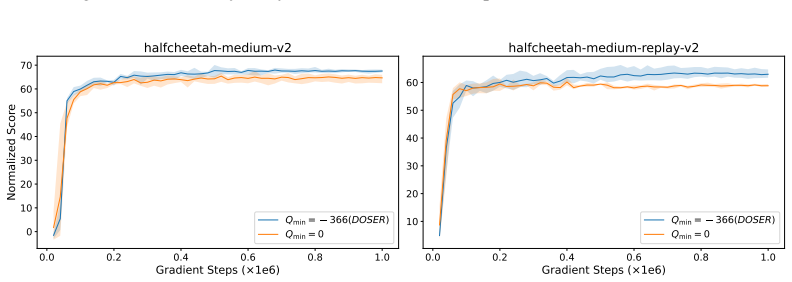
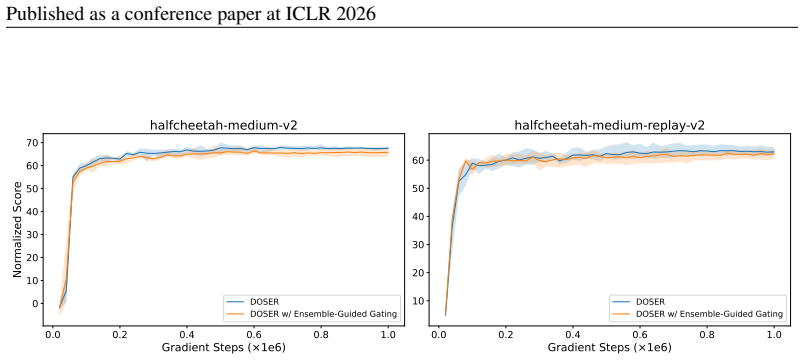




read the original abstract
Offline reinforcement learning (RL) faces a critical challenge of overestimating the value of out-of-distribution (OOD) actions. Existing methods mitigate this issue by penalizing unseen samples, yet they fail to accurately identify OOD actions and may suppress beneficial exploration beyond the behavioral support. Although several methods have been proposed to differentiate OOD samples with distinct properties, they typically rely on restrictive assumptions about the data distribution and remain limited in discrimination ability. To address this problem, we propose DOSER (Diffusion-based OOD Detection and Selective Regularization), a novel framework that goes beyond uniform penalization. DOSER trains two diffusion models to capture the behavior policy and state distribution, using single-step denoising reconstruction error as a reliable OOD indicator. During policy optimization, it further distinguishes between beneficial and detrimental OOD actions by evaluating predicted transitions, selectively suppressing risky actions while encouraging exploration of high-potential ones. Theoretically, we prove that DOSER is a $\gamma$-contraction and therefore admits a unique fixed point with bounded value estimates. We further provide an asymptotic performance guarantee relative to the optimal policy under model approximation and OOD detection errors. Across extensive offline RL benchmarks, DOSER consistently attains superior performance to prior methods, especially on suboptimal datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DOSER, a framework for offline RL that trains two diffusion models (one for the behavior policy and one for the state distribution) and uses single-step denoising reconstruction error as an OOD indicator. During optimization, it evaluates predicted transitions to classify OOD actions as beneficial or detrimental, selectively suppressing risky actions while encouraging high-potential ones. The central claims are that the resulting operator is a γ-contraction (hence has a unique fixed point with bounded values) and that an asymptotic performance guarantee holds relative to the optimal policy under model approximation and OOD detection errors; empirically, DOSER outperforms prior methods on offline RL benchmarks, especially suboptimal datasets.
Significance. If the contraction and performance guarantees hold with the stated error bounds, DOSER would offer a substantive improvement over uniform penalization approaches by allowing controlled exploration of beneficial OOD actions. The diffusion-based OOD detection and selective regularization are technically novel for the offline RL setting and could be impactful on datasets with partial coverage. The empirical superiority claim, if supported by ablations and quantitative results, would strengthen the case for moving beyond simple conservatism.
major comments (2)
- [Abstract and theoretical analysis] Abstract and theoretical analysis section: The claim that DOSER defines a γ-contraction (and therefore admits a unique fixed point) requires that the selective regularization term—driven by single-step denoising reconstruction errors and predicted-transition evaluations—does not increase the Lipschitz constant beyond γ. The manuscript does not appear to derive an explicit bound showing that misclassification errors from the single-step proxy (which can be coarse in multimodal or high-dimensional spaces) are absorbed within the original contraction factor; without this, the perturbation remains uncontrolled even under the paper's stated model/OOD error assumptions. This is load-bearing for both the fixed-point existence and the asymptotic guarantee.
- [Theoretical analysis] Theoretical analysis section (performance guarantee): The asymptotic guarantee relative to the optimal policy is stated to hold under model approximation and OOD detection errors, but the derivation appears to treat the selective term's effect on value estimates as bounded without showing how the sign-dependent regularization (suppress vs. encourage) interacts with the error terms. If the OOD indicator can flip the sign of the perturbation on a non-negligible fraction of actions, the guarantee may not follow from standard error-propagation arguments.
minor comments (2)
- [Abstract] The abstract asserts 'superior performance' and 'extensive benchmarks' but provides no quantitative deltas, dataset list, or ablation controls; these details should be summarized with effect sizes and statistical significance to allow readers to assess the strength of the empirical claim.
- [Method and notation] Notation for the two diffusion models and the precise definition of the selective regularization operator (including how predicted transitions are computed and thresholded) should be introduced earlier and used consistently in the method and theory sections to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of DOSER's selective regularization over uniform penalization. We address the two major comments on the theoretical analysis below, providing clarifications from the manuscript and indicating where revisions will strengthen the exposition.
read point-by-point responses
-
Referee: The claim that DOSER defines a γ-contraction (and therefore admits a unique fixed point) requires that the selective regularization term—driven by single-step denoising reconstruction errors and predicted-transition evaluations—does not increase the Lipschitz constant beyond γ. The manuscript does not appear to derive an explicit bound showing that misclassification errors from the single-step proxy (which can be coarse in multimodal or high-dimensional spaces) are absorbed within the original contraction factor; without this, the perturbation remains uncontrolled even under the paper's stated model/OOD error assumptions.
Authors: We appreciate the referee's careful scrutiny of the contraction proof. The theoretical analysis shows that the selective regularization term contributes a perturbation whose sup-norm is bounded by the OOD detection error ε (via the single-step denoising reconstruction error and transition prediction). Under the paper's assumptions, this perturbation is absorbed such that the composite operator remains a γ-contraction when ε < (1-γ)/2, following standard arguments for approximate Bellman operators. To make the absorption of misclassification errors explicit—particularly for the single-step proxy in multimodal settings—we will add a supporting lemma deriving the Lipschitz bound on the selective term and its dependence on the stated error assumptions. revision: partial
-
Referee: The asymptotic guarantee relative to the optimal policy is stated to hold under model approximation and OOD detection errors, but the derivation appears to treat the selective term's effect on value estimates as bounded without showing how the sign-dependent regularization (suppress vs. encourage) interacts with the error terms. If the OOD indicator can flip the sign of the perturbation on a non-negligible fraction of actions, the guarantee may not follow from standard error-propagation arguments.
Authors: We agree that the interaction of sign-dependent regularization with error terms merits clearer derivation. The performance guarantee proof bounds the total perturbation via the triangle inequality after separating beneficial (encouraged) and detrimental (suppressed) OOD actions, with the sign determined by the predicted-transition evaluation whose accuracy is controlled by the model approximation error. The regularization magnitude is scaled by the denoising error, limiting the effect of any sign flips. We will revise the proof to insert an intermediate step explicitly showing that the propagated error remains O(ε + δ) (where δ is the OOD detection error) without the sign dependence invalidating the bound. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper trains diffusion models on behavior policy and state distribution data, defines an OOD indicator via single-step denoising error, applies selective regularization during policy optimization, and then proves the resulting operator is a γ-contraction with unique fixed point plus an asymptotic guarantee expressed in terms of model and detection errors. These steps follow standard RL contraction arguments once the operator is explicitly defined; the error terms are treated as exogenous bounds rather than quantities fitted inside the same equations. No self-definitional reduction, fitted input renamed as prediction, or load-bearing self-citation chain appears in the abstract or claimed theoretical results. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
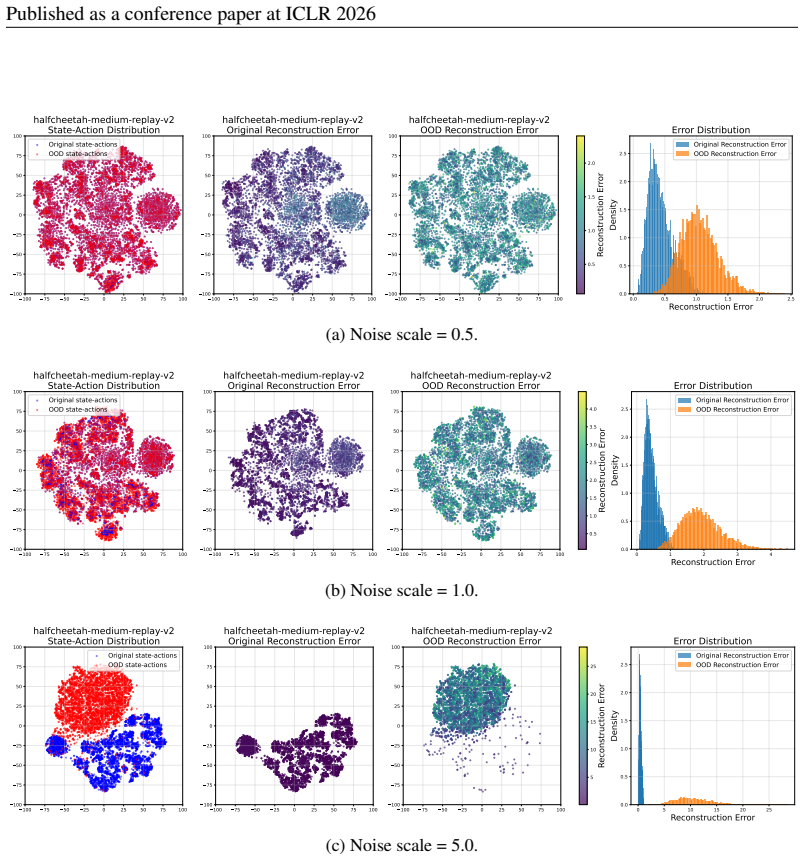
- domain assumption Diffusion models trained on the behavior policy and state distribution yield a single-step denoising reconstruction error that reliably flags OOD actions.
- domain assumption Evaluating the predicted next state under an OOD action can distinguish beneficial from detrimental actions without introducing errors that break the contraction property.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 1 (Contraction mapping property). ... ||T_DOSER Q1 − T_DOSER Q2||_∞ ≤ γ||Q1 − Q2||_∞. By the Banach fixed-point theorem...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearusing single-step denoising reconstruction error as a reliable OOD indicator
Reference graph
Works this paper leans on
-
[1]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
International conference on machine learning , pages=
Off-policy deep reinforcement learning without exploration , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[3]
Advances in neural information processing systems , volume=
Stabilizing off-policy q-learning via bootstrapping error reduction , author=. Advances in neural information processing systems , volume=
-
[4]
Behavior Regularized Offline Reinforcement Learning
Behavior regularized offline reinforcement learning , author=. arXiv preprint arXiv:1911.11361 , year=
work page internal anchor Pith review arXiv 1911
-
[5]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[6]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
work page internal anchor Pith review arXiv
-
[7]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Diffusion policies as an expressive policy class for offline reinforcement learning , author=. arXiv preprint arXiv:2208.06193 , year=
-
[9]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[10]
arXiv preprint arXiv:2105.08140 , year=
Uncertainty weighted actor-critic for offline reinforcement learning , author=. arXiv preprint arXiv:2105.08140 , year=
-
[11]
arXiv preprint arXiv:2202.11566 , year=
Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning , author=. arXiv preprint arXiv:2202.11566 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Supported value regularization for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2212.04607 , year=
Confidence-conditioned value functions for offline reinforcement learning , author=. arXiv preprint arXiv:2212.04607 , year=
-
[14]
IEEE Transactions on Neural Networks and Learning Systems , year=
De-Pessimism Offline Reinforcement Learning via Value Compensation , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[15]
IEEE Transactions on Neural Networks and Learning Systems , year=
ACL-QL: Adaptive Conservative Level in Q -Learning for Offline Reinforcement Learning , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[16]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[17]
Reinforcement learning: State-of-the-art , pages=
Batch reinforcement learning , author=. Reinforcement learning: State-of-the-art , pages=. 2012 , publisher=
work page 2012
-
[18]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[19]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[20]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[22]
A connection between score matching and denoising autoencoders , author=. Neural computation , volume=. 2011 , publisher=
work page 2011
-
[23]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
work page internal anchor Pith review arXiv
-
[24]
International Conference on Machine Learning , pages=
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[25]
Offline reinforcement learning via high-fidelity generative behavior modeling
Offline reinforcement learning via high-fidelity generative behavior modeling , author=. arXiv preprint arXiv:2209.14548 , year=
-
[26]
arXiv preprint arXiv:2310.07297 , year=
Score regularized policy optimization through diffusion behavior , author=. arXiv preprint arXiv:2310.07297 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Diffusion policies creating a trust region for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review arXiv 2004
-
[29]
Advances in neural information processing systems , volume=
Likelihood ratios for out-of-distribution detection , author=. Advances in neural information processing systems , volume=
-
[30]
Advances in neural information processing systems , volume=
Glow: Generative flow with invertible 1x1 convolutions , author=. Advances in neural information processing systems , volume=
-
[31]
Deep anomaly detection with outlier exposure.arXiv preprint arXiv:1812.04606, 2018
Deep anomaly detection with outlier exposure , author=. arXiv preprint arXiv:1812.04606 , year=
-
[32]
Do Deep Generative Models Know What They Don't Know?
Do deep generative models know what they don't know? , author=. arXiv preprint arXiv:1810.09136 , year=
-
[33]
arXiv preprint arXiv:1909.11480 , year=
Input complexity and out-of-distribution detection with likelihood-based generative models , author=. arXiv preprint arXiv:1909.11480 , year=
-
[34]
Detecting out-of-distribution inputs to deep generative models using typicality , author=. arXiv preprint arXiv:1906.02994 , year=
-
[35]
arXiv preprint arXiv:1812.02765 (2018)
Improving reconstruction autoencoder out-of-distribution detection with mahalanobis distance , author=. arXiv preprint arXiv:1812.02765 , year=
-
[36]
International conference on learning representations , year=
Deep autoencoding gaussian mixture model for unsupervised anomaly detection , author=. International conference on learning representations , year=
-
[37]
Outlier detection using autoencoders , author=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Denoising diffusion models for out-of-distribution detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
arXiv preprint arXiv:2412.03258 , year=
Learning on one mode: Addressing multi-modality in offline reinforcement learning , author=. arXiv preprint arXiv:2412.03258 , year=
-
[40]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[41]
Advances in Neural Information Processing Systems , volume=
Mopo: Model-based offline policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DARL: distance-aware uncertainty estimation for offline reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[44]
arXiv preprint arXiv:2405.20555 , year=
Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning , author=. arXiv preprint arXiv:2405.20555 , year=
-
[45]
Adam: A Method for Stochastic Optimization
A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
SGDR: Stochastic Gradient Descent with Warm Restarts
Sgdr: Stochastic gradient descent with warm restarts , author=. arXiv preprint arXiv:1608.03983 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [47]
-
[48]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications , author=. arXiv preprint arXiv:1812.05905 , year=
work page internal anchor Pith review arXiv
-
[49]
Proceedings 2001 international conference on image processing (Cat
One-class SVM for learning in image retrieval , author=. Proceedings 2001 international conference on image processing (Cat. No. 01CH37205) , volume=. 2001 , organization=
work page 2001
-
[50]
International conference on machine learning , pages=
Is pessimism provably efficient for offline rl? , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[51]
International conference on machine learning , pages=
Deep structured energy based models for anomaly detection , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[52]
arXiv preprint arXiv:2005.02359 , year=
Classification-based anomaly detection for general data , author=. arXiv preprint arXiv:2005.02359 , year=
-
[53]
Regularisation of neural networks by enforcing lipschitz continuity , author=. Machine Learning , volume=. 2021 , publisher=
work page 2021
-
[54]
SIAM Journal on Control and Optimization , volume=
Finite linear programming approximations of constrained discounted Markov decision processes , author=. SIAM Journal on Control and Optimization , volume=. 2013 , publisher=
work page 2013
-
[55]
Uncertainty in Artificial Intelligence , pages=
Deterministic policy gradient: Convergence analysis , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
work page 2022
-
[56]
International conference on machine learning , pages=
Policy regularization with dataset constraint for offline reinforcement learning , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[57]
arXiv preprint arXiv:2405.19909 , year=
Adaptive advantage-guided policy regularization for offline reinforcement learning , author=. arXiv preprint arXiv:2405.19909 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.