Recognition: no theorem link
MARLaaS: Multi-Tenant Asynchronous Reinforcement Learning as a Service
Pith reviewed 2026-05-12 01:20 UTC · model grok-4.3
The pith
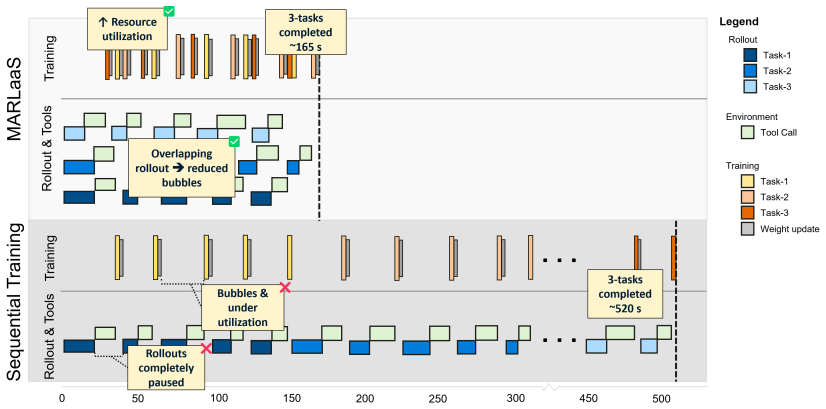
MARLaaS runs up to 32 concurrent RL fine-tuning tasks on LLMs while matching single-task performance and cutting training time by 85 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MARLaaS achieves single-task state-of-the-art performance in multi-task settings with up to 32 concurrent tasks by sharing a base model across tenants using lightweight LoRA adapters and employing a disaggregated asynchronous architecture that decouples rollout generation, environment interaction, and policy training into independently scheduled stages, resulting in up to 4.3x better accelerator utilization and 85% reduction in end-to-end training time.
What carries the argument
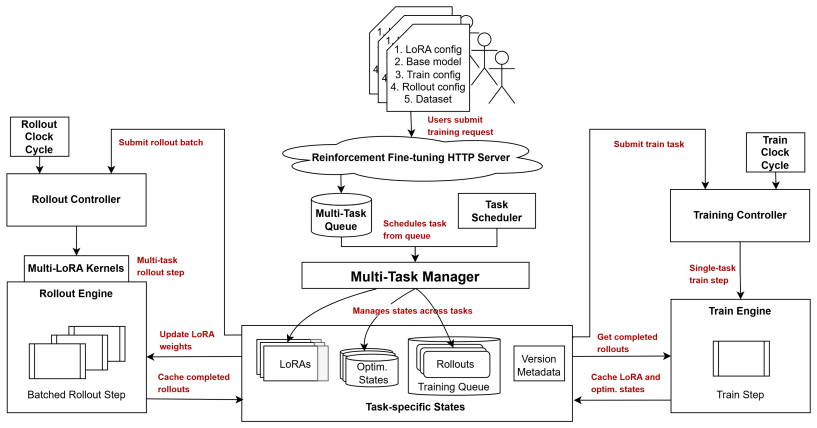
Disaggregated asynchronous architecture that separates rollout generation, environment interaction, and policy training into independently scheduled stages, paired with LoRA adapters for sharing a single base model across tenants.
If this is right
- Each task advances through the RL pipeline at its own pace without blocking others.
- Cross-task interference and accelerator idle time drop because stages run independently.
- Single-task state-of-the-art performance is preserved even when many tasks share the same hardware.
- Accelerator utilization rises by up to 4.3 times in multi-task workloads.
- End-to-end training time for the full set of tasks falls by 85 percent.
Where Pith is reading between the lines
- The same separation of stages could reduce waiting time in other multi-user training setups that mix generation and update work.
- If LoRA adapters continue to isolate tasks well at higher concurrency, the system could support many more simultaneous users without extra hardware.
- The design might extend to other verifiable-reward RL domains beyond language models if environment interactions remain the main bottleneck.
Load-bearing premise
That lightweight LoRA adapters combined with a disaggregated asynchronous pipeline will not introduce meaningful interference, latency in environment interactions, or degradation in RLVR policy quality across tenants.
What would settle it
Running the same 32 tasks sequentially on dedicated single-task instances and comparing final policy quality and total wall-clock time against the multi-tenant MARLaaS run to check whether performance holds or utilization gains vanish.
Figures





read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) has significantly improved the reasoning capabilities of large language models (LLMs), particularly in multi-turn agentic settings involving environment interaction like tool use. However, fine-tuning such models remains prohibitively expensive due to high computational requirements, limiting accessibility. We propose MARLaaS (Multi-tenant Asynchronous RL as a Service), a system for concurrent RL fine-tuning across multiple users and tasks. Our approach is based on two key ideas: (1) sharing a base model across tenants using lightweight LoRA adapters, and (2) a disaggregated asynchronous architecture that decouples rollout generation, environment interaction, and policy training into independently scheduled stages. This design enables tasks to progress through the RL pipeline at their own pace in an event-driven manner, reducing cross-task interference, idle time, and end-to-end latency. In multi-task settings (we report up to 32 concurrent tasks), MARLaaS achieves single-task state-of-the-art performance while improving accelerator utilization by up to 4.3x and reducing end-to-end training time by 85%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MARLaaS, a multi-tenant asynchronous RL-as-a-service system for RLVR fine-tuning of LLMs in agentic settings. It relies on sharing a base model via lightweight per-tenant LoRA adapters and a disaggregated event-driven pipeline that decouples rollout generation, environment interaction, and policy training. The central claim is that this enables up to 32 concurrent tasks while matching single-task SOTA performance, improving accelerator utilization by up to 4.3x, and cutting end-to-end training time by 85%.
Significance. If the empirical results hold, the work could meaningfully improve accessibility of RLVR by raising utilization and lowering latency in shared accelerator environments. The event-driven disaggregation and LoRA-based sharing represent a practical systems contribution for multi-user RL pipelines.
major comments (2)
- [Abstract] Abstract: The claims of 'single-task state-of-the-art performance' in 32-tenant settings, 4.3x utilization improvement, and 85% training-time reduction are asserted without any reference to experimental methodology, baselines, reward curves, statistical significance, or error bars. This absence directly undermines evaluation of the central performance result.
- [Architecture description] Architecture description (disaggregated pipeline): The design assumes that decoupling rollout generation from policy updates and using per-tenant LoRA adapters will introduce no measurable interference, policy-version lag, or shift in verifiable-reward trajectory distributions. No quantitative controls (e.g., policy divergence metrics, per-task reward histograms, or effective batch statistics) are reported to verify preservation of RLVR dynamics under asynchrony.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the evaluation setup (number of tasks, hardware, baselines) to allow readers to contextualize the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve the presentation of our evaluation methodology and validation of the architecture.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'single-task state-of-the-art performance' in 32-tenant settings, 4.3x utilization improvement, and 85% training-time reduction are asserted without any reference to experimental methodology, baselines, reward curves, statistical significance, or error bars. This absence directly undermines evaluation of the central performance result.
Authors: We agree that the abstract's brevity leaves the central claims without sufficient methodological context. In the revised manuscript we will update the abstract to briefly reference the evaluation methodology (standard RLVR benchmarks, single-task baselines, and that full reward curves with error bars and statistical details appear in Section 5), thereby allowing readers to assess the claims more readily while respecting abstract length limits. revision: yes
-
Referee: [Architecture description] Architecture description (disaggregated pipeline): The design assumes that decoupling rollout generation from policy updates and using per-tenant LoRA adapters will introduce no measurable interference, policy-version lag, or shift in verifiable-reward trajectory distributions. No quantitative controls (e.g., policy divergence metrics, per-task reward histograms, or effective batch statistics) are reported to verify preservation of RLVR dynamics under asynchrony.
Authors: The referee correctly identifies that we did not supply direct quantitative controls to confirm the absence of interference. Although end-to-end performance parity with single-task SOTA provides supporting evidence, we will strengthen the manuscript by adding a dedicated subsection (in both the architecture and experiments sections) that reports policy divergence metrics, per-task reward histograms, and effective batch statistics measured under the asynchronous multi-tenant regime. These metrics will be computed from the existing experimental traces to directly verify preservation of RLVR dynamics. revision: yes
Circularity Check
No circularity: empirical system claims rest on implementation measurements
full rationale
The paper describes a multi-tenant RL system architecture using LoRA adapters and disaggregated asynchronous pipelines, then reports measured outcomes such as 4.3x utilization gains and 85% training time reduction in up to 32 concurrent tasks. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All central claims are externally falsifiable via the implemented system and benchmark comparisons rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey of Reinforcement Learning from Human Feedback , author=. 2024 , eprint=
work page 2024
-
[2]
Efficient rlhf: Reducing the memory usage of ppo
Efficient rlhf: Reducing the memory usage of ppo , author=. arXiv preprint arXiv:2309.00754 , year=
-
[3]
ALTO: Adaptive LoRA Tuning and Orchestration for Heterogeneous LoRA Training Workloads , author=. 2026 , eprint=
work page 2026
-
[4]
tLoRA: Efficient Multi-LoRA Training with Elastic Shared Super-Models , author=. 2026 , eprint=
work page 2026
-
[5]
Proceedings of the Nineteenth European Conference on Computer Systems , pages=
Orion: Interference-aware, fine-grained gpu sharing for ml applications , author=. Proceedings of the Nineteenth European Conference on Computer Systems , pages=
-
[6]
LLM Inference Scheduling: A Survey of Techniques, Frameworks, and Trade-offs , author =. TechRxiv , year =
-
[7]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. 2018 , eprint=
work page 2018
-
[8]
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , year=. HybridFlow: A Flexible and Efficient RLHF Framework , url=. doi:10.1145/3689031.3696075 , booktitle=
-
[9]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel , author=. 2023 , eprint=
work page 2023
- [10]
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[12]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Unleashing Efficient Asynchronous RL Post-Training via Staleness-Constrained Rollout Coordination , author=. 2026 , eprint=
work page 2026
-
[14]
2026 , month = feb, howpublished =
SkyRL Brings Tinker to Your GPUs , author =. 2026 , month = feb, howpublished =
work page 2026
-
[15]
SLO-Aware Scheduling for Large Language Model Inferences , author=. 2025 , eprint=
work page 2025
-
[16]
Deep reinforcement learning from human preferences , author=. 2023 , eprint=
work page 2023
- [17]
-
[18]
22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) , year =
Yinmin Zhong and Zili Zhang and Bingyang Wu and Shengyu Liu and Yukun Chen and Changyi Wan and Hanpeng Hu and Lei Xia and Ranchen Ming and Yibo Zhu and Xin Jin , title =. 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) , year =
-
[19]
RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training , author=. 2025 , eprint=
work page 2025
-
[20]
Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models , author=. 2025 , eprint=
work page 2025
-
[21]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
work page 2024
- [22]
-
[23]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. 2022 , eprint=
work page 2022
- [24]
-
[25]
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
work page 2023
-
[26]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
work page 2025
-
[27]
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
work page 2022
-
[28]
Aladdin: Joint Placement and Scaling for SLO-Aware LLM Serving , author=. 2024 , eprint=
work page 2024
-
[29]
2022 USENIX Annual Technical Conference (USENIX ATC 22) , pages=
Serving heterogeneous machine learning models on \ Multi-GPU \ servers with \ Spatio-Temporal \ sharing , author=. 2022 USENIX Annual Technical Conference (USENIX ATC 22) , pages=
work page 2022
-
[30]
ElasticMoE: An Efficient Auto Scaling Method for Mixture-of-Experts Models , author=. 2025 , eprint=
work page 2025
-
[31]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning , author=. 2025 , eprint=
work page 2025
-
[32]
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Training , author=. 2025 , eprint=
work page 2025
-
[33]
Laminar: A Scalable Asynchronous RL Post-Training Framework , author=. 2025 , eprint=
work page 2025
- [34]
-
[35]
S-LoRA: Serving Thousands of Concurrent LoRA Adapters , author=. 2024 , eprint=
work page 2024
-
[36]
MoA: Heterogeneous Mixture of Adapters for Parameter-Efficient Fine-Tuning of Large Language Models , author=. 2025 , eprint=
work page 2025
-
[37]
mLoRA: Fine-Tuning LoRA Adapters via Highly-Efficient Pipeline Parallelism in Multiple GPUs , author=. 2024 , eprint=
work page 2024
-
[38]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[39]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[40]
M. J. Kearns , title =
-
[41]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[42]
Agentic Reasoning: A Streamlined Framework for Enhancing LLM Reasoning with Agentic Tools , author=. 2025 , eprint=
work page 2025
-
[43]
LobRA: Multi-Tenant Fine-Tuning over Heterogeneous Data , volume=
Lin, Sheng and Fu, Fangcheng and Li, Haoyang and Ge, Hao and Wang, Xuanyu and Niu, Jiawen and Tu, Yaofeng and Cui, Bin , year=. LobRA: Multi-Tenant Fine-Tuning over Heterogeneous Data , volume=. Proceedings of the VLDB Endowment , publisher=. doi:10.14778/3742728.3742752 , number=
- [44]
-
[45]
SkyRL-Agent: Efficient RL Training for Multi-turn LLM Agent , author=. 2025 , eprint=
work page 2025
-
[46]
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. 2023 , eprint=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.