Recognition: 1 theorem link
· Lean TheoremDecoupling Endpoint and Semantic Transition Learning for Zero-Shot Composed Image Retrieval
Pith reviewed 2026-05-12 01:38 UTC · model grok-4.3
The pith
Decoupling endpoint alignment from semantic transition learning resolves the bottleneck in projection-based zero-shot composed image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
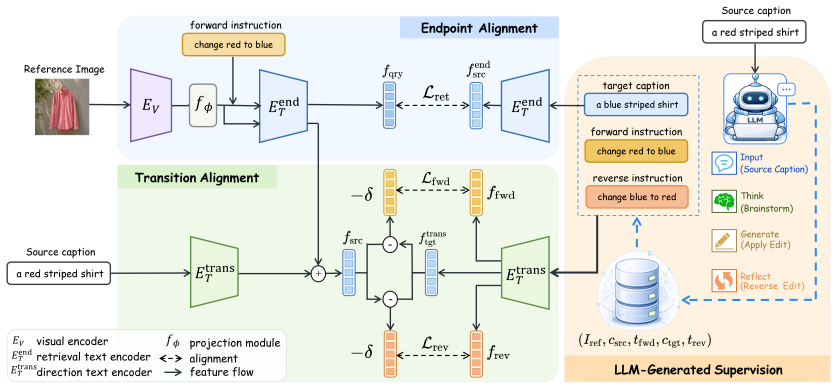
Endpoint-level matching in projection-based ZS-CIR lets edit text serve as a target attribute cue rather than grounding a source-conditioned semantic transition. Adding transition supervision to the shared text adapter produces an endpoint-transition conflict. DeCIR constructs paired forward and reverse edit tuples from image-caption pairs, trains separate low-rank text adapter branches for endpoint alignment and semantic transition alignment, and merges them with Low-Rank Directional Merge into a single deployable adapter.
What carries the argument
Paired forward and reverse edit tuples from image-caption pairs used to train separate low-rank text adapter branches for endpoint alignment and semantic transition alignment, then merged via Low-Rank Directional Merge into one model.
If this is right
- Projection-based ZS-CIR can handle complex semantic modifications more effectively while remaining free of LLMs at inference.
- The single merged adapter preserves the original lightweight inference cost of projection methods.
- Gains appear consistently on CIRR, CIRCO, FashionIQ, and GeneCIS without extra annotation requirements.
- Semantic transition supervision becomes usable without harming endpoint alignment.
Where Pith is reading between the lines
- The same forward-reverse pairing and branch decoupling may apply to other tasks where text must describe a change conditioned on a source image rather than an absolute target.
- Reducing dependence on human-annotated triplets could extend to additional composed retrieval or image-editing settings.
- Analogous endpoint-transition conflicts may exist in other adapter-based multimodal adaptation methods.
Load-bearing premise
Forward and reverse edit tuples derived from ordinary image-caption pairs supply unbiased supervision for genuine semantic transitions without domain shift or spurious correlations.
What would settle it
If the merged adapter shows no gain on complex semantic edits relative to a jointly trained baseline, or if the two branches interfere after Low-Rank Directional Merge, the claimed resolution of the endpoint-transition conflict would not hold.
Figures







read the original abstract
Zero-shot composed image retrieval (ZS-CIR) retrieves a target image from a reference image and a text modification without human-annotated CIR triplets. Projection-based ZS-CIR methods are attractive because they do not rely on LLMs at inference and remain lightweight, but they often underperform LLM-based approaches on complex semantic modifications. This gap reflects a semantic transition bottleneck in projection-based ZS-CIR: endpoint-level matching can let the edit text act as a target-side attribute cue rather than grounding it as a source-conditioned semantic transition. We further show that adding semantic transition supervision to the same text adapter creates an endpoint--transition conflict between endpoint alignment and semantic transition alignment. To address this conflict, DeCIR decouples endpoint and transition learning. It constructs paired forward/reverse edit tuples from image-caption pairs, trains separate low-rank text adapter branches for endpoint alignment and semantic transition alignment, and merges them with Low-Rank Directional Merge (LRDM) into one deployable adapter. Extensive experiments on CIRR, CIRCO, FashionIQ, and GeneCIS demonstrate that DeCIR consistently improves projection-based ZS-CIR without increasing inference complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that projection-based zero-shot composed image retrieval (ZS-CIR) suffers from an endpoint-transition conflict, where edit text acts as a target attribute cue rather than a source-conditioned modification. To resolve this, DeCIR constructs paired forward/reverse edit tuples from image-caption pairs, trains separate low-rank text adapter branches for endpoint alignment and semantic transition alignment, and merges them via Low-Rank Directional Merge (LRDM) into a single deployable adapter. It reports consistent improvements on CIRR, CIRCO, FashionIQ, and GeneCIS without increasing inference complexity.
Significance. If the decoupling is shown to address a genuine conflict rather than partitioning correlated signals, the work could meaningfully advance lightweight projection-based ZS-CIR by narrowing the gap with LLM-based methods while preserving efficiency. The forward/reverse tuple construction and LRDM merge represent a targeted architectural response to the identified bottleneck. The evaluation across four datasets provides a broad empirical base, and the absence of added inference cost is a practical strength.
major comments (2)
- [§3.2] §3.2 (tuple construction): The central claim that paired forward/reverse edit tuples supply independent, unbiased supervision for the transition branch rests on the assumption that reverse tuples from holistic image-caption pairs are true inverses. Because captions are not source-conditioned modifications, the reverse tuple can reinforce attribute matching or dataset-specific phrasing instead of genuine semantic transitions. This risks the separate branches simply partitioning correlated signals, so that LRDM gains may reflect extra capacity rather than conflict resolution.
- [§4] §4 (experiments): The abstract asserts consistent benchmark gains from decoupling, yet no quantitative results, ablations isolating the conflict (e.g., joint vs. decoupled training with matched capacity), error bars, or verification that constructed tuples avoid post-hoc selection bias are referenced. Without these, it is impossible to confirm that reported improvements on CIRR/CIRCO stem from resolving the endpoint-transition conflict rather than added parameters or data volume.
minor comments (2)
- [§3.3] The LRDM merge operation is introduced as a novel component but lacks an explicit equation or pseudocode in the method description, making it difficult to reproduce the directional merge precisely.
- [Figure 2] Notation for the two low-rank branches (endpoint vs. transition) should be distinguished more clearly in figures and equations to avoid conflating the separate training objectives.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying the design choices in tuple construction and committing to expanded experimental validation. These responses aim to strengthen the manuscript's claims regarding the endpoint-transition conflict and its resolution via decoupling.
read point-by-point responses
-
Referee: [§3.2] §3.2 (tuple construction): The central claim that paired forward/reverse edit tuples supply independent, unbiased supervision for the transition branch rests on the assumption that reverse tuples from holistic image-caption pairs are true inverses. Because captions are not source-conditioned modifications, the reverse tuple can reinforce attribute matching or dataset-specific phrasing instead of genuine semantic transitions. This risks the separate branches simply partitioning correlated signals, so that LRDM gains may reflect extra capacity rather than conflict resolution.
Authors: We acknowledge that image captions provide holistic descriptions rather than explicit source-conditioned edits, which introduces a degree of correlation between forward and reverse signals. However, the paired construction derives the reverse tuple by inverting the semantic direction on the same image-caption pair (e.g., using the caption to define the target state and deriving the opposing edit text), thereby supplying complementary supervision focused on the modification delta rather than static attributes. The endpoint branch is trained exclusively on direct image-text alignment objectives, while the transition branch optimizes for the paired edit direction; this separation, combined with LRDM's directional merging, is intended to prevent simple signal partitioning. We will revise §3.2 to include a concrete example of tuple construction and a brief discussion of the limitations of caption-derived inverses, while retaining the core method. revision: partial
-
Referee: [§4] §4 (experiments): The abstract asserts consistent benchmark gains from decoupling, yet no quantitative results, ablations isolating the conflict (e.g., joint vs. decoupled training with matched capacity), error bars, or verification that constructed tuples avoid post-hoc selection bias are referenced. Without these, it is impossible to confirm that reported improvements on CIRR/CIRCO stem from resolving the endpoint-transition conflict rather than added parameters or data volume.
Authors: Section 4 of the manuscript reports quantitative results across CIRR, CIRCO, FashionIQ, and GeneCIS with comparisons to prior projection-based and LLM-based methods. To directly isolate the contribution of decoupling, we will add new ablations in the revised §4: (1) joint training versus decoupled branches under matched parameter budgets, (2) standard error bars computed over three independent runs, and (3) explicit verification that all image-caption pairs are processed systematically without post-hoc filtering. These additions will confirm that gains arise from conflict resolution rather than capacity or data volume increases. revision: yes
Circularity Check
No circularity: architectural decoupling is independent of fitted inputs
full rationale
The paper's core contribution is an architectural change—constructing forward/reverse tuples from existing image-caption pairs, training separate low-rank adapter branches, and merging via LRDM—applied on top of standard projection-based ZS-CIR frameworks. No equations, derivations, or self-citations are presented that reduce the claimed performance gains to a quantity defined by the method itself or to a fitted parameter renamed as a prediction. The supervision signal is generated from external data sources rather than being tautological with the target metric, and the decoupling benefit is presented as an empirical architectural hypothesis rather than a mathematical necessity. This satisfies the criteria for a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Image-caption pairs can be transformed into forward/reverse edit tuples that provide clean supervision for both endpoint and semantic transition objectives.
invented entities (1)
-
Low-Rank Directional Merge (LRDM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InProceedings of the IEEE/CVF international conference on computer vision, pages 15338–15347, 2023
work page 2023
-
[2]
Effective conditioned and composed image retrieval combining clip-based features
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Effective conditioned and composed image retrieval combining clip-based features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21466–21474, 2022
work page 2022
-
[3]
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Composed image retrieval using contrastive learning and task-oriented clip-based features.ACM Transactions on Multimedia Computing, Communications and Applications, 20(3):1–24, 2023
work page 2023
-
[4]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[5]
Image search with text feedback by visiolinguistic attention learning
Yanbei Chen, Shaogang Gong, and Loris Bazzani. Image search with text feedback by visiolinguistic attention learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3001–3011, 2020
work page 2020
-
[6]
Model breadcrumbs: Scaling multi-task model merging with sparse masks
MohammadReza Davari and Eugene Belilovsky. Model breadcrumbs: Scaling multi-task model merging with sparse masks. InEuropean Conference on Computer Vision, pages 270–287. Springer, 2024
work page 2024
-
[7]
Chatglm: A family of large language models from glm-130b to glm-4 all tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page 2024
-
[8]
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, HeeJae Jun, Yoohoon Kang, and Sangdoo Yun. Compodiff: Versatile composed image retrieval with latent diffusion.Transactions on Machine Learning Research,
-
[9]
Expert Certification
-
[10]
Language-only training of zero-shot composed image retrieval
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoohoon Kang, and Sangdoo Yun. Language-only training of zero-shot composed image retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13225–13234, 2024
work page 2024
-
[11]
Jitai Hao, Hao Liu, Xinyan Xiao, Qiang Huang, and Jun Yu. Uni-x: Mitigating modality conflict with a two-end-separated architecture for unified multimodal models. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[12]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Ges- mundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[13]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[14]
Collm: A large language model for composed image retrieval
Chuong Huynh, Jinyu Yang, Ashish Tawari, Mubarak Shah, Son Tran, Raffay Hamid, Trishul Chilimbi, and Abhinav Shrivastava. Collm: A large language model for composed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3994–4004, 2025
work page 2025
-
[15]
Editing models with task arithmetic, 2023
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic, 2023
work page 2023
-
[16]
Spherical linear interpo- lation and text-anchoring for zero-shot composed image retrieval
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, and Ser-Nam Lim. Spherical linear interpo- lation and text-anchoring for zero-shot composed image retrieval. InEuropean conference on computer vision, pages 239–254. Springer, 2024
work page 2024
-
[17]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021. 10
work page 2021
-
[18]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser- Nam Lim. Visual prompt tuning. InEuropean conference on computer vision, pages 709–727. Springer, 2022
work page 2022
-
[19]
Vision-by-language for training-free compositional image retrieval
S Karthik, K Roth, M Mancini, Z Akata, et al. Vision-by-language for training-free compositional image retrieval. InThe Twelfth International Conference on Learning Representations. International Conference on Learning Representations, ICLR, 2024
work page 2024
-
[20]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023
work page 2023
-
[21]
Qure: Query-relevant retrieval through hard negative sampling in composed image retrieval
Jaehyun Kwak, Ramahdani Muhammad Izaaz Inhar, Se-Young Yun, and Sung-Ju Lee. Qure: Query-relevant retrieval through hard negative sampling in composed image retrieval. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[23]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
work page 2022
-
[24]
Wei Li, Hehe Fan, Yongkang Wong, Yi Yang, and Mohan Kankanhalli. Improving context understanding in multimodal large language models via multimodal composition learning. InInternational conference on machine learning, 2024
work page 2024
-
[25]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582– 4597, 2021
work page 2021
-
[26]
Imagine and seek: Improving composed image retrieval with an imagined proxy
You Li, Fan Ma, and Yi Yang. Imagine and seek: Improving composed image retrieval with an imagined proxy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3984–3993, 2025
work page 2025
-
[27]
Hierarchy-aware pseudo word learning with text adaptation for zero-shot composed image retrieval
Zhe Li, Lei Zhang, Zheren Fu, Kun Zhang, and Zhendong Mao. Hierarchy-aware pseudo word learning with text adaptation for zero-shot composed image retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24319–24329, 2025
work page 2025
-
[28]
Zhe Li, Lei Zhang, Kun Zhang, Weidong Chen, Yongdong Zhang, and Zhendong Mao. Rethinking pseudo word learning in zero-shot composed image retrieval: From an object-aware perspective. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 833–843, 2025
work page 2025
-
[29]
Image retrieval on real-life images with pre-trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2125–2134, 2021
work page 2021
-
[30]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[31]
Michael S Matena and Colin A Raffel. Merging models with fisher-weighted averaging.Advances in Neural Information Processing Systems, 35:17703–17716, 2022
work page 2022
-
[32]
Composed image retrieval for remote sensing
Bill Psomas, Ioannis Kakogeorgiou, Nikos Efthymiadis, Giorgos Tolias, Ondˇrej Chum, Yannis Avrithis, and Konstantinos Karantzalos. Composed image retrieval for remote sensing. InIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium, pages 8526–8534. IEEE, 2024
work page 2024
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[34]
Pic2word: Mapping pictures to words for zero-shot composed image retrieval
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Pic2word: Mapping pictures to words for zero-shot composed image retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19305–19314, 2023. 11
work page 2023
-
[35]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018
work page 2018
-
[36]
Shitong Sun, Qilei Li, Shaogang Gong, Weitong Cai, Philip Torr, and Jindong Gu. Benchcir: Benchmarking robustness in composed image retrieval across modalities.Pattern Recognition, page 113724, 2026
work page 2026
-
[37]
Cotmr: chain-of-thought multi-scale reasoning for training- free zero-shot composed image retrieval
Zelong Sun, Dong Jing, and Zhiwu Lu. Cotmr: chain-of-thought multi-scale reasoning for training- free zero-shot composed image retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22675–22684, 2025
work page 2025
-
[38]
Knowledge-enhanced dual-stream zero-shot composed image retrieval
Yucheng Suo, Fan Ma, Linchao Zhu, and Yi Yang. Knowledge-enhanced dual-stream zero-shot composed image retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26951–26962, 2024
work page 2024
-
[39]
Yuanmin Tang, Jing Yu, Keke Gai, Jiamin Zhuang, Gang Xiong, Gaopeng Gou, and Qi Wu. Missing target-relevant information prediction with world model for accurate zero-shot composed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24785–24795, 2025
work page 2025
-
[40]
Yuanmin Tang, Jing Yu, Keke Gai, Jiamin Zhuang, Gang Xiong, Yue Hu, and Qi Wu. Context-i2w: Map- ping images to context-dependent words for accurate zero-shot composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5180–5188, 2024
work page 2024
-
[41]
Yuanmin Tang, Jue Zhang, Xiaoting Qin, Jing Yu, Gaopeng Gou, Gang Xiong, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Wu. Reason-before-retrieve: One-stage reflective chain-of-thoughts for training-free zero-shot composed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14400–14410, 2025
work page 2025
-
[42]
Composing text and image for image retrieval-an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval-an empirical odyssey. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6439–6448, 2019
work page 2019
-
[43]
Tianyue Wang, Leigang Qu, Tianyu Yang, Xiangzhao Hao, Yifan Xu, Haiyun Guo, and Jinqiao Wang. Wiser: Wider search, deeper thinking, and adaptive fusion for training-free zero-shot composed image retrieval.arXiv preprint arXiv:2602.23029, 2026
-
[44]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: aver- aging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pages 23965–23998...
work page 2022
-
[45]
Fashion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11307–11317, 2021
work page 2021
-
[46]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
work page 2023
-
[47]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[48]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
work page 2020
-
[49]
Robustmerge: Parameter-efficient model merging for mllms with direction robustness
Fanhu Zeng, Haiyang Guo, Fei Zhu, Li Shen, and Hao Tang. Robustmerge: Parameter-efficient model merging for mllms with direction robustness. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[50]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[51]
Zero-shot composed image retrieval via dual-stream instruction-aware distillation
Wenliang Zhong, Rob Barton, Weizhi An, Feng Jiang, Hehuan Ma, Yuzhi Guo, Abhishek Dan, Shioulin Sam, Karim Bouyarmane, and Junzhou Huang. Zero-shot composed image retrieval via dual-stream instruction-aware distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22221–22231, 2025. 12 A Additional Benchmark Results Ta...
work page 2025
-
[52]
Input: A source image caption will be provided
-
[53]
Brainstorming: Identify the key source details in the source caption (objects, actions, setting) and propose one significant, plausible visual change. 3.instruction: Write the forward edit from source to target. 4.modified_caption: Apply the edit while preserving unrelated source details. 5.reverse_instruction: Write the reverse edit frommodified_captionb...
-
[54]
Make exactly one significant visual change, such as changing an object color, location, action, material, count, or category
-
[55]
Keep unrelated details unchanged inmodified_caption
-
[56]
Thereverse_instructionmust undo only the forward edit
-
[57]
The instruction and modified caption should be coherent and plausible. Input: {source_caption} Figure 5:Prompt template used for offline supervision construction.We prompt the LLM to produce the forward edit, edited caption, and reverse instruction in one structured output. 14 Table 7:Main DeCIR training hyperparameters.Common optimization settings follow...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.