Recognition: no theorem link
Large Language Models over Networks: Collaborative Intelligence under Resource Constraints
Pith reviewed 2026-05-12 01:31 UTC · model grok-4.3
The pith
Multiple independent LLMs can collaborate at the task level across devices and clouds to achieve higher response quality under resource constraints than any single endpoint allows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Collaborative intelligence enables multiple independent LLMs distributed across device and cloud endpoints to work together at the task level through natural language or structured messages, delivering superior response quality while respecting heterogeneous constraints on computation, memory, communication, and cost that no single endpoint can meet alone.
What carries the argument
Collaborative inference structured along vertical device-cloud collaboration and horizontal multi-agent collaboration, which combine into hybrid network topologies.
If this is right
- Applications with sub-second latency budgets or intermittent connectivity become feasible without sacrificing response quality.
- Data-residency rules can be met by keeping sensitive processing on local devices while still using cloud models for difficult subtasks.
- High-volume inference loads can be spread across many endpoints instead of overloading any one device or cloud server.
- Hybrid vertical-plus-horizontal topologies allow flexible scaling as network conditions change.
- Training routing policies and cooperative skills becomes necessary to realize the quality gains in practice.
Where Pith is reading between the lines
- Security and privacy risks may rise when models exchange intermediate reasoning steps in natural language.
- Energy consumption across the whole network could become a new optimization target once message passing is routine.
- Simple two-model device-cloud pairs could serve as an early testbed for measuring actual quality gains versus overhead.
- The same message-passing idea might extend to mixtures of LLMs and smaller specialized models on the same device.
Load-bearing premise
That LLMs can reliably exchange messages to divide tasks and improve quality without adding prohibitive communication overhead, coordination failures, or security risks under realistic resource differences.
What would settle it
A controlled test on a latency-sensitive task showing that message-based collaboration either fails to raise answer quality above the best single model or increases end-to-end latency beyond the single-model baseline.
Figures

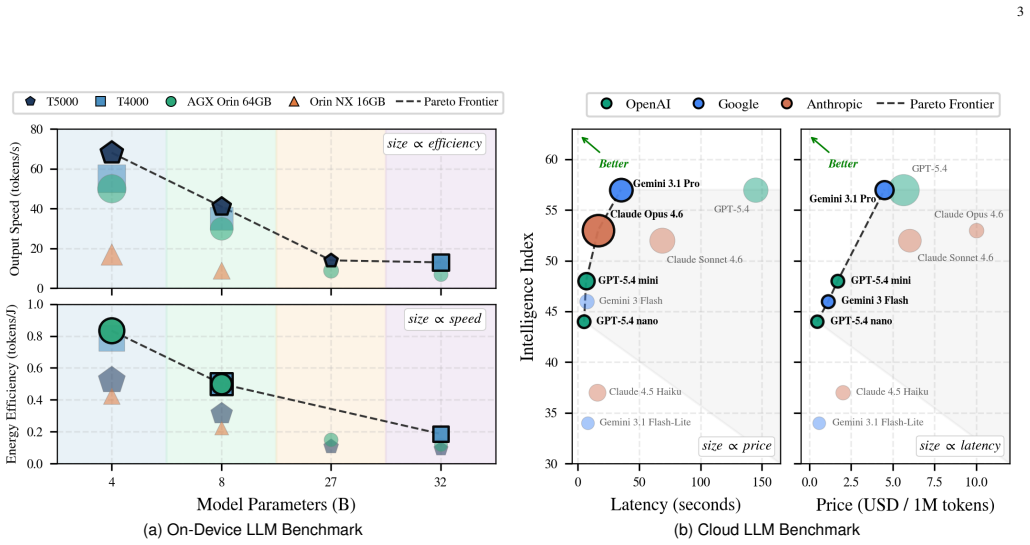


read the original abstract
Large language models (LLMs) are transforming society, powering applications from smartphone assistants to autonomous driving. Yet cloud-based LLM services alone cannot serve a growing class of applications, including those operating under intermittent connectivity, sub-second latency budgets, data-residency constraints, or sustained high-volume inference. On-device deployment is in turn constrained by limited computation and memory. No single endpoint can deliver high-quality service across this spectrum. This article focuses on collaborative intelligence, a paradigm in which multiple independent LLMs distributed across device and cloud endpoints collaborate at the task level through natural language or structured messages. Such collaboration strives for superior response quality under heterogeneous resource constraints spanning computation, memory, communication, and cost across network tiers. We present collaborative inference along two complementary and composable dimensions: vertical device-cloud collaboration and horizontal multi-agent collaboration, which can be combined into hybrid topologies in practice. We then examine learning to collaborate, addressing the training of routing policies and the development of cooperative capabilities among LLMs. Finally, we identify open research challenges including scaling under resource heterogeneity and trustworthy collaborative intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces collaborative intelligence as a paradigm in which multiple independent LLMs distributed across device and cloud endpoints collaborate at the task level via natural language or structured messages. It presents this along two dimensions—vertical device-cloud collaboration and horizontal multi-agent collaboration—that can be combined into hybrid topologies, examines learning to collaborate through routing policies and cooperative capabilities, and identifies open challenges including scaling under resource heterogeneity and trustworthy collaboration. The work is positioned as a conceptual overview rather than an empirical or theoretical derivation.
Significance. If realized, the framework could enable practical LLM deployment in latency-sensitive, connectivity-constrained, or data-residency-restricted settings by leveraging network heterogeneity rather than treating endpoints in isolation. By explicitly cataloging open problems in coordination, trustworthiness, and resource-aware routing, the paper supplies a useful organizing lens for subsequent research in networked AI systems. Its value lies in synthesis and agenda-setting rather than in new algorithms or validated performance gains.
major comments (1)
- [Abstract and § on collaborative inference dimensions] The central claim that collaboration 'strives for superior response quality under heterogeneous resource constraints' (abstract) rests on the unelaborated premise that task-level message exchange can be both effective and low-overhead. No section supplies even a qualitative cost-benefit sketch or reference to existing multi-agent LLM protocols that would make this premise testable; this weakens the motivation for the two-dimensional taxonomy.
minor comments (2)
- [Introduction / paradigm definition] The distinction between 'collaborative inference' and 'collaborative intelligence' is used without explicit definition; a short clarifying paragraph early in the manuscript would prevent reader confusion.
- [Open research challenges] Open challenges are listed at a high level; adding one or two concrete research questions per challenge (e.g., a specific coordination protocol to evaluate) would increase utility for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of the manuscript as a conceptual overview. We address the major comment point by point below and have revised the manuscript to strengthen the motivation for the proposed taxonomy.
read point-by-point responses
-
Referee: [Abstract and § on collaborative inference dimensions] The central claim that collaboration 'strives for superior response quality under heterogeneous resource constraints' (abstract) rests on the unelaborated premise that task-level message exchange can be both effective and low-overhead. No section supplies even a qualitative cost-benefit sketch or reference to existing multi-agent LLM protocols that would make this premise testable; this weakens the motivation for the two-dimensional taxonomy.
Authors: We agree that the original manuscript, positioned as a high-level conceptual overview rather than an empirical study, did not include an explicit qualitative cost-benefit sketch or citations to specific multi-agent protocols within the abstract and dimensions section. This omission could indeed leave the premise less immediately testable. In the revised version, we have added a concise qualitative discussion immediately following the abstract and within the collaborative inference dimensions section. This discussion outlines high-level trade-offs: benefits such as latency reduction by routing simple subtasks to on-device models and complex reasoning to cloud endpoints, versus overheads including communication latency and token costs for natural-language message exchange. We also now cite representative existing multi-agent LLM frameworks (e.g., AutoGen, LangGraph, and device-cloud splitting approaches from recent literature) to ground the premise and illustrate that task-level collaboration is already being explored in practice. These additions preserve the paper's conceptual character while directly addressing the motivation for the vertical-horizontal taxonomy. revision: yes
Circularity Check
No significant circularity
full rationale
This is a conceptual survey paper that defines collaborative intelligence as a paradigm, outlines vertical device-cloud and horizontal multi-agent dimensions, discusses learning to collaborate, and flags open challenges. It contains no equations, fitted parameters, derivations, or self-citations that reduce any claim to the paper's own inputs by construction. The discussion is descriptive and positions reliable task-level collaboration as a direction for future work rather than an asserted result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple independent LLMs can collaborate effectively at the task level through natural language or structured messages to improve response quality under resource constraints.
Reference graph
Works this paper leans on
-
[1]
A Review on Edge Large Language Models: Design, Execution, and Applications,
Y . Zheng, Y . Chen, B. Qian, X. Shi, Y . Shu, and J. Chen, “A Review on Edge Large Language Models: Design, Execution, and Applications,” ACM Computing Surveys, vol. 57, no. 8, pp. 1–35, 2025
work page 2025
-
[2]
Toward Federated Large Language Models: Motivations, Methods, and Future Directions,
Y . Cheng, W. Zhang, Z. Zhang, C. Zhang, S. Wang, and S. Mao, “Toward Federated Large Language Models: Motivations, Methods, and Future Directions,”IEEE Communications Surveys & Tutorials, vol. 27, no. 4, pp. 2733–2764, 2024
work page 2024
-
[3]
Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities,
Z. Lin, G. Qu, Q. Chen, X. Chen, Z. Chen, and K. Huang, “Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities,”IEEE Communications Magazine, vol. 63, no. 9, pp. 52–59, 2025
work page 2025
-
[4]
Mobile Edge Intelligence for Large Language Models: A Contemporary Survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile Edge Intelligence for Large Language Models: A Contemporary Survey,” IEEE Communications Surveys & Tutorials, vol. 27, no. 6, pp. 3820– 3860, 2025
work page 2025
-
[5]
Local-Cloud Infer- ence Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings,
L. Yuan, D.-J. Han, S. Wang, and C. Brinton, “Local-Cloud Infer- ence Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings,” inProceedings of the Twenty-Sixth International Symposium on Theory, Algorithmic F oundations, and Protocol Design for Mobile Networks and Mobile Computing, 2025, pp. 201–210
work page 2025
-
[6]
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 13 358–13 376
work page 2023
-
[7]
H. Luo, Y . Liu, R. Zhang, J. Wang, G. Sun, D. Niyato, H. Yu, Z. Xiong, X. Wang, and X. Shen, “Toward Edge General Intelligence with Multiple-Large Language Model (Multi-LLM): Architecture, Trust, and Orchestration,”IEEE Transactions on Cognitive Communications and Networking, vol. 11, no. 6, pp. 3563–3585, 2025
work page 2025
-
[8]
AutoGen: Enabling Next-Gen LLM Appli- cations via Multi-Agent Conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “AutoGen: Enabling Next-Gen LLM Appli- cations via Multi-Agent Conversation,” inProceedings of the First Conference on Language Modeling, 2024
work page 2024
-
[9]
Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems,
G. Zhang, Y . Yue, Z. Li, S. Yun, G. Wan, K. Wang, D. Cheng, J. X. Yu, and T. Chen, “Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems,” inProceedings of the Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[10]
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing,
D. Ding, A. Mallick, C. Wang, R. Sim, S. Mukherjee, V . Ruhle, L. V . Lakshmanan, and A. H. Awadallah, “Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing,” inProceedings of the Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[11]
W. Fang, D.-J. Han, L. Yuan, E. Chen, and C. Brinton, “Bridging On-Device and Cloud LLMs for Collaborative Reasoning: A Unified Methodology for Local Routing and Post-Training,” inProceedings of the F orty-third International Conference on Machine Learning, 2026
work page 2026
-
[12]
C. Park, S. Han, X. Guo, A. E. Ozdaglar, K. Zhang, and J.-K. Kim, “MAPoRL: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 30 215–30 248
work page 2025
-
[13]
Multi-Agent Collaboration via Evolving Orchestration,
Y . Dang, C. Qian, X. Luo, J. Fan, Z. Xie, R. Shi, W. Chen, C. Yang, X. Che, Y . Tianet al., “Multi-Agent Collaboration via Evolving Orchestration,” inProceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[14]
Im- proving Multi-Agent Debate with Sparse Communication Topology,
Y . Li, Y . Du, J. Zhang, L. Hou, P. Grabowski, Y . Li, and E. Ie, “Im- proving Multi-Agent Debate with Sparse Communication Topology,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 7281–7294
work page 2024
-
[15]
Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System,
W. Chen, J. Yuan, C. Qian, C. Yang, Z. Liu, and M. Sun, “Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 11 534–11 557. Liangqi Yuanis pursuing the Ph.D. degree in ECE with Purdue University. Wenzhi Fangis pursuing the Ph.D. degree in ECE wi...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.