Recognition: 2 theorem links
· Lean TheoremPromptDx: Differentiable Prompt Tuning for Multimodal In-Context Alzheimer's Diagnosis
Pith reviewed 2026-05-12 00:59 UTC · model grok-4.3
The pith
A lightweight differentiable adapter lets TabPFN perform multimodal in-context learning for Alzheimer's diagnosis with only 1% of the usual context samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
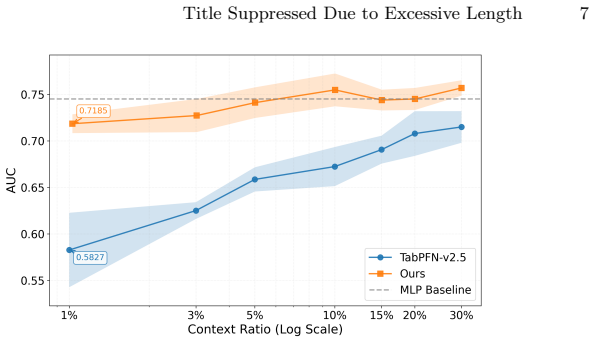
The central claim is that a Differentiable Prompt Tuning mechanism can align a Masked Multimodal Modeling module with a frozen TabPFN engine by using a lightweight adapter as a surrogate for the engine's non-differentiable preprocessing pipeline. Once this alignment is in place, multimodal prompts can be optimized jointly, yielding better Alzheimer's diagnosis on the ADNI dataset with 3D MRI and tabular biomarkers than conventional parametric models and achieving the same performance with only 1% context samples instead of the 30% required by unmodified ICL.
What carries the argument
Differentiable Prompt Tuning (DPT), a lightweight adapter that surrogates TabPFN's non-differentiable preprocessing so multimodal representations can be optimized end-to-end inside the in-context learning loop.
If this is right
- Traditional parametric deep-learning baselines are outperformed on the ADNI Alzheimer's task using 3D MRI plus tabular biomarkers.
- Diagnostic performance holds when context samples are reduced from 30% to 1% of the training pool.
- The same DPT framework transfers to six tabular datasets of varying sizes without retraining the underlying ICL engine.
- Multimodal data can enter an ICL system without gradient fracture or manifold mismatch.
- The overall approach supplies a data-efficient, reference-based alternative to standard supervised medical imaging models.
Where Pith is reading between the lines
- The same adapter pattern could be applied to other non-differentiable ICL engines to incorporate image or text data without full retraining.
- Manifold condensation observed at 1% context size suggests the method may scale to clinical settings where only a handful of reference cases are available.
- Testing the framework on additional neurodegenerative conditions would show whether the gains are specific to Alzheimer's or reflect a broader property of aligned multimodal ICL.
- Combining DPT with larger vision foundation models could enable in-context diagnosis without the computational cost of fine-tuning the entire vision backbone.
Load-bearing premise
A lightweight differentiable adapter can faithfully replace TabPFN's non-differentiable preprocessing steps on heterogeneous multimodal inputs without systematic bias or loss of diagnostic information.
What would settle it
Apply the original non-differentiable TabPFN preprocessing directly to the same multimodal features on the ADNI test set and measure whether diagnostic accuracy remains statistically indistinguishable from the DPT version.
Figures

read the original abstract
Deep learning models in medical imaging typically operate as parametric memory, diagnosing patients by recalling fixed knowledge learned during training. This contrasts sharply with clinical practice, where physicians employ analogical reasoning to diagnose new cases by referencing similar records from past exemplars. While In-Context Learning (ICL) frameworks such as Tabular Prior-Fitted Networks (TabPFN) offer a promising diagnosis-by-reference paradigm, they are designed with tabular-specific inductive priors and rely on non-differentiable preprocessing pipelines, leading to manifold mismatch and gradient fracture when applied to heterogeneous multimodal data. To address these limitations, we propose PromptDx, a novel diagnosis-by-reference framework that leverages a pre-trained TabPFN as an ICL engine while enabling seamless integration with multimodal representations. Our core contribution is a Differentiable Prompt Tuning (DPT) mechanism that aligns a Masked Multimodal Modeling module with the pre-trained ICL engine. By training a lightweight adapter as a differentiable surrogate for the engine's non-differentiable preprocessors, we enable an end-to-end optimization of multimodal prompts within the ICL paradigm. We validate our method on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset using 3D MRI and tabular biomarkers. Experiments demonstrate that our approach outperforms traditional parametric baselines. Notably, our method achieves superior performance using only 1% context samples compared to 30% in standard ICL, demonstrating exceptional manifold condensation ability. We further validate the generalizability of our DPT framework across six tabular datasets with diverse scales. Overall, our method offers a more data-efficient and clinically aligned paradigm for Alzheimer's Disease diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PromptDx, a framework for Alzheimer's diagnosis that repurposes a pre-trained TabPFN as an in-context learning engine for multimodal (3D MRI + tabular) inputs. The core mechanism is Differentiable Prompt Tuning (DPT), which trains a lightweight adapter as a differentiable surrogate for TabPFN's non-differentiable preprocessing pipeline, enabling end-to-end optimization of multimodal prompts. Experiments on the ADNI dataset claim superior performance using only 1% context samples versus 30% for standard ICL, plus generalizability across six tabular datasets.
Significance. If the central claims hold, the work could offer a clinically aligned, data-efficient alternative to parametric memory models in medical imaging by enabling reference-based diagnosis with heterogeneous inputs. The reported 1%-vs-30% data efficiency would be notable if it genuinely arises from manifold condensation within the ICL paradigm rather than adapter-specific fitting.
major comments (2)
- [Differentiable Prompt Tuning mechanism] The central performance and manifold-condensation claims rest on the assumption that the lightweight adapter exactly reproduces the output distribution and inductive priors of TabPFN's non-differentiable preprocessors for heterogeneous multimodal data. No output-matching metrics, distribution-divergence ablations, or gradient-flow analysis are described to confirm fidelity; without these, the reported gains cannot be confidently attributed to unaltered ICL rather than adapter-driven effects.
- [Experiments on ADNI] The abstract states superior performance with 1% context samples on ADNI, yet provides no details on baseline implementations, statistical tests, error bars, or controls that isolate the contribution of the adapter versus the ICL engine. This omission directly undermines evaluation of the data-efficiency claim.
minor comments (1)
- [Generalizability experiments] The abstract mentions validation on six tabular datasets but does not specify which datasets, metrics, or how multimodal aspects were handled in those experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our claims regarding the Differentiable Prompt Tuning mechanism and experimental rigor. We address each point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Differentiable Prompt Tuning mechanism] The central performance and manifold-condensation claims rest on the assumption that the lightweight adapter exactly reproduces the output distribution and inductive priors of TabPFN's non-differentiable preprocessors for heterogeneous multimodal data. No output-matching metrics, distribution-divergence ablations, or gradient-flow analysis are described to confirm fidelity; without these, the reported gains cannot be confidently attributed to unaltered ICL rather than adapter-driven effects.
Authors: We agree that explicit validation of the adapter's fidelity is necessary to attribute gains to the ICL paradigm. The DPT design (Section 3.2) trains the adapter as a differentiable surrogate specifically to preserve TabPFN's inductive priors while enabling gradient flow for multimodal prompts. However, the current manuscript lacks the requested quantitative checks. In revision, we will add: (i) output-matching metrics (e.g., cosine similarity and KL divergence) between adapter-transformed features and TabPFN's original non-differentiable outputs on held-out ADNI samples; (ii) distribution-divergence ablations comparing performance with and without the surrogate; and (iii) a gradient-flow analysis demonstrating absence of fracture. These will clarify whether manifold condensation stems from unaltered ICL or adapter effects. revision: yes
-
Referee: [Experiments on ADNI] The abstract states superior performance with 1% context samples on ADNI, yet provides no details on baseline implementations, statistical tests, error bars, or controls that isolate the contribution of the adapter versus the ICL engine. This omission directly undermines evaluation of the data-efficiency claim.
Authors: The full experimental section (Section 4) reports comparisons against parametric baselines (ResNet/ViT for MRI, MLP for tabular) and standard TabPFN ICL, with the 1%-vs-30% result highlighted. We acknowledge that implementation details, variability measures, and isolating controls are insufficiently explicit. In the revision we will: provide complete baseline adaptation procedures for multimodal inputs; report error bars from multiple random seeds and 5-fold cross-validation; include statistical tests (e.g., paired t-tests or Wilcoxon signed-rank) for the data-efficiency comparison; and add an ablation control that disables differentiability to isolate the adapter's role. These changes will directly support evaluation of the claim. revision: yes
Circularity Check
No significant circularity detected; claims rest on empirical validation.
full rationale
The paper describes a Differentiable Prompt Tuning (DPT) adapter trained to align multimodal representations with a pre-trained TabPFN ICL engine, then reports empirical results on the ADNI dataset (3D MRI + tabular) and six additional tabular datasets showing improved data efficiency. No derivation step equates a reported outcome to its inputs by construction, renames a fitted parameter as an independent prediction, or relies on a self-citation chain for a uniqueness theorem. The adapter training is an explicit part of the proposed method, and performance comparisons are presented against external baselines rather than being forced by the fitting procedure itself. The framework is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBy training a lightweight adapter as a differentiable surrogate for the engine’s non-differentiable preprocessors, we enable an end-to-end optimization of multimodal prompts within the ICL paradigm.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearLalign = 1/|T| Σ ||Aϕ(hi) − ψ_PFN(hi)||1
Reference graph
Works this paper leans on
-
[1]
AI communications7(1), 39–59 (1994)
Aamodt, A., Plaza, E.: Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI communications7(1), 39–59 (1994)
work page 1994
-
[2]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
work page 1901
-
[3]
Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. pp. 785–794 (2016)
work page 2016
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
arXiv preprint arXiv:2003.06505 (2020)
Erickson, N., Mueller, J., Shirkov, A., Zhang, H., Larroy, P., Li, M., Smola, A.: Autogluon-tabular: Robust and accurate automl for structured data. arXiv preprint arXiv:2003.06505 (2020)
-
[6]
Journal of Machine Learning Research 23(120), 1–39 (2022)
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022)
work page 2022
-
[7]
Neuroimage62(2), 774–781 (2012)
Fischl, B.: Freesurfer. Neuroimage62(2), 774–781 (2012)
work page 2012
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022) 10 Authors Suppressed Due to Excessive Length
work page 2022
-
[9]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
work page 2016
-
[10]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
He, Y., Nath, V., Yang, D., Tang, Y., Myronenko, A., Xu, D.: Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d medical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 416–426. Springer (2023)
work page 2023
-
[11]
Nature637(8045), 319–326 (2025)
Hollmann, N., Müller, S., Purucker, L., Krishnakumar, A., Körfer, M., Hoo, S.B., Schirrmeister, R.T., Hutter, F.: Accurate predictions on small data with a tabular foundation model. Nature637(8045), 319–326 (2025)
work page 2025
-
[12]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)
work page 2018
-
[13]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4700–4708 (2017)
work page 2017
-
[14]
Whitwell, J., Ward, C., et al.: The alzheimer’s disease neuroimaging initiative (adni): Mri methods
Jack Jr, C.R., Bernstein, M.A., Fox, N.C., Thompson, P., Alexander, G., Harvey, D., Borowski, B., Britson, P.J., L. Whitwell, J., Ward, C., et al.: The alzheimer’s disease neuroimaging initiative (adni): Mri methods. Journal of Magnetic Reso- nance Imaging: An Official Journal of the International Society for Magnetic Res- onance in Medicine27(4), 685–691 (2008)
work page 2008
-
[15]
arXiv preprint arXiv:2410.07348 (2024)
Jin, P., Zhu, B., Yuan, L., Yan, S.: Moe++: Accelerating mixture-of-experts meth- ods with zero-computation experts. arXiv preprint arXiv:2410.07348 (2024)
-
[16]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 3045–3059 (2021)
work page 2021
-
[17]
Liu, X., Zheng, Y., Du, Z., Ding, M., Qian, Y., Yang, Z., Tang, J.: Gpt understands, too. AI open5, 208–215 (2024)
work page 2024
-
[18]
Neuroimaging Clinics15(4), 869–877 (2005)
Mueller, S.G., Weiner, M.W., Thal, L.J., Petersen, R.C., Jack, C., Jagust, W., Trojanowski, J.Q., Toga, A.W., Beckett, L.: The alzheimer’s disease neuroimaging initiative. Neuroimaging Clinics15(4), 869–877 (2005)
work page 2005
-
[19]
arXiv preprint arXiv:2402.02933 (2024)
Swamy, V., Montariol, S., Blackwell, J., Frej, J., Jaggi, M., Käser, T.: Intrin- sic user-centric interpretability through global mixture of experts. arXiv preprint arXiv:2402.02933 (2024)
-
[20]
In: Pro- ceedingsofthe57thannualmeetingoftheassociationforcomputationallinguistics
Tsai, Y.H.H., Bai, S., Liang, P.P., Kolter, J.Z., Morency, L.P., Salakhutdinov, R.: Multimodal transformer for unaligned multimodal language sequences. In: Pro- ceedingsofthe57thannualmeetingoftheassociationforcomputationallinguistics. pp. 6558–6569 (2019)
work page 2019
-
[21]
arXiv preprint arXiv:2505.19190 (2025)
Xin, J., Yun, S., Peng, J., Choi, I., Ballard, J.L., Chen, T., Long, Q.: I2moe: Interpretable multimodal interaction-aware mixture-of-experts. arXiv preprint arXiv:2505.19190 (2025)
-
[22]
Advances in Neural Information Processing Systems37, 98782–98805 (2024)
Yun, S., Choi, I., Peng, J., Wu, Y., Bao, J., Zhang, Q., Xin, J., Long, Q., Chen, T.: Flex-moe: Modeling arbitrary modality combination via the flexible mixture- of-experts. Advances in Neural Information Processing Systems37, 98782–98805 (2024)
work page 2024
-
[23]
In: International conference on medical image computing and computer-assisted intervention
Zhang, Y., He, N., Yang, J., Li, Y., Wei, D., Huang, Y., Zhang, Y., He, Z., Zheng, Y.: mmformer: Multimodal medical transformer for incomplete multimodal learn- ing of brain tumor segmentation. In: International conference on medical image computing and computer-assisted intervention. pp. 107–117. Springer (2022)
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.