Recognition: no theorem link
NoisyCoconut: Counterfactual Consensus via Latent Space Reasoning
Pith reviewed 2026-05-12 00:45 UTC · model grok-4.3
The pith
Adding controlled noise to an LLM's internal states during reasoning creates multiple paths whose unanimous agreement signals trustworthy answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
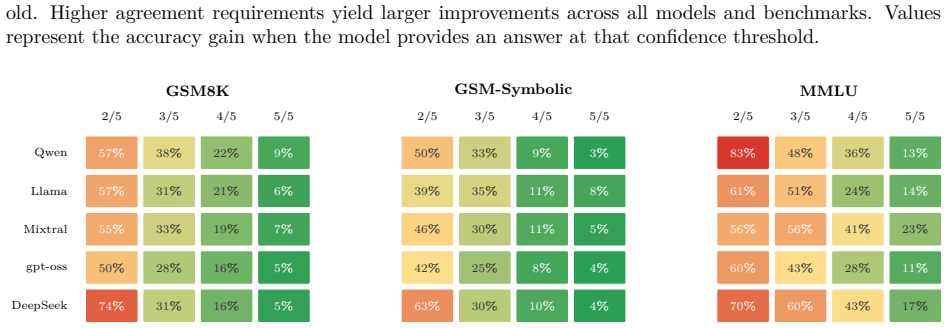
By perturbing latent representations to generate counterfactual reasoning paths and requiring unanimous agreement among them, the approach supplies a practical confidence signal that lets models abstain selectively, sharply reducing errors on reasoning tasks while preserving compatibility with existing LLMs.
What carries the argument
Controlled noise injection into latent trajectories that produces multiple diverse reasoning paths whose agreement acts as a correctness indicator.
If this is right
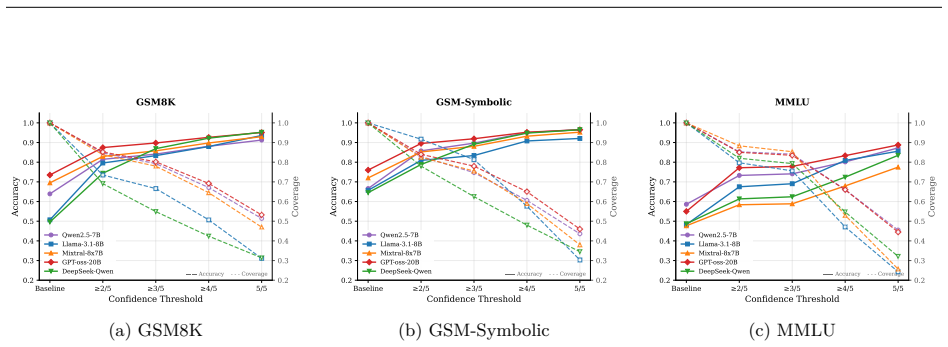
- Selective abstention can raise accuracy above 95 percent on mathematical reasoning benchmarks while keeping coverage useful.
- The method requires no retraining and works on any existing model whose internal states are accessible.
- It produces measurable coverage-accuracy tradeoffs across multiple reasoning benchmarks without access to training data.
- Error rates fall from 40-70 percent to below 15 percent when only unanimous paths are accepted.
Where Pith is reading between the lines
- The same noise-based consensus idea could be tested on code generation or factual question answering to see whether agreement still tracks correctness.
- Combining the abstention signal with other inference-time techniques might further improve reliability without additional training.
- If the noise levels can be tuned automatically per question type, the method could adapt coverage dynamically across different domains.
Load-bearing premise
The injected noise must create sufficiently independent paths so that agreement reflects genuine correctness rather than shared mistakes across all paths.
What would settle it
A test set where many questions receive unanimous agreement across noise-perturbed paths yet the agreed answer is incorrect would falsify the reliability of the consensus signal.
Figures



read the original abstract
This paper presents NoisyCoconut, a novel inference-time method that enhances large language model (LLM) reliability by manipulating internal representations. Unlike fine-tuning methods that require extensive retraining, NoisyCoconut operates directly on model representations during inference and requires no retraining. Rather than training models to reason in latent space, we inject controlled noise into latent trajectories to generate diverse reasoning paths. Agreement among these paths provides a confidence signal, enabling models to abstain when uncertain. We demonstrate that this approach achieves effective coverage-accuracy tradeoffs across multiple reasoning benchmarks without requiring access to training data or modification of model parameters. This approach provides a practical pathway to improving the reliability of LLM outputs while maintaining compatibility with existing models. Our experiments show that unanimous agreement among noise-perturbed paths reduces error rates from 40-70% to below 15%, enabling models to exceed 95% accuracy on mathematical reasoning tasks through selective abstention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NoisyCoconut, an inference-time technique that injects controlled noise into LLM latent trajectories to generate multiple diverse reasoning paths. Unanimous agreement among these paths is used as a confidence signal to enable selective abstention on uncertain queries. The central empirical claim is that this reduces error rates from 40-70% to below 15% and allows models to exceed 95% accuracy on mathematical reasoning tasks, all without retraining, parameter changes, or access to training data.
Significance. If the reported gains hold under proper controls, the method would offer a practical, training-free approach to uncertainty estimation that is compatible with existing models. The use of latent-space noise for counterfactual consensus is a distinct direction from temperature sampling or ensemble methods and could complement other reliability techniques, though its value depends entirely on whether the perturbed paths are sufficiently independent.
major comments (2)
- [Abstract] Abstract: the headline performance numbers (error reduction from 40-70% to <15%, accuracy >95%) are presented with no reference to specific benchmarks, baseline comparisons, number of runs, noise-level selection procedure, or statistical controls. Without these details the central claim cannot be evaluated.
- [Method] Method description: no diagnostic, ablation, or analysis is supplied to verify that noise injection produces decorrelated reasoning traces rather than correlated paths that share the model's systematic biases. If the latter occurs, unanimous agreement would not reliably indicate correctness and the selective-abstention benefit would not materialize.
minor comments (1)
- Notation for the original versus noise-perturbed latent trajectories should be made explicit and consistent throughout.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance numbers (error reduction from 40-70% to <15%, accuracy >95%) are presented with no reference to specific benchmarks, baseline comparisons, number of runs, noise-level selection procedure, or statistical controls. Without these details the central claim cannot be evaluated.
Authors: We agree that the abstract would be stronger with additional context. The body of the manuscript already specifies the benchmarks (GSM8K and MATH), baseline comparisons to temperature sampling and greedy decoding, the use of 5 independent runs with different seeds, noise-level selection via grid search on a validation split, and reporting of means with standard deviations. In revision we will condense these elements into the abstract while respecting length limits, for example by adding a parenthetical note on benchmarks and trial count. revision: yes
-
Referee: [Method] Method description: no diagnostic, ablation, or analysis is supplied to verify that noise injection produces decorrelated reasoning traces rather than correlated paths that share the model's systematic biases. If the latter occurs, unanimous agreement would not reliably indicate correctness and the selective-abstention benefit would not materialize.
Authors: We acknowledge the importance of this verification. The current manuscript provides only qualitative examples of path diversity. We will add a quantitative ablation subsection that measures average pairwise semantic similarity (via sentence embeddings) across noise-perturbed traces versus temperature-sampled traces, and we will report the correlation between unanimous agreement and correctness on held-out data. This will demonstrate that the consensus signal is effective primarily when decorrelation is achieved. revision: yes
Circularity Check
No significant circularity; method is inference-time and self-contained
full rationale
The paper presents NoisyCoconut as an inference-time procedure that injects noise into existing model latent trajectories to produce multiple paths and uses their agreement as an abstention signal. No equations, fitted parameters, or derivations are shown that reduce the claimed performance to the inputs by construction. No self-citations are used to justify uniqueness or load-bearing assumptions. The central claim rests on empirical coverage-accuracy tradeoffs rather than any tautological renaming or self-referential definition, making the derivation chain independent of the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
Advances in Neural Information Processing Systems , volume=
Selective Classification for Deep Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Journal of Machine Learning Research , volume=
On the Foundations of Noise-Free Selective Classification , author=. Journal of Machine Learning Research , volume=
-
[4]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[5]
International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. International Conference on Learning Representations , year=
-
[6]
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , author=. 2025 , eprint=
work page 2025
-
[7]
Continuous Chain of Thought Enables Parallel Exploration and Reasoning , author=. 2025 , eprint=
work page 2025
-
[8]
Everything Everywhere All at Once:
Zheyang Xiong and Ziyang Cai and John Cooper and Albert Ge and Vasilis Papageorgiou and Zack Sifakis and Angeliki Giannou and Ziqian Lin and Liu Yang and Saurabh Agarwal and Grigorios G Chrysos and Samet Oymak and Kangwook Lee and Dimitris Papailiopoulos , year=. Everything Everywhere All at Once:. 2410.05603 , archivePrefix=
-
[9]
STaR: Bootstrapping Reasoning With Reasoning , author=. 2022 , eprint=
work page 2022
-
[10]
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in
Xuan Zhang and Chao Du and Tianyu Pang and Qian Liu and Wei Gao and Min Lin , year=. Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in. 2406.09136 , archivePrefix=
-
[11]
Fine-Tuning on Diverse Reasoning Chains Drives Within-Inference CoT Refinement in
Haritz Puerto and Tilek Chubakov and Xiaodan Zhu and Harish Tayyar Madabushi and Iryna Gurevych , year=. Fine-Tuning on Diverse Reasoning Chains Drives Within-Inference CoT Refinement in. 2407.03181 , archivePrefix=
-
[12]
On the Impact of Fine-Tuning on Chain-of-Thought Reasoning , author=. 2025 , eprint=
work page 2025
-
[13]
Qwen2.5: A Party of Foundation Models , url =
-
[14]
Aaron Grattafiori and. The. 2024 , eprint=
work page 2024
- [15]
- [16]
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI , year=. DeepSeek-R1: Incentivizing Reasoning Capability in. 2501.12948 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
work page 2021
-
[19]
Iman Mirzadeh and Keivan Alizadeh and Hooman Shahrokhi and Oncel Tuzel and Samy Bengio and Mehrdad Farajtabar , year=. 2410.05229 , archivePrefix=
-
[20]
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
work page 2021
-
[21]
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models , author=. 2024 , eprint=
work page 2024
- [22]
- [23]
-
[24]
Pretraining Language Models to Ponder in Continuous Space , author=. 2025 , eprint=
work page 2025
-
[25]
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning , author=. 2025 , eprint=
work page 2025
-
[26]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [27]
-
[28]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. arXiv preprint arXiv:2201.11903 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Decomposed prompting: A modular approach for solving complex tasks,
Decomposed Prompting: A Modular Approach for Solving Complex Tasks , author=. arXiv preprint arXiv:2210.02406 , year=
-
[30]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Mammoth: Building Math Generalist Models through Hybrid Instruction Tuning , author=. arXiv preprint arXiv:2309.05653 , year=
-
[32]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=. arXiv preprint arXiv:2309.12284 , year=
work page internal anchor Pith review arXiv
-
[33]
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , journal=
-
[34]
Teaching Large Language Models to Reason with Reinforcement Learning , author=. arXiv preprint arXiv:2403.04642 , year=
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Flow of Reasoning: Efficient Training of
Yu, Fangxu and Jiang, Lai and Kang, Haoqiang and Hao, Shibo and Qin, Lianhui , journal=. Flow of Reasoning: Efficient Training of
-
[37]
Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango
Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango , author=. arXiv preprint arXiv:2209.07686 , year=
-
[38]
A Path Towards Autonomous Machine Intelligence Version 0.9.2 , author=. Open Review , volume=
-
[39]
arXiv preprint arXiv:2305.14992 , year=
Reasoning with Language Model is Planning with World Model , author=. arXiv preprint arXiv:2305.14992 , year=
-
[40]
Advances in Neural Information Processing Systems , year=
Towards Revealing the Mystery Behind Chain of Thought: A Theoretical Perspective , author=. Advances in Neural Information Processing Systems , year=
-
[41]
The expressive power of transformers with chain of thought, 2024
The Expresssive Power of Transformers with Chain of Thought , author=. arXiv preprint arXiv:2310.07923 , year=
-
[42]
Chain of thought empowers transformers to solve inherently serial problems, 2024
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , author=. arXiv preprint arXiv:2402.12875 , year=
-
[43]
arXiv preprint arXiv:2402.16837 , year=
Do Large Language Models Latently Perform Multi-hop Reasoning? , author=. arXiv preprint arXiv:2402.16837 , year=
-
[44]
arXiv preprint arXiv:2406.12775 , year=
Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-hop Queries , author=. arXiv preprint arXiv:2406.12775 , year=
-
[45]
Shalev, Yuval and Feder, Amir and Goldstein, Ariel , journal=. Distributional Reasoning in
-
[46]
arXiv preprint arXiv:2212.10001 , year=
Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters , author=. arXiv preprint arXiv:2212.10001 , year=
-
[47]
Advances in Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Advances in Neural Information Processing Systems , year=
-
[48]
Think Before You Speak: Training Language Models With Pause Tokens , author=. arXiv preprint arXiv:2310.02226 , year=
-
[49]
Let’s think dot by dot: Hidden computa- tion in transformer language models
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models , author=. arXiv preprint arXiv:2404.15758 , year=
-
[50]
arXiv preprint arXiv:2310.05707 , year=
Guiding Language Model Reasoning with Planning Tokens , author=. arXiv preprint arXiv:2310.05707 , year=
-
[51]
Implicit chain of thought reasoning via knowledge distillation, 2023
Implicit Chain of Thought Reasoning via Knowledge Distillation , author=. arXiv preprint arXiv:2311.01460 , year=
- [52]
-
[53]
Distilling system 2 into system 1
Distilling System 2 into System 1 , author=. arXiv preprint arXiv:2407.06023 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Advances in Neural Information Processing Systems , volume=
Self-Evaluation Guided Beam Search for Reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2402.14083 , year=
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping , author=. arXiv preprint arXiv:2402.14083 , year=
-
[57]
Stream of search (sos): Learning to search in language, 2024,
Stream of Search (SoS): Learning to Search in Language , author=. arXiv preprint arXiv:2404.03683 , year=
-
[58]
arXiv preprint arXiv:2410.09918 , year=
DualFormer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces , author=. arXiv preprint arXiv:2410.09918 , year=
-
[59]
Training Large Language Models to Reason in a Continuous Latent Space
Training Large Language Models to Reason in a Continuous Latent Space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
International Conference on Machine Learning , pages=
SelectiveNet: A Deep Neural Network with an Integrated Reject Option , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[61]
Detecting Hallucinations in Large Language Models Using Semantic Entropy , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[62]
Transactions on Machine Learning Research , year=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[63]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle=. Can
-
[64]
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
work page 2022
-
[65]
Transactions on Machine Learning Research , year=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , year=
-
[66]
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. EMNLP , year=
-
[67]
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , booktitle=. 2023 , url=
work page 2023
-
[68]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
International Conference on Learning Representations , year=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. International Conference on Learning Representations , year=
-
[70]
When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of
Kamoi, Ryo and Hou, Yusen and Zhang, Nan and Guo, Jiawei and Wang, Yichao and Wang, Hongming and Caverlee, James and Zhang, Rui , journal=. When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of
-
[71]
Adaptation with Self-Evaluation to Improve Selective Prediction in
Chen, Jiefeng and Yoon, Jinsung and Ebrahimi, Sayna and Arik, Sercan O and Pfister, Tomas and Jha, Somesh , booktitle=. Adaptation with Self-Evaluation to Improve Selective Prediction in
-
[72]
Conference on Language Modeling , year=
Training Large Language Models to Reason in a Continuous Latent Space , author=. Conference on Language Modeling , year=
-
[73]
arXiv preprint arXiv:2311.08298 , year=
A Survey of Confidence Estimation and Calibration in Large Language Models , author=. arXiv preprint arXiv:2311.08298 , year=
-
[74]
A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions , author=. ACM Computing Surveys , year=
-
[75]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. EMNLP , year=
-
[76]
Findings of the Association for Computational Linguistics , year=
Chain-of-Verification Reduces Hallucination in Large Language Models , author=. Findings of the Association for Computational Linguistics , year=
-
[77]
Confidence Improves Self-Consistency in
Taubenfeld, Amir and Sheffer, Tom and Ofek, Eran and Feder, Amir and Goldstein, Ariel and Gekhman, Zorik and Yona, Gal , journal=. Confidence Improves Self-Consistency in
-
[78]
Kernel Language Entropy: Fine-grained Uncertainty Quantification for
Nikitin, Alexander and Kossen, Jannik and Gal, Yarin and Marttinen, Pekka , booktitle=. Kernel Language Entropy: Fine-grained Uncertainty Quantification for
-
[79]
International Conference on Learning Representations , year=
Bias-Reduced Uncertainty Estimation for Deep Neural Classifiers , author=. International Conference on Learning Representations , year=
-
[80]
International Conference on Machine Learning , year=
On Calibration of Modern Neural Networks , author=. International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.