Recognition: no theorem link
LLM Translation of Compiler Intermediate Representation
Pith reviewed 2026-05-12 00:54 UTC · model grok-4.3
The pith
A fine-tuned 14-billion-parameter model translates GCC GIMPLE to LLVM IR more accurately than models up to 70 times larger.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
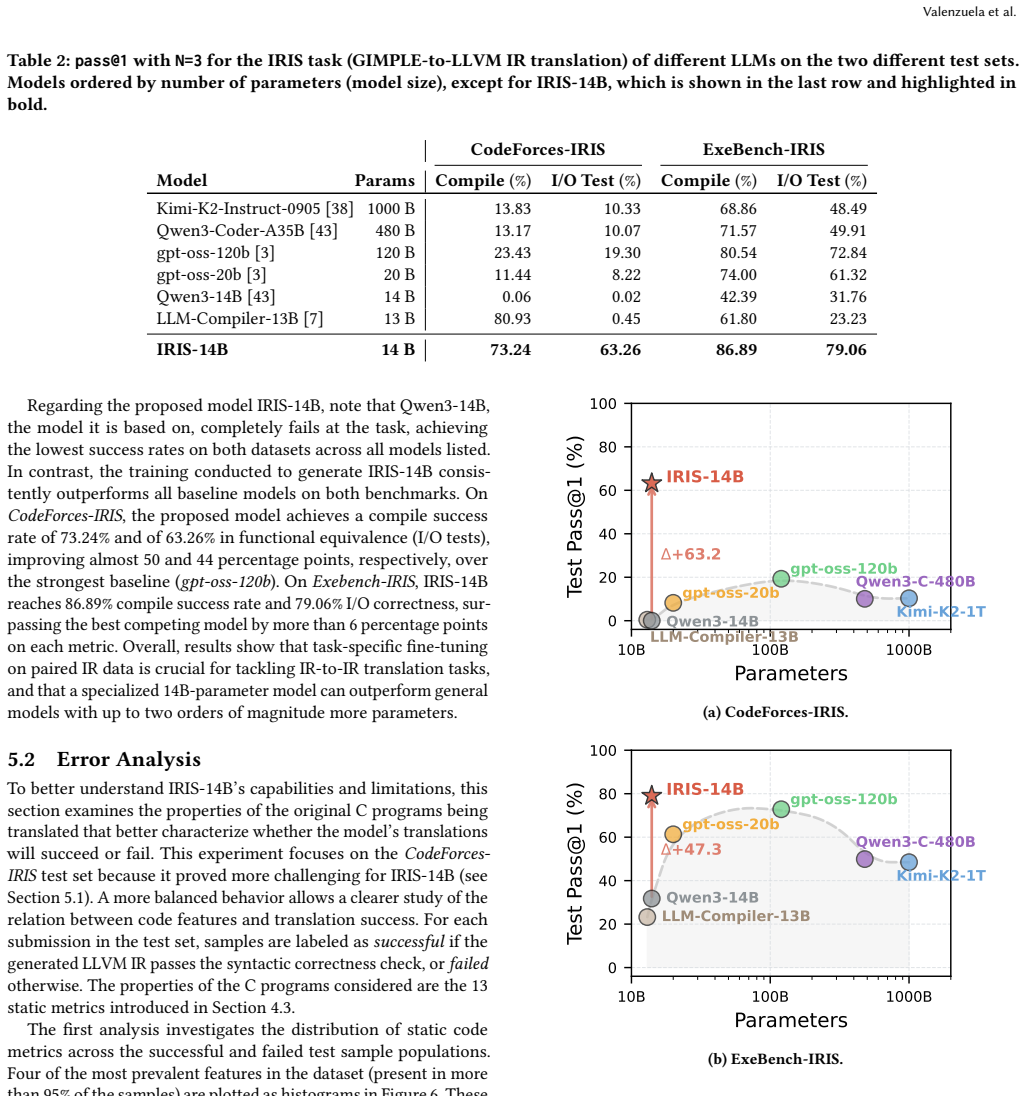
IRIS-14B is the first model explicitly trained for GIMPLE-to-LLVM-IR translation; when evaluated on IRs derived from real C sources and programming problems, it outperforms widely used open models (13B to 1000B parameters) by as much as 44 percentage points and thereby supports the insertion of LLMs as interchangeable bridges between otherwise incompatible compiler toolchains.
What carries the argument
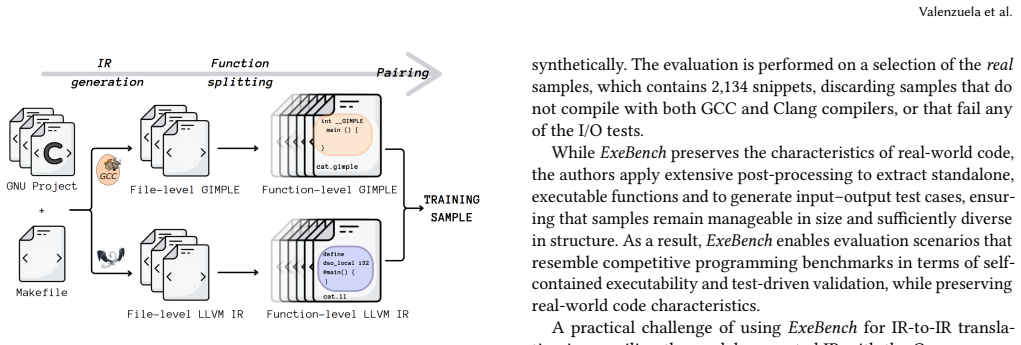
IRIS-14B, a 14B-parameter transformer fine-tuned on paired GIMPLE and LLVM IR sequences extracted from the same C sources.
If this is right
- Front-end and back-end passes written for one toolchain become reusable in the other without rewriting rule-based translators.
- Hybrid compiler pipelines can keep all existing deterministic optimization passes unchanged while using the model only for the IR conversion step.
- Cross-toolchain workflows become feasible for any language that both GCC and LLVM already support, without new manual engineering effort.
Where Pith is reading between the lines
- The same training recipe could be applied to other pairs of IRs or to translation between IR and source-level representations.
- If accuracy holds on larger codebases, maintenance cost for custom IR translators could drop from ongoing rule engineering to periodic retraining on fresh paired data.
- Integration tests that feed translated IR directly into production LLVM optimization passes would reveal whether the model preserves enough invariants for real deployment.
Load-bearing premise
Paired IR examples drawn from C programs are representative enough for the model to learn the full semantic and structural mappings between GIMPLE and LLVM IR without producing errors that would break later compilation steps.
What would settle it
Compile a set of programs from their original C source, translate the emitted GIMPLE to LLVM IR with IRIS-14B, then compile and run the resulting LLVM IR and check whether every program produces identical output to the original binary.
Figures






read the original abstract
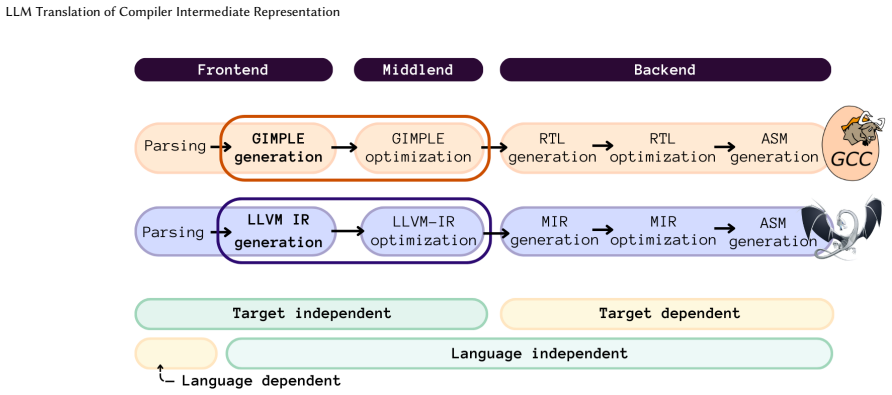
GCC and LLVM underpin much of modern software infrastructure, relying on distinct Intermediate Representations (IRs) to drive optimizations and code generation. However, the semantic and structural differences between these IRs create significant barriers for cross-toolchain interaction, limiting the reuse of compiler frontends, backends, and optimization pipelines across programming languages and compilation ecosystems. Traditional rule-based translators have attempted to bridge this gap, but their complexity and maintenance cost have hindered practical adoption. In this context, Large Language Models (LLMs) appear to be an emerging technology that offers a data-driven alternative, capable of learning complex mappings between heterogeneous compiler IRs directly from sufficiently representative examples. To explore this approach, this paper presents IRIS-14B, a 14-billion-parameter transformer model fine-tuned to translate GIMPLE (as emitted by GCC) to LLVM IR (as emitted by LLVM). The model is trained on paired IRs extracted from C sources and evaluated on the GIMPLE-to-LLVM IR transformation applied to IRs derived from real-world C code and competitive programming problems. To the best of our knowledge, IRIS-14B is the first model trained explicitly for IR-to-IR translation. It outperforms the accuracy of widely used models, including the largest state-of-the-art open models available today, ranging from 13 to 1,000 billion parameters, by up to 44 percentage points. The proposed transformation supports the integration of LLMs as complementary components within hybrid neuro-symbolic compiler architectures, where models such as IRIS-14B act as interoperability layers enabling cross-toolchain workflows without modifying existing compiler passes, while traditional compiler infrastructure continues to perform deterministic compilation and optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IRIS-14B, a 14-billion-parameter transformer model fine-tuned on paired GIMPLE and LLVM IR extracted from C sources. It claims to be the first model trained explicitly for IR-to-IR translation and reports accuracy gains of up to 44 percentage points over zero-shot baselines ranging from 13B to 1000B parameters on held-out IRs from real-world C code and competitive programming problems. The work positions the model as an interoperability layer for hybrid neuro-symbolic compiler pipelines.
Significance. If the reported accuracy corresponds to semantically valid, compilable translations that preserve program behavior, the result would be a meaningful step toward data-driven cross-toolchain IR translation, reducing reliance on complex rule-based translators. The scale of the empirical comparison to much larger models is a positive aspect, but the absence of semantic validation limits the assessed practical significance for compiler workflows.
major comments (2)
- [Evaluation section] Evaluation section (results and experimental setup): The abstract asserts a 44 percentage point accuracy gain over much larger models, yet supplies no definition of the accuracy metric (exact match, token-level, BLEU, or otherwise), no dataset sizes or split details, no baseline configurations, and no controls for data leakage or contamination. This information is load-bearing for the central performance claim and must be provided with tables or equations specifying the metric.
- [§4] §4 (or equivalent experimental results): No evidence is presented that translated LLVM IR modules successfully compile under clang or produce identical runtime behavior on the original test inputs. Syntactic accuracy on paired IRs does not guarantee semantic equivalence for register allocation, type lowering, or control-flow mappings; without compilation and execution checks, the utility for hybrid compiler pipelines remains unproven.
minor comments (3)
- [Abstract] The abstract should include a concise statement of training dataset size and source (e.g., number of C programs and IR pairs) to allow immediate assessment of scale.
- [Related work] Related-work discussion should explicitly compare against any prior LLM-based or rule-based GIMPLE-to-LLVM translators to substantiate the 'first model' claim.
- [Figures and tables] Figure captions and table headers would benefit from explicit notation of what 'accuracy' measures in each row or column.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation clarity and semantic validation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (results and experimental setup): The abstract asserts a 44 percentage point accuracy gain over much larger models, yet supplies no definition of the accuracy metric (exact match, token-level, BLEU, or otherwise), no dataset sizes or split details, no baseline configurations, and no controls for data leakage or contamination. This information is load-bearing for the central performance claim and must be provided with tables or equations specifying the metric.
Authors: We agree that the current manuscript lacks sufficient detail on the evaluation protocol, which weakens the central claim. In the revised version we will expand the Evaluation section to formally define the accuracy metric (exact match after IR canonicalization to normalize register names and ordering), provide dataset statistics and split information, specify the zero-shot baseline configurations for all compared models, and describe contamination controls such as source deduplication and held-out test sets. These additions will be presented in tables and equations. revision: yes
-
Referee: [§4] §4 (or equivalent experimental results): No evidence is presented that translated LLVM IR modules successfully compile under clang or produce identical runtime behavior on the original test inputs. Syntactic accuracy on paired IRs does not guarantee semantic equivalence for register allocation, type lowering, or control-flow mappings; without compilation and execution checks, the utility for hybrid compiler pipelines remains unproven.
Authors: We acknowledge that syntactic exact-match accuracy is only a proxy and does not by itself establish semantic equivalence or practical utility in compiler pipelines. The manuscript positions IRIS-14B as an initial data-driven interoperability layer; to address the referee's concern we will add in revision a new subsection reporting clang compilation success rates on the translated outputs together with runtime equivalence checks on a representative subset of test inputs. Any limitations observed will be discussed explicitly. revision: yes
Circularity Check
No circularity: standard empirical ML training and held-out evaluation
full rationale
The paper presents an empirical result: fine-tuning a 14B transformer on paired GIMPLE-to-LLVM IR examples extracted from C sources, then measuring accuracy on held-out real-world and competitive-programming IR pairs. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The performance numbers (up to 44-point gains) are direct output-reference comparisons on unseen data and do not reduce to any input by construction. This is a self-contained empirical claim with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large Language Models can learn complex semantic and structural mappings between heterogeneous compiler IRs directly from sufficiently representative paired examples
Reference graph
Works this paper leans on
-
[1]
Ada Working Group ISO/IEC JTC 1/SC 22/WG 9. 2022. Ada Reference Manual. http://www.ada-auth.org/standards/22rm/RM-Final.pdf
work page 2022
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. GPT-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al . 2025. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Jordi Armengol-Estapé, Jackson Woodruff, Alexander Brauckmann, José Wesley de Souza Magalhaes, and Michael FP O’Boyle. 2022. ExeBench: an ML-scale dataset of executable C functions. InProceedings of the 6th ACM SIGPLAN Inter- national Symposium on Machine Programming. 50–59
work page 2022
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[7]
Chris Cummins, Volker Seeker, Dejan Grubisic, Baptiste Roziere, Jonas Gehring, Gabriel Synnaeve, and Hugh Leather. 2025. Llm compiler: Foundation language models for compiler optimization. InProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction. 141–153
work page 2025
- [8]
-
[9]
GCC. 2025. DragonEgg. https://dragonegg.llvm.org/
work page 2025
-
[10]
GCC Developer Community. 2019. GIMPLE FE: A Gimple Front End. https: //gcc.gnu.org/wiki/GimpleFrontEnd. Accessed: 11 December 2025
work page 2019
-
[11]
GitHub. 2025. Copilot. https://github.com/copilot
work page 2025
-
[12]
GNU Project. 2026. GNU Software. https://www.gnu.org/software/software. html#allgnupkgs Accessed: 2026-03-11
work page 2026
- [13]
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Zifan (Carl) Guo and William S. Moses. 2022. Understanding high-level properties of low-level programs through transformers. https://api.semanticscholar.org/ CorpusID:251439807
work page 2022
- [16]
- [17]
-
[18]
Chris Lattner and Vikram Adve. 2004. LLVM: A compilation framework for lifelong program analysis & transformation. InInternational symposium on code generation and optimization, 2004. CGO 2004.IEEE, 75–86
work page 2004
-
[19]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Olek- sandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 2–14. doi:10.1109/CGO51591.2021.9370308
-
[20]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with Alphacode.Science378, 6624 (2022), 1092–1097
work page 2022
-
[21]
LLVM. 2004. llvm-gcc: LLVM C front-end. https://releases.llvm.org/1.3/docs/ CommandGuide/html/llvmgcc.html. Valenzuela et al
work page 2004
-
[22]
LLVM Project. 2024. LLVM Language Reference Manual. https://llvm.org/docs/ LangRef.html. Accessed: 2026-03-16
work page 2024
-
[23]
Nuno P Lopes, Juneyoung Lee, Chung-Kil Hur, Zhengyang Liu, and John Regehr
-
[24]
Alive2: bounded translation validation for LLVM. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. 65–79
-
[25]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Sirui Mu. 2024. mlir-gccjit. https://github.com/Lancern/mlir-gccjit
work page 2024
-
[27]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to help with code understanding. In46th International Conference on Software Engineering. 1–13
work page 2024
-
[28]
OpenAI. 2025. Codex. https://openai.com/codex
work page 2025
-
[29]
Zhenyu Pan, Xuefeng Song, Yunkun Wang, Rongyu Cao, Binhua Li, Yongbin Li, and Han Liu. 2025. Do Code LLMs Understand Design Patterns?. InIEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 209–212
work page 2025
- [30]
-
[31]
Guilherme Penedo, Anton Lozhkov, Hynek Kydlíček, Loubna Ben Allal, Edward Beeching, Agustín Piqueres Lajarín, Quentin Gallouédec, Nathan Habib, Lewis Tunstall, and Leandro von Werra. 2025. CodeForces. https://huggingface.co/ datasets/open-r1/codeforces
work page 2025
-
[32]
Rust-GCC Project. 2025. gccrs: GCC Rust Front-End. https://github.com/Rust- GCC/gccrs. Accessed: 11 December 2025
work page 2025
-
[33]
Nishath Rajiv Ranasinghe, Shawn M Jones, Michal Kucer, Ayan Biswas, Daniel O’Malley, Alexander Most, Selma Liliane Wanna, and Ajay Sreekumar. 2025. LLM-assisted translation of legacy FORTRAN codes to C++: A cross-platform study. In1st Workshop on AI and Scientific Discovery: Directions and Opportunities. 58–69
work page 2025
-
[34]
Jeremy Rifkin. 2024. Wyrm. https://github.com/jeremy-rifkin/wyrm
work page 2024
-
[35]
Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample
-
[36]
Unsupervised translation of programming languages.Advances in neural information processing systems33 (2020), 20601–20611
work page 2020
-
[37]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
work page 2024
- [38]
-
[39]
Zujun Tan, Yebin Chon, Michael Kruse, Johannes Doerfert, Ziyang Xu, Brian Homerding, Simone Campanoni, and David I August. 2023. Splendid: Supporting parallel LLVM-IR enhanced natural decompilation for interactive development. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V...
work page 2023
-
[40]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
2022.Decompilation of Binaries into LLVM IR for Automated Analysis
Tejvinder Toor. 2022.Decompilation of Binaries into LLVM IR for Automated Analysis. Ph. D. Dissertation. University of Waterloo
work page 2022
-
[42]
Andrea Valenzuela, Marta Gonzalez-Mallo, Cristian Gutierrez, Dario Garcia- Gasulla, Gokcen Kestor, and Sara Royuela. 2025. From C to Rust: Evaluating LLM Capabilities in Transpilation Through Compilation Errors. InInternational Conference on High Performance Computing. Springer, 311–324
work page 2025
-
[43]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[44]
Niklaus Wirth. 1982.Programming in Modula-2. Springer-Verlag, Berlin, Heidel- berg
work page 1982
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
Shuoming Zhang, Jiacheng Zhao, Qiuchu Yu, Chunwei Xia, Zheng Wang, Xiaob- ing Feng, and Huimin Cui. 2026. The new compiler stack: a survey on the synergy of LLMs and compilers.CCF Transactions on High Performance Computing(2026), 1–32
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.