Recognition: no theorem link
MemQ: Integrating Q-Learning into Self-Evolving Memory Agents over Provenance DAGs
Pith reviewed 2026-05-13 06:58 UTC · model grok-4.3
The pith
By propagating Q-learning credit along provenance DAGs, MemQ enables LLM agents to learn from memory dependency chains rather than isolated experiences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
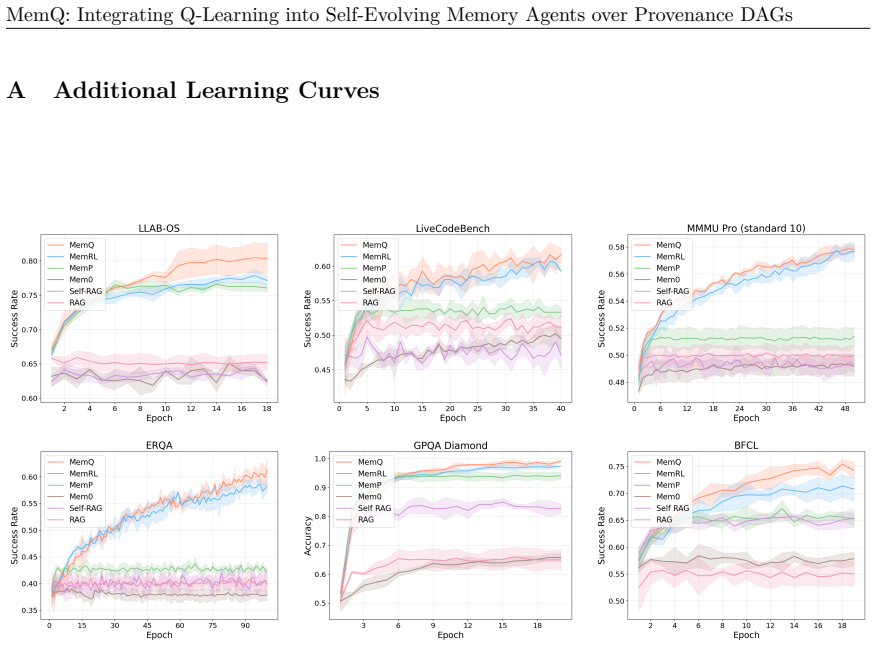
The central claim is that applying TD(λ) eligibility traces to memory Q-values over a provenance DAG improves agent success rates. The DAG captures which memories were used to create new ones, allowing structural proximity to guide credit assignment with decay (γλ)^d. This replaces independent memory updates and leads to superior performance in generalization and online learning on tasks from OS interaction to expert QA.
What carries the argument
The provenance DAG recording dependency chains between memories, combined with TD(λ) eligibility traces applied to memory Q-values for credit propagation based on structural depth.
Load-bearing premise
The provenance DAG accurately captures the dependency chains through which memories enable the creation of future memories, making structural proximity a valid substitute for temporal credit assignment.
What would settle it
An ablation study that randomizes the edges in the provenance DAG while keeping the same memories and retrievals would eliminate the performance gains if the DAG structure is key to the improvement.
Figures









read the original abstract
Episodic memory allows LLM agents to accumulate and retrieve experience, but current methods treat each memory independently, i.e., evaluating retrieval quality in isolation without accounting for the dependency chains through which memories enable the creation of future memories. We introduce MemQ, which applies TD($\lambda$) eligibility traces to memory Q-values, propagating credit backward through a provenance DAG that records which memories were retrieved when each new memory was created. Credit weight decays as $(\gamma\lambda)^d$ with DAG depth $d$, replacing temporal distance with structural proximity. We formalize the setting as an Exogenous-Context MDP, whose factored transition decouples the exogenous task stream from the endogenous memory store. Across six benchmarks, spanning OS interaction, function calling, code generation, multimodal reasoning, embodied reasoning, and expert-level QA, MemQ achieves the highest success rate on all six in generalization evaluation and runtime learning, with gains largest on multi-step tasks that produce deep and relevant provenance chains (up to +5.7~pp) and smallest on single-step classification (+0.77~pp) where single-step updates already suffice. We further study how $\gamma$ and $\lambda$ interact with the EC-MDP structure, providing principled guidance for parameter selection and future research. Code is available at https://github.com/jwliao-ai/MemQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemQ, a method that augments episodic memory in LLM agents by applying TD(λ) eligibility traces to memory Q-values, with credit propagated backward along a provenance DAG that records retrieval dependencies at memory creation time. Credit decays as (γλ)^d where d is DAG depth, replacing temporal distance. The setting is formalized as an Exogenous-Context MDP (EC-MDP) whose factored transitions separate the exogenous task stream from the endogenous memory store. On six benchmarks (OS interaction, function calling, code generation, multimodal reasoning, embodied reasoning, expert QA), MemQ reports the highest success rates in both generalization and runtime learning evaluations, with the largest gains (+5.7 pp) on multi-step tasks producing deep relevant chains and the smallest (+0.77 pp) on single-step tasks.
Significance. If the reported ordering and differential gains hold under controlled conditions, the work supplies a concrete mechanism for credit assignment across memory dependency chains rather than treating memories independently. The alignment between gain magnitude and provenance depth provides direct empirical support for the structural-propagation hypothesis. Public code release is a clear strength that enables verification and extension.
major comments (1)
- [§4] §4 (Experiments): the central claim attributes performance gains to TD(λ) over the provenance DAG, yet the manuscript does not report whether the DAG construction procedure (including retrieval logging) is applied identically to all baselines or only to MemQ; if the latter, the comparison confounds the credit-propagation mechanism with differences in memory-graph construction.
minor comments (3)
- [Abstract, §3.1] Abstract and §3.1: the EC-MDP factorization is presented as decoupling exogenous and endogenous components, but the text does not explicitly state whether memory retrieval can alter the exogenous task stream within a single step; a one-sentence clarification would remove ambiguity.
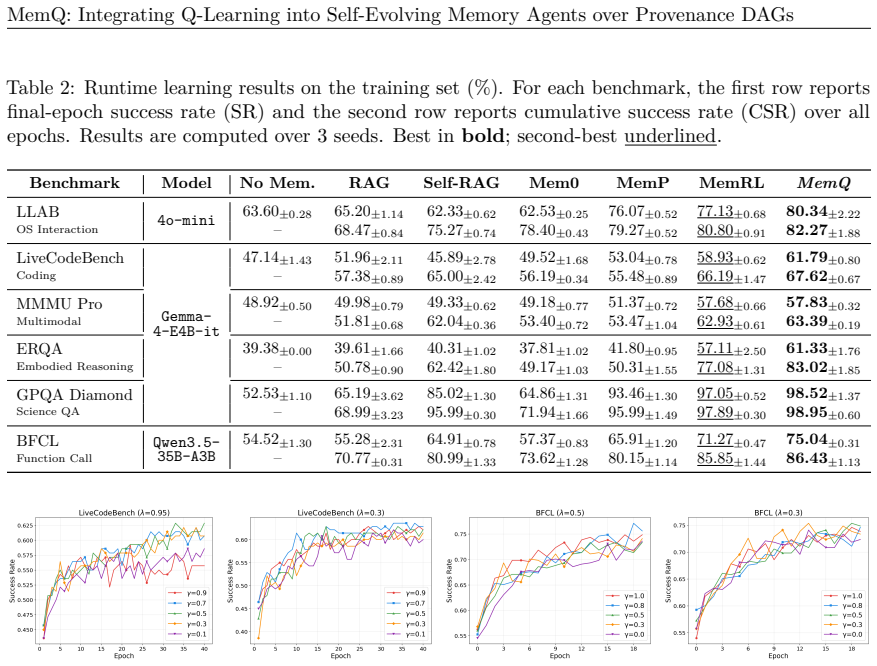
- [§5] §5 (Parameter study): the interaction plots for γ and λ are useful, but the manuscript should add a short table reporting the exact (γ, λ) pairs used for the main results on each benchmark to aid reproducibility.
- [§4.2, figures] Figure captions and §4.2: several success-rate tables list absolute percentages without standard deviations or number of runs; adding these would strengthen the reported ordering.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, recognition of the credit-assignment contribution, and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central claim attributes performance gains to TD(λ) over the provenance DAG, yet the manuscript does not report whether the DAG construction procedure (including retrieval logging) is applied identically to all baselines or only to MemQ; if the latter, the comparison confounds the credit-propagation mechanism with differences in memory-graph construction.
Authors: The provenance DAG construction (including retrieval logging at memory creation) is an integral and MemQ-specific component; it is not applied to any baseline. All methods share an identical episodic memory buffer, embedding-based retrieval interface, and memory-creation pipeline. The only difference is that MemQ additionally records provenance edges and applies TD(λ) updates along them, while baselines follow their original independent-memory update rules (standard TD(0) or no eligibility traces). This isolates the structural credit-propagation mechanism. We will revise §4 and the experimental appendix to explicitly document the shared memory interface, confirm that retrieval logging occurs uniformly, and state that the DAG is MemQ-only. If desired, we can also add a controlled ablation in which baselines receive a dummy DAG without credit propagation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces MemQ by formalizing an Exogenous-Context MDP and applying standard TD(λ) eligibility traces over a provenance DAG as modeling choices, then reports empirical success rates on six benchmarks. No equation or claim reduces by construction to a fitted parameter renamed as prediction, no self-citation chain is invoked to justify uniqueness or load-bearing assumptions, and the differential gains are presented as direct experimental outcomes rather than tautological redefinitions. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- gamma
- lambda
axioms (1)
- domain assumption The setting can be formalized as an Exogenous-Context MDP whose factored transition decouples the exogenous task stream from the endogenous memory store.
invented entities (2)
-
Provenance DAG
no independent evidence
-
Exogenous-Context MDP (EC-MDP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Large Language Models Are Semi-Parametric Reinforcement Learning Agents , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[2]
Memento 2: Learning by Stateful Reflective Memory , author=. 2026 , eprint=
work page 2026
-
[3]
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory , author=. 2026 , eprint=
work page 2026
-
[4]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
- [5]
-
[6]
Transactions on Machine Learning Research , issn=
Cognitive Architectures for Language Agents , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[7]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reflexion: language agents with verbal reinforcement learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[8]
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , articleno =....
-
[9]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[10]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2024 , isbn =. doi:10....
-
[11]
Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory , author=. 2023 , eprint=
work page 2023
-
[12]
RecallM: An Adaptable Memory Mechanism with Temporal Understanding for Large Language Models , author=. 2023 , eprint=
work page 2023
- [13]
-
[14]
Proceedings of the 27th International Joint Conference on Artificial Intelligence , pages =
Lin, Zichuan and Zhao, Tianqi and Yang, Guangwen and Zhang, Lintao , title =. Proceedings of the 27th International Joint Conference on Artificial Intelligence , pages =. 2018 , isbn =
work page 2018
-
[15]
Kearns, Michael J. and Singh, Satinder P. , title =. Proceedings of the Thirteenth Annual Conference on Computational Learning Theory , pages =. 2000 , isbn =
work page 2000
-
[16]
A Lyapunov Theory for Finite-Sample Guarantees of Asynchronous Q-Learning and TD-Learning Variants , author=. 2023 , eprint=
work page 2023
-
[17]
Jaakkola, Tommi and Jordan, Michael I. and Singh, Satinder P. , title =. Neural Comput. , month = nov, pages =. 1994 , issue_date =. doi:10.1162/neco.1994.6.6.1185 , abstract =
-
[18]
Asynchronous Stochastic Approximation and
Tsitsiklis, John N , journal=. Asynchronous Stochastic Approximation and
-
[19]
Borkar, V. S. and Meyn, S. P. , title =. SIAM J. Control Optim. , month = jan, pages =. 2000 , issue_date =. doi:10.1137/S0363012997331639 , abstract =
-
[20]
Neuro-Dynamic Programming , author=
-
[21]
Tsitsiklis, J.N. and Van Roy, B. , journal=. An analysis of temporal-difference learning with function approximation , year=
-
[22]
The Annals of Mathematical Statistics , volume=
A Stochastic Approximation Method , author=. The Annals of Mathematical Statistics , volume=
-
[23]
Learning to Predict by the Methods of Temporal Differences , author=. Machine Learning , volume=
-
[24]
Singh, Satinder P. and Sutton, Richard S. , title =. 1996 , issue_date =. doi:10.1007/BF00114726 , journal =
-
[25]
Reinforcement Learning: An Introduction , author=
-
[26]
Proceedings of the 31st International Conference on Machine Learning , pages =
True Online TD(lambda) , author =. Proceedings of the 31st International Conference on Machine Learning , pages =. 2014 , editor =
work page 2014
-
[27]
Learning from Delayed Rewards , author=
-
[28]
Peng, Jing and Williams, Ronald J , journal=. Incremental Multi-Step
-
[29]
Advances in Neural Information Processing Systems , volume=
Safe and Efficient Off-Policy Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Advances in Neural Information Processing Systems , volume=
Reconciling -Returns with Experience Replay , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Learning Representations , year=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. International Conference on Learning Representations , year=
-
[32]
International Conference on Machine Learning , year=
Espeholt, Lasse and Soyer, Hubert and Munos, R. International Conference on Machine Learning , year=
- [33]
-
[34]
Proceedings of the 34th International Conference on Machine Learning , pages =
Neural Episodic Control , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[35]
International Conference on Learning Representations , year=
Prioritized Experience Replay , author=. International Conference on Learning Representations , year=
-
[36]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Guu, Kelvin and Lee, Kenton and Tung, Zora and Pasupat, Panupong and Chang, Ming-Wei , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
- [37]
-
[38]
arXiv preprint arXiv:2505.00000 , year=
Yan, Sikuan and Yang, Xiufeng and Huang, Zuchao and Nie, Ercong and Ding, Zifeng and Li, Zonggen and Ma, Xiaowen and Bi, Jinhe and Kersting, Kristian and Pan, Jeff Z and Sch. arXiv preprint arXiv:2505.00000 , year=
-
[39]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks , author=. 2026 , eprint=
work page 2026
-
[40]
Fine-Mem: Fine-Grained Feedback Alignment for Long-Horizon Memory Management , author=. 2026 , eprint=
work page 2026
-
[41]
MemBuilder: Reinforcing LLMs for Long-Term Memory Construction via Attributed Dense Rewards , author=. 2026 , eprint=
work page 2026
-
[42]
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback , author=. 2026 , eprint=
work page 2026
-
[43]
RAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization , author=. 2026 , eprint=
work page 2026
-
[44]
ProRAG: Process-Supervised Reinforcement Learning for Retrieval-Augmented Generation , author=. 2026 , eprint=
work page 2026
-
[45]
The Thirteenth International Conference on Learning Representations , year=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
Patil, Shishir G and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The Berkeley Function Calling Leaderboard (. 2025 , editor =
work page 2025
-
[47]
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
work page 2024
- [48]
-
[49]
Gemini Robotics: Bringing AI into the Physical World , author=. 2025 , eprint=
work page 2025
-
[50]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , booktitle=. Self-. 2024 , url=
work page 2024
- [51]
-
[52]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. 2025 , eprint=
work page 2025
-
[53]
Memento: Fine-tuning LLM Agents without Fine-tuning LLMs , author=. 2025 , eprint=
work page 2025
-
[54]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents , author=. 2026 , eprint=
work page 2026
-
[55]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. 2026 , eprint=
work page 2026
-
[56]
Live-Evo: Online Evolution of Agentic Memory from Continuous Feedback , author=. 2026 , eprint=
work page 2026
-
[57]
HeLa-Mem: Hebbian Learning and Associative Memory for LLM Agents , author=. 2026 , eprint=
work page 2026
-
[58]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution , author=. 2026 , eprint=
work page 2026
-
[59]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author=. 2025 , eprint=
work page 2025
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Memo: Training Memory-Efficient Embodied Agents with Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
Mem-T: Densifying Rewards for Long-Horizon Memory Agents , author=. 2026 , eprint=
work page 2026
-
[62]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory , author=. 2025 , eprint=
work page 2025
-
[63]
The Fourteenth International Conference on Learning Representations , year=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. The Fourteenth International Conference on Learning Representations , year=
-
[64]
MemEvolve: Meta-Evolution of Agent Memory Systems , author=. 2025 , eprint=
work page 2025
-
[65]
Qianhao Yuan and Jie Lou and Zichao Li and Jiawei Chen and Yaojie Lu and Hongyu Lin and Le Sun and Debing Zhang and Xianpei Han , year=. MemSearcher: Training
-
[66]
and Niranjan, Mahesan , year =
Rummery, G. and Niranjan, Mahesan , year =. On-Line Q-Learning Using Connectionist Systems , journal =
-
[67]
LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners , author=. 2025 , eprint=
work page 2025
-
[68]
Shishir G Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng-Jie Ji and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , booktitle=. The Berkeley Function Calling Leaderboard (. 2025 , url=
work page 2025
-
[69]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[70]
MMMU -Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Yue, Xiang and Zheng, Tianyu and Ni, Yuansheng and Wang, Yubo and Zhang, Kai and Tong, Shengbang and Sun, Yuxuan and Yu, Botao and Zhang, Ge and Sun, Huan and Su, Yu and Chen, Wenhu and Neubig, Graham. MMMU -Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.