Recognition: 2 theorem links
· Lean TheoremQueryable LoRA: Instruction-Regularized Routing Over Shared Low-Rank Update Atoms
Pith reviewed 2026-05-12 00:56 UTC · model grok-4.3
The pith
Queryable LoRA replaces static low-rank adapters with a shared memory of update atoms retrieved dynamically via attention over network-state queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By forming a query from the current low-rank state and a running summary of previous blocks, retrieving a content-dependent combination of shared update atoms via attention, and applying the routed operator inside the low-rank bottleneck, together with instruction-regularized routing logits, the architecture produces data-adaptive low-rank updates that improve final test performance and training stability over standard LoRA while using a comparable number of trainable parameters.
What carries the argument
Shared queryable memory of low-rank update atoms retrieved by attention over queries formed from the current low-rank state and running block summaries
If this is right
- The effective update can vary across inputs and across layer depths while remaining compact.
- Instruction regularization biases atom selection toward semantically relevant transformations without generating unconstrained parameters.
- Training stability improves on noisy non-linear regression and LLM fine-tuning tasks.
- The method occupies a middle ground between static LoRA-style updates and fully generated parameter updates.
- Parameter efficiency is preserved at levels comparable to standard low-rank adaptation.
Where Pith is reading between the lines
- The shared-atom design could be grafted onto other parameter-efficient fine-tuning families that currently use independent adapters per layer.
- Running summaries across blocks may naturally encourage reuse of transformations that recur at multiple depths.
- If the attention routing proves stable, similar query mechanisms might reduce the need for task-specific hyperparameter search in multi-task adaptation.
- The approach suggests testing whether the same shared memory can be frozen after initial training and reused across related downstream tasks.
Load-bearing premise
Forming a query from the low-rank state and running summary and retrieving atoms via attention produces a meaningfully more expressive update without introducing instability or substantially more compute.
What would settle it
On a standard LLM fine-tuning benchmark, if the method shows no gain in test accuracy or no reduction in training loss variance relative to vanilla LoRA at the same parameter budget, the claimed benefit of queryable routing collapses.
Figures








read the original abstract
We present a data-adaptive method for parameter-efficient fine-tuning of large neural networks. Standard low-rank adaptation methods improve efficiency by restricting each layer update to a fixed low-rank form, but this static parameterization can be too rigid when the appropriate correction depends on the input and on the evolving depth-wise computation of the network. Our approach replaces a purely layer-local adapter with a shared queryable memory of low-rank update atoms. For each block of layers, the model forms a query from the current low-rank state and a running summary of previous blocks, uses this query to retrieve a content-dependent combination of shared update components via attention, and applies the resulting routed operator within the low-rank bottleneck. In this way, the method retains the efficiency and scalability of low-rank adaptation while allowing the effective update to vary across inputs and to share reusable structure across layers. The resulting architecture provides a principled middle ground between static LoRA-style updates and fully generated parameter updates: it remains compact and parameter-efficient while supporting dynamic, context-sensitive adaptation. Further, we incorporate instruction-regularization by augmenting routing logits with a language-induced prior over update atoms, thereby biasing the selection of low-rank transformations toward semantically relevant directions without generating unconstrained parameter updates. Experiments on noisy non-linear regression tasks and LLM fine-tuning suggest that this queryable update-memory formulation can improve final test performance and training stability compared to standard low-rank adaptation, while using a comparable number of trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Queryable LoRA, a parameter-efficient fine-tuning method that augments standard LoRA by maintaining a shared memory of low-rank update atoms. For each layer block, it constructs a query from the current low-rank factors plus a running summary of prior blocks, retrieves a content-dependent linear combination of the atoms via attention, applies the routed update inside the low-rank bottleneck, and augments the routing logits with an instruction-regularization term derived from language priors. Experiments on noisy non-linear regression and LLM fine-tuning tasks are reported to show gains in test performance and training stability relative to vanilla LoRA while using a comparable number of trainable parameters.
Significance. If the empirical claims are robust, the work supplies a concrete architectural middle ground between static low-rank adapters and fully input-dependent parameter generation. The shared-atom design plus instruction regularization could improve adaptability across layers and inputs without sacrificing the core efficiency of LoRA, which would be of practical interest for fine-tuning large models.
major comments (3)
- [§3] §3 (Method): The query is formed directly from the evolving low-rank matrices A and B together with the running summary; because these matrices are themselves being optimized, the routing logits are coupled to the parameters under adaptation. No ablation that detaches or freezes the query source is described, so it remains unclear whether observed stability improvements arise from the shared-atom routing or from the instruction-regularization term alone.
- [§4] §4 (Experiments): The abstract states that the method improves final test performance and training stability on regression and LLM tasks, yet the provided description supplies no quantitative tables, error bars, baseline hyper-parameter details, or ablation studies that isolate the contribution of the attention-based retrieval versus the regularization prior. Without these controls, the central claim that the queryable formulation is responsible for the gains cannot be verified.
- [§3.2] §3.2 (Routing and compute): The additional parameters and FLOPs introduced by the query network and attention over the shared atoms are asserted to be negligible, but no explicit accounting (e.g., parameter count breakdown or relative FLOP increase per forward pass) is given to substantiate that the total trainable budget remains comparable to standard LoRA.
minor comments (2)
- Notation for the running summary and the instruction-induced prior should be defined once in a single table or equation block rather than re-introduced in prose.
- The paper should include a small diagram or pseudocode block illustrating the query formation, attention retrieval, and application inside one layer block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested clarifications, ablations, and quantitative details.
read point-by-point responses
-
Referee: [§3] §3 (Method): The query is formed directly from the evolving low-rank matrices A and B together with the running summary; because these matrices are themselves being optimized, the routing logits are coupled to the parameters under adaptation. No ablation that detaches or freezes the query source is described, so it remains unclear whether observed stability improvements arise from the shared-atom routing or from the instruction-regularization term alone.
Authors: The coupling is intentional: forming the query from the current A and B allows routing to adapt as parameters evolve during training. We agree that this makes it difficult to isolate effects without further controls. We will add an ablation that detaches or freezes the query source (e.g., using fixed or random queries) while keeping the shared atoms and regularization, to clarify the source of any stability gains. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states that the method improves final test performance and training stability on regression and LLM tasks, yet the provided description supplies no quantitative tables, error bars, baseline hyper-parameter details, or ablation studies that isolate the contribution of the attention-based retrieval versus the regularization prior. Without these controls, the central claim that the queryable formulation is responsible for the gains cannot be verified.
Authors: We will expand the experimental section with full quantitative tables (including means and standard deviations across runs), error bars, complete hyperparameter details for all baselines, and dedicated ablations that separately disable the attention-based retrieval and the instruction-regularization term. These additions will allow direct verification of each component's contribution. revision: yes
-
Referee: [§3.2] §3.2 (Routing and compute): The additional parameters and FLOPs introduced by the query network and attention over the shared atoms are asserted to be negligible, but no explicit accounting (e.g., parameter count breakdown or relative FLOP increase per forward pass) is given to substantiate that the total trainable budget remains comparable to standard LoRA.
Authors: We will insert a dedicated subsection with an explicit parameter-count breakdown (query network, attention weights, and shared atoms) and a per-forward-pass FLOP comparison against vanilla LoRA. This will quantify the overhead and confirm the trainable budget remains comparable. revision: yes
Circularity Check
Architectural proposal without self-referential derivations or fitted predictions
full rationale
The paper introduces Queryable LoRA as a data-adaptive PEFT architecture using shared low-rank atoms, query formation from low-rank state plus summary, attention-based retrieval, and instruction regularization. No equations, derivations, or theoretical predictions appear in the provided text. The central claims rest on empirical experiments comparing test performance and stability to standard LoRA at similar parameter counts. No load-bearing steps reduce by construction to inputs, self-citations, or fitted quantities renamed as predictions. This is a standard architectural contribution whose validity is assessed externally via experiments rather than internal reduction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
shared low-rank update atoms
no independent evidence
-
instruction-regularized routing logits
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness and convexity) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Sb(c) = ∑ α_m C_m (convex combination inside LoRA bottleneck); α = argmax <a,ζ> - KL(a || π^τ); ||ΔW|| ≤ (α_L/r) R_B (1+R_C) R_A
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection (coupling combiner forces bilinear branch) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
global shared memory bank of atoms; reusable across layers/blocks/depth summaries
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. InProceedings of NAACL-HLT 2019,
work page 2019
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Nghiem T Diep, Hien Dang, Tuan Truong, Tan Dinh, Huy Nguyen, and Nhat Ho. Doran: Stabilizing weight-decomposed low-rank adaptation via noise injection and auxiliary networks.arXiv preprint arXiv:2510.04331,
-
[7]
URL https://arxiv.org/abs/2510.04295. Bolin Gao and Lacra Pavel. On the properties of the softmax function with application in game theory and reinforcement learning.arXiv preprint arXiv:1704.00805,
-
[8]
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy
URL http://dblp.uni-trier.de/db/conf/iclr/iclr2022.html#HuSWALWWC22. Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, Copenhagen, Denmark, September
work page 2017
-
[9]
RACE : Large-scale R e A ding comprehension dataset from examinations
Association for Computational Linguistics. doi: 10.18653/v1/D17-1082. URL https: //aclanthology.org/D17-1082. Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. [https://h...
-
[10]
Decoupled Weight Decay Regularization
10 Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Tongxu Luo, Jiahe Lei, Fangyu Lei, Weihao Liu, Shizhu He, Jun Zhao, and Kang Liu. Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models.arXiv preprint arXiv:2402.12851,
-
[12]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
S. Surjanovic and D. Bingham. Virtual library of simulation experiments: Test functions and datasets. Retrieved April 8, 2026, fromhttp://www.sfu.ca/~ssurjano,
work page 2026
-
[14]
arXiv preprint arXiv:2603.15031 (2026)
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. Attention residuals.arXiv preprint arXiv:2603.15031,
-
[15]
Tuan Truong, Chau Nguyen, Huy Nguyen, Minh Le, Trung Le, and Nhat Ho. Replora: Reparameteriz- ing low-rank adaptation via the perspective of mixture of experts.arXiv preprint arXiv:2502.03044,
-
[16]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321,
work page internal anchor Pith review arXiv
-
[17]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems.arXiv preprint 1905.00537,
work page internal anchor Pith review arXiv 1905
-
[18]
Low-rank interconnected adaptation across layers
Yibo Zhong, Jinman Zhao, and Yao Zhou. Low-rank interconnected adaptation across layers. In Findings of the Association for Computational Linguistics: ACL 2025, pages 17005–17029,
work page 2025
-
[19]
Let the frozen attention projections be {W 0,Q ℓ ,W 0,K ℓ ,W 0,V ℓ ,W 0,O ℓ }
11 A Additional Methodological Details A.1 Attention Updates Consider an attention block ℓ with token matrix H ℓ ∈R T×d ℓ. Let the frozen attention projections be {W 0,Q ℓ ,W 0,K ℓ ,W 0,V ℓ ,W 0,O ℓ }. For each projection type p∈ {Q, K, V, O} , the LoRA factors are [Hu et al., 2022]: Ap ℓ ∈R r×din,p ℓ and Bp ℓ ∈R dout,p ℓ ×r. For the query, key, and value...
work page 2022
-
[20]
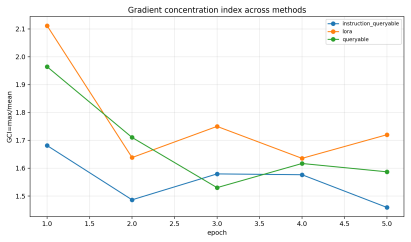
Lower values indicate that optimization is less dominated by a small number of layers
B Additional Experimental Results Figure 4 summarizes Figure 3 results through the gradient concentration index, defined as the ratio between the maximum and mean per-layer adapter gradient norm. Lower values indicate that optimization is less dominated by a small number of layers. Across epochs, the instruction-queryable model has the lowest or near-lowe...
-
[21]
All configurations use the same frozen Qwen2.5-0.5B-Instruct backbone, task instruction, training procedure, and evaluation protocol; only the instruction-queryable hyperparameters are varied. For each setting, we select the final checkpoint based on the highest observed training accuracy and report its corresponding held-out evaluation accuracy. The dash...
-
[22]
as it remains a retrieval-and-composition mechanism over a bounded memory bank as compared to a direct text-to-weight generator in Charakorn et al. [2025]. The depth-summary bounds in D.8, D.8.1, D.9, D.9.1 prove that the attention-based summary of previous blocks stays bounded and stable. This stability ensures that information from earlier layers does n...
work page 2025
-
[23]
Hence, Sb(c) is a convex combi- nation of atoms {Cm}M m=1, which demonstrates Sb(c)∈conv{C 1, C2, C3, . . . , CM }. Additionally, ∥Sb(c)∥= MX m=1 αb,m(c)Cm ≤ MX m=1 αb,m(c)∥Cm∥ ≤max 1≤m≤M ∥Cm∥ MX m=1 αb,m(c) = max 1≤m≤M ∥Cm∥(57) Using assumption D.1,∥S b(c)∥ ≤R C. Corollary D.8.1(Layerwise norm-to-norm bound).For any adapted layerℓ∈ B b, ∥∆Wℓ(hℓ;b, c)∥ ≤ ...
work page 2019
-
[24]
and in analyses of the log-sum-exp Hessian by Gao and Pavel [2017]. Lemma D.10(Exact Jacobian of RMS normalization).Let r(x) =RMS ε(x) = q 1 d ∥x∥2 2 +ε , and, f(x) = x r(x) . Then Jf(x) = 1 r(x) Id − 1 d r(x)3 xx⊤ (65) Ifr(x)≥ρ min >0, then ∥Jf(x)∥2→2 ≤ 1 ρmin (66) Proof. We refer to Stollenwerk
work page 2017
-
[25]
for this proof. Write f(x) =r(x) −1x. By the product rule for Jacobians, Jf(x) =r(x) −1Id +x∇(r(x) −1)⊤ (67) We compute∇r(x). Since,r(x) = 1 d x⊤x+ε 1/2 , we have, ∇r(x) = 1 2 1 d x⊤x+ε −1/2 2 d x= x d r(x) From chain rule, ∇(r(x)−1) =−r(x) −2∇r(x) =− x d r(x)3 (68) 25 From 68 and 67, we get (65). For the operator norm bound, note that xx⊤ is symmetric ra...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.