Recognition: no theorem link
Active Multiple-Prediction-Powered Inference
Pith reviewed 2026-05-12 01:06 UTC · model grok-4.3
The pith
Active Multiple-Prediction-Powered Inference adapts predictor choice and label sampling per instance to produce narrower confidence intervals than single-predictor methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
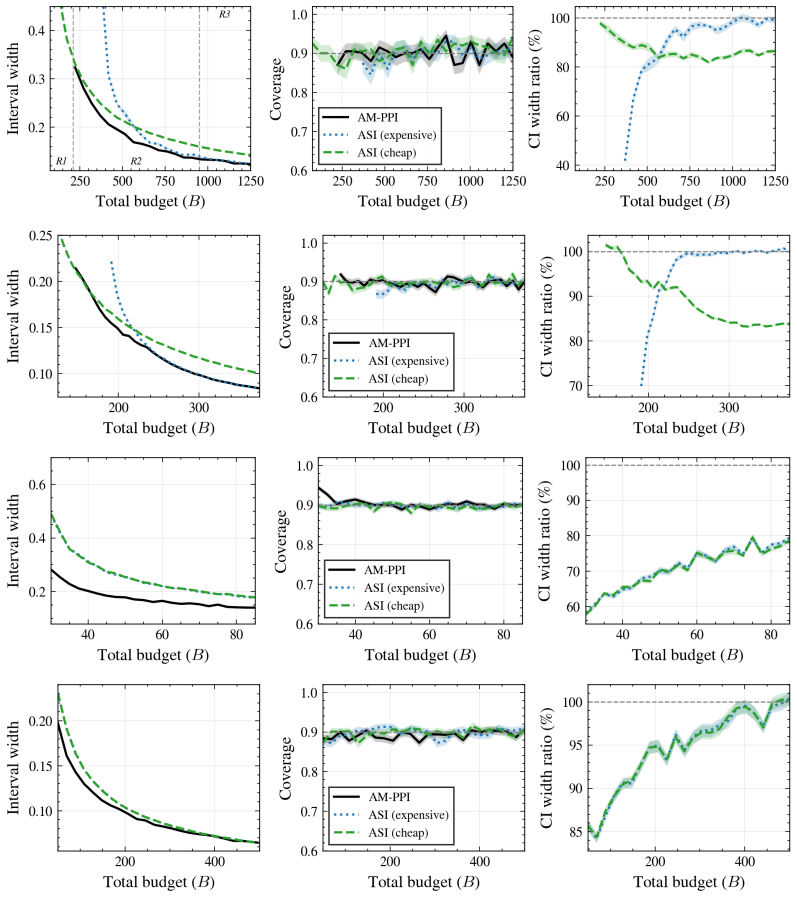
We propose Active Multiple-Prediction-Powered Inference (AM-PPI) that routes each instance to a cost-appropriate predictor subset, samples gold-standard labels in proportion to the chosen subset's residual uncertainty, and reweights predictions to minimize estimator variance, all under a single deployment-time budget. Closed-form KKT conditions for the three decisions are derived and the fixed point is proven to be globally optimal via biconvexity and strong duality despite non-joint convexity. The estimator is asymptotically normal with valid coverage, minimum-variance unbiased within the linear AIPW class, and a criterion shows when multiple predictors help. Experiments show 10-40% narrow
What carries the argument
Per-instance adaptive routing to predictor subsets combined with uncertainty-proportional label sampling and variance-minimizing reweighting, solved via closed-form KKT conditions from a biconvex optimization problem.
If this is right
- Produces asymptotically normal estimators with valid coverage guarantees.
- Achieves minimum-variance unbiasedness within the augmented inverse propensity weighted class.
- Identifies via closed-form criterion when using multiple predictors improves performance.
- Delivers 10 to 40 percent narrower confidence intervals than single-predictor methods in relevant budget settings.
Where Pith is reading between the lines
- The same adaptive routing logic could apply to other resource-constrained inference settings such as active learning or federated estimation.
- If predictor accuracies are correlated across instances, the uncertainty sampling rule might need adjustment to capture dependence.
- Deployment teams could use the optimality criterion to decide in advance whether investing in additional predictors is worthwhile.
Load-bearing premise
Multiple predictors of differing cost and accuracy must be available simultaneously for every instance at inference time, and the minimum-variance unbiased estimator must belong to the linear-prediction augmented inverse propensity weighted class.
What would settle it
A controlled experiment where all predictors are forced to the same cost and accuracy, or where only one predictor is available per instance, should make the adaptive routing collapse to a single-predictor baseline; failure to recover the baseline performance would indicate the method does not generalize as claimed.
Figures


read the original abstract
Post-deployment monitoring of healthcare AI requires statistically valid, label-efficient methods, but gold-standard labels from clinician chart review are expensive. Prediction-powered inference (PPI) and active statistical inference (ASI) reduce label cost by combining a small labeled sample with abundant model predictions, but both are restricted to a single predictor, a poor fit for modern clinical pipelines that have multiple predictors of differing cost and accuracy available at inference time. We propose Active Multiple-Prediction-Powered Inference (AM-PPI), which routes each instance to a cost-appropriate predictor subset, samples gold-standard labels in proportion to the chosen subset's residual uncertainty, and reweights predictions to minimize estimator variance, all under a single deployment-time budget. AM-PPI generalizes ASI to leverage multiple predictors and extends Multiple-PPI from global per-predictor allocation to per-instance adaptive routing. We derive closed-form Karush-Kuhn-Tucker (KKT) conditions for all three decisions and prove, via biconvexity and strong duality, that the resulting fixed point is a global optimum despite the joint problem being non-jointly-convex. We establish asymptotic normality with valid coverage, minimum-variance unbiasedness within the linear-prediction augmented inverse propensity weighted (AIPW) class, and a closed-form criterion identifying when multiple predictors help. On synthetic data and three healthcare monitoring tasks, AM-PPI produces 10 to 40 percent narrower confidence intervals (CIs) than single-predictor ASI in the budget regime where routing matters, and matches the better baseline elsewhere.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Active Multiple-Prediction-Powered Inference (AM-PPI) to enable label-efficient, statistically valid inference for post-deployment healthcare AI monitoring. It extends single-predictor methods by adaptively routing each instance to a cost-appropriate subset of available predictors, sampling gold-standard labels in proportion to the subset's residual uncertainty, and reweighting predictions to minimize estimator variance, all subject to a single deployment-time budget. The authors derive closed-form KKT conditions for the joint decisions on routing, sampling proportions, and reweighting; prove that the resulting fixed point is globally optimal via biconvexity and strong duality despite the problem not being jointly convex; establish asymptotic normality with valid coverage; show minimum-variance unbiasedness within the linear-prediction AIPW class; and provide a closed-form criterion for when multiple predictors improve performance. Experiments on synthetic data and three healthcare tasks report 10-40% narrower confidence intervals than single-predictor ASI baselines in relevant budget regimes.
Significance. If the derivations hold, the work meaningfully generalizes prediction-powered inference and active statistical inference to heterogeneous predictor ensembles with per-instance adaptation, addressing a practical gap in clinical AI monitoring where multiple models of differing cost and accuracy are typically available. The closed-form KKT conditions, biconvexity-based global optimality proof, and minimum-variance result within the AIPW class are notable strengths, as is the explicit criterion identifying when multiple predictors help. These elements, combined with the reported empirical efficiency gains, position the method as a potentially useful tool for label-efficient inference under realistic deployment constraints.
minor comments (3)
- [Abstract] Abstract: the acronym 'AIPW' appears before its expansion; spell out 'augmented inverse propensity weighted' on first use to aid readers outside the immediate subfield.
- The empirical claims of 10-40% narrower CIs would be strengthened by explicit reference to the precise budget regimes and single-predictor baselines used in the comparison (e.g., which predictor is chosen when routing does not matter).
- A compact notation table summarizing the three decision variables (per-instance routing, sampling proportions, and reweighting) and their associated KKT conditions would improve readability of the theoretical sections.
Simulated Author's Rebuttal
We thank the referee for their detailed and positive summary of the manuscript, for highlighting the strengths of the derivations (KKT conditions, biconvexity-based optimality, minimum-variance result within the AIPW class, and closed-form criterion), and for recommending minor revision. We are pleased that the practical relevance for label-efficient post-deployment healthcare AI monitoring was recognized.
Circularity Check
No significant circularity; derivation uses standard KKT, biconvexity, and duality on explicitly formulated objective
full rationale
The paper formulates a joint optimization over per-instance routing, label sampling proportions, and reweighting under a budget, then derives closed-form KKT conditions and invokes biconvexity plus strong duality to establish global optimality. These steps rely on standard convex-analysis results applied to the stated objective rather than any self-referential definition, fitted parameter renamed as a prediction, or load-bearing self-citation. Asymptotic normality, coverage, and minimum-variance unbiasedness are asserted inside the linear AIPW class using conventional semiparametric arguments. No equation or claim in the provided description reduces the claimed optimum to an input by construction, so the derivation chain remains non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The joint decision problem over routing, sampling, and reweighting is biconvex
- domain assumption Estimators belong to the linear-prediction augmented inverse propensity weighted (AIPW) class
Reference graph
Works this paper leans on
-
[1]
URLhttp://dx.doi.org/10.52202/068431-0833
doi: 10.52202/068431-0833. URLhttp://dx.doi.org/10.52202/068431-0833. Philip Chung, Akshay Swaminathan, Alex J. Goodell, Yeasul Kim, S. Momsen Reincke, Lichy Han, Ben Deverett, Mohammad Amin Sadeghi, Abdel-Badih Ariss, Marc Ghanem, David Seong, Andrew A. Lee, Caitlin E. Coombes, Brad Bradshaw, Mahir A. Sufian, Hyo Jung Hong, Teresa P. Nguyen, Mohammad R. ...
-
[2]
URLhttps://arxiv.org/abs/2511.08991. Jiacheng Miao and Qiongshi Lu. Task-agnostic machine-learning-assisted inference. InAdvances in Neural Information Processing Systems 37, NeurIPS 2024, pages 106162–106189. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017-3368. URLhttp://dx.doi.org/10.52202/079017-3368. NVIDI...
-
[3]
ISSN 1537-274X. doi: 10.1080/01621459.1995.10476494. URL http://dx.doi.org/ 10.1080/01621459.1995.10476494. Elham Tabassi. Artificial intelligence risk management framework (AI RMF 1.0). Technical report, National Institute of Standards and Technology (U.S.), January 2023. URL http://dx.doi. org/10.6028/NIST.AI.100-1. U.S. Food and Drug Administration. Ar...
-
[4]
Compute the conditional mean over the given burn-in data and show it equals θ∗ for any nuisance value withˆπ >0
-
[5]
Apply the Lindeberg–Lévy CLT conditionally on the burn-in
-
[6]
Show the conditional variance converges in probability toV
-
[7]
Step 1: Conditional Mean Let FN denote the σ-algebra generated by the burn-in data
Show unconditional convergence. Step 1: Conditional Mean Let FN denote the σ-algebra generated by the burn-in data. Conditional on FN , the nuisance parameters (ˆπ,ˆλI , ˆI) are deterministic, and the deployment data (Xi, Yi)n i=1 are i.i.d. with ξi ∼ Bern(ˆπ(Xi))drawn independently. The increments ∆i = ˆλ⊤ ˆI fˆI(Xi) + Yi − ˆλ⊤ ˆI fˆI(Xi) ξi ˆπ(Xi) are t...
-
[8]
(12)) 2.V N p − →V(Step 3) We now lift to unconditional convergence
√n(ˆθ−θ ∗)| F N d − → N(0, VN)(Step 2, Eq. (12)) 2.V N p − →V(Step 3) We now lift to unconditional convergence. LetZn = √n(ˆθ−θ ∗). The conditional convergence in (1) implies that the conditional characteristic function converges: E eitZn | F N p − →e−t2VN /2 for each t∈R . Since VN p − →Vby (2), we have e−t2VN /2 p − →e−t2V /2. Taking unconditional expec...
-
[9]
The1/π ∗ term: 1 n E[rI /π∗ I ] = p µclabel/nE[ √rI]
-
[10]
The−1term:− 1 n E[rI]
-
[11]
Since terms (1) and (3) are equal, the combined coefficient on E[√rI] is 2 p µclabel/n
The budget term:µ c label E[π∗ I ] = p µclabel/nE[ √rI]. Since terms (1) and (3) are equal, the combined coefficient on E[√rI] is 2 p µclabel/n. Multiplying through bynand differentiating: 2√nµclabel d dλI E hp rI(X) i − d dλI E[rI(X)] = 0. For the second derivative, d dλI E[rI] =−2E[(Y−λ ⊤ I fI)f I]. For the first, define s(x) =r I(x) and apply the chain...
work page 2004
-
[12]
The choiceh I ≡1makes this automatic
(Unbiasedness condition.) ˆθ(g, h, π, I) is unbiased forθ∗ iff E[gI(X)+h I(X)(µ(X)−g I(X))] = E[Y]. The choiceh I ≡1makes this automatic
-
[13]
easy” (all predictors achieve small residual variance re) and a fraction 1−p are “hard
(Reduction to hI ≡1 .) For any unbiased (g, h, π, I)∈ ˜C, define ˜gI(x) :=h I(x)gI(x) + 1−h I(x) µ(x). Then (˜g,1, π, I)∈ ˜C is unbiased and its asymptotic variance satisfies V(˜g,1, π, I)≤V(g, h, π, I), with equality only whenh I(x) = 1on{µ(x)̸=g I(x)}P X-a.s. Consequently, hI ≡1 uniquely (up to PX-null sets where µ=g I) attains the variance minimum with...
work page 1998
- [14]
-
[15]
**Numerical Mismatch (Inconsistent):** Do lab values, dosages, or dates in the EHR contradict the note?
-
[16]
**Omissions (Inconsistent):** If information is in the note but missing from the EHR, mark as INCONSISTENT
-
[17]
**Extra EHR Data (Consistent):** The EHR is a comprehensive record that can contain information not mentioned in the brief discharge note. Do NOT penalize this. As long as everything in the note exists in the EHR, mark as 1
-
[18]
Do not mark as an omission if there was nothing to report in either source
**Mutual Absence (Consistent):** If a section in the clinical note is empty, blank, or says "None," and the corresponding section in the structured EHR is also empty (e.g., [] or no codes listed), this is CONSISTENT. Do not mark as an omission if there was nothing to report in either source. Analyze whether all key information documented in the clinical n...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.