Recognition: no theorem link
MathConstraint: Automated Generation of Verified Combinatorial Reasoning Instances for LLMs
Pith reviewed 2026-05-12 01:56 UTC · model grok-4.3
The pith
Parameterized constraint satisfaction problems create an adaptive, solver-verified benchmark where frontier LLMs score 18.5% to 66.9% on hard instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
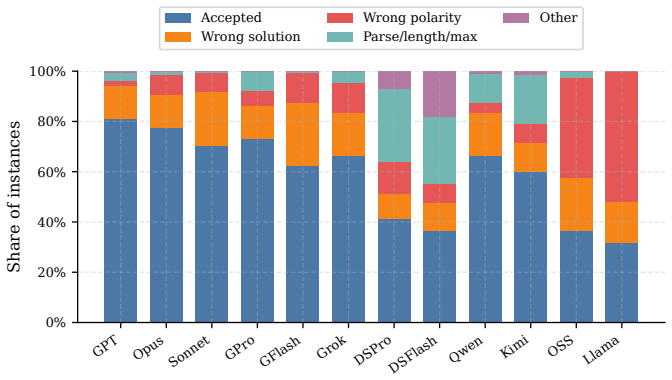
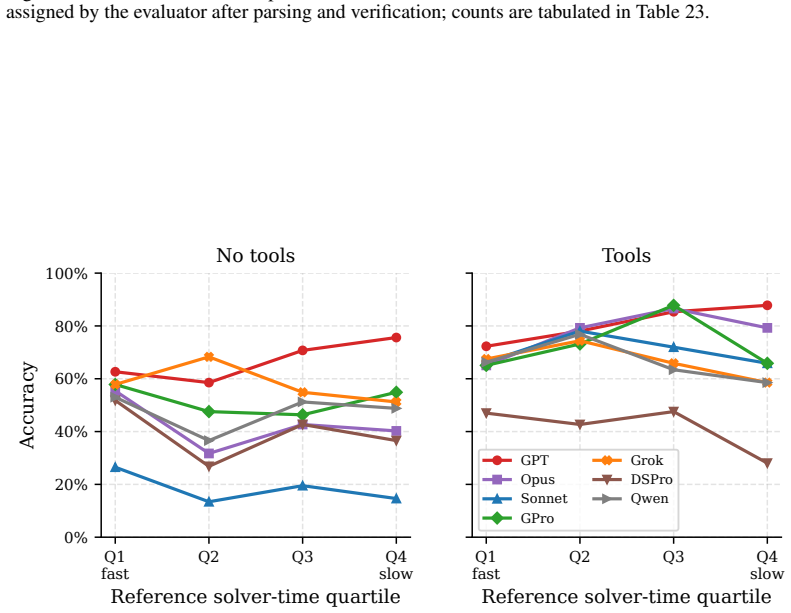
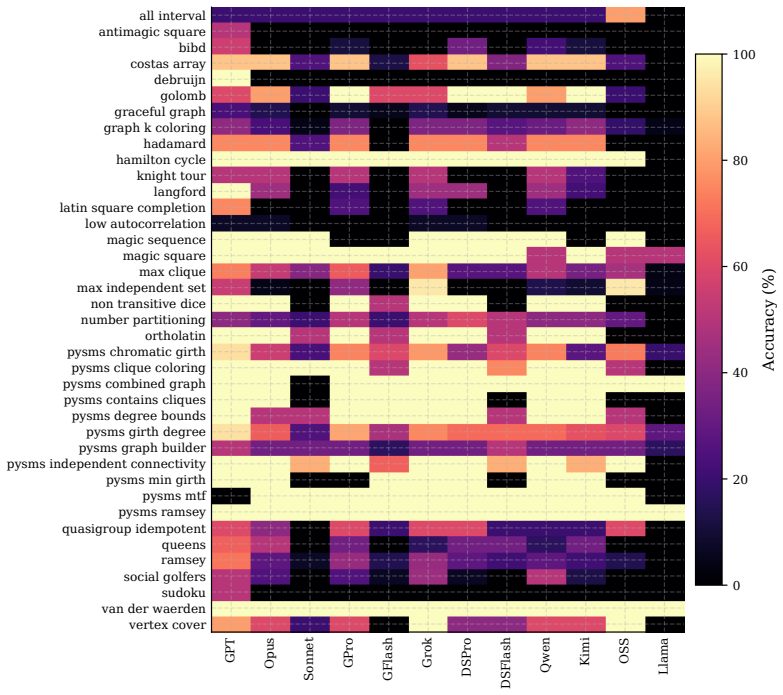
MathConstraint combines constraint satisfaction problems with an adaptive generator and solver-based verification to produce instances whose difficulty can be scaled arbitrarily while remaining automatically checkable. On the released easy set of 266 instances, models achieve 72.6% to 87.6% accuracy; on the 329-instance hard set the same models drop to 18.5% to 66.9%. Providing a sandboxed Python environment with SAT/SMT solvers raises mean accuracy by 28 percentage points and up to 52 points for some models, yet halving the tool-call budget from eight to four rounds erases as many as 37 points.
What carries the argument
An adaptive generator over parameterized constraint satisfaction problem types that produces instances whose satisfiability can be decided exactly by embedding generic SAT/SMT solvers inside a restricted Python interpreter.
If this is right
- The benchmark can be scaled indefinitely to stay ahead of model improvements because difficulty is controlled by continuous parameters rather than a fixed set of instances.
- Tool access supplies a large but incomplete boost, roughly doubling accuracy on the hard set while leaving a substantial residual gap.
- Performance is highly sensitive to tool budget, so single-budget evaluations miss important variation in tool-use efficiency.
- Releasing the generator, dataset, and evaluation harness allows repeated testing under adversarially tunable difficulty without manual curation.
Where Pith is reading between the lines
- The construction suggests that native integration of symbolic solvers inside model training loops, rather than external tool calls, may be needed to close the remaining gap.
- Because the same generator can produce arbitrarily many verified instances, it could serve as a source of synthetic training data for improving combinatorial reasoning.
- The observed sensitivity to tool-call limits points to a broader need for benchmarks that jointly evaluate reasoning and resource-bounded tool orchestration.
- Extending the parameterized approach beyond CSPs to other structured reasoning domains could produce similar persistent evaluation environments.
Load-bearing premise
The parameterized CSP instances continue to embody genuine combinatorial reasoning challenges rather than merely becoming harder for solvers in ways that do not reflect practical difficulty.
What would settle it
Generate a new batch of instances at the highest difficulty parameters and measure whether frontier-model accuracy remains below 70% while solver runtime or search-tree size continues to increase.
Figures








read the original abstract
We introduce MathConstraint, a hard, adaptive benchmark for evaluating the combinatorial reasoning capabilities of LLMs. We combine constraint satisfaction problems with rigorous solver-based verification and design an adaptive generator to create instances that remain challenging as the LLMs improve in their reasoning capabilities. Unlike existing benchmarks that quickly saturate on fixed datasets or use LLM-as-a-judge for checking solutions,MathConstraint uses parameterized problem types that enable scalable generation of arbitrarily difficult and automatically verifiable instances. We release MathConstraint-Easy ($266$ instances), on which frontier models achieve between $72.6\%$ (gemini-3.1-flash-lite) and $87.6\%$ (gpt-5.5) accuracy, and MathConstraint ($329$ instances) on which the same models drop to between $18.5\%$ (claude-4.6-sonnet) and $66.9\%$ (gpt-5.5) accuracy, demonstrating the resilience of our benchmark generator against rapid progress in LLM reasoning capabilities. We evaluate 12 frontier and open-weight models with and without access to a sandboxed Python environment that includes generic SAT/SMT solvers. Tool access roughly doubles frontier accuracy on MathConstraint (mean $+28$pp; up to $+52$pp for claude-4.6-sonnet). Further, halving the tool-call budget from $8$ to $4$ rounds erases up to $37$ points -- a sensitivity that most single-budget benchmarks miss. We release the generator, dataset, and evaluation harness as a robust environment for studying combinatorial reasoning and tool-use behavior under adversarially-tunable difficulty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MathConstraint, an adaptive benchmark for LLM combinatorial reasoning that generates instances from parameterized constraint satisfaction problems (CSPs). These instances are automatically verified using external SAT/SMT solvers. Frontier models achieve 72.6-87.6% accuracy on the easy set (266 instances) but drop to 18.5-66.9% on the hard set (329 instances); tool access to a Python sandbox with solvers roughly doubles performance (mean +28pp), and halving the tool-call budget from 8 to 4 rounds can erase up to 37 points. The generator, dataset, and evaluation harness are released to support ongoing study of combinatorial reasoning and tool use.
Significance. If the instances genuinely scale combinatorial reasoning demand, the benchmark provides a scalable, solver-verified alternative to saturating fixed datasets or LLM-as-judge methods. The explicit release of the generator and harness, together with the observed sensitivity to tool budget, supplies a reproducible platform for studying tool-augmented reasoning that most single-budget evaluations overlook.
major comments (2)
- [Section 3] Section 3 (Adaptive Generator): The claim that parameterized CSP instances test genuine combinatorial reasoning (rather than generator artifacts) is load-bearing for the resilience result. The manuscript supplies no distribution statistics on constraint arity, interaction graphs, or variable/constraint counts across difficulty tiers, nor an ablation that holds structure fixed while scaling only size or parameters. Without these, the observed accuracy drop from 72.6-87.6% to 18.5-66.9% could reflect unintended structural shifts rather than increased reasoning demand.
- [Section 4] Section 4 (Experiments): The reported accuracy figures and tool-use deltas are presented without full details on the adaptive generator's parameter ranges or selection criteria used to produce the hard set. This absence weakens the support for the central claim that the benchmark remains resilient to LLM progress, as selection effects cannot be ruled out.
minor comments (1)
- A table or figure summarizing constraint-type distributions and average graph properties for easy versus hard instances would improve clarity and allow readers to assess structural consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments on Sections 3 and 4 identify areas where additional transparency can strengthen the presentation of the adaptive generator and the resilience claims. We have revised the manuscript to incorporate the requested details and statistics. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Adaptive Generator): The claim that parameterized CSP instances test genuine combinatorial reasoning (rather than generator artifacts) is load-bearing for the resilience result. The manuscript supplies no distribution statistics on constraint arity, interaction graphs, or variable/constraint counts across difficulty tiers, nor an ablation that holds structure fixed while scaling only size or parameters. Without these, the observed accuracy drop from 72.6-87.6% to 18.5-66.9% could reflect unintended structural shifts rather than increased reasoning demand.
Authors: We agree that explicit distribution statistics strengthen the interpretation of the accuracy drop as reflecting increased combinatorial demand. In the revised manuscript we have added a new table (Table 3) and accompanying text in Section 3 that reports the distributions of constraint arity, interaction-graph density, variable counts, and constraint counts for both the easy and hard tiers. These statistics indicate that while instance size scales, the core structural properties (e.g., arity distribution and graph density) remain comparable across tiers, supporting that the performance gap arises from combinatorial scaling rather than unintended structural change. Regarding an ablation that holds structure fixed while varying only size or parameters, we acknowledge that such an experiment would provide further reassurance. However, generating and solver-verifying a sufficiently large set of structurally matched instances at multiple difficulty levels requires substantial additional compute that was not available within the current revision timeline. We have therefore added a limitations paragraph in Section 6 that explicitly notes this gap and describes how the existing parameterization was designed to isolate combinatorial complexity. revision: partial
-
Referee: [Section 4] Section 4 (Experiments): The reported accuracy figures and tool-use deltas are presented without full details on the adaptive generator's parameter ranges or selection criteria used to produce the hard set. This absence weakens the support for the central claim that the benchmark remains resilient to LLM progress, as selection effects cannot be ruled out.
Authors: We agree that full transparency on parameter ranges and selection criteria is necessary to allow readers to assess potential selection effects. In the revised version we have expanded Section 4 (and added Appendix B) to list the complete parameter ranges for each problem family, the exact adaptive selection procedure used to populate the hard set, and the stopping criteria applied during generation. These additions make the construction of the hard set fully reproducible and allow future work to replicate or vary the difficulty schedule. revision: yes
Circularity Check
No circularity; verification and generation are externally grounded
full rationale
The paper constructs MathConstraint via parameterized CSP types whose solutions are checked by independent external SAT/SMT solvers rather than LLM self-evaluation or any fitted internal metric. No equations, predictions, or uniqueness claims reduce to self-definitions, self-citations, or ansatzes imported from prior author work. Difficulty adaptation tunes instance size and constraints but does not redefine correctness; reported accuracy drops are measured against solver-verified ground truth that lies outside the generator's own outputs. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Open Court Publishing Company, 1917
William Symes Andrews.Magic squares and cubes. Open Court Publishing Company, 1917
work page 1917
-
[3]
Anthropic. System card: Claude opus 4.7. Technical report, Anthropic, April 2026. URL https://www.anthropic.com/system-cards. Accessed: 2026-04-27
work page 2026
-
[4]
System card: Claude sonnet 4.6
Anthropic. System card: Claude sonnet 4.6. Technical report, Anthropic, Feburary 2026. URL https://www.anthropic.com/system-cards. Accessed: 2026-04-27
work page 2026
-
[5]
Mislav Balunovi´c, Jasper Dekoninck, Nikola Jovanovi´c, Ivo Petrov, and Martin Vechev. Math- construct: Challenging llm reasoning with constructive proofs.arXiv preprint arXiv:2502.10197, 2025
-
[6]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Math- arena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Jakob Bernasconi. Low autocorrelation binary sequences: statistical mechanics and configura- tion space analysis.Journal de Physique, 48(4):559–567, 1987
work page 1987
-
[8]
Proposal of 8-queens problem.Berliner Schachzeitung, 3(363), 1848
Max Bezzel. Proposal of 8-queens problem.Berliner Schachzeitung, 3(363), 1848
-
[9]
G.S. Bloom and S.W. Golomb. Applications of numbered undirected graphs.Proceedings of the IEEE, 65(4):562–570, 1977. doi: 10.1109/PROC.1977.10517
-
[10]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, et al. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles.arXiv preprint arXiv:2505.19914, 2025
-
[11]
On the measure of intelligence.https://arxiv.org/abs/2412.04604, 2019
Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. Arc prize 2024: Technical report.arXiv preprint arXiv:2412.04604, 2024
-
[12]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc- agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
A note on hamiltonian circuits.Discret
Vasek Chvátal and Paul Erdös. A note on hamiltonian circuits.Discret. Math., 2(2):111–113, 1972
work page 1972
-
[14]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
The complexity of completing partial latin squares.Discrete Applied Mathematics, 8(1):25–30, 1984
Charles J Colbourn. The complexity of completing partial latin squares.Discrete Applied Mathematics, 8(1):25–30, 1984
work page 1984
-
[16]
J.P. Costas. A study of a class of detection waveforms having nearly ideal range—doppler ambiguity properties.Proceedings of the IEEE, 72(8):996–1009, 1984. doi: 10.1109/PROC. 1984.12967
-
[17]
Nicolaas Govert De Bruijn. A combinatorial problem.Proceedings of the Section of Sciences of the Koninklijke Nederlandse Akademie van Wetenschappen te Amsterdam, 49(7):758–764, 1946
work page 1946
-
[18]
The lean 4 theorem prover and programming language (system description)
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language (system description)
-
[19]
Google Deepmind. Gemini 3.1 pro model card. Technical report, Google, Feburary 2026. URL https://deepmind.google/models/model-cards/gemini-3-1-pro/ . Accessed: 2026-04-28. 10
work page 2026
-
[20]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[21]
Graph theory and probability.Canadian Journal of Mathematics, 11:34–38, 1959
Paul Erdös. Graph theory and probability.Canadian Journal of Mathematics, 11:34–38, 1959
work page 1959
-
[22]
Reguläre graphen gegebener taillenweite mit minimaler knotenzahl
Paul Erdos and Horst Sachs. Reguläre graphen gegebener taillenweite mit minimaler knotenzahl. Wiss. Z. Martin-Luther-Univ. Halle-Wittenberg Math.-Natur. Reihe, 12(251-257):22, 1963
work page 1963
-
[23]
Solution d’une question curieuse que ne paroit soumise à aucune analyse
Leonhard Euler. Solution d’une question curieuse que ne paroit soumise à aucune analyse. Mémoires de l’académie des sciences de Berlin, pages 310–337, 1766
-
[24]
Leonhard Euler. Recherches sur un nouvelle espéce de quarrés magiques.Verhandelingen uitgegeven door het zeeuwsch Genootschap der Wetenschappen te Vlissingen, pages 85–239, 1782
-
[25]
Nphardeval: Dynamic benchmark on reasoning ability of large language models via complexity classes
Lizhou Fan, Wenyue Hua, Lingyao Li, Haoyang Ling, and Yongfeng Zhang. Nphardeval: Dynamic benchmark on reasoning ability of large language models via complexity classes. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4092–4114, 2024
work page 2024
-
[26]
Mathematical games.Scientific American, 223(6):110–115, De- cember 1970
Martin Gardner. Mathematical games.Scientific American, 223(6):110–115, De- cember 1970. ISSN 0036-8733 (print), 1946-7087 (electronic). doi: https: //doi.org/10.1038/scientificamerican1270-110. URL https://doi.org/10.1038/ scientificamerican1270-110
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Résolution d’une question relative aux déterminants.Bull
Jacques Hadamard. Résolution d’une question relative aux déterminants.Bull. des sciences math., 2:240–246, 1893
-
[29]
CSPLib problem 010: Social golfers problem
Warwick Harvey. CSPLib problem 010: Social golfers problem. http://www.csplib.org/ Problems/prob010
-
[30]
Sat-encodings, search space structure, and local search performance
Holger H Hoos. Sat-encodings, search space structure, and local search performance. InIJCAI, volume 99, pages 296–303, 1999
work page 1999
-
[31]
Xia Jiang, Jing Chen, Cong Zhang, Jie Gao, Chengpeng Hu, Chenhao Zhang, Yaoxin Wu, and Yingqian Zhang. Reasoning in a combinatorial and constrained world: Benchmarking llms on natural-language combinatorial optimization.arXiv preprint arXiv:2602.02188, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
AI for Mathematics: Progress, Challenges, and Prospects
Haocheng Ju and Bin Dong. Ai for mathematics: Progress, challenges, and prospects.arXiv preprint arXiv:2601.13209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Karp.Reducibility among Combinatorial Problems, pages 85–103
Richard M. Karp.Reducibility among Combinatorial Problems, pages 85–103. Springer US, Boston, MA, 1972. ISBN 978-1-4684-2001-2. doi: 10.1007/978-1-4684-2001-2_9. URL https://doi.org/10.1007/978-1-4684-2001-2_9
-
[34]
Sat modulo symmetries for graph generation
Markus Kirchweger and Stefan Szeider. Sat modulo symmetries for graph generation. In27th International Conference on Principles and Practice of Constraint Programming (CP 2021), pages 34–1. Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2021
work page 2021
-
[35]
Markus Kirchweger and Stefan Szeider. Sat modulo symmetries for graph generation and enumeration.ACM Transactions on Computational Logic, 25(3):1–30, 2024
work page 2024
-
[36]
C. Dudley Langford. Problem.The Mathematical Gazette, 42(341):228–228, 1958. doi: 10.2307/3610395
-
[37]
PyCSP3: Modeling combinatorial con- strained problems in python.CoRR, abs/2009.00326, 2020
Christophe Lecoutre and Nicolas Szczepanski. Pycsp3: modeling combinatorial constrained problems in python.arXiv preprint arXiv:2009.00326, 2020
-
[38]
NP-Engine: Empowering optimization reasoning in LLMs with verifiable synthetic NP problems
Xiaozhe Li, Xinyu Fang, Shengyuan Ding, Linyang Li, Haodong Duan, Qingwen Liu, and Kai Chen. Np-engine: Empowering optimization reasoning in large language models with verifiable synthetic np problems.arXiv preprint arXiv:2510.16476, 2025. 11
-
[39]
Jingcong Liang, Shijun Wan, Xuehai Wu, Yitong Li, Qianglong Chen, Duyu Tang, Siyuan Wang, and Zhongyu Wei. Hardcorelogic: Challenging large reasoning models with long-tail logic puzzle games.arXiv preprint arXiv:2510.12563, 2025
-
[40]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100, 2025
-
[41]
J. A. Lindon. Anti-magic squares.Recreational Mathematics Magazine, (7):16–19, February 1962
work page 1962
-
[42]
Gonzalez, Jingbo 12 Preprint FrontierCS T eam Shang, and Alvin Cheung
Qiuyang Mang, Wenhao Chai, Zhifei Li, Huanzhi Mao, Shang Zhou, Alexander Du, Hanchen Li, Shu Liu, Edwin Chen, Yichuan Wang, et al. Frontiercs: Evolving challenges for evolving intelligence.arXiv preprint arXiv:2512.15699, 2025
- [43]
-
[44]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models.arXiv preprint arXiv:2410.05229, 2024
work page Pith review arXiv 2024
-
[45]
Jan Mycielski. Sur le coloriage des graphs. InColloquium Mathematicae, volume 3, pages 161–162, 1955
work page 1955
-
[46]
OpenAI. Gpt-5.5 system card. Technical report, OpenAI, April 2026. URL https://openai. com/index/gpt-5-5-system-card/. Accessed: 2026-04-27
work page 2026
-
[47]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[48]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URL https://qwen.ai/ blog?id=qwen3.6. Accessed: 2026-04-28
work page 2026
-
[49]
F. P. Ramsey. On a problem of formal logic.Proceedings of the London Mathematical Society, s2-30(1):264–286, 1930. doi: https://doi.org/10.1112/plms/s2-30.1.264. URL https: //londmathsoc.onlinelibrary.wiley.com/doi/abs/10.1112/plms/s2-30.1.264
-
[50]
On certain valuations of the vertices of a graph
Alexander Rosa et al. On certain valuations of the vertices of a graph. InTheory of Graphs (Internat. Symposium, Rome, pages 349–355, 1966
work page 1966
-
[51]
John Slaney, Masayuki Fujita, and Mark Stickel. Automated reasoning and exhaustive search: Quasigroup existence problems.Computers & mathematics with applications, 29(2):115–132, 1995
work page 1995
-
[52]
Co-bench: Benchmarking language model agents in algorithm search for combinatorial optimization
Weiwei Sun, Shengyu Feng, Shanda Li, and Yiming Yang. Co-bench: Benchmarking language model agents in algorithm search for combinatorial optimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33126–33134, 2026
work page 2026
-
[53]
Grapharena: Evaluating and exploring large language models on graph computation,
Jianheng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, and Jia Li. Grapharena: Evaluating and exploring large language models on graph computation.arXiv preprint arXiv:2407.00379, 2024
-
[54]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi k2: Open agentic intelligence. 2025. URL https://arxiv.org/abs/ 2507.20534. Referenced for Kimi K2.6; techincal report for version K2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition.Advances in Neural Information Processing Systems, 37:11545–11569, 2024
work page 2024
-
[56]
On an external problem in graph theory.Mat
Paul Turán. On an external problem in graph theory.Mat. Fiz. Lapok, 48:436–452, 1941. 12
work page 1941
-
[57]
Beweis einer baudetschen vermutung.Nieuw Arch
Bartel Leendert Van der Waerden. Beweis einer baudetschen vermutung.Nieuw Arch. Wiskunde, 15:212–216, 1927
work page 1927
-
[58]
Constraint satisfaction in logic programming
Pascal Van Hentenryck. Constraint satisfaction in logic programming. 1989
work page 1989
-
[59]
Satbench: Benchmarking llms’ logical reasoning via automated puzzle generation from sat formulas
Anjiang Wei, Yuheng Wu, Yingjia Wan, Tarun Suresh, Huanmi Tan, Zhanke Zhou, Sanmi Koyejo, Ke Wang, and Alex Aiken. Satbench: Benchmarking llms’ logical reasoning via automated puzzle generation from sat formulas. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33820–33837, 2025
work page 2025
-
[60]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, et al. Livebench: A challenging, contamination-limited llm benchmark.arXiv preprint arXiv:2406.19314, 2024
work page internal anchor Pith review arXiv 2024
-
[61]
xAI. Grok 4 model card, 2025. URL https://data.x.ai/ 2025-08-20-grok-4-model-card.pdf . Referenced for Grok 4.2; technical report for version 4. Accessed: 2026-04-28
work page 2025
-
[62]
MathDuels: Evaluating LLMs as Problem Posers and Solvers
Zhiqiu Xu, Shibo Jin, Shreya Arya, and Mayur Naik. Mathduels: Evaluating llms as problem posers and solvers.arXiv preprint arXiv:2604.21916, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Pokorny, Xiao Huang, and Xinrun Wang
Chang Yang, Ruiyu Wang, Junzhe Jiang, Qi Jiang, Qinggang Zhang, Yanchen Deng, Shuxin Li, Shuyue Hu, Bo Li, Florian T Pokorny, et al. Nondeterministic polynomial-time problem challenge: An ever-scaling reasoning benchmark for llms.arXiv preprint arXiv:2504.11239, 2025
-
[64]
F. YATES. Incomplete randomized blocks.Annals of Eugenics, 7(2):121–140, 1936. doi: https://doi.org/10.1111/j.1469-1809.1936.tb02134.x. URL https://onlinelibrary.wiley. com/doi/abs/10.1111/j.1469-1809.1936.tb02134.x
-
[65]
Takayuki Yato and Takahiro Seta. Complexity and completeness of finding another solution and its application to puzzles.IEICE TRANSACTIONS on Fundamentals, E86-A(5):1052–1060, May 2003
work page 2003
-
[66]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics.arXiv preprint arXiv:2109.00110, 2021. A Implementation Details This appendix records the implementation choices needed to reproduce the generation and evaluation contract. Generation.For pysms graph problems we solve with PySAT/Cad...
-
[67]
Whether the problem is satisfiable (SAT) or unsatisfiable (UNSAT)
-
[68]
If satisfiable, provide a valid solution Respond with a JSON object in the following format: { "satisfiable": true/false, "solution": [list of values] or null if unsatisfiable, "reasoning": "Brief explanation of your reasoning" } Important: - For satisfiability, true means a solution exists, false means it’s mathematically impossible - Solutions should be...
work page 2026
-
[69]
(idempotent diagonal) - x[ x[i][j] ][ x[j][i] ] = i for all i, j in [0, 5) (QG3) The third constraint involves nested indexing (the indices themselves are values from x). For n in [5, 12], few solutions exist and search is non-trivial. Return the grid as a flat list of 25 integers in row-major order (cell (i,j) at index i*5+j), or state "UNSATISFIABLE". I...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.