Recognition: no theorem link
GPU-Accelerated Synthesis of Mixed-Boolean Arithmetic: Beyond Caching
Pith reviewed 2026-05-12 00:45 UTC · model grok-4.3
The pith
A cache-free GPU enumeration method synthesizes mixed-boolean arithmetic expressions faster and at scales where prior tools fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SIMBA performs synthesis of mixed-boolean arithmetic expressions from input-output examples using a cache-free bottom-up enumeration strategy that is explicitly designed for GPU execution, keeping all work local and highly parallel without storing observationally equivalent candidates.
What carries the argument
Cache-free bottom-up enumeration on GPU, which enumerates candidate expressions directly without language caches or equivalence checks that fail for quantitative bitvector outputs.
If this is right
- Substantially faster synthesis than prior CPU-based or cache-dependent MBA tools on the same specifications.
- Successful handling of larger input-output specifications that overwhelm existing methods.
- Ability to reach expression sizes that cause prior synthesizers to time out or fail entirely.
- Cache-free GPU synthesis becomes a practical alternative for other quantitative domains beyond pure boolean settings.
Where Pith is reading between the lines
- The same local-parallel enumeration pattern could transfer to synthesis tasks involving other quantitative outputs such as floating-point or cryptographic values.
- Deobfuscation pipelines might incorporate this approach to tackle more complex real-world obfuscators that produce larger MBA expressions.
- Hybrid systems could combine the GPU enumerator with lightweight CPU post-processing to further reduce overall runtime on mixed workloads.
- The results suggest that hardware-specific redesigns of enumeration, rather than caching, deserve consideration in other program synthesis settings.
Load-bearing premise
The chosen benchmarks and expression sizes are representative of real-world deobfuscation and optimization tasks, and GPU enumeration stays efficient without hidden bottlenecks when scaling beyond the tested sizes.
What would settle it
Apply SIMBA to a new set of benchmarks containing twice as many input-output pairs or targeting expressions one size larger than the largest solved in the paper, then measure whether runtime and success rate maintain the reported advantages or degrade sharply.
Figures
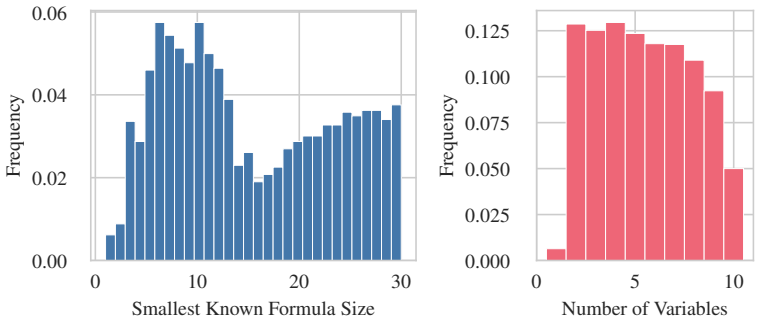
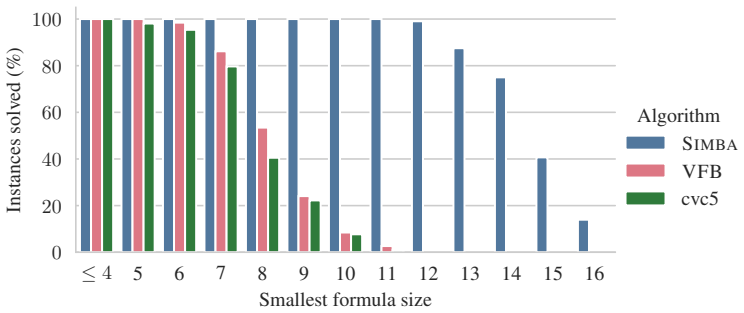




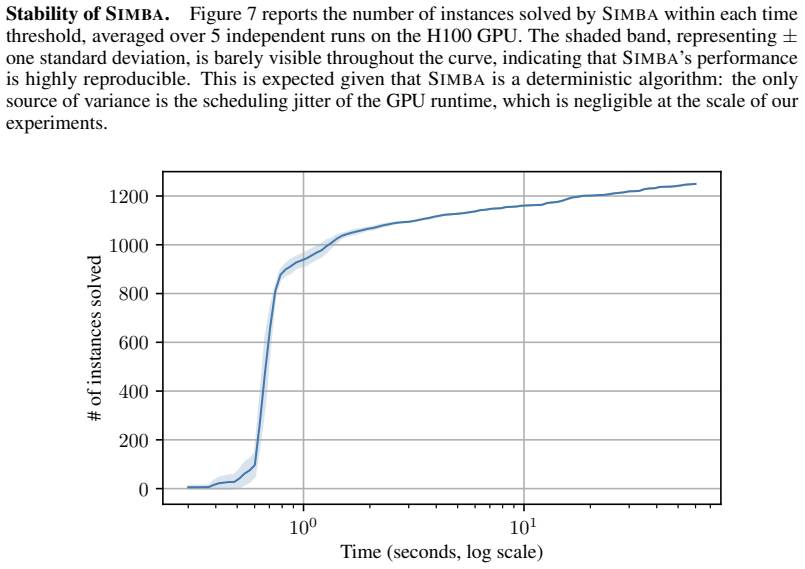
read the original abstract
Synthesizing Mixed-Boolean Arithmetic (MBA) expressions from input-output examples is central to program deobfuscation and also useful for compiler optimization, reverse engineering, and cryptanalysis. Existing MBA synthesizers are typically CPU-based and scale poorly on large specifications or complex targets. Recent GPU-accelerated synthesis methods achieve large speedups in qualitative settings, but they depend on caching observationally equivalent candidates; this strategy breaks down for MBA because candidate outputs are quantitative bitvectors and the behavioral space is enormous. We present SIMBA (Synthesis of Mixed-Boolean Arithmetic), a GPU-accelerated MBA synthesizer built around cache-free bottom-up enumeration. SIMBA avoids language caches entirely and uses a GPU-oriented enumeration design that keeps work local and highly parallel. In experiments, SIMBA is substantially faster than prior MBA synthesis tools, handles larger specifications, and reaches expression sizes that existing methods fail to solve. These results establish cache-free GPU synthesis as a practical and scalable approach for quantitative domains, and identify it as a strong alternative to cache-centric designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SIMBA, a GPU-accelerated synthesizer for Mixed-Boolean Arithmetic (MBA) expressions from input-output examples. It proposes a cache-free bottom-up enumeration strategy optimized for GPU parallelism, arguing that caching fails for MBA because candidate outputs are quantitative bitvectors with an enormous behavioral space. The central empirical claim is that SIMBA is substantially faster than prior MBA tools, handles larger specifications, and reaches expression sizes that existing methods cannot solve.
Significance. If the results hold, the work is significant for establishing cache-free GPU enumeration as a practical approach for quantitative synthesis domains where cache-centric designs break down. It provides direct experimental comparisons supporting speedups and extended reach, with strengths in the GPU-oriented design that keeps work local and parallel, and the absence of reliance on fitted parameters or circular derivations. This could advance applications in program deobfuscation, compiler optimization, reverse engineering, and cryptanalysis.
major comments (1)
- [Experiments] Experimental evaluation: The performance claims rest on direct comparisons showing speedups and scalability, but the manuscript provides insufficient detail on benchmark selection criteria and does not report run-to-run variance or statistical measures in the timing results. This limits assessment of whether the tested cases are representative of real-world tasks and whether the GPU enumeration scales without hidden bottlenecks.
minor comments (1)
- [Abstract] The abstract states that SIMBA reaches 'expression sizes that existing methods fail to solve' but does not reference a specific table or example showing the failure threshold; adding this would improve clarity of the reach claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The feedback on experimental details is constructive, and we address it directly below by committing to clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: Experimental evaluation: The performance claims rest on direct comparisons showing speedups and scalability, but the manuscript provides insufficient detail on benchmark selection criteria and does not report run-to-run variance or statistical measures in the timing results. This limits assessment of whether the tested cases are representative of real-world tasks and whether the GPU enumeration scales without hidden bottlenecks.
Authors: We agree that more detail on benchmark selection and statistical reporting would improve clarity. In the revision we will add an explicit subsection describing the benchmark selection criteria, including how the input-output specifications were derived from real-world deobfuscation, compiler optimization, and cryptanalysis tasks to ensure representativeness. Although the core enumeration algorithm is deterministic, GPU kernel scheduling can introduce small timing variations; we will re-run all timing experiments five times per benchmark, report means with standard deviations in the tables, and add a short discussion of observed scalability limits and potential bottlenecks. revision: yes
Circularity Check
No significant circularity detected; claims rest on independent algorithmic design and empirical validation
full rationale
The paper introduces SIMBA as a new GPU-oriented, cache-free bottom-up enumeration algorithm for MBA synthesis, motivated by the breakdown of caching for quantitative bitvector outputs. No derivation chain, equations, or first-principles results are presented that reduce by construction to fitted inputs, self-citations, or renamed known patterns. The performance claims (faster runtimes, larger solvable specifications) are grounded in direct experimental comparisons rather than any predictive model or uniqueness theorem imported from prior self-work. The design choices are explicitly justified by domain characteristics without circular reduction, making the contribution self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bottom-up enumeration generates all expressions up to a given size without duplicates when using appropriate pruning.
- domain assumption GPU kernels can be organized so that work remains local and highly parallel without global synchronization overhead for this enumeration pattern.
Reference graph
Works this paper leans on
-
[1]
Rajeev Alur, Rastislav Bodík, Garvit Juniwal, Milo M. K. Martin, Mukund Raghothaman, Sanjit A. Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, and Abhishek Udupa. Syntax- guided synthesis. InFormal Methods in Computer-Aided Design, FMCAD 2013, Portland, OR, USA, October 20-23, 2013, pages 1–8. IEEE,
work page 2013
-
[2]
URL https://ieeexplore.ieee.org/ document/6679385/. Austin Appleby. Murmurhash3 and smhasher. https://github.com/aappleby/smhasher,
-
[3]
Vidal Attias, Nicolas Bellec, Grégoire Menguy, Sébastien Bardin, and Jean-Yves Marion
Accessed: 2026-04-24. Vidal Attias, Nicolas Bellec, Grégoire Menguy, Sébastien Bardin, and Jean-Yves Marion. Augmenting search-based program synthesis with local inference rules to improve black-box deobfuscation. In Chun-Ying Huang, Jyh-Cheng Chen, Shiuh-Pyng Shieh, David Lie, and Véronique Cortier, editors,Proceedings of the 2025 ACM SIGSAC Conference o...
work page 2026
-
[4]
In: Huang, C., Chen, J., Shieh, S., Lie, D., Cortier, V
doi: 10.1145/3719027.3765134. URLhttps://doi.org/10.1145/3719027.3765134. Sorav Bansal and Alex Aiken. Automatic generation of peephole superoptimizers. In John Paul Shen and Margaret Martonosi, editors,Proceedings of the 12th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2006, San Jose, CA, USA,...
-
[5]
URLhttps://doi.org/10.1145/1168857.1168906
doi: 10.1145/1168857.1168906. URLhttps://doi.org/10.1145/1168857.1168906. Haniel Barbosa, Clark W. Barrett, Martin Brain, Gereon Kremer, Hanna Lachnitt, Makai Mann, Abdalrhman Mohamed, Mudathir Mohamed, Aina Niemetz, Andres Nötzli, Alex Ozdemir, Mathias Preiner, Andrew Reynolds, Ying Sheng, Cesare Tinelli, and Yoni Zohar. cvc5: A versatile and industrial-...
-
[6]
URL https://doi.org/10.1007/978-3-030-99524-9_24
doi: 10.1007/978-3-030-99524-9\_24. URL https://doi.org/10.1007/978-3-030-99524-9_24. Martin Berger, Nathanaël Fijalkow, and Mojtaba Valizadeh. GPU accelerated program synthesis: Enumerate semantics, not syntax!CoRR, abs/2504.18943,
-
[7]
doi: 10.48550/ARXIV .2504. 18943. URLhttps://doi.org/10.48550/arXiv.2504.18943. Sandrine Blazy and Rémi Hutin. Formal verification of a program obfuscation based on mixed boolean-arithmetic expressions. In Assia Mahboubi and Magnus O. Myreen, editors,Proceedings of the 8th ACM SIGPLAN International Conference on Certified Programs and Proofs, CPP 2019, Ca...
work page internal anchor Pith review doi:10.48550/arxiv 2019
-
[8]
doi: 10.1145/3293880. 3294103. URLhttps://doi.org/10.1145/3293880.3294103. Tim Blazytko, Moritz Contag, Cornelius Aschermann, and Thorsten Holz. Syntia: Synthesiz- ing the semantics of obfuscated code. In Engin Kirda and Thomas Ristenpart, editors,26th USENIX Security Symposium, USENIX Security 2017, Vancouver, BC, Canada, August 16-18, 2017, pages 643–65...
-
[9]
NeuReduce: Reducing mixed boolean-arithmetic expressions by recurrent neural network
Weijie Feng, Binbin Liu, Dongpeng Xu, Qilong Zheng, and Yun Xu. NeuReduce: Reducing mixed boolean-arithmetic expressions by recurrent neural network. In Trevor Cohn, Yulan He, and Yang Liu, editors,Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, Findings of ACL, pages 635–644. Association for Compu...
work page 2020
-
[10]
URL https: //doi.org/10.18653/v1/2020.findings-emnlp.56
doi: 10.18653/V1/2020.FINDINGS-EMNLP.56. URL https: //doi.org/10.18653/v1/2020.findings-emnlp.56. 10 Sumit Gulwani, Oleksandr Polozov, and Rishabh Singh.Program Synthesis. Now Publishers,
-
[11]
Simplifying mixed boolean-arithmetic obfuscation by program synthesis and term rewriting
Jaehyung Lee and Woosuk Lee. Simplifying mixed boolean-arithmetic obfuscation by program synthesis and term rewriting. In Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda, editors,Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS 2023, Copenhagen, Denmark, November 26-30, 2023, pages 2351–2365. ACM,
work page 2023
-
[12]
URL https://doi.org/10.1145/ 3576915.3623186
doi: 10.1145/3576915.3623186. URL https://doi.org/10.1145/ 3576915.3623186. Binbin Liu, Wenying Feng, Qilong Zheng, Jing Li, and Dongpeng Xu. Software obfuscation with non-linear mixed Boolean-arithmetic expressions. InInternational Conference on Information Security and Cryptology (ICISC), pages 276–296. Springer, 2021a. Binbin Liu, Junfu Shen, Jiang Min...
-
[13]
URL https://doi.org/10.1145/ 3460120.3485250
doi: 10.1145/3460120.3485250. URL https://doi.org/10.1145/ 3460120.3485250. John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. Scalable parallel programming with CUDA.ACM Queue, 6(2):40–53,
-
[14]
URL https: //doi.org/10.1145/1365490.1365500
doi: 10.1145/1365490.1365500. URL https: //doi.org/10.1145/1365490.1365500. Benjamin Reichenwallner and Peter Meerwald-Stadler. Efficient deobfuscation of linear mixed boolean-arithmetic expressions. In Golden G. Richard III and Tim Blazytko, editors,Proceedings of the 2022 ACM Workshop on Research on offensive and defensive techniques in the context of M...
-
[15]
URLhttps://doi.org/10.1145/3560831.3564256
doi: 10.1145/3560831.3564256. URLhttps://doi.org/10.1145/3560831.3564256. Benjamin Reichenwallner and Peter Meerwald-Stadler. Simplification of general mixed boolean- arithmetic expressions: GAMBA. InIEEE European Symposium on Security and Privacy, Eu- roS&P 2023 - Workshops, Delft, Netherlands, July 3-7, 2023, pages 427–438. IEEE,
-
[16]
Get a higher return on your savings!
doi: 10.1109/EUROSPW59978.2023.00053. URL https://doi.org/10.1109/EuroSPW59978. 2023.00053. Raimondas Sasnauskas, Yang Chen, Peter Collingbourne, Jeroen Ketema, Gratian Lup, Jubi Taneja, and John Regehr. Souper: A synthesizing superoptimizer.arXiv preprint arXiv:1711.04422,
-
[17]
Deshmukh, Sela Mador-Haim, Milo M
Abhishek Udupa, Arun Raghavan, Jyotirmoy V . Deshmukh, Sela Mador-Haim, Milo M. K. Martin, and Rajeev Alur. TRANSIT: specifying protocols with concolic snippets. In Hans-Juergen Boehm and Cormac Flanagan, editors,ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’13, Seattle, WA, USA, June 16-19, 2013, pages 287–296. ACM,
work page 2013
-
[18]
doi: 10.1145/2491956.2462174. URLhttps://doi.org/10.1145/2491956.2462174. Mojtaba Valizadeh and Martin Berger. Search-based regular expression inference on a GPU.Proc. ACM Program. Lang., 7(PLDI):1317–1339,
-
[19]
doi: 10.1145/3591274. URL https://doi. org/10.1145/3591274. Mojtaba Valizadeh, Nathanaël Fijalkow, and Martin Berger. LTL learning on GPUs. In Arie Gurfinkel and Vijay Ganesh, editors,Computer Aided Verification - 36th International Conference, CAV 2024, Montreal, QC, Canada, July 24-27, 2024, Proceedings, Part III, Lecture Notes in Computer Science, page...
-
[20]
URL https://doi.org/10.1007/978-3-031-65633-0_10
doi: 10.1007/978-3-031-65633-0\_10. URL https://doi.org/10.1007/978-3-031-65633-0_10. Hui Wei, Ting Liu, Shuai Wang, and Chengyu Hu. Unifying mixed Boolean-arithmetic obfuscation by architectural and anti-generalization hardening.Computers & Security,
-
[21]
Information hiding in software with mixed boolean-arithmetic transforms
11 Yongxin Zhou, Alec Main, Yuan Xiang Gu, and Harold Johnson. Information hiding in software with mixed boolean-arithmetic transforms. In Sehun Kim, Moti Yung, and Hyung-Woo Lee, editors,Information Security Applications, 8th International Workshop, WISA 2007, Jeju Island, Korea, August 27-29, 2007, Revised Selected Papers, Lecture Notes in Computer Scie...
work page 2007
-
[22]
URL https://doi.org/10.1007/ 978-3-540-77535-5_5
doi: 10.1007/978-3-540-77535-5\_5. URL https://doi.org/10.1007/ 978-3-540-77535-5_5. A Comparison with Existing Tools 1 2 3 4 5 6 7 8 9 10 Number of variables 0 20 40 60 80 100Instances solved (%) Algorithm SIMBA VFB cvc5 Figure 4: Percentage of instances solved by each algorithm across varying numbers of variables. B Cache Size and Efficiency Tables The ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.