Recognition: 2 theorem links
· Lean TheoremCUDABeaver: Benchmarking LLM-Based Automated CUDA Debugging
Pith reviewed 2026-05-12 01:40 UTC · model grok-4.3
The pith
A benchmark for LLM CUDA debugging shows that models often pass tests by degenerating optimized code into slower versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
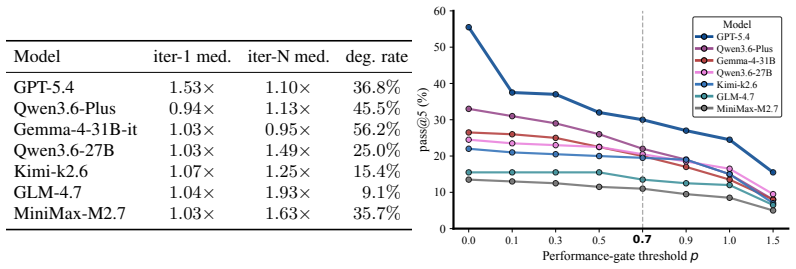
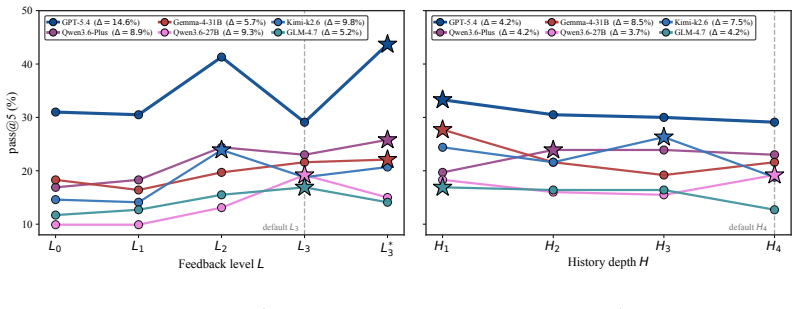
CUDABEAVER supplies tasks drawn from actual LLM-generated failing CUDA workspaces together with native build and test commands and error evidence. It evaluates fixers not only on whether they restore correctness but also on whether they preserve performance, reporting results by failure category, debugging trajectory, and stagnation mode. The protocol-conditional metric pass@k(M,C,A) applied to seven LLMs demonstrates that high tolerance for performance loss makes fixers appear stronger, whereas stricter performance requirements sharply reduce success scores by up to 40 percentage points.
What carries the argument
The CUDABEAVER benchmark of 213 tasks from real failing workspaces and the pass@k(M,C,A) metric that conditions evaluation on model, corpus, and explicit protocol axes including performance preservation.
If this is right
- Evaluations of LLM code repair in performance-critical domains must incorporate explicit performance checks or risk overestimating capability.
- Small adjustments to performance-loss tolerance produce large shifts in reported debugging success.
- Detailed breakdowns by failure category and stagnation mode expose specific LLM weaknesses in handling CUDA memory and execution subtleties.
- True repair requires restoring both correctness and the original optimization structure rather than substituting a slower safe variant.
Where Pith is reading between the lines
- Similar degeneration risks likely exist in benchmarks for other performance-sensitive languages such as OpenCL or HIP.
- Extending the benchmark to multi-file projects or runtime profiling data could surface additional failure modes not captured by single-file edits.
- Protocol-aware metrics may become standard for any automated repair task where speed matters as much as correctness.
Load-bearing premise
The 213 tasks drawn from LLM-generated failing workspaces are representative of real-world CUDA debugging needs and the chosen performance preservation metric correctly identifies degeneration without missing other failure modes.
What would settle it
Apply the same seven LLMs to a fresh collection of human-authored failing CUDA programs and measure whether the 40-point swing in success rate between loose and strict performance protocols still appears.
Figures



read the original abstract
Debugging CUDA programs has long been challenging because failures often arise from subtle interactions among hardware behavior, compiler decisions, memory hierarchy, and asynchronous execution. More importantly, with the rapid expansion of GPU usage across scientific computing, machine learning, graphics, and systems workloads, CUDA debugging has become more challenging than ever. Current evaluations of LLM-based CUDA programming largely miss this setting: a model can pass correctness tests with repair by degeneration, simplifying the CUDA code into a safer but slower program that abandons the original optimization structure. We introduce CUDABEAVER, a benchmark for CUDA debugging from real failing workspaces produced during LLM-based CUDA generation. Each task provides the broken candidate, native build/test commands, raw error evidence, and a single editable file. CUDABEAVER evaluates whether a fixer truly repairs the failing CUDA code or merely finds a slower test-passing replacement, reporting results by failure category, debugging trajectory, stagnation mode, and performance preservation. We further propose pass@k(M,C,A), a protocol-conditional CUDA debugging metric by making the fixer M, corpus C, and protocol axes Aexplicit. Using this metric across 213 tasks and seven frontier LLMs, we show that protocol-aware evaluation gives a more faithful view of CUDA debugging ability: when performance-loss tolerance is high, fixers appear much stronger, but even a minor stricter performance requirement can sharply reduce measured success, shifting scores by up to 40 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CUDABeaver, a benchmark of 213 tasks constructed from LLM-generated failing CUDA workspaces, each providing a broken candidate, build/test commands, and error evidence. It proposes the protocol-conditional metric pass@k(M,C,A) that conditions success on model M, corpus C, and evaluation axes A (including performance-loss tolerance). Experiments across seven frontier LLMs show that relaxing performance preservation inflates apparent debugging success, with measured pass rates shifting by up to 40 percentage points under stricter tolerance, arguing that standard evaluations overestimate true repair capability by permitting degenerate but test-passing simplifications.
Significance. If the benchmark tasks prove representative, the work provides a concrete demonstration that protocol design materially affects measured LLM debugging performance on CUDA, highlighting a previously under-examined failure mode (performance-degrading repair). The explicit conditioning on performance axes and reporting by failure category and stagnation mode are useful contributions for future empirical studies in LLM code repair.
major comments (3)
- [Benchmark Construction] Benchmark construction section: the paper states that the 213 tasks originate exclusively from LLM generation runs but provides no validation that the resulting bug distribution (indexing errors, synchronization issues, etc.) matches the hardware-specific, compiler-interaction, or legacy-code pathologies typical of production CUDA maintenance; without such evidence or a comparison to real-world bug corpora, the claim that protocol-aware evaluation yields a 'more faithful view' of debugging ability rests on an untested representativeness assumption.
- [Evaluation Protocol] Evaluation and metric definition: the performance-preservation component of pass@k(M,C,A) is described at a high level but lacks precise operationalization (e.g., exact runtime thresholds relative to the original optimized code, hardware platform used for timing, handling of non-deterministic kernels); this ambiguity directly affects the reported 40pp swings and prevents readers from reproducing or extending the sensitivity analysis.
- [Experimental Results] Results and statistical controls: while results are broken down by failure category and trajectory, the manuscript does not report confidence intervals, multiple-run variance, or controls for prompt sensitivity and temperature; given that the central empirical claim concerns large metric shifts, absence of these controls leaves the magnitude and reliability of the 40pp effect only partially supported.
minor comments (2)
- [Metric Definition] Notation for pass@k(M,C,A) is introduced without an explicit equation; adding a formal definition would improve clarity.
- [Abstract and Introduction] The abstract and introduction use 'real failing workspaces' without immediate qualification that these are LLM-generated; a parenthetical clarification on first use would prevent misreading.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction section: the paper states that the 213 tasks originate exclusively from LLM generation runs but provides no validation that the resulting bug distribution (indexing errors, synchronization issues, etc.) matches the hardware-specific, compiler-interaction, or legacy-code pathologies typical of production CUDA maintenance; without such evidence or a comparison to real-world bug corpora, the claim that protocol-aware evaluation yields a 'more faithful view' of debugging ability rests on an untested representativeness assumption.
Authors: We agree that the benchmark's construction from LLM-generated failures means its bug distribution has not been explicitly validated against production CUDA corpora. Our design choice targets the specific use case of repairing errors produced by LLMs themselves, which is directly relevant to automated debugging pipelines. We will revise the benchmark construction and limitations sections to explicitly state this scope, add a qualitative comparison of observed bug types (e.g., indexing, synchronization) to those reported in open CUDA repositories where possible, and frame the 'more faithful view' claim as conditional on this LLM-centric setting rather than claiming broad representativeness of all CUDA maintenance. revision: partial
-
Referee: [Evaluation Protocol] Evaluation and metric definition: the performance-preservation component of pass@k(M,C,A) is described at a high level but lacks precise operationalization (e.g., exact runtime thresholds relative to the original optimized code, hardware platform used for timing, handling of non-deterministic kernels); this ambiguity directly affects the reported 40pp swings and prevents readers from reproducing or extending the sensitivity analysis.
Authors: We acknowledge the need for precise operational details. In the revised manuscript we will expand the metric definition to specify: performance tolerance as no more than 10% increase in kernel runtime relative to the original optimized version; hardware as NVIDIA A100 GPUs with CUDA 12.4; timing via CUDA events averaged over 5 warm-up and 10 measurement runs; and non-determinism handling by fixing seeds for random operations and reporting median runtime across runs. These additions will make the 40pp sensitivity results fully reproducible. revision: yes
-
Referee: [Experimental Results] Results and statistical controls: while results are broken down by failure category and trajectory, the manuscript does not report confidence intervals, multiple-run variance, or controls for prompt sensitivity and temperature; given that the central empirical claim concerns large metric shifts, absence of these controls leaves the magnitude and reliability of the 40pp effect only partially supported.
Authors: We agree that additional statistical controls would strengthen the central claim. We will add bootstrap-derived 95% confidence intervals to all pass@k(M,C,A) figures, include a sensitivity table showing variance across three temperatures (0.0, 0.2, 0.5) and two prompt phrasings, and report the standard deviation of the observed metric shifts. These controls will be computed from additional evaluation runs performed during revision. revision: yes
Circularity Check
No circularity: pure empirical benchmark with direct measurements
full rationale
The paper introduces an empirical benchmark (CUDABEAVER with 213 tasks) and a conditional metric pass@k(M,C,A), then reports measured success rates under varying performance tolerances. All claims rest on experimental outcomes from held-out tasks rather than any derivation, fitted parameter, or self-referential prediction. No equations, uniqueness theorems, or ansatzes appear; the central observation (up to 40pp score shift) is a direct count of pass/fail under different protocol axes. Self-citations, if present, are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formalise that pass@k itself is protocol-conditional... pass@k(M, C, A)... performance-gate threshold p in pass=correctness∧speedup≥p
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearrepair by degeneration... abandoning the original kernel’s optimized structure
Reference graph
Works this paper leans on
-
[1]
When benchmarks are targets: Revealing the sensitivity of large language model leaderboards
Norah Alzahrani, Hisham Alyahya, Yazeed Alnumay, Sultan Alrashed, Shaykhah Alsubaie, Yousef Almushayqih, Faisal Mirza, Nouf Alotaibi, Nora Al-Twairesh, Areeb Alowisheq, et al. When benchmarks are targets: Revealing the sensitivity of large language model leaderboards. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistic...
work page 2024
-
[2]
Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948,
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948, 2025
-
[3]
An improved monte carlo factorization algorithm.BIT Numerical Mathematics, 20(2):176–184, 1980
Richard P Brent. An improved monte carlo factorization algorithm.BIT Numerical Mathematics, 20(2):176–184, 1980
work page 1980
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Bringmann, John Tran, Wei Liu, Fung Xie, Michael Lightstone, and Humphrey Shi
Terry Chen, Zhifan Ye, Bing Xu, Zihao Ye, Timmy Liu, Ali Hassani, Tianqi Chen, Andrew Kerr, Haicheng Wu, Yang Xu, et al. Avo: Agentic variation operators for autonomous evolutionary search.arXiv preprint arXiv:2603.24517, 2026
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023. URLhttps://arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Kenneth Alan De Jong.An analysis of the behavior of a class of genetic adaptive systems. University of Michigan, 1975
work page 1975
-
[8]
Philippe Flajolet and Andrew M Odlyzko. Random mapping statistics. InWorkshop on the Theory and Application of of Cryptographic Techniques, pages 329–354. Springer, 1989
work page 1989
-
[9]
Don't Pass@k: A Bayesian Framework for Large Language Model Evaluation
Mohsen Hariri, Amirhossein Samandar, Michael Hinczewski, and Vipin Chaudhary. Don’t pass@ k: A bayesian framework for large language model evaluation.arXiv preprint arXiv:2510.04265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review arXiv 1904
-
[11]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The twelfth international conference on learning representations, 2023
work page 2023
-
[12]
Addison-Wesley Professional, 2014
Donald E Knuth.The art of computer programming: Seminumerical algorithms, volume 2. Addison-Wesley Professional, 2014
work page 2014
-
[13]
Tritonbench: Benchmarking large language model capabilities for generating triton operators
Jianling Li, Shangzhan Li, Zhenye Gao, Qi Shi, Yuxuan Li, Zefan Wang, Jiacheng Huang, WangHaojie WangHaojie, Jianrong Wang, Xu Han, et al. Tritonbench: Benchmarking large language model capabilities for generating triton operators. InFindings of the Association for Computational Linguistics: ACL 2025, pages 23053–23066, 2025
work page 2025
-
[14]
Shiyang Li, Zijian Zhang, Winson Chen, Yuebo Luo, Mingyi Hong, and Caiwen Ding. Stitchcuda: An automated multi-agents end-to-end gpu programing framework with rubric- based agentic reinforcement learning, 2026
work page 2026
- [15]
-
[16]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/ 2303.17651. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang Cai, Haichao Z...
work page internal anchor Pith review arXiv 2025
-
[18]
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt llm evaluation.Transactions of the Association for Computational Linguistics, 12:933–949, 2024
work page 2024
-
[19]
Computeeval: Evaluating large language models for cuda code generation
NVIDIA. Computeeval: Evaluating large language models for cuda code generation. GitHub repository, 2025. URLhttps://github.com/NVIDIA/compute-eval
work page 2025
-
[20]
NVIDIA. Cutlass. GitHub repository, 2026. URL https://github.com/NVIDIA/ cutlass
work page 2026
-
[21]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama
Theo X Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar- Lezama. Is self-repair a silver bullet for code generation?arXiv preprint arXiv:2306.09896, 2023
-
[22]
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517, 2025
-
[23]
Perfcodegen: Improving performance of llm generated code with execution feedback
Yun Peng, Akhilesh Deepak Gotmare, Michael R Lyu, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Perfcodegen: Improving performance of llm generated code with execution feedback. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), pages 1–13. IEEE, 2025
work page 2025
-
[24]
Andrea Saltelli, Marco Ratto, Terry Andres, Francesca Campolongo, Jessica Cariboni, Debora Gatelli, Michaela Saisana, and Stefano Tarantola.Global sensitivity analysis: the primer. John Wiley & Sons, 2008
work page 2008
-
[25]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.arXiv preprint arXiv:2310.11324, 2023
-
[26]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Hunting cuda bugs at scale with cufuzz
Mohamed Tarek Ibn Ziad and Christos Kozyrakis. Hunting cuda bugs at scale with cufuzz. Proceedings of the ACM on Programming Languages, 10(OOPSLA1):877–904, 2026
work page 2026
-
[28]
Mohamed Tarek Ibn Ziad, Sana Damani, Aamer Jaleel, Stephen W Keckler, and Mark Stephen- son. Cucatch: A debugging tool for efficiently catching memory safety violations in cuda applications.Proceedings of the ACM on Programming Languages, 7(PLDI):124–147, 2023
work page 2023
-
[29]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bowe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Kimi Team, Yifan Bai, Yiping Bao, Y . Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong G...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
ThunderKittens Authors. Thunderkittens. GitHub repository, 2026. URL https://github. com/HazyResearch/ThunderKittens
work page 2026
-
[33]
Debugbench: Evaluating debugging capability of large 15 language models
Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Hui Haotian, Liu Weichuan, Zhiyuan Liu, et al. Debugbench: Evaluating debugging capability of large 15 language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4173–4198, 2024
work page 2024
-
[34]
Characterizing and detecting cuda program bugs.arXiv preprint arXiv:1905.01833, 2019
Mingyuan Wu, Husheng Zhou, Lingming Zhang, Cong Liu, and Yuqun Zhang. Characterizing and detecting cuda program bugs.arXiv preprint arXiv:1905.01833, 2019
-
[35]
Chunqiu Steven Xia and Lingming Zhang. Keep the conversation going: Fixing 162 out of 337 bugs for $0.42 each using chatgpt.arXiv preprint arXiv:2304.00385, 2023
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Cudaforge: An agent framework with hardware feedback for cuda kernel optimization, 2025
Zijian Zhang, Rong Wang, Shiyang Li, Yuebo Luo, Mingyi Hong, and Caiwen Ding. Cudaforge: An agent framework with hardware feedback for cuda kernel optimization, 2025
work page 2025
-
[38]
Yuhao Zhou, Peng Jia, Jiayong Liu, and Ximing Fan. Fuzz4cuda: Fuzzing your nvidia gpu libraries through debug interface.Computers & Security, page 104754, 2025
work page 2025
-
[39]
C"linkage. •task.yaml — metadata including anti-cheat blocked patterns (e.g., #include
Jiace Zhu, Wentao Chen, Qi Fan, Zhixing Ren, Junying Wu, Xing Zhe Chai, Chotiwit Run- grueangwutthinon, Yehan Ma, and An Zou. Cudabench: Benchmarking llms for text-to-cuda generation.arXiv preprint arXiv:2603.02236, 2026. 16 A Asymmetric pass@kNormalisation When the fixer is also a broken-start source, its pipeline is structurally one step ahead: the brok...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.