Recognition: no theorem link
Probing the Impact of Scale on Data-Efficient, Generalist Transformer World Models for Atari
Pith reviewed 2026-05-12 00:59 UTC · model grok-4.3
The pith
Joint training on 26 Atari environments stabilizes scaling in a transformer world model, producing monotonic fidelity gains and downstream policies with a 0.770 median normalized score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
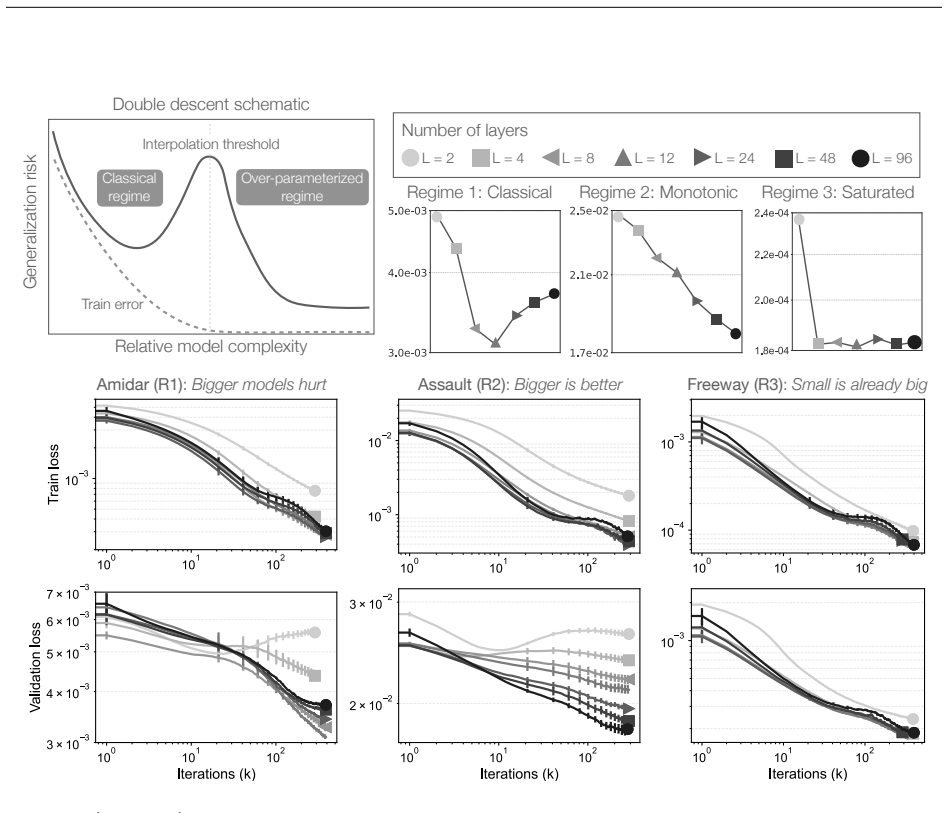
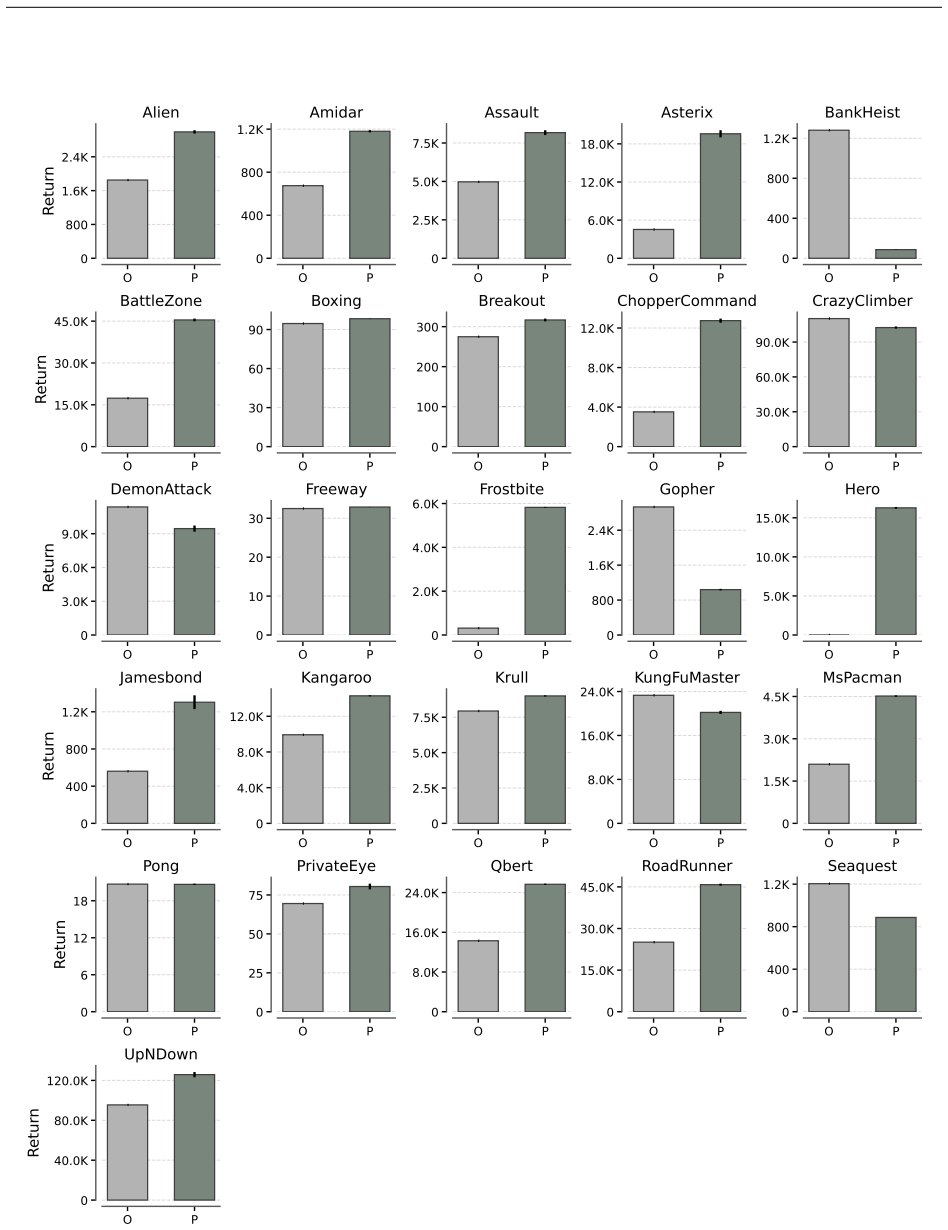
Environments fall into distinct scaling regimes even under identical offline data and model capacity: some allow models to pass the interpolation threshold and show monotonic improvements in the overparameterized regime, while others remain in the classical regime where larger models reduce fidelity. In the unified setting a single transformer trained jointly on the full suite of 26 environments stabilizes these dynamics and delivers monotonic gains across every environment regardless of its individual regime. Improved world-model fidelity translates directly to control, with policies learned entirely inside the simulated dynamics attaining a median expert-random-normalized score of 0.770.
What carries the argument
The minimalist transformer world model under joint versus per-environment training, which exposes and then removes environment-specific scaling regimes.
If this is right
- Individual environments exhibit fundamentally different scaling behaviors under the same data budget and model family.
- Joint training across environments removes per-task scaling differences and guarantees consistent improvement with added scale.
- Higher world-model accuracy obtained through joint training produces stronger control policies when those policies are trained entirely in simulation.
- Progress toward data-efficient generalist systems requires attention to scaling and training regime choices in addition to architectural changes.
Where Pith is reading between the lines
- The stabilization effect may extend to other multi-task settings where shared training data can override single-task scaling ceilings.
- Future experiments could test whether the same joint-training benefit appears when the world model is updated online rather than trained on fixed expert traces.
- The result suggests that generalist world models may reduce the need for environment-specific hyperparameter tuning around model size.
Load-bearing premise
The fixed offline datasets collected from a single expert policy supply an unbiased and complete picture of each environment's dynamics without interference from online interaction or policy-dependent sampling.
What would settle it
Repeating the scaling curves after replacing the expert-derived datasets with data collected from a different or weaker policy and checking whether the joint-training stabilization and monotonic gains survive.
Figures












read the original abstract
Developing generalist systems that retain human-like data efficiency is a central challenge. While world models (WMs) offer a promising path, existing research often conflates architectural mechanisms with the independent impact of model \emph{scale}. In this work, we use a minimalist transformer world model to analyze scaling behaviors on the Atari 100k benchmark, using fixed offline datasets derived from a presupposed expert policy. Our results reveal that environments fundamentally fall into distinct scaling regimes, even when constrained by identical offline data budgets and model capacities. For individual tasks, some environments naturally allow models to pass the interpolation threshold, yielding monotonic improvements in the overparameterized regime, while others remain trapped in the classical regime, where larger world models degrade fidelity. In the unified setting, i.e., a single transformer trained on a suite of 26 Atari environments, we uncover that joint training stabilizes scaling dynamics, ensuring monotonic gains across all environments, regardless of their distinct inherent scaling regimes. Finally, we demonstrate that improved fidelity translates directly to downstream control, with policies learned entirely within the simulated dynamics achieving a median expert-random-normalized score of 0.770. Our findings suggest that future progress lies as much in precise scaling strategies as in architectural innovation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that individual Atari environments exhibit distinct scaling regimes for a minimalist transformer world model trained on fixed offline expert datasets under identical data budgets, with some environments showing monotonic fidelity gains in the overparameterized regime and others degrading in the classical regime. It further claims that joint training of a single transformer on the union of 26 Atari environments stabilizes scaling dynamics to produce monotonic gains across all environments regardless of their individual regimes, and that the resulting higher-fidelity world models enable downstream policies achieving a median expert-random-normalized score of 0.770.
Significance. If the stabilization from joint training holds after addressing data-volume confounds and includes statistical validation, the results would be significant for scaling laws in generalist world models and data-efficient RL, indicating that multi-task training can mitigate regime-specific overfitting issues and support progress toward generalist agents.
major comments (2)
- [Abstract and unified setting experiments] Abstract (unified setting claim): the assertion that joint training 'stabilizes scaling dynamics, ensuring monotonic gains across all environments, regardless of their distinct inherent scaling regimes' is load-bearing but threatened by the absence of any control for total training tokens, epochs, or gradient steps; the multi-task model is trained on the union of all 26 datasets and therefore sees substantially more environment transitions than any single-task run, which could produce the observed monotonicity through reduced overfitting on a larger corpus rather than cross-environment interaction.
- [Experimental setup and results] Experimental details (regime classification and evaluation): the abstract reports distinct scaling regimes and downstream control results but provides no information on statistical significance, error bars or run-to-run variance, exact model architectures, hyperparameter selection, or the criteria used to classify environments into scaling regimes, which undermines assessment of whether the post-hoc regime assignments and fidelity-to-control translation are robust.
minor comments (2)
- [Abstract] The median normalized score of 0.770 is reported without direct comparison to single-task world-model baselines or prior methods, limiting interpretation of the downstream control improvement.
- [Introduction and abstract] Clarify notation for 'interpolation threshold' and 'classical regime' with explicit references to prior scaling literature to aid readers unfamiliar with the terminology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting potential data-volume confounds and the need for greater experimental transparency. We address each major comment below and commit to revisions that strengthen the claims without altering the core findings.
read point-by-point responses
-
Referee: [Abstract and unified setting experiments] Abstract (unified setting claim): the assertion that joint training 'stabilizes scaling dynamics, ensuring monotonic gains across all environments, regardless of their distinct inherent scaling regimes' is load-bearing but threatened by the absence of any control for total training tokens, epochs, or gradient steps; the multi-task model is trained on the union of all 26 datasets and therefore sees substantially more environment transitions than any single-task run, which could produce the observed monotonicity through reduced overfitting on a larger corpus rather than cross-environment interaction.
Authors: We agree this is a valid concern and a potential confound. The unified model inherently processes more total transitions due to the concatenated datasets. To isolate the contribution of cross-environment interactions, we will add a controlled ablation in the revised manuscript: single-task models will be trained with matched total tokens/gradient steps by repeating their fixed offline datasets (with appropriate shuffling) or extending epochs proportionally. We will report scaling curves under these matched budgets and test whether monotonic gains still emerge only under joint training. If the stabilization persists, this will support the cross-environment benefit; otherwise, we will qualify the claims accordingly. We will also update the abstract and discussion to explicitly note the data-volume difference and the new controls. revision: yes
-
Referee: [Experimental setup and results] Experimental details (regime classification and evaluation): the abstract reports distinct scaling regimes and downstream control results but provides no information on statistical significance, error bars or run-to-run variance, exact model architectures, hyperparameter selection, or the criteria used to classify environments into scaling regimes, which undermines assessment of whether the post-hoc regime assignments and fidelity-to-control translation are robust.
Authors: We acknowledge these omissions weaken the current presentation. In the revision we will: (1) report all results with error bars from at least three independent random seeds per configuration, including run-to-run variance; (2) add statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) for key comparisons between scaling regimes and between single- vs. multi-task fidelity; (3) specify the exact transformer architecture (layers, heads, embedding dimension, context length) and all hyperparameters; (4) detail the hyperparameter selection procedure (grid or random search ranges and validation metric); and (5) provide explicit, reproducible criteria for regime classification (e.g., sign of the slope of validation loss vs. model size in the overparameterized regime, with a quantitative threshold). These additions will be placed in a new 'Experimental Details' subsection and the appendix, allowing readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: empirical observations from controlled scaling experiments
full rationale
The paper reports direct empirical measurements of scaling behaviors for a minimalist transformer world model trained on fixed offline Atari 100k datasets derived from expert policies. Claims of distinct per-environment scaling regimes (monotonic vs. classical) and stabilization under joint multi-task training on the union of 26 datasets are presented as observed outcomes of training runs and downstream policy learning, with no mathematical derivation chain, equations, or fitted parameters that reduce predictions to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the experimental design (identical per-task data budgets for single-task baselines) does not create self-definitional loops. The analysis remains self-contained as falsifiable empirical evidence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer architecture can serve as a generalist world model for visual Atari observations
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , doi=
work page 1998
-
[6]
Kingma, Diederik and Welling, Max , booktitle=. Auto-Encoding Variational. 2014 , url=
work page 2014
-
[7]
Stochastic Backpropagation and Approximate Inference in Deep Generative Models , author=. ICML , year=
-
[8]
arXiv preprint arXiv:2308.11079 , year=
Long-Term Prediction of Natural Video Sequences with Robust Video Predictors , author=. arXiv preprint arXiv:2308.11079 , year=
-
[9]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Mastering diverse domains through world models , author=. Nature , volume=. 2023 , doi=
work page 2023
-
[12]
Transformer-based World Models Are Happy With 100k Interactions , author=. ICLR , year=
-
[13]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , author=. arXiv preprint arXiv:1308.3432 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author=. ICLR , year=
-
[15]
Categorical Reparameterization with
Jang, Eric and Gu, Shixiang and Poole, Ben , booktitle=. Categorical Reparameterization with. 2017 , url=
work page 2017
-
[16]
Zhang, Weipu and Wang, Gang and Sun, Jian and Yuan, Yetian and Huang, Gao , booktitle=. 2023 , url=
work page 2023
- [17]
-
[18]
Agarwal, Pranav and Andrews, Sheldon and Kahou, Samira Ebrahimi , booktitle=. Learning to Play. 2024 , url=
work page 2024
- [19]
-
[20]
Hu, Edward and Yang, Qiankun and Lee, Alex and Gurjar, Sachin and Davari, Artur and Garner, Philip and Kwiatkowski, Rowan and McCutcheon, Robert and Bottarel, Fabrizio and Peyton-Jones, Simon and Klein, Bartek and Kendall, Alex and Shahidi, Niels , year=. Wayve Research , note=
-
[21]
Hu, Edward and Yang, Qiankun and Lee, Alex and Davari, Artur and Gurjar, Sachin and Garner, Philip and Kwiatkowski, Rowan and McCutcheon, Robert and Bottarel, Fabrizio and Peyton-Jones, Simon and Klein, Bartek and Kendall, Alex and Shahidi, Niels , year=. Wayve Research , note=
-
[22]
Diffusion for World Modeling: Visual Details Matter in
Eloi Alonso and Adam Jelley and Vincent Micheli and Anssi Kanervisto and Amos Storkey and Tim Pearce and Fran. Diffusion for World Modeling: Visual Details Matter in. NeurIPS , year=
- [23]
-
[24]
arXiv preprint arXiv:1405.4733 , year=
Multiple-environment Markov decision processes , author=. arXiv preprint arXiv:1405.4733 , year=
- [25]
-
[26]
Current Opinion in Behavioral Sciences , volume=
Analogues of mental simulation and imagination in deep learning , author=. Current Opinion in Behavioral Sciences , volume=. 2019 , url=
work page 2019
-
[27]
Artificial Intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial Intelligence , volume=. 1998 , url=
work page 1998
-
[28]
Recurrent world models facilitate policy evolution , author=. NeurIPS , year=
-
[29]
World models , author=. arXiv preprint arXiv:1803.10122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Language Models are Unsupervised Multitask Learners , author=. 2019 , number=
work page 2019
- [31]
- [32]
-
[33]
IEEE Transactions on Systems, Man, and Cybernetics , volume=
Neuronlike adaptive elements that can solve difficult learning control problems , author=. IEEE Transactions on Systems, Man, and Cybernetics , volume=. 1983 , url=
work page 1983
-
[34]
Learning to Predict by the Methods of Temporal Differences , author=. Machine Learning , volume=. 1988 , url=
work page 1988
-
[35]
Transactions on Machine Learning Research , issn=
A Generalist Agent , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[36]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Deep double descent: Where bigger models and more data hurt , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2021 , url=
work page 2021
-
[37]
Recurrent experience replay in distributed reinforcement learning , author=. ICLR , year=
-
[38]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author=. ICML , year=
-
[39]
Generative Modeling by Estimating Gradients of the Data Distribution , author=. NeurIPS , year=
- [40]
-
[41]
Efficient world models with context-aware tokenization , author=. arXiv preprint arXiv:2406.19320 , year=
-
[42]
Backpropagation Applied to Handwritten Zip Code Recognition , author =. Neural Computation , volume =. 1989 , url =
work page 1989
-
[43]
Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning , author=. arXiv preprint arXiv:2402.03570 , year=
-
[44]
Zhang, Weipu and Wang, Gang and Sun, Jian and Yuan, Yetian and Huang, Gao , booktitle=. 2024 , url=
work page 2024
-
[45]
Copilot4D: Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion , author=. ICLR , year=
-
[46]
Ma, Haoyu and Wu, Jialong and Feng, Ningya and Xiao, Chenjun and Li, Dong and Hao, Jianye and Wang, Jianmin and Long, Mingsheng , booktitle=. Harmony. 2024 , url=
work page 2024
-
[47]
Mastering diverse control tasks through world models , author=. Nature , pages=. 2025 , url=
work page 2025
-
[48]
Efficiently Modeling Long Sequences with Structured State Spaces , author=. ICLR , year=
-
[49]
Transdreamer: Reinforcement learning with transformer world models, 2024
Transdreamer: Reinforcement learning with transformer world models , author=. arXiv preprint arXiv:2202.09481 , year=
-
[50]
Facing off World Model Backbones:
Deng, Fei and Park, Junyeong and Ahn, Sungjin , journal=. Facing off World Model Backbones:. 2023 , url=
work page 2023
-
[51]
Action-conditional video prediction using deep networks in
Oh, Junhyuk and Guo, Xiaoxiao and Lee, Honglak and Lewis, Richard and Singh, Satinder , booktitle=. Action-conditional video prediction using deep networks in. 2015 , url=
work page 2015
- [52]
-
[53]
Long Short-Term Memory , author =. Neural Computation , volume =. 1997 , url =
work page 1997
-
[54]
Training Agents Inside of Scalable World Models
Training Agents Inside of Scalable World Models , author=. arXiv preprint arXiv:2509.24527 , year=
work page internal anchor Pith review arXiv
-
[55]
Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion , author=. NeurIPS , year=
- [56]
-
[57]
Stabilizing Transformer Training by Preventing Attention Entropy Collapse , author=. ICML , year=
-
[58]
Which Tasks Should Be Learned Together in Multi-task Learning? , author=. ICML , year=
-
[59]
Transactions on Machine Learning Research , year=
A generalist agent , author=. Transactions on Machine Learning Research , year=
-
[60]
Human-level concept learning through probabilistic program induction , author=. Science , volume=. 2015 , url=
work page 2015
-
[61]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners , author=. ICLR , year=
-
[63]
Bigger, better, faster: Human-level
Schwarzer, Max and Ceron, Johan Samir Obando and Courville, Aaron and Bellemare, Marc and Agarwal, Rishabh and Castro, Pablo Samuel , booktitle=. Bigger, better, faster: Human-level. 2023 , url=
work page 2023
-
[64]
Learning Transformer-based World Models with Contrastive Predictive Coding , author=. ICLR , year=
-
[65]
Scaling Offline Model-Based RL via Jointly-Optimized World-Action Model Pretraining , author=. ICLR , year=
-
[66]
Loss of plasticity in deep continual learning , author=. Nature , volume=. 2024 , url=
work page 2024
-
[67]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
- [68]
- [69]
-
[70]
Tuning large neural networks via zero-shot hyperparameter transfer , author=. NeurIPS , year=
-
[71]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes , author=. ICLR , url=
-
[72]
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
In search of the real inductive bias: On the role of implicit regularization in deep learning , author=. arXiv preprint arXiv:1412.6614 , year=
-
[73]
The implicit bias of gradient descent on separable data , author=. JMLR , volume=. 2018 , url=
work page 2018
-
[74]
Scaling laws in linear regression: Compute, parameters, and data , author=. NeurIPS , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.