Recognition: unknown
MathDuels: Evaluating LLMs as Problem Posers and Solvers
Pith reviewed 2026-05-09 21:23 UTC · model grok-4.3
The pith
Models that create math problems for others show skills only partly aligned with those who solve them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
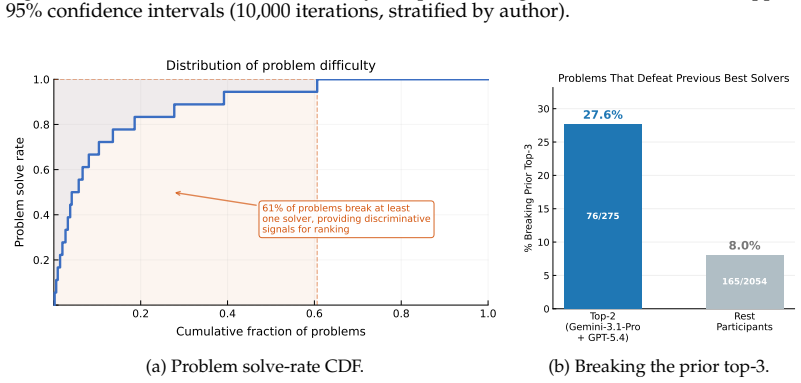
MathDuels lets each model author problems via meta-prompting, generation, and difficulty amplification, then solve every other model's problems after an independent verifier removes ill-posed items. A Rasch model estimates solver ability and problem difficulty from the outcomes while author quality is taken from the difficulties of the problems each model produced. Experiments with 19 frontier models show authoring and solving abilities are only partially coupled, and the dual-role format reveals capability separations that single-role solver benchmarks do not detect. Newer models generate problems that defeat earlier leaders, so the benchmark's overall difficulty grows with participant pool
What carries the argument
The self-play arena in which models simultaneously author and solve problems, scored jointly by a Rasch model that derives solver ability and problem difficulty from win rates across the generated set.
If this is right
- Dual-role evaluation separates capabilities that remain hidden when models are tested only as solvers of fixed sets.
- Author quality can be measured directly by the difficulty level of the problems each model generates.
- Benchmark difficulty co-evolves with the strength of participating models instead of saturating at a fixed ceiling.
- A public leaderboard can track progress as new models are added without requiring new static problem sets.
Where Pith is reading between the lines
- Separate training objectives or data mixtures may be needed to improve problem creation independently of solution accuracy.
- The same dual-role structure could be tested in non-math domains such as code or scientific hypothesis generation.
- Capability splits observed here suggest that aggregate benchmark scores may mask distinct generative and analytical strengths.
Load-bearing premise
The three-stage automated pipeline plus independent verifier produces problems that test genuine authoring and solving skill without artifacts introduced by the generation process itself.
What would settle it
If replacing the automated problem generator with human-authored problems of matched difficulty eliminates the observed partial decoupling between authoring and solving scores, the central claim would not hold.
Figures


read the original abstract
As frontier language models attain near-ceiling performance on static mathematical benchmarks, existing evaluations are increasingly unable to differentiate model capabilities, largely because they cast models solely as solvers of fixed problem sets. We introduce MathDuels, a self-play benchmark in which models occupy dual roles: each authors math problems under adversarial prompting and solves problems authored by every other participant. Problems are produced through a three-stage generation pipeline (meta-prompting, problem generation, and difficulty amplification), and validated by an independent verifier that excludes ill-posed questions. A Rasch model (Rasch, 1993) jointly estimates solver abilities and problem difficulties; author quality is derived from the difficulties of each model's authored problems. Experiments across 19 frontier models reveal that authoring and solving capabilities are partially decoupled, and that dual-role evaluation reveals capability separations invisible in single-role benchmarks. As newer models enter the arena, they produce problems that defeat previously dominant solvers, so the benchmark's difficulty co-evolves with participant strength rather than saturating at a fixed ceiling. We host a public leaderboard that updates as new models are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MathDuels, a self-play benchmark in which 19 frontier LLMs act as both problem authors (via a three-stage pipeline of meta-prompting, generation, and difficulty amplification, followed by independent verification) and solvers. A Rasch model jointly estimates solver abilities and problem difficulties from the resulting data; author quality is derived from the difficulties of each model's generated problems. Experiments show partial decoupling between authoring and solving capabilities, with dual-role evaluation exposing separations invisible in single-role benchmarks, and benchmark difficulty co-evolving as new models enter.
Significance. If the results hold after validation, this would be a significant contribution by providing a dynamic, adversarial evaluation framework that avoids saturation of static math benchmarks. The demonstration of decoupled capabilities and the public, updating leaderboard offer a practical advance for tracking LLM progress in both posing and solving. The Rasch-based joint estimation is a methodological strength when properly validated.
major comments (3)
- [Abstract and §3] Abstract and §3 (Generation Pipeline): The three-stage pipeline (meta-prompting, problem generation, difficulty amplification) plus independent verifier is presented as producing valid problems, but no details are given on validation results, error analysis, or checks for distributional biases (e.g., model-specific algebraic forms or proof styles) that could confound cross-model solving performance and the observed decoupling.
- [§4] §4 (Rasch Model): The Rasch model jointly estimates solver abilities and problem difficulties from the same self-play data, with author quality derived directly from the fitted difficulties. This creates a circular dependence; the manuscript must demonstrate that the partial decoupling is robust to this (e.g., via hold-out validation, simulation studies, or independent difficulty anchors) rather than an artifact of the joint fitting.
- [§5] §5 (Experiments): The central claim that dual-role evaluation reveals capability separations invisible in single-role benchmarks rests on the assumption that generated problems are unbiased measures. Without reported checks for pipeline artifacts or sensitivity analyses (e.g., varying the amplification stage), the decoupling result cannot be confidently attributed to genuine capability differences.
minor comments (2)
- [§4] Notation for the Rasch model parameters (e.g., ability and difficulty parameters) should be defined explicitly on first use with a clear equation reference.
- Figure legends and tables would benefit from explicit error bars or confidence intervals on ability/difficulty estimates and from listing the exact 19 models evaluated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the validation and robustness of our claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Generation Pipeline): The three-stage pipeline (meta-prompting, problem generation, difficulty amplification) plus independent verifier is presented as producing valid problems, but no details are given on validation results, error analysis, or checks for distributional biases (e.g., model-specific algebraic forms or proof styles) that could confound cross-model solving performance and the observed decoupling.
Authors: We agree that the current manuscript provides insufficient detail on pipeline validation. In the revised version, we will add a dedicated subsection in §3 reporting: (i) quantitative validation results (e.g., rejection rates by the independent verifier and inter-verifier agreement), (ii) an error analysis categorizing rejected problems, and (iii) distributional checks comparing algebraic forms, proof styles, and topic distributions across authoring models. These additions will allow readers to assess potential confounds and strengthen the attribution of decoupling to genuine capability differences. revision: yes
-
Referee: [§4] §4 (Rasch Model): The Rasch model jointly estimates solver abilities and problem difficulties from the same self-play data, with author quality derived directly from the fitted difficulties. This creates a circular dependence; the manuscript must demonstrate that the partial decoupling is robust to this (e.g., via hold-out validation, simulation studies, or independent difficulty anchors) rather than an artifact of the joint fitting.
Authors: The concern about circularity in the joint Rasch estimation is valid and merits explicit validation. We will revise §4 to include: (a) a hold-out experiment where the model is fit on 70% of the solver-problem matrix and evaluated on the remaining 30% for ability/difficulty recovery, and (b) simulation studies in which synthetic abilities and difficulties are generated with known partial decoupling, then recovered via the same pipeline to quantify bias. These analyses will be reported with quantitative metrics (e.g., correlation between true and recovered decoupling). We do not currently have independent external difficulty anchors, but the proposed internal validations address the core robustness question. revision: yes
-
Referee: [§5] §5 (Experiments): The central claim that dual-role evaluation reveals capability separations invisible in single-role benchmarks rests on the assumption that generated problems are unbiased measures. Without reported checks for pipeline artifacts or sensitivity analyses (e.g., varying the amplification stage), the decoupling result cannot be confidently attributed to genuine capability differences.
Authors: We acknowledge that the decoupling results in §5 would be more convincing with explicit sensitivity checks. In the revision, we will add analyses that: (i) vary the difficulty-amplification parameters (e.g., number of amplification rounds and target difficulty thresholds) and re-compute the authoring-solving correlation, and (ii) test for pipeline artifacts by comparing problem features (length, operator distribution, proof depth) across models and correlating them with solver performance. If these checks show the decoupling persists, we will report them as supporting evidence; otherwise, we will qualify the claim accordingly. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core empirical claim—that authoring and solving capabilities are partially decoupled—arises from fitting a standard external Rasch model (cited to Rasch 1993) to self-play response data, then defining author quality as the estimated difficulties of problems each model authored. This is a conventional joint estimation in item response theory and does not reduce any result to its inputs by construction, nor does it rename a fitted parameter as an independent prediction. No self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems appear in the abstract or described pipeline. The three-stage generation process and verifier are methodological choices whose potential artifacts affect validity rather than creating definitional equivalence in the reported decoupling. The benchmark co-evolves with new models by design, but this is an explicit feature, not a hidden circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MathConstraint: Automated Generation of Verified Combinatorial Reasoning Instances for LLMs
MathConstraint generates scalable, automatically verifiable combinatorial problems where LLMs achieve 18.5-66.9% accuracy without tools but roughly double that with solver access.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Hynek Kydlíček , title =. 2025 , howpublished =
2025
-
[2]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review arXiv
-
[3]
Update to
OpenAI , institution =. Update to. 2025 , month = dec, url =
2025
-
[4]
2026 , month = mar, url =
OpenAI , institution =. 2026 , month = mar, url =
2026
-
[5]
Introducing
OpenAI , year =. Introducing
-
[6]
2026 , month = feb, url =
Gemini 3.1. 2026 , month = feb, url =
2026
-
[7]
2025 , month = dec, url =
Introducing. 2025 , month = dec, url =
2025
-
[8]
Anthropic , institution =. Claude. 2026 , month = feb, url =
2026
-
[9]
2025 , month = nov, url =
Grok 4.1 Fast Model Card , author =. 2025 , month = nov, url =
2025
-
[10]
2026 , month = feb, url =
Grok 4.20 , author =. 2026 , month = feb, url =
2026
-
[11]
2026 , month = feb, url =
2026
-
[12]
Kimi K2.5: Visual Agentic Intelligence
Kimi. arXiv preprint arXiv:2602.02276 , year =. 2602.02276 , url =
work page internal anchor Pith review arXiv
-
[13]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
arXiv preprint arXiv:2512.02556 , year =. 2512.02556 , url =
work page internal anchor Pith review arXiv
-
[14]
GLM-5: from Vibe Coding to Agentic Engineering
arXiv preprint arXiv:2602.15763 , year =. 2602.15763 , url =
work page internal anchor Pith review arXiv
-
[15]
2026 , month = mar, url =
2026
-
[16]
Step 3.5 flash: Open frontier-level intelligence with 11b active parameters
Step 3.5 Flash: Open Frontier-Level Intelligence with. arXiv preprint arXiv:2602.10604 , year =. 2602.10604 , url =
-
[17]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[18]
, author=
Probabilistic models for some intelligence and attainment tests. , author=. 1993 , publisher=
1993
-
[19]
ICLR , year=
AutoCode: LLMs as Problem Setters for Competitive Programming , author=. ICLR , year=
-
[20]
NeurIPS Datasets and Benchmarks , year=
Livecodebench pro: How do olympiad medalists judge llms in competitive programming? , author=. NeurIPS Datasets and Benchmarks , year=
-
[21]
ICLR , year=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. ICLR , year=
-
[22]
ACL , year=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. ACL , year=
-
[23]
Leveraging online olympiad-level math problems for llms training and contamination-resistant evaluation , author=. arXiv preprint arXiv:2501.14275 , year=
-
[24]
EMNLP , year=
VarBench: Robust language model benchmarking through dynamic variable perturbation , author=. EMNLP , year=
-
[25]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models , author=. arXiv preprint arXiv:2503.21380 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
ICLR , year=
Livebench: A challenging, contamination-limited llm benchmark , author=. ICLR , year=
-
[27]
ICLR , year=
Omni-math: A universal olympiad level mathematic benchmark for large language models , author=. ICLR , year=
-
[28]
ICML , year=
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations , author=. ICML , year=
-
[29]
ICLR , year=
Hardmath: A benchmark dataset for challenging problems in applied mathematics , author=. ICLR , year=
-
[30]
NeurIPS Datasets and Benchmark , year=
Matharena: Evaluating llms on uncontaminated math competitions , author=. NeurIPS Datasets and Benchmark , year=
-
[31]
ICML , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. ICML , year=
-
[32]
2020 , publisher=
The secret formula: how a mathematical duel inflamed renaissance Italy and uncovered the cubic equation , author=. 2020 , publisher=
2020
-
[33]
NeurIPS , year=
Attention is all you need , author=. NeurIPS , year=
-
[34]
NeurIPS Datasets and Benchmark , year=
Measuring mathematical problem solving with the math dataset , author=. NeurIPS Datasets and Benchmark , year=
-
[35]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
NeurIPS , year=
Solving quantitative reasoning problems with language models , author=. NeurIPS , year=
-
[37]
ICLR , year=
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. ICLR , year=
-
[38]
COLM , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. COLM , year=
-
[39]
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai , author=. arXiv preprint arXiv:2411.04872 , year=
-
[40]
ACL , year=
Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark , author=. ACL , year=
-
[41]
NeurIPS , year=
Mathematical capabilities of chatgpt , author=. NeurIPS , year=
-
[42]
EMNLP , year=
Lila: A unified benchmark for mathematical reasoning , author=. EMNLP , year=
-
[43]
NeurIPS , year=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. NeurIPS , year=
-
[44]
ICML , year=
From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline , author=. ICML , year=
-
[45]
Alpacaeval: An automatic evaluator of instruction-following models , author=
-
[46]
ICLR , year=
Judgebench: A benchmark for evaluating llm-based judges , author=. ICLR , year=
-
[47]
NAACL , year=
Dynabench: Rethinking benchmarking in NLP , author=. NAACL , year=
-
[48]
ACL , year=
Adversarial NLI: A new benchmark for natural language understanding , author=. ACL , year=
-
[49]
ICLR , year=
Dyval: Dynamic evaluation of large language models for reasoning tasks , author=. ICLR , year=
-
[50]
EMNLP , year=
Red teaming language models with language models , author=. EMNLP , year=
-
[51]
Science , year=
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play , author=. Science , year=
-
[52]
ICML , year=
Self-play fine-tuning converts weak language models to strong language models , author=. ICML , year=
-
[53]
AI safety via debate , author=. arXiv preprint arXiv:1805.00899 , year=
work page internal anchor Pith review arXiv
-
[54]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
ICML , year=
Debating with more persuasive llms leads to more truthful answers , author=. ICML , year=
-
[56]
ICLR , year=
Metamath: Bootstrap your own mathematical questions for large language models , author=. ICLR , year=
-
[57]
ICLR , year=
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct , author=. ICLR , year=
-
[58]
ICLR , year=
Mammoth: Building math generalist models through hybrid instruction tuning , author=. ICLR , year=
-
[59]
NeurIPS Datasets and Benchmark , year=
Openmathinstruct-1: A 1.8 million math instruction tuning dataset , author=. NeurIPS Datasets and Benchmark , year=
-
[60]
AAAI , year=
Key-point-driven data synthesis with its enhancement on mathematical reasoning , author=. AAAI , year=
-
[61]
ICLR , year=
Let's verify step by step , author=. ICLR , year=
-
[62]
ICLR , year=
Llemma: An open language model for mathematics , author=. ICLR , year=
-
[63]
ICLR , year=
Draft, sketch, and prove: Guiding formal theorem provers with informal proofs , author=. ICLR , year=
-
[64]
NeurIPS , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. NeurIPS , year=
-
[65]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.