Recognition: no theorem link
Do not copy and paste! Rewriting strategies for code retrieval
Pith reviewed 2026-05-12 01:22 UTC · model grok-4.3
The pith
Full natural-language rewriting of queries and code boosts retrieval performance, while corpus-only changes usually hurt and token-entropy shift predicts the gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transforming both queries and code snippets into full natural-language descriptions yields the largest retrieval gains across six CoIR benchmarks, five encoders, and three LLM rewriters. This strategy outperforms lighter stylistic or pseudo-code rewrites. Corpus-only rewriting degrades performance in 56 of 90 configurations. The change in token entropy between original and rewritten text, termed Delta H, shows consistent positive Spearman correlation with retrieval gains and functions as a cheap, rewriter-agnostic signal for deciding when rewriting pays off.
What carries the argument
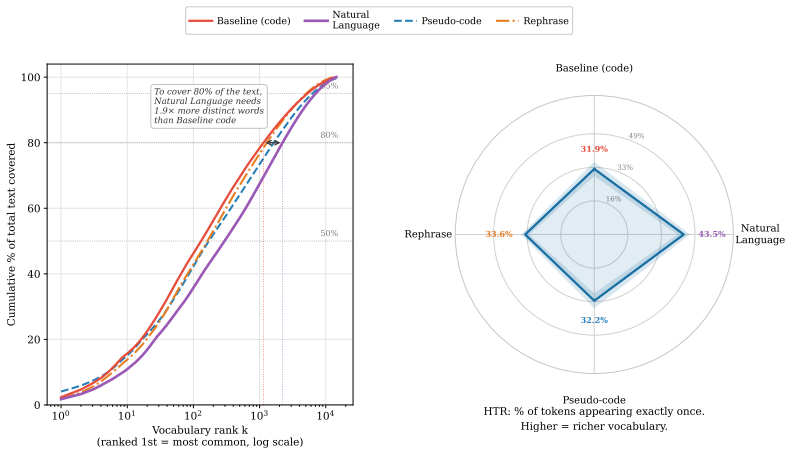
Hierarchy of three rewriting strategies (stylistic rephrasing, NL-enriched PseudoCode, full Natural-Language transcription) under joint query-corpus or corpus-only modes, with Delta H (token-entropy delta) serving as the predictive proxy for retrieval improvement.
If this is right
- Rewriting pays off most when used as a remediation layer for lightweight encoders on code-dominant queries.
- Strong encoders and queries already rich in natural language see smaller or no benefit.
- Delta H can be computed first to avoid unnecessary LLM calls on queries unlikely to improve.
- Full natural-language versions can replace the original snippets as the indexed representation rather than serving only as temporary aids.
Where Pith is reading between the lines
- Retrieval pipelines could compute Delta H on the fly and invoke the rewriter only when the value exceeds a threshold, turning an expensive step into a conditional one.
- The same entropy-based filter might generalize to other embedding-retrieval settings where surface-form mismatch reduces similarity scores.
- Hybrid systems that keep original code for strong encoders and apply full NL only for weaker ones become practical if Delta H remains reliable.
- Testing whether analogous cheap proxies exist for non-code domains such as legal or medical document retrieval would clarify the scope of the finding.
Load-bearing premise
The observed gains from full natural-language rewriting and the predictive power of Delta H will continue to hold for code-retrieval tasks, encoders, and rewriters outside the six benchmarks and three model families tested.
What would settle it
A follow-up experiment on a new code-retrieval benchmark or encoder family that finds either no positive correlation between Delta H and retrieval gains or consistent improvements from corpus-only rewriting.
Figures




read the original abstract
Embedding-based code retrieval often suffers when encoders overfit to surface syntax. Prior work mitigates this by using LLMs to rephrase queries and corpora into a normalized style, but leaves two questions open: how much representational shift helps, and when is the per-query LLM call justified? We study a hierarchy of three rewriting strategies: stylistic rephrasing, NL-enriched PseudoCode, and full Natural-Language transcription, under joint query-corpus (QC, online) and corpus-only (C, offline) augmentation, across six CoIR benchmarks, five encoders, and three rewriters spanning independent model families (Qwen, DeepSeek, Mistral). We are the first to evaluate NL-enriched PseudoCode and snippet-level Natural Language as direct retrieval representations, rather than as transient intermediates. Full NL rewriting with QC yields the largest gains (+0.51 absolute NDCG@10 on CT-Contest for MoSE-18), while corpus-only rewriting degrades retrieval in 56 of 90 configurations, about 62%. We introduce two diagnostics, Delta H, token entropy, and Delta s, embedding cosine, and show that Delta H predicts retrieval gain under QC across all three rewriter families: pooled Spearman rho = +0.436, p < 0.001 on DeepSeek+Codestral; rho = +0.593 on Codestral alone; rho = +0.356 on Qwen. This establishes Delta H as a cheap, rewriter-agnostic proxy for deciding when rewriting pays off before running retrieval. Our analysis reframes LLM rewriting as a cost-benefit decision: it is most effective as a remediation layer for lightweight encoders on code-dominant queries, with diminishing returns for strong encoders or NL-heavy queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates a hierarchy of LLM-based rewriting strategies (stylistic rephrasing, NL-enriched PseudoCode, and full Natural Language transcription) for improving embedding-based code retrieval. It compares joint query-corpus (QC) versus corpus-only (C) augmentation across six CoIR benchmarks, five encoders, and three rewriters from different families. Key empirical findings include the largest gains from full NL rewriting under QC (e.g., +0.51 absolute NDCG@10 on CT-Contest for MoSE-18), degradation from corpus-only rewriting in 56 of 90 configurations (~62%), and the introduction of Delta H (token entropy difference) as a predictor of QC retrieval gains with pooled Spearman rho = +0.436 (p < 0.001). Delta H is positioned as a cheap, rewriter-agnostic pre-retrieval proxy, with the work reframing rewriting as a cost-benefit decision most useful for lightweight encoders on code-dominant queries.
Significance. If the quantitative results hold, the paper makes a useful empirical contribution by systematically comparing rewriting granularities and augmentation modes, while being the first to treat NL-enriched PseudoCode and snippet-level NL as direct retrieval representations. The multi-benchmark, multi-encoder, multi-rewriter design (90 configurations total) and consistent reporting of specific deltas and correlations provide a solid foundation for the claims within the tested scope. The Delta H diagnostic, if generalizable, offers a practical low-cost signal for deciding when LLM calls are justified, addressing an open question in prior rewriting work.
major comments (2)
- [Results and Analysis] The claim that Delta H is a rewriter-agnostic proxy for retrieval gain under QC (pooled rho = +0.436 across families, with per-family values +0.593 and +0.356) rests entirely on the six CoIR benchmarks and three rewriters tested. No cross-benchmark hold-out validation, out-of-distribution encoder experiments, or controls for query-type confounders (code-dominant vs. NL-dominant) are described, which is load-bearing for the practical recommendation to deploy Delta H as a pre-retrieval decision tool beyond the current suite. (Results and Analysis sections reporting the Spearman correlations and pooled statistics)
- [Experimental Results] The statement that corpus-only rewriting degrades retrieval in 56 of 90 configurations (~62%) is presented as a general finding, but the manuscript provides no breakdown by benchmark, encoder, or rewriter family to show whether this is uniformly distributed or driven by particular subsets of the CoIR collection. This detail is needed to support the broader conclusion that corpus-only augmentation is rarely justified. (Experimental results tables or figures enumerating the 90 configurations)
minor comments (2)
- The abstract and main text should include explicit formulas or definitions for Delta H (token entropy) and Delta s (embedding cosine) at first use, rather than assuming readers infer them from the names and reported correlations.
- All reported NDCG@10 gains and correlation coefficients should be accompanied by error bars, standard deviations, or confidence intervals (e.g., via bootstrap or multiple runs) to allow readers to assess variability, especially for the +0.51 absolute gain example.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the empirical scope. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Results and Analysis] The claim that Delta H is a rewriter-agnostic proxy for retrieval gain under QC (pooled rho = +0.436 across families, with per-family values +0.593 and +0.356) rests entirely on the six CoIR benchmarks and three rewriters tested. No cross-benchmark hold-out validation, out-of-distribution encoder experiments, or controls for query-type confounders (code-dominant vs. NL-dominant) are described, which is load-bearing for the practical recommendation to deploy Delta H as a pre-retrieval decision tool beyond the current suite. (Results and Analysis sections reporting the Spearman correlations and pooled statistics)
Authors: We acknowledge that our evaluation of Delta H is confined to the six CoIR benchmarks and three rewriter families, without explicit cross-benchmark hold-out or OOD encoder experiments. The pooled Spearman rho of +0.436 (p < 0.001) and per-family correlations (+0.593 and +0.356) demonstrate consistency within the tested multi-benchmark, multi-rewriter design. We agree that controls for query-type confounders would strengthen claims for broader deployment. In revision, we will expand the Results and Analysis sections with a discussion of these limitations, add a leave-one-benchmark-out analysis on existing data to probe robustness, and include a breakdown of correlations by query-type (code-dominant vs. NL-dominant) where feasible. This keeps the practical recommendation scoped to the evaluated conditions while addressing the concern. revision: partial
-
Referee: [Experimental Results] The statement that corpus-only rewriting degrades retrieval in 56 of 90 configurations (~62%) is presented as a general finding, but the manuscript provides no breakdown by benchmark, encoder, or rewriter family to show whether this is uniformly distributed or driven by particular subsets of the CoIR collection. This detail is needed to support the broader conclusion that corpus-only augmentation is rarely justified. (Experimental results tables or figures enumerating the 90 configurations)
Authors: We agree that an aggregate statistic alone is insufficient and that a per-configuration breakdown is needed to evaluate uniformity. The 56/90 figure summarizes outcomes across all 90 setups (six benchmarks, five encoders, three rewriters). In the revised manuscript, we will add supplementary tables or an extended results figure that enumerates degradation cases by benchmark, encoder, and rewriter family, allowing readers to identify any driving subsets and better substantiate the conclusion that corpus-only augmentation is rarely justified. revision: yes
Circularity Check
No circularity: empirical measurements and observed correlations only
full rationale
The paper reports direct experimental results from evaluating three rewriting strategies across six CoIR benchmarks, five encoders, and three rewriters. It measures retrieval metrics (NDCG@10), introduces Delta H (token entropy difference) and Delta s (embedding cosine) as post-hoc diagnostics, and computes Spearman correlations between Delta H and retrieval gains. These are observed statistical associations from the data, not derivations or predictions that reduce by the paper's own equations to quantities defined in terms of fitted parameters or self-referential inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption NDCG@10 is an appropriate metric for ranking quality in code retrieval
- domain assumption The six CoIR benchmarks are representative of practical code retrieval tasks
invented entities (2)
-
Delta H
no independent evidence
-
Delta s
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Haochen Li and Xin Zhou and Zhiqi Shen , editor =. Rewriting the Code:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.75 , timestamp =
-
[2]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[3]
Xiangyang Li and Kuicai Dong and Yi Quan Lee and Wei Xia and Hao Zhang and Xinyi Dai and Yasheng Wang and Ruiming Tang , editor =. CoIR:. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2025 , url =. doi:10.18653/V1/2025.ACL-LONG.1072 , timestamp =
-
[4]
Improving Repository-level Code Search with Text Conversion
Kondo, Mizuki and Kawahara, Daisuke and Kurabayashi, Toshiyuki. Improving Repository-level Code Search with Text Conversion. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop). 2024. doi:10.18653/v1/2024.naacl-srw.15
-
[5]
Yixuan Li and Xinyi Liu and Weidong Yang and Ben Fei and Shuhao Li and Mingjie Zhou and Lipeng Ma , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.20881 , eprinttype =. 2509.20881 , timestamp =
-
[6]
Laneve, C. and Span \`o , A. and Ressi, D. and Rossi, S. and Bugliesi, M. Assessing Code Understanding in LLMs. Formal Techniques for Distributed Objects, Components, and Systems. 2025
work page 2025
-
[7]
Feng, Zhangyin and Guo, Daya and Tang, Duyu and Duan, Nan and Feng, Xiaocheng and Gong, Ming and Shou, Linjun and Qin, Bing and Liu, Ting and Jiang, Daxin and Zhou, Ming. C ode BERT : A Pre-Trained Model for Programming and Natural Languages. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.139
-
[8]
GraphCodeBERT: Pre-training Code Representations with Data Flow , year = "2020", author=
work page 2020
-
[9]
Khan, Mohammad Abdullah Matin and Bari, M Saiful and Do, Xuan Long and Wang, Weishi and Parvez, Md Rizwan and Joty, Shafiq. XC ode E val: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[10]
CoSQA: 20, 000+ Web Queries for Code Search and Question Answering , booktitle =
Junjie Huang and Duyu Tang and Linjun Shou and Ming Gong and Ke Xu and Daxin Jiang and Ming Zhou and Nan Duan , editor =. CoSQA: 20, 000+ Web Queries for Code Search and Question Answering , booktitle =. 2021 , url =. doi:10.18653/V1/2021.ACL-LONG.442 , timestamp =
-
[11]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain and Ho. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search , journal =. 2019 , url =. 1909.09436 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[12]
Ye Liu and Rui Meng and Shafiq Joty and Silvio Savarese and Caiming Xiong and Yingbo Zhou and Semih Yavuz , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.12644 , eprinttype =. 2411.12644 , timestamp =
-
[13]
MoSE: Hierarchical Self-Distillation Enhances Early Layer Embeddings , booktitle =
Andrea Gurioli and Federico Pennino and Jo. MoSE: Hierarchical Self-Distillation Enhances Early Layer Embeddings , booktitle =. 2026 , url =. doi:10.1609/AAAI.V40I37.40348 , timestamp =
-
[14]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2212.03533 , eprinttype =. 2212.03533 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.03533 2022
-
[15]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang and Mingxin Li and Dingkun Long and Xin Zhang and Huan Lin and Baosong Yang and Pengjun Xie and An Yang and Dayiheng Liu and Junyang Lin and Fei Huang and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.05176 , eprinttype =. 2506.05176 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[16]
Yue Wang and Hung Le and Akhilesh Gotmare and Nghi D. Q. Bui and Junnan Li and Steven C. H. Hoi , editor =. CodeT5+: Open Code Large Language Models for Code Understanding and Generation , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.68 , timestamp =
-
[17]
Unixcoder: Unified cross-modal pre-training for code representation,
Guo, Daya and Lu, Shuai and Duan, Nan and Wang, Yanlin and Zhou, Ming and Yin, Jian. U ni X coder: Unified Cross-Modal Pre-training for Code Representation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.499
-
[18]
Generation-Augmented Retrieval for Open-Domain Question Answering
Mao, Yuning and He, Pengcheng and Liu, Xiaodong and Shen, Yelong and Gao, Jianfeng and Han, Jiawei and Chen, Weizhu. Generation-Augmented Retrieval for Open-Domain Question Answering. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.