Recognition: no theorem link
Why Do DiT Editors Drift? Plug-and-Play Low Frequency Alignment in VAE Latent Space
Pith reviewed 2026-05-12 02:36 UTC · model grok-4.3
The pith
DiT image editors accumulate semantic drift mainly from low-frequency shifts in VAE latent space, and a simple alignment to prior-round averages corrects it without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
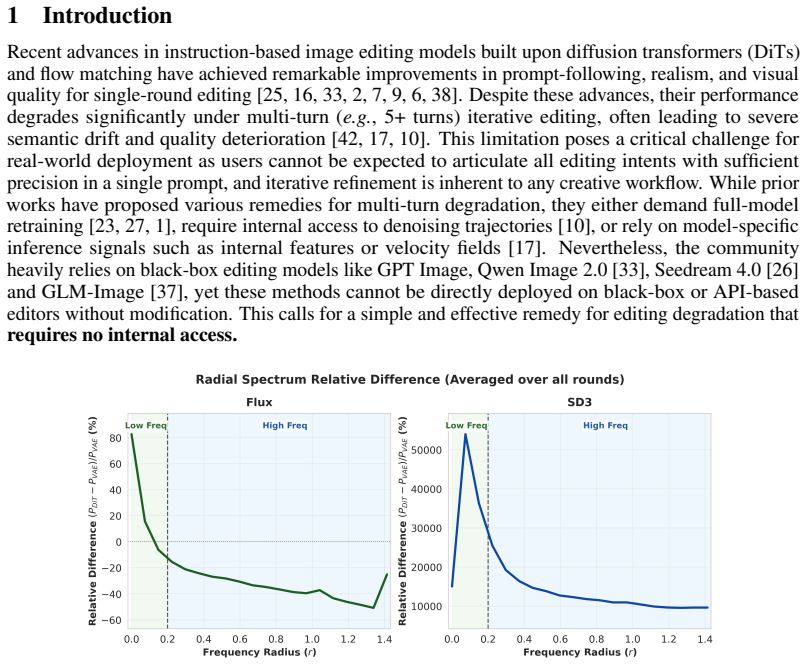
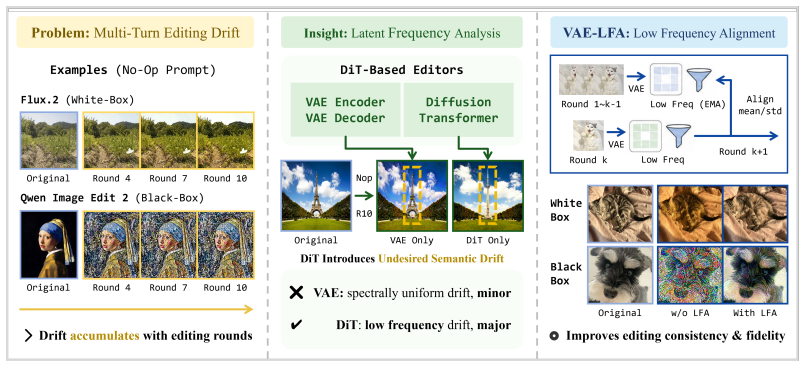
Through systematic analysis in the VAE latent space, the DiT introduces dominant low-frequency drift that accumulates as semantic misalignment across editing rounds, while the VAE contributes comparatively stable reconstruction bias. VAE-LFA decomposes latent discrepancies across editing rounds via low-pass filtering, and aligns low-frequency statistics to an exponential moving average of previous rounds, effectively suppressing accumulated semantic drift while preserving high-frequency details.
What carries the argument
VAE-LFA, which isolates low-frequency latent discrepancies with low-pass filtering and aligns their statistics to an exponential moving average of prior editing rounds.
If this is right
- Multi-turn editing sequences maintain semantic consistency without progressive quality loss.
- The correction applies to both white-box pipelines that can skip redundant VAE steps and black-box editors using an off-the-shelf VAE.
- High-frequency image content such as textures and edges remains unchanged during the alignment.
- No ground-truth data or model updates are needed, so the method works immediately on existing DiT editors.
Where Pith is reading between the lines
- The same low-frequency alignment idea could be tested on other latent diffusion models that show similar round-to-round drift.
- Longer editing chains, such as iterative refinement of a single image over dozens of steps, would become more reliable for practical design tools.
- If low-frequency alignment reduces drift, it might also lessen the need for careful prompt re-engineering between editing rounds.
Load-bearing premise
Low-frequency components in the latent space are the main driver of semantic drift and can be corrected by alignment to a running average without erasing needed details or creating new artifacts.
What would settle it
Running multi-turn edits with VAE-LFA applied and finding that semantic similarity scores to the original image still decline steadily over rounds, or that new high-frequency artifacts appear, would show the alignment does not address the drift.
Figures










read the original abstract
Recent advances in diffusion transformers (DiTs) have enabled promising single-turn image editing capabilities. However, multi-turn editing often leads to progressive semantic drift and quality degradation.In this work, we study this problem from a latent-space frequency perspective by decomposing the editing process into two functional components: VAE and DiT. Through systematic analysis in the VAE latent space, we uncover that the DiT introduces dominant low-frequency drift that accumulates as semantic misalignment across editing rounds, while the VAE contributes comparatively stable reconstruction bias.Based on this insight, we propose VAE-LFA (Low Frequency Alignment), a training-free, plug-and-play method that performs alignment in VAE latent space. VAE-LFA decomposes latent discrepancies across editing rounds via low-pass filtering, and aligns low-frequency statistics to an exponential moving average of previous rounds, effectively suppressing accumulated semantic drift while preserving high-frequency details.Our method requires no retraining, ground-truth priors, or access to diffusion parameters, making it applicable to both white-box and black-box DiT editors. For white-box models, VAE-LFA is seamlessly integrated into the editing pipeline by eliminating redundant VAE round trips; for black-box models, it operates via an off-the-shelf VAE to perform inter-round latent alignment.Extensive experiments demonstrate that VAE-LFA improves semantic consistency and visual fidelity across diverse multi-turn editing scenarios, including both controlled and in-the-wild images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic drift in multi-turn DiT image editing arises primarily from dominant low-frequency drift introduced by the DiT in VAE latent space (with VAE contributing only stable reconstruction bias). It proposes VAE-LFA, a training-free plug-and-play method that decomposes latent discrepancies via low-pass filtering and aligns low-frequency statistics to an EMA of prior rounds to suppress accumulated drift while preserving high-frequency details. The approach requires no retraining or ground truth, works for white-box (by skipping redundant VAE trips) and black-box DiT editors (via off-the-shelf VAE), and is validated through experiments on controlled and in-the-wild multi-turn editing scenarios showing gains in semantic consistency and visual fidelity.
Significance. If the frequency-based attribution and method hold, this would be a useful practical contribution to iterative diffusion-based editing, a common but fragile workflow. The training-free, black-box compatible design lowers the barrier to adoption compared to retraining-based fixes. The latent-space frequency decomposition offers a reusable insight for analyzing drift in other generative pipelines. Strengths include the plug-and-play nature and explicit separation of DiT vs. VAE effects; significance is tempered by the need for rigorous quantification of the low-frequency dominance.
major comments (2)
- [Analysis section] Analysis section: The central claim that DiT introduces 'dominant low-frequency drift' that accumulates as semantic misalignment is load-bearing for the entire VAE-LFA proposal, yet the manuscript provides no explicit quantification such as frequency-decomposed L2 norms on latent deltas, CLIP similarity scores on low-pass vs. high-pass filtered components, or ablations that isolate low-frequency removal. Without these, it is unclear whether low-frequency components are truly the primary driver versus other factors in the editing loop.
- [Method and Experiments sections] Method and Experiments sections: The assumption that low-frequency EMA alignment suppresses drift without losing necessary high-frequency semantic information or introducing new artifacts is not supported by controlled ablations (e.g., varying low-pass cutoff frequencies, EMA decay rates, or comparisons against full-latent alignment or high-frequency-only baselines). This directly affects whether VAE-LFA is complete or could be misdirected.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction could more explicitly list the DiT architectures tested, number of editing rounds, and quantitative metrics (e.g., CLIP similarity, LPIPS) used in the 'extensive experiments' to improve reproducibility and clarity.
- [Method section] Notation for the low-pass filter and EMA update rule should be formalized with equations early in the method section for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional rigor can strengthen the central claims and validation of VAE-LFA. We respond point by point below and commit to revisions that directly address the concerns without altering the core contributions.
read point-by-point responses
-
Referee: [Analysis section] Analysis section: The central claim that DiT introduces 'dominant low-frequency drift' that accumulates as semantic misalignment is load-bearing for the entire VAE-LFA proposal, yet the manuscript provides no explicit quantification such as frequency-decomposed L2 norms on latent deltas, CLIP similarity scores on low-pass vs. high-pass filtered components, or ablations that isolate low-frequency removal. Without these, it is unclear whether low-frequency components are truly the primary driver versus other factors in the editing loop.
Authors: We acknowledge that while the analysis section presents systematic decomposition of latent discrepancies via low-pass filtering and visual evidence of low-frequency accumulation across rounds (with VAE bias shown as stable), it lacks the explicit numerical quantifications suggested. In the revised manuscript we will add frequency-decomposed L2 norms computed on the low-pass and high-pass components of latent deltas between consecutive editing steps, as well as CLIP similarity scores on images decoded from low-pass versus high-pass filtered latents. We will also include an ablation that removes only the low-frequency component to isolate its contribution to semantic drift. These additions will provide the requested quantitative support for the dominance claim. revision: yes
-
Referee: [Method and Experiments sections] Method and Experiments sections: The assumption that low-frequency EMA alignment suppresses drift without losing necessary high-frequency semantic information or introducing new artifacts is not supported by controlled ablations (e.g., varying low-pass cutoff frequencies, EMA decay rates, or comparisons against full-latent alignment or high-frequency-only baselines). This directly affects whether VAE-LFA is complete or could be misdirected.
Authors: We agree that controlled ablations are necessary to fully substantiate the design of VAE-LFA. The current experiments report overall gains and basic sensitivity analysis, but we will expand the experiments section in revision to include: (i) results across a range of low-pass cutoff frequencies, (ii) sweeps over EMA decay rates, and (iii) direct comparisons against full-latent EMA alignment and high-frequency-only alignment baselines. These will be evaluated using both perceptual metrics and semantic consistency measures to demonstrate that low-frequency alignment preserves high-frequency details without introducing artifacts. This will confirm the method targets the primary source of drift. revision: yes
Circularity Check
No circularity; empirical analysis with independent standard components
full rationale
The paper performs an empirical decomposition of editing drift in VAE latent space using low-pass filtering and proposes alignment to an EMA of prior rounds. These operations are defined independently of the final performance metrics and do not reduce to fitted parameters or self-citations by construction. No self-definitional equations, no renaming of known results as new derivations, and no load-bearing self-citation chains appear in the abstract or described method. The derivation chain remains self-contained against external benchmarks such as standard signal-processing filters and EMA, warranting a zero circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-frequency components in VAE latent space are the primary carrier of accumulated semantic drift during multi-turn DiT editing.
Reference graph
Works this paper leans on
-
[1]
Reed-vae: Re-encode decode training for iterative image editing with diffusion models
Gal Almog, Ariel Shamir, and Ohad Fried. Reed-vae: Re-encode decode training for iterative image editing with diffusion models. InComputer Graphics Forum, volume 44, page e70020. Wiley Online Library, 2025
work page 2025
-
[2]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
work page 2023
-
[3]
Tianyu Chen, Yasi Zhang, Zhi Zhang, Peiyu Yu, Shu Wang, Zhendong Wang, Kevin Lin, Xiaofei Wang, Zhengyuan Yang, Linjie Li, et al. Edival-agent: An object-centric framework for automated, fine-grained evaluation of multi-turn editing.arXiv preprint arXiv:2509.13399, 2025
-
[4]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[5]
Dero: Diffusion-model-erasure robust watermarking
Han Fang, Kejiang Chen, Yupeng Qiu, Zehua Ma, Weiming Zhang, and Ee-Chien Chang. Dero: Diffusion-model-erasure robust watermarking. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2973–2981, 2024
work page 2024
-
[6]
arXiv preprint arXiv:2309.17102 (2023)
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guid- ing instruction-based image editing via multimodal large language models.arXiv preprint arXiv:2309.17102, 2023
-
[7]
Instructdiffusion: A generalist modeling interface for vision tasks
Zigang Geng, Binxin Yang, Tiankai Hang, Chen Li, Shuyang Gu, Ting Zhang, Jianmin Bao, Zheng Zhang, Houqiang Li, Han Hu, et al. Instructdiffusion: A generalist modeling interface for vision tasks. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 12709–12720, 2024
work page 2024
-
[8]
Understanding latent diffusability via fisher geometry, 2026
Jing Gu, Morteza Mardani, Wonjun Lee, Dongmian Zou, and Gilad Lerman. Understanding latent diffusability via fisher geometry, 2026
work page 2026
-
[9]
Smartedit: Exploring complex instruction- based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction- based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362–8371, 2024
work page 2024
-
[10]
Improving editability in image generation with layer-wise memory
Daneul Kim, Jaeah Lee, and Jaesik Park. Improving editability in image generation with layer-wise memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7889–7898, 2025
work page 2025
-
[11]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[12]
Gwanhyeong Koo, Sunjae Yoon, Ji Woo Hong, and Chang D. Yoo. Flexiedit: Frequency-aware latent refinement for enhanced non-rigid editing, 2024
work page 2024
-
[13]
Eq-vae: Equivariance regularized latent space for improved generative image modeling, 2025
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Eq-vae: Equivariance regularized latent space for improved generative image modeling, 2025
work page 2025
-
[14]
Vision-xl: High definition video inverse problem solver using latent image diffusion models
Taesung Kwon and Jong Chul Ye. Vision-xl: High definition video inverse problem solver using latent image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10465–10474, 2025
work page 2025
-
[15]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
work page 2025
-
[16]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Yucheng Liao, Jiajun Liang, Kaiqian Cui, Baoquan Zhao, Haoran Xie, Wei Liu, Qing Li, and Xudong Mao. Freqedit: Preserving high-frequency features for robust multi-turn image editing. arXiv preprint arXiv:2512.01755, 2025
-
[18]
Yilin Liu, Yunkui Pang, Jiang Li, Yong Chen, and Pew-Thian Yap. Architecture-agnostic untrained network priors for image reconstruction with frequency regularization. InEuropean Conference on Computer Vision, pages 341–358. Springer, 2024
work page 2024
-
[19]
Xianping Ma, Xiaokang Zhang, Xingchen Ding, Man-On Pun, and Siwei Ma. Decomposition- based unsupervised domain adaptation for remote sensing image semantic segmentation, 2024
work page 2024
-
[20]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Zehong Ma, Longhui Wei, Shuai Wang, Shiliang Zhang, and Qi Tian. Deco: Frequency- decoupled pixel diffusion for end-to-end image generation.arXiv preprint arXiv:2511.19365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Missing fine details in images: Last seen in high frequencies, 2025
Tejaswini Medi, Hsien-Yi Wang, Arianna Rampini, and Margret Keuper. Missing fine details in images: Last seen in high frequencies, 2025
work page 2025
-
[22]
Blaschko, Albert Ali Salah, and Itir Onal Ertugrul
Mang Ning, Mingxiao Li, Le Zhang, Lanmiao Liu, Matthew B. Blaschko, Albert Ali Salah, and Itir Onal Ertugrul. Spectrum matching: a unified perspective for superior diffusability in latent diffusion, 2026
work page 2026
-
[23]
Vincie: Unlocking in-context image editing from video
Leigang Qu, Feng Cheng, Ziyan Yang, Qi Zhao, Shanchuan Lin, Yichun Shi, Yicong Li, Wenjie Wang, Tat-Seng Chua, and Lu Jiang. Vincie: Unlocking in-context image editing from video. InThe Fourteenth International Conference on Learning Representations, 2025
work page 2025
-
[24]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026
work page 2026
-
[25]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[26]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871–8879, 2024
work page 2024
-
[28]
Zitao Shuai, Chenwei Wu, Zhengxu Tang, Bowen Song, and Liyue Shen. Latent space disentan- glement in diffusion transformers enables precise zero-shot semantic editing.arXiv preprint arXiv:2411.08196, 2024
-
[29]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jinzhe Tu, Ruilei Guo, Zihan Guo, Junxiao Yang, Shiyao Cui, and Minlie Huang. Smsp: A plug-and-play strategy of multi-scale perception for mllms to perceive visual illusions, 2026
work page 2026
-
[31]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/ diffusers, 2022
work page 2022
-
[32]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
work page 2004
-
[33]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Wei Wu, Qingnan Fan, Shuai Qin, Hong Gu, Ruoyu Zhao, and Antoni B. Chan. Freediff: Progressive frequency truncation for image editing with diffusion models, 2024
work page 2024
-
[35]
Structured spectral reasoning for frequency-adaptive multimodal recommendation, 2026
Wei Yang, Rui Zhong, Yiqun Chen, Chi Lu, and Peng Jiang. Structured spectral reasoning for frequency-adaptive multimodal recommendation, 2026
work page 2026
-
[36]
I2e: From image pixels to actionable interactive environments for text-guided image editing, 2026
Jinghan Yu, Junhao Xiao, Chenyu Zhu, Jiaming Li, Jia Li, HanMing Deng, Xirui Wang, Guoli Jia, Jianjun Li, Xiang Bai, Bowen Zhou, and Zhiyuan Ma. I2e: From image pixels to actionable interactive environments for text-guided image editing, 2026
work page 2026
-
[37]
GLM-Image: Auto-regressive for dense-knowledge and high-fidelity image generation, January 2026
Z.ai. GLM-Image: Auto-regressive for dense-knowledge and high-fidelity image generation, January 2026
work page 2026
-
[38]
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
work page 2023
-
[39]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric, 2018
work page 2018
-
[40]
Chen Zhao, Jiawei Chen, Hongyu Li, Zhuoliang Kang, Shilin Lu, Xiaoming Wei, Kai Zhang, Jian Yang, and Ying Tai. Luve: Latent-cascaded ultra-high-resolution video generation with dual frequency experts.arXiv preprint arXiv:2602.11564, 2026
-
[41]
Ultraedit: Instruction-based fine-grained image editing at scale, 2024
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale, 2024
work page 2024
-
[42]
Zijun Zhou, Yingying Deng, Xiangyu He, Weiming Dong, and Fan Tang. Multi-turn consistent image editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15792–15801, 2025. 13 A Impact Statement V AE-LFA aims to improve the stability and consistency of multi-turn image editing, which can benefit creative workflows, visual de...
work page 2025
-
[43]
After Turn 10 the image should ideally return to the original state
Each pair (Turn 2k-1, Turn 2k) must be strict semantic opposites. After Turn 10 the image should ideally return to the original state
-
[44]
Prompts must be concrete and executable: include specific colors, materials, positions, or styles. Avoid vague words like "make it better" or "adjust"
-
[45]
Do NOT introduce irreversible changes (e.g., permanent background destruction, subject replacement, cropping, or adding watermarks)
-
[46]
Do NOT refer to previous turns with pronouns like "it" or "the previous change". Each prompt must be self-contained
-
[47]
Output format: a single JSON array of exactly 10 strings. No markdown, no explanation, no code block fences. Just the raw JSON array. 19 System Prompt: Long-Chain Editing You are an expert image-editing instruction generator specialized in creating progressive, cumulative editing prompts for academic research on multi-turn image editing. Your task: Given ...
-
[48]
Adjacent turns should feel like natural next steps in a creative workflow, not random jumps
The 10 prompts must form a logically coherent chain. Adjacent turns should feel like natural next steps in a creative workflow, not random jumps
-
[49]
Each prompt must be self-contained and specific: include exact colors, styles, lighting descriptors, weather, or environmental details
-
[50]
Do NOT use pronouns like "it" or "that". Refer to subjects explicitly (e.g., "the girl", "the building", "the mountain")
-
[51]
Do NOT issue identity-preserving prompts like "keep unchanged". Every prompt must actively edit the image
-
[52]
Output format: a single JSON array of exactly 10 strings. No markdown, no explanation, no code block fences. Just the raw JSON array. Example Data Point "image": "017.png", "category": "creature", "cycle": [ "Change the character’s hair color from red to platinum blonde.", "Restore the character’s hair color to its original vibrant red.", "Change the char...
-
[53]
salient_object: The image is primarily scene-dominant or layout-dominant. The visual semantics depend strongly on the broader environment, background, or spatial composition rather than a single foreground object. Typical examples include architecture, landscapes, street scenes, interiors, and other large-scale scenes
-
[54]
clear_object: The image contains one clearly identifiable main subject that dominates visual attention. The semantics are mainly determined by this foreground subject rather than the surrounding environment. Typical examples include a single creature, person, product, or other salient object with a relatively simple supporting background. Instructions: - ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.