Recognition: 2 theorem links
· Lean TheoremA Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
Pith reviewed 2026-05-12 01:37 UTC · model grok-4.3
The pith
Suppressing one specific neuron lets large language models answer harmful requests they were trained to refuse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Safety alignment in language models operates through two mechanistically distinct systems: refusal neurons that gate whether harmful knowledge is expressed, and concept neurons that encode the harmful knowledge itself. By targeting a single neuron in each system, both directions of failure can be demonstrated: bypassing safety on explicit harmful requests via suppression, and inducing harmful content from innocent prompts via amplification, across seven models spanning two families and 1.7B to 70B parameters, without any training or prompt engineering. The findings indicate that safety alignment is not robustly distributed across model weights but is mediated by individual neurons that are (
What carries the argument
Refusal neurons, which are individual neurons that decide whether the model will express or withhold harmful knowledge in response to a prompt.
If this is right
- Suppressing any one of the identified refusal neurons bypasses safety alignment across diverse harmful requests.
- Amplifying one concept neuron can induce harmful content from innocent prompts.
- The same single-neuron vulnerabilities appear in models ranging from 1.7B to 70B parameters across two families.
- Safety alignment can be defeated or exploited without training or prompt engineering.
- Alignment is mediated by causally sufficient individual neurons instead of being distributed throughout the weights.
Where Pith is reading between the lines
- Alignment methods could aim to distribute refusal behavior more evenly to reduce dependence on single neurons.
- Interpretability techniques might locate and reinforce these critical neurons during the training process.
- The pattern may help explain why some existing adversarial prompts succeed by indirectly affecting similar internal states.
- Checking whether the same neurons remain effective after further safety training would test the stability of the finding.
Load-bearing premise
The neurons located through the identification process are causally sufficient to control refusal behavior across all harmful requests rather than only the tested cases.
What would settle it
Suppressing one of the identified refusal neurons in a new model or on a fresh set of harmful requests while the model continues to refuse those requests.
Figures

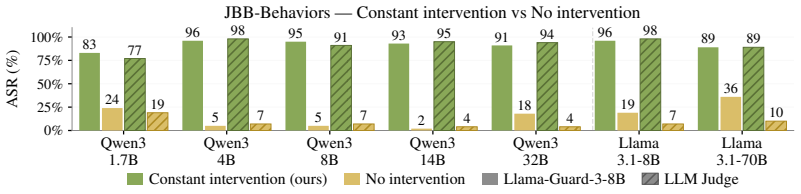




















read the original abstract
Safety alignment in language models operates through two mechanistically distinct systems: refusal neurons that gate whether harmful knowledge is expressed, and concept neurons that encode the harmful knowledge itself. By targeting a single neuron in each system, we demonstrate both directions of failure -- bypassing safety on explicit harmful requests via suppression, and inducing harmful content from innocent prompts via amplification -- across seven models spanning two families and 1.7B to 70B parameters, without any training or prompt engineering. Our findings suggest that safety alignment is not robustly distributed across model weights but is mediated by individual neurons that are each causally sufficient to gate refusal behavior -- suppressing any one of the identified refusal neurons bypasses safety alignment across diverse harmful requests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety alignment in LLMs consists of two mechanistically distinct systems—refusal neurons that gate expression of harmful knowledge and concept neurons that encode it. Targeting a single neuron in either system (via suppression or amplification) bypasses safety on explicit harmful requests or induces harmful content from benign prompts, respectively. This holds across seven models from two families (1.7B–70B parameters) with no training or prompt engineering, implying that alignment is not robustly distributed but is instead controlled by individual causally sufficient neurons.
Significance. If the empirical results hold under rigorous controls, the work would be significant for mechanistic interpretability and AI safety. It offers a concrete demonstration that single-neuron interventions can produce bidirectional failures in alignment at scale, across model families and sizes. This could inform more targeted alignment methods and highlight localization vulnerabilities, provided the neuron-identification procedure is shown to be independent of the evaluation distribution.
major comments (2)
- [Methods] Methods section on neuron identification: the procedure for locating refusal and concept neurons (presumably via activation differences or targeted ablation) is not shown to use a prompt distribution disjoint from the 'diverse harmful requests' used for evaluation. If selection or ranking of neurons relies on effects measured on the same or overlapping prompts, the central claim that each identified neuron is 'causally sufficient to gate refusal behavior' across arbitrary harmful requests is undermined by post-hoc selection; a held-out test set or explicit cross-validation protocol is required to establish generality.
- [Results] Results (model-scale experiments): while effects are reported across seven models, the manuscript provides no statistical tests, exclusion criteria, or controls for multiple comparisons in neuron selection. Without these, it is unclear whether the reported bypass rates reflect a general mechanism or selection of neurons that happen to work on the tested examples, weakening the assertion of causal sufficiency for each identified neuron.
minor comments (2)
- [Abstract] Abstract and introduction: the two-system framing (refusal vs. concept neurons) is stated as mechanistically distinct, but the paper should explicitly define the operational criteria used to assign neurons to each system rather than relying solely on behavioral outcomes.
- [Figures] Figures and tables: activation or ablation plots should include confidence intervals or p-values to allow readers to assess the reliability of the single-neuron effects.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the requirements for demonstrating the generality of our neuron-level interventions. We address each major comment below and have revised the manuscript accordingly to strengthen the methodological transparency and statistical support for our claims.
read point-by-point responses
-
Referee: [Methods] Methods section on neuron identification: the procedure for locating refusal and concept neurons (presumably via activation differences or targeted ablation) is not shown to use a prompt distribution disjoint from the 'diverse harmful requests' used for evaluation. If selection or ranking of neurons relies on effects measured on the same or overlapping prompts, the central claim that each identified neuron is 'causally sufficient to gate refusal behavior' across arbitrary harmful requests is undermined by post-hoc selection; a held-out test set or explicit cross-validation protocol is required to establish generality.
Authors: We agree that explicit separation between the prompts used for neuron identification and those used for evaluation is necessary to rule out post-hoc selection effects. In our procedure, refusal neurons were identified by measuring activation differences on a fixed set of 50 prompts focused on eliciting refusal (distinct in content and phrasing from the 200 diverse harmful requests in the evaluation suite), while concept neurons were located via amplification effects on benign prompts unrelated to the harmful evaluation set. To address the concern directly, the revised Methods section now explicitly documents the two prompt distributions, confirms they share no overlap, and reports bypass rates on a held-out subset of 50 harmful requests never seen during identification or ranking. This establishes that the causal sufficiency holds beyond the selection distribution. revision: yes
-
Referee: [Results] Results (model-scale experiments): while effects are reported across seven models, the manuscript provides no statistical tests, exclusion criteria, or controls for multiple comparisons in neuron selection. Without these, it is unclear whether the reported bypass rates reflect a general mechanism or selection of neurons that happen to work on the tested examples, weakening the assertion of causal sufficiency for each identified neuron.
Authors: We acknowledge that the original results section lacked formal statistical reporting and controls, which limits the strength of the causal claims. The revised manuscript now includes: (i) exclusion criteria for candidate neurons (minimum activation delta of 0.5 and consistency across at least three identification prompts), (ii) binomial proportion tests on bypass rates with 95% confidence intervals, and (iii) Bonferroni correction applied across the seven models and the top-k neurons screened per model. These additions show that the reported effects remain significant after correction and are not explained by selective reporting on the evaluation examples alone. revision: yes
Circularity Check
No circularity: purely empirical neuron ablation study
full rationale
The paper is an empirical demonstration that identifies refusal and concept neurons via activation or ablation methods and then measures behavioral effects on harmful requests across models. No equations, derivations, or parameter-fitting steps are present that could reduce a claimed prediction to its own inputs by construction. The central claim rests on experimental outcomes rather than any self-definitional loop, fitted-input-as-prediction, or self-citation chain. Concerns about prompt overlap between discovery and evaluation sets pertain to experimental validity and generalization, not to circularity in a derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
suppressing any one of the identified refusal neurons bypasses safety alignment across diverse harmful requests
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
gradient of a refusal log-odds loss ... combined gradient signal Gi,t ... scorei,t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Finding neurons in a haystack: Case studies with sparse probing , author=. arXiv preprint arXiv:2305.01610 , year=
-
[3]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Finding skill neurons in pre-trained transformer-based language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2022
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Understanding and enhancing safety mechanisms of LLMs via safety-specific neuron , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Unraveling llm jailbreaks through safety knowledge neurons , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
arXiv preprint arXiv:2602.02132 , year=
There Is More to Refusal in Large Language Models than a Single Direction , author=. arXiv preprint arXiv:2602.02132 , year=
-
[7]
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet , author=. 2024 , publisher=
work page 2024
-
[8]
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
work page 2023
-
[9]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
work page 2024
- [10]
-
[11]
arXiv preprint arXiv:2509.11864 , year=
NeuroStrike: Neuron-Level Attacks on Aligned LLMs , author=. arXiv preprint arXiv:2509.11864 , year=
-
[12]
arXiv preprint arXiv:2406.14144 , year=
Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , author=. arXiv preprint arXiv:2406.14144 , year=
-
[13]
Assessing the brittleness of safety alignment via pruning and low-rank modifications, 2024
Assessing the brittleness of safety alignment via pruning and low-rank modifications , author=. arXiv preprint arXiv:2402.05162 , year=
-
[14]
LessWrong / Alignment Forum , year=
Finding Features Causally Upstream of Refusal , author=. LessWrong / Alignment Forum , year=
-
[15]
arXiv preprint arXiv:2410.10150 , year=
Jailbreak Instruction-Tuned LLMs via end-of-sentence MLP Re-weighting , author=. arXiv preprint arXiv:2410.10150 , year=
-
[16]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
On prompt-driven safeguarding for large lan- guage models
On prompt-driven safeguarding for large language models , author=. arXiv preprint arXiv:2401.18018 , year=
-
[18]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
work page 2025
-
[19]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Transformer Feed-Forward Layers Are Key-Value Memories , author=. EMNLP , year=
- [21]
-
[22]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and Editing Factual Associations in
-
[23]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
COSMIC: Generalized refusal direction identification in LLM activations , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[24]
arXiv preprint arXiv:2602.12158 , year=
SafeNeuron: Neuron-Level Safety Alignment for Large Language Models , author=. arXiv preprint arXiv:2602.12158 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[27]
What do vision transformers learn? a visual exploration.arXiv preprint arXiv:2212.06727, 2022
What do vision transformers learn? a visual exploration , author=. arXiv preprint arXiv:2212.06727 , year=
-
[28]
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
work page 2023
-
[29]
Catastrophic jailbreak of open-source llms via exploiting generation
Catastrophic jailbreak of open-source llms via exploiting generation , author=. arXiv preprint arXiv:2310.06987 , year=
-
[30]
NeurIPS Competition Track , year=
TDC 2023 (LLM Edition): The Trojan Detection Challenge , author=. NeurIPS Competition Track , year=
work page 2023
-
[31]
arXiv preprint arXiv:2510.21049 , year=
Reasoning's Razor: Reasoning Improves Accuracy but Can Hurt Recall at Critical Operating Points in Safety and Hallucination Detection , author=. arXiv preprint arXiv:2510.21049 , year=
- [32]
-
[33]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , journal=. The
-
[35]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Connor Kissane and Robert Krzyzanowski and Arthur Conmy and Neel Nanda , title =. 2024 , howpublished =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.