Recognition: no theorem link
TinySSL: Distilled Self-Supervised Pretraining for Sub-Megabyte MCU Models
Pith reviewed 2026-05-12 01:01 UTC · model grok-4.3
The pith
Asymmetric distillation from a frozen large teacher enables self-supervised pretraining for sub-500K parameter models that reach 94% of supervised accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
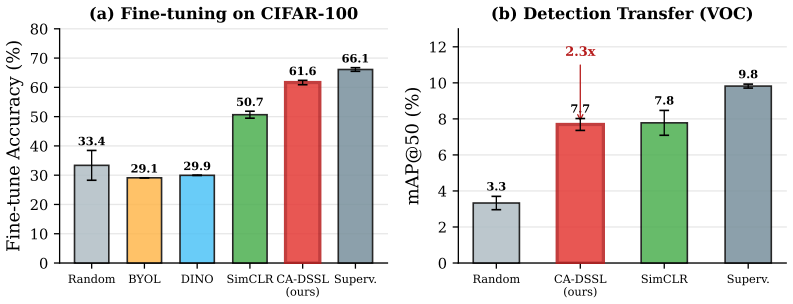
CA-DSSL overcomes the obstacles that cause standard SSL to fail at sub-500K scale by combining asymmetric distillation from a frozen DINO ViT-S/16 teacher, multi-scale feature distillation for spatial representations, and a progressive augmentation curriculum. On a MobileNetV2-0.35 backbone with 396K parameters pretrained on CIFAR-100, the method reaches 62.7% linear-probe accuracy, surpassing SimCLR-Tiny by 18 percentage points, matching SEED with ten times fewer projection parameters, and attaining 94% of a supervised upper bound. Standard methods such as BYOL-Tiny and DINO-Tiny collapse entirely at this scale, while the resulting 378 KB INT8 backbone shows no inference overhead and yields
What carries the argument
Capacity-Aware Distilled Self-Supervised Learning (CA-DSSL), an asymmetric teacher-student distillation framework that transfers multi-scale representations from a large frozen vision transformer to a capacity-limited convolutional student using curriculum augmentations.
If this is right
- The 396K-parameter backbone reaches 2.3 times the mAP of random initialization on Pascal VOC detection.
- CA-DSSL matches SEED performance while using only 426K total parameters versus SEED's 3.15M.
- The pretrained model occupies 378 KB in INT8 with zero added inference cost from pretraining.
- Standard SSL variants collapse completely at this scale while CA-DSSL succeeds.
- The performance gain appears specific to small-data regimes such as CIFAR-100.
Where Pith is reading between the lines
- If the curriculum and multi-scale components prove robust, similar distillation patterns could be tested on other low-capacity architectures beyond MobileNetV2.
- The method's dependence on a large teacher raises the question of whether a medium-sized teacher or purely student-internal signals could achieve comparable results.
- Success on CIFAR-100 and VOC suggests the framework may transfer to other MCU vision tasks such as keyword spotting or gesture recognition where labels are scarce.
- The paper notes that scaling experiments to ImageNet-1K remain future work; positive results there would indicate whether the approach is regime-specific or broadly applicable.
Load-bearing premise
The three obstacles of projection head dominance, representation bottleneck, and augmentation sensitivity are the primary reasons standard SSL collapses below 500K parameters and that asymmetric distillation from a much larger frozen teacher can fix them without creating new capacity-mismatch failures.
What would settle it
A controlled replication in which a non-distilled SimCLR or BYOL run on the identical MobileNetV2-0.35 backbone and CIFAR-100 data reaches above 50% linear-probe accuracy would falsify the claim that these obstacles necessitate teacher-guided distillation.
Figures




read the original abstract
Self-supervised learning (SSL) has transformed representation learning for large models, yet remains unexplored for microcontroller (MCU)-class models with fewer than 500K parameters. We identify three obstacles at this scale -- projection head dominance, representation bottleneck, and augmentation sensitivity -- and propose Capacity-Aware Distilled Self-Supervised Learning (CA-DSSL), a teacher-guided framework that overcomes them without labels or text supervision. CA-DSSL combines asymmetric distillation from a frozen DINO ViT-S/16 teacher, multi-scale feature distillation for spatial representations, and a progressive augmentation curriculum. On a MobileNetV2-0.35 backbone (396K parameters) pretrained on CIFAR-100, CA-DSSL reaches 62.7 0.5% linear-probe accuracy (3-seed mean) -- surpassing SimCLR-Tiny by 18 pp, matching SEED (61.7%) with 10 fewer projection parameters (426K vs. 3.15M), and reaching 94.0% of a supervised upper bound. Standard SSL methods (BYOL-Tiny, DINO-Tiny) collapse entirely at this scale. On Pascal VOC detection, CA-DSSL achieves 2.3 the mAP of random initialization and +3 pp over SEED, though SimCLR-Tiny matches CA-DSSL on detection mAP. The deployed backbone occupies 378 KB (INT8) with no inference overhead from pretraining. Preliminary ImageNet-100 experiments reveal that CA-DSSL's advantage is specific to small-data regimes; scaling to ImageNet-1K is discussed as future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Capacity-Aware Distilled Self-Supervised Learning (CA-DSSL) for self-supervised pretraining of sub-500K parameter MCU-class models. It identifies three obstacles to standard SSL at this scale (projection head dominance, representation bottleneck, augmentation sensitivity) and introduces asymmetric distillation from a frozen DINO ViT-S/16 teacher combined with multi-scale feature distillation and a progressive augmentation curriculum. On a 396K-parameter MobileNetV2-0.35 backbone pretrained on CIFAR-100, it reports 62.7 ± 0.5% linear-probe accuracy (3-seed mean), outperforming SimCLR-Tiny by 18 pp, matching SEED with fewer projection parameters, and reaching 94% of a supervised upper bound; standard tiny SSL methods collapse. Secondary results on Pascal VOC detection show 2.3× mAP over random init and +3 pp over SEED (though SimCLR-Tiny matches on detection), with a deployed INT8 size of 378 KB and no inference overhead. Preliminary ImageNet-100 results indicate the advantage is specific to small-data regimes.
Significance. If the empirical results hold under rigorous controls, the work is significant for enabling label-free pretraining on severely constrained edge devices where standard SSL fails entirely. The multi-seed reporting, direct comparisons to multiple baselines (including supervised upper bound), and secondary detection task evaluation provide concrete evidence. The practical deployment metric (378 KB INT8 backbone) is a clear strength for MCU applications.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The central claim that CA-DSSL overcomes the three obstacles 'without' introducing teacher-student capacity mismatch rests on asymmetric distillation from a frozen DINO ViT-S/16 teacher; however, no ablation is reported that isolates this from the teacher's superior capacity (ViT transformer vs. tiny CNN student) or compares against a capacity-matched teacher or a non-distillation baseline that directly mitigates the three obstacles. This leaves open whether the 62.7% accuracy and 94% supervised recovery are due to the proposed framework or knowledge transfer from a much larger model.
- [§4.2] §4.2 (Pascal VOC experiments): While CA-DSSL is reported to achieve 2.3× mAP over random initialization and +3 pp over SEED, the manuscript notes that SimCLR-Tiny matches CA-DSSL on detection mAP; this undercuts the claim of broad superiority at tiny scale and requires explicit analysis of why the method's advantages appear classification-specific rather than general.
minor comments (2)
- [Abstract] Abstract: The linear-probe result is written as '62.7 0.5%' (missing ±) and '2.3 the mAP' (should be 2.3×); these are minor but affect readability of the key claims.
- [Abstract] Abstract: The statement 'no inference overhead from pretraining' is asserted but would benefit from a brief note on how the final backbone is extracted (e.g., student-only weights after distillation and INT8 quantization).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that CA-DSSL overcomes the three obstacles 'without' introducing teacher-student capacity mismatch rests on asymmetric distillation from a frozen DINO ViT-S/16 teacher; however, no ablation is reported that isolates this from the teacher's superior capacity (ViT transformer vs. tiny CNN student) or compares against a capacity-matched teacher or a non-distillation baseline that directly mitigates the three obstacles. This leaves open whether the 62.7% accuracy and 94% supervised recovery are due to the proposed framework or knowledge transfer from a much larger model.
Authors: We thank the referee for this observation. The manuscript does not claim to overcome the obstacles without any capacity mismatch; it instead presents a teacher-guided framework that uses asymmetric distillation from a larger frozen DINO ViT-S/16 teacher precisely because standard SSL collapses at this scale. However, we agree that the current version lacks ablations to separate the contributions of the proposed components (asymmetric distillation, multi-scale feature distillation, and progressive augmentation curriculum) from the teacher's capacity advantage. In the revised manuscript we will add: (1) results with a capacity-matched larger CNN teacher, (2) a non-distillation baseline that applies the same mitigations without any teacher, and (3) component-wise ablations. These experiments will clarify that the reported gains arise from the framework's ability to effectively adapt and distill knowledge to the tiny student rather than from teacher size alone. We will also revise the wording in the abstract and §3 for greater precision. revision: yes
-
Referee: [§4.2] §4.2 (Pascal VOC experiments): While CA-DSSL is reported to achieve 2.3× mAP over random initialization and +3 pp over SEED, the manuscript notes that SimCLR-Tiny matches CA-DSSL on detection mAP; this undercuts the claim of broad superiority at tiny scale and requires explicit analysis of why the method's advantages appear classification-specific rather than general.
Authors: We agree that the matching detection performance of SimCLR-Tiny requires explicit discussion. In the revised §4.2 we will expand the analysis to explain the task-specific results. Linear probing on classification directly measures the quality of the global representation produced by distillation, where CA-DSSL shows clear gains. Detection, by contrast, relies on local backbone features fed into a region proposal network; SimCLR-Tiny's contrastive objective appears sufficient for this particular downstream task. We will support the discussion with additional qualitative feature visualizations and note that the primary target application (MCU pretraining) centers on classification in small-data regimes, consistent with the ImageNet-100 observations. The manuscript does not assert universal superiority across all tasks. revision: yes
Circularity Check
No circularity: empirical benchmarks against external baselines
full rationale
The paper identifies three obstacles at sub-500K scale and proposes the CA-DSSL framework (asymmetric distillation from frozen DINO ViT-S/16, multi-scale features, progressive curriculum) as a solution. All load-bearing claims are validated by direct empirical measurements: 62.7% linear-probe accuracy on CIFAR-100 MobileNetV2-0.35, comparisons to SimCLR-Tiny/SEED/supervised bounds, and Pascal VOC mAP. No equations, fitted parameters renamed as predictions, or self-citation chains appear; results are independent benchmark scores on public datasets. The derivation chain is self-contained as a method-plus-experiment paper with no reductions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen larger ViT teacher can supply useful spatial and semantic supervision to a capacity-constrained student via multi-scale feature distillation without labels.
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
A simple framework for contrastive learning of visual representations , author=. International Conference on Machine Learning , pages=
-
[2]
Advances in Neural Information Processing Systems , volume=
Bootstrap your own latent: A new approach to self-supervised learning , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
IEEE/CVF International Conference on Computer Vision , pages=
Emerging properties in self-supervised vision transformers , author=. IEEE/CVF International Conference on Computer Vision , pages=
-
[4]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Improved Baselines with Momentum Contrastive Learning
Improved baselines with momentum contrastive learning , author=. arXiv preprint arXiv:2003.04297 , year=
work page internal anchor Pith review arXiv 2003
-
[6]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Exploring simple siamese representation learning , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Masked autoencoders are scalable vision learners , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
Bao, Hangbo and Dong, Li and Piao, Songhao and Wei, Furu , booktitle=
-
[9]
Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh , booktitle=
-
[10]
Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Gan, Chuang and Han, Song , booktitle=
-
[11]
Lin, Ji and Chen, Wei-Ming and Cai, Han and Gan, Chuang and Han, Song , booktitle=
-
[12]
Banbury, Colby and Reddi, Vijay Janapa and Torelli, Peter and Holleman, Jeremy and Jeffries, Nat and Kirber, Csaba and Montino, Pietro and Kanter, David and Ahmed, Sebastian and Pau, Danilo and others , booktitle=
-
[13]
NIPS Deep Learning Workshop , year=
Distilling the knowledge in a neural network , author=. NIPS Deep Learning Workshop , year=
-
[14]
Fang, Zhiyuan and Wang, Jianfeng and Wang, Lijuan and Zhang, Lei and Yang, Yezhou and Liu, Zicheng , booktitle=
-
[15]
Abbasi Koohpayegani, Soroush and Tejankar, Ajinkya and Pirsiavash, Hamed , booktitle=
-
[16]
Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong , booktitle=
-
[17]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
European Conference on Computer Vision (ECCV) , year=
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning , author=. European Conference on Computer Vision (ECCV) , year=
-
[19]
CompRess : Self-supervised learning by compressing representations
Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. CompRess : Self-supervised learning by compressing representations. In Advances in Neural Information Processing Systems, volume 33, pages 12980--12992, 2020
work page 2020
-
[20]
Colby Banbury, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kirber, Pietro Montino, David Kanter, Sebastian Ahmed, Danilo Pau, et al. MLPerf tiny benchmark. In Advances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[21]
BE i T : BERT pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BE i T : BERT pre-training of image transformers. In International Conference on Learning Representations, 2022
work page 2022
-
[22]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv \'e J \'e gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In IEEE/CVF International Conference on Computer Vision, pages 9650--9660, 2021
work page 2021
-
[23]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pages 1597--1607, 2020 a
work page 2020
-
[24]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15750--15758, 2021
work page 2021
-
[25]
Improved baselines with momentum contrastive learning
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. 2020 b
work page 2020
-
[26]
SEED : Self-supervised distillation for visual representation
Zhiyuan Fang, Jianfeng Wang, Lijuan Wang, Lei Zhang, Yezhou Yang, and Zicheng Liu. SEED : Self-supervised distillation for visual representation. In International Conference on Learning Representations, 2021
work page 2021
-
[27]
Disco: Remedy self-supervised learning on lightweight models with distilled contrastive learning
Yuting Gao, Jia Zhuang, Shaohui Lin, Hao Cheng, Xing Sun, Ke Li, and Chunhua Shen. Disco: Remedy self-supervised learning on lightweight models with distilled contrastive learning. In European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[28]
Bootstrap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altch \'e , Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Chen, Michal Valko, et al. Bootstrap your own latent: A new approach to self-supervised learning. In Advances in Neural Information Processing Systems, volume 33, pages 21271--21284, 2020
work page 2020
-
[29]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729--9738, 2020
work page 2020
-
[30]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll \'a r, and Ross Girshick. Masked autoencoders are scalable vision learners. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000--16009, 2022
work page 2022
-
[31]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning Workshop, 2015
work page 2015
-
[32]
MCUNet : Tiny deep learning on IoT devices
Ji Lin, Wei-Ming Chen, Yujun Lin, Chuang Gan, and Song Han. MCUNet : Tiny deep learning on IoT devices. In Advances in Neural Information Processing Systems, volume 33, pages 11711--11722, 2020
work page 2020
-
[33]
MCUNetV2 : Memory-efficient patch-based inference for tiny deep learning
Ji Lin, Wei-Ming Chen, Han Cai, Chuang Gan, and Song Han. MCUNetV2 : Memory-efficient patch-based inference for tiny deep learning. In Advances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[34]
MobileNetV2 : Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. MobileNetV2 : Inverted residuals and linear bottlenecks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4510--4520, 2018
work page 2018
-
[35]
FCOS : Fully convolutional one-stage object detection
Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS : Fully convolutional one-stage object detection. In IEEE/CVF International Conference on Computer Vision, pages 9627--9636, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.