Recognition: no theorem link
The Cancellation Hypothesis in Critic-Free RL: From Outcome Rewards to Token Credits
Pith reviewed 2026-05-12 01:20 UTC · model grok-4.3
The pith
Critic-free RL for language models induces token-level credit assignment by canceling opposing signals on tokens shared across positive and negative rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Token probability changes in critic-free RL are not determined solely by a token's own advantage but also by coupled gradient interactions with identical low-confidence tokens. As a result, opposing signals cancel for tokens shared by positive and negative rollouts, while tokens more specific to successful rollouts receive stronger reinforcement. This mechanism induces hidden token-level credit assignment from rollout-level rewards.
What carries the argument
The cancellation hypothesis, which states that coupling between identical low-confidence tokens causes signal cancellation on shared tokens and net reinforcement on tokens unique to successful rollouts.
Load-bearing premise
Coupled gradient interactions between identical low-confidence tokens are the main driver of the observed token probability changes and value differences.
What would settle it
If shared tokens across positive and negative rollouts showed the same net probability change as tokens unique to successful rollouts, or if boosted tokens did not reliably exhibit higher value than suppressed ones, the cancellation hypothesis would be falsified.
Figures



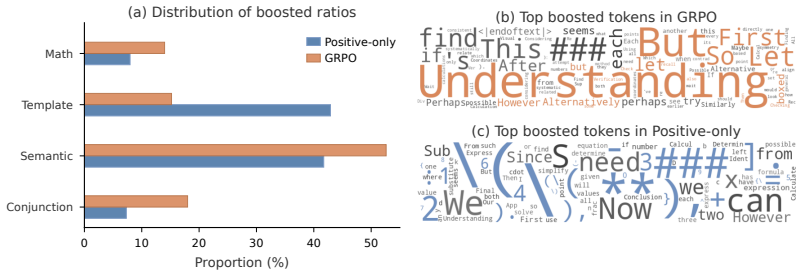
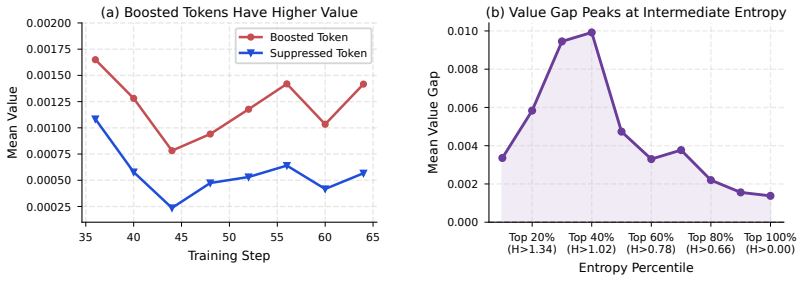


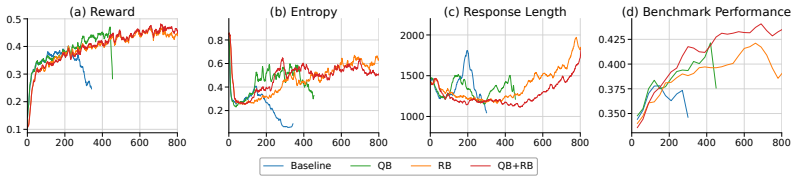



read the original abstract
A commonly accepted explanation of critic-free RL for LLMs, based on sequence-level rewards, is that it reinforces successful rollouts with a positive advantage while penalizing failed ones. In contrast, we study critic-free RL from a token-level perspective, revealing the token-flipping phenomenon: positive and negative rollouts exhibit remarkably similar proportions of tokens whose probabilities are boosted or suppressed during RL training. To explain this phenomenon, we further show that a token's change in probability is not fully determined by its own advantage; coupled gradient interactions with other tokens also play a non-negligible role. Specifically, these token coupling effects occur primarily between identical tokens that are both predicted with low confidence. Building upon this analysis, we propose the cancellation hypothesis: as a result of coupling, opposing signals cancel out for tokens shared by positive and negative rollouts, while tokens more specific to successful rollouts receive stronger reinforcement, thereby inducing hidden token-level credit assignment from rollout-level rewards. We support this hypothesis with complementary empirical evidence. (1) Compared with training on only positive rollouts, critic-free RL shifts updates from template and formatting tokens toward reasoning tokens; (2) Tokens boosted by critic-free RL consistently demonstrate higher value than suppressed tokens, regardless of whether they originate from positive or negative rollouts. Guided by this view, we implement two batching interventions to encourage or preserve cancellation in critic-free RL training: query-preserved mini-batching and reward-balanced batching. Despite their simplicity, these interventions improve RLVR training across multiple model scales, supporting cancellation as both an explanatory principle and a practical design criterion for critic-free RL training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines critic-free RL for LLMs from a token-level view, documenting a token-flipping phenomenon in which positive and negative rollouts show similar fractions of probability-boosted and probability-suppressed tokens. It attributes this to coupled gradient interactions that occur mainly between identical low-confidence tokens, leading to the cancellation hypothesis: opposing signals cancel for tokens shared across rollouts while success-specific tokens receive net reinforcement, thereby inducing implicit token-level credit assignment from sequence-level rewards. Complementary evidence is offered via (1) a shift toward reasoning tokens relative to positive-only training and (2) higher value for boosted versus suppressed tokens regardless of rollout origin; two simple batching interventions (query-preserved mini-batching and reward-balanced batching) are shown to improve RLVR performance across scales.
Significance. If the cancellation mechanism is isolated as the dominant driver, the work supplies a mechanistic account of how rollout-level rewards produce token-level credit assignment without an explicit critic, together with immediately usable batching heuristics that demonstrably improve training. The emphasis on gradient coupling and the empirical interventions constitute a concrete advance over purely sequence-level interpretations of critic-free RL.
major comments (2)
- [Empirical evidence paragraphs (1) and (2)] The central claim that coupled gradient interactions between identical low-confidence tokens are the primary driver of the observed token-flipping and value differences (rather than token-frequency or co-occurrence differences between positive and negative rollouts, or optimizer artifacts) is load-bearing for the cancellation hypothesis yet is not isolated by the reported controls or ablations. The two empirical observations cited in the abstract could arise from distributional imbalances alone.
- [Analysis of token probability changes and hypothesis proposal] No direct quantification or ablation of the magnitude of the claimed coupling effect (e.g., gradient inner products or controlled interventions that hold token frequencies fixed) is provided; without such measurements the hypothesis remains consistent with the data but not uniquely supported by it.
minor comments (2)
- The abstract and introduction would benefit from explicit statements of the model sizes, datasets, and RL algorithm (e.g., GRPO or PPO variant) used in the main experiments.
- [Value comparison experiments] Clarify whether the value comparisons in observation (2) are computed on held-out data or on the same rollouts used for training, and report statistical significance or confidence intervals.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. The comments highlight important points about isolating the coupling mechanism and providing more direct quantification. We respond to each major comment below and outline revisions that will strengthen the evidence for the cancellation hypothesis.
read point-by-point responses
-
Referee: [Empirical evidence paragraphs (1) and (2)] The central claim that coupled gradient interactions between identical low-confidence tokens are the primary driver of the observed token-flipping and value differences (rather than token-frequency or co-occurrence differences between positive and negative rollouts, or optimizer artifacts) is load-bearing for the cancellation hypothesis yet is not isolated by the reported controls or ablations. The two empirical observations cited in the abstract could arise from distributional imbalances alone.
Authors: We agree that isolating the coupling effect from potential distributional factors is important. However, the token-flipping phenomenon—nearly identical fractions of boosted and suppressed tokens in both positive and negative rollouts—is itself difficult to reconcile with frequency or co-occurrence differences alone, as one would otherwise expect systematically higher boosting rates in positive rollouts. Our analysis shows that gradient coupling is strongest precisely for identical low-confidence tokens, offering a mechanism that naturally produces cancellation on shared tokens while preserving net reinforcement on success-specific tokens. The shift toward reasoning tokens (observation 1) and the value advantage of boosted tokens independent of rollout origin (observation 2) are consistent with this view. That said, we acknowledge the need for stronger isolation. In the revised manuscript we will add a frequency-matched ablation that re-computes token-flipping statistics and value differences after controlling for token occurrence rates across positive and negative rollouts. revision: yes
-
Referee: [Analysis of token probability changes and hypothesis proposal] No direct quantification or ablation of the magnitude of the claimed coupling effect (e.g., gradient inner products or controlled interventions that hold token frequencies fixed) is provided; without such measurements the hypothesis remains consistent with the data but not uniquely supported by it.
Authors: We accept that the current version presents the coupling effect through indirect evidence (token-flipping statistics, differential updates relative to positive-only training, and the efficacy of cancellation-preserving batching) rather than direct metrics. The batching interventions function as a practical test by altering the conditions under which cancellation can occur, and their consistent improvements across scales lend support to the hypothesis. To provide the requested direct quantification, the revision will include: (i) measurements of gradient inner products between identical tokens across positive and negative rollouts, stratified by confidence level, and (ii) a controlled intervention that holds token frequencies fixed while varying rollout sign composition. These additions will allow us to report the magnitude of the coupling effect and test whether it accounts for the observed phenomena beyond distributional factors. revision: yes
Circularity Check
No significant circularity in cancellation hypothesis derivation
full rationale
The paper derives the cancellation hypothesis from direct empirical observations of token probability changes and gradient coupling effects in critic-free RL, then validates it through independent comparisons (critic-free vs. positive-only training) and simple batching interventions that measurably improve performance. No equation or claim reduces the hypothesis to a quantity defined in terms of itself, a fitted parameter relabeled as a prediction, or a load-bearing self-citation chain. The supporting evidence consists of external-to-the-hypothesis measurements (token value differences, update shifts toward reasoning tokens) that do not presuppose the cancellation mechanism. The overall chain is therefore self-contained and falsifiable against held-out training runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A token's probability change during RL is not fully determined by its own advantage but is also shaped by coupled gradient interactions with other tokens, especially identical low-confidence predictions.
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review arXiv
-
[2]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review arXiv
-
[3]
Wenlong Deng, Yushu Li, Boying Gong, Yi Ren, Christos Thrampoulidis, and Xiaoxiao Li. On grpo collapse in search-r1: The lazy likelihood-displacement death spiral.arXiv preprint arXiv:2512.04220, 2025a. Wenlong Deng, Yi Ren, Muchen Li, Danica J Sutherland, Xiaoxiao Li, and Christos Thrampoulidis. On the effect of negative gradient in group relative deep r...
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review arXiv
-
[6]
Step 3.5 flash: Open frontier-level intelligence with 11b active parameters
Ailin Huang, Ang Li, Aobo Kong, Bin Wang, Binxing Jiao, Bo Dong, Bojun Wang, Boyu Chen, Brian Li, Buyun Ma, et al. Step 3.5 flash: Open frontier-level intelligence with 11b active parameters. arXiv preprint arXiv:2602.10604,
-
[7]
Zeyu Huang, Tianhao Cheng, Zihan Qiu, Zili Wang, Yinghui Xu, Edoardo M Ponti, and Ivan Titov. Blending supervised and reinforcement fine-tuning with prefix sampling.arXiv preprint arXiv:2507.01679,
-
[8]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models. arXiv preprint arXiv:2310.10505,
-
[11]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Youssef Mroueh. Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639,
-
[13]
Sagnik Mukherjee, Lifan Yuan, Pavan Jayasinha, Dilek Hakkani-Tür, and Hao Peng. Do we need adam? surprisingly strong and sparse reinforcement learning with sgd in llms.arXiv preprint arXiv:2602.07729,
-
[14]
Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive.arXiv preprint arXiv:2402.13228,
-
[15]
Noam Razin, Sadhika Malladi, Adithya Bhaskar, Danqi Chen, Sanjeev Arora, and Boris Hanin. Unintentional unalignment: Likelihood displacement in direct preference optimization.arXiv preprint arXiv:2410.08847,
-
[16]
Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490,
Yi Ren and Danica J Sutherland. Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490,
-
[17]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618,
work page internal anchor Pith review arXiv
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2508.03772 , year=
Marco Simoni, Aleksandar Fontana, Giulio Rossolini, Andrea Saracino, and Paolo Mori. Gtpo: Stabilizing group relative policy optimization via gradient and entropy control.arXiv preprint arXiv:2508.03772,
-
[22]
Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Rethinking sample polarity in reinforcement learning with verifiable rewards. arXiv preprint arXiv:2512.21625,
-
[23]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
11 Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review arXiv
-
[25]
Jianghao Wu, Yasmeen George, Jin Ye, Yicheng Wu, Daniel F Schmidt, and Jianfei Cai. Spine: Token-selective test-time reinforcement learning with entropy-band regularization.arXiv preprint arXiv:2511.17938, 2025a. Yihong Wu, Liheng Ma, Lei Ding, Muzhi Li, Xinyu Wang, Kejia Chen, Zhan Su, Zhanguang Zhang, Chenyang Huang, Yingxue Zhang, et al. It takes two: ...
-
[26]
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. Sim- pletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning.arXiv preprint arXiv:2509.02479,
-
[27]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118,
work page internal anchor Pith review arXiv
-
[29]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review arXiv
-
[30]
arXiv preprint arXiv:2506.03106 , year=
Xiaoying Zhang, Hao Sun, Yipeng Zhang, Kaituo Feng, Chaochao Lu, Chao Yang, and Helen Meng. Critique-grpo: Advancing llm reasoning with natural language and numerical feedback.arXiv preprint arXiv:2506.03106,
-
[31]
First return, entropy-eliciting explore, 2025
Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, et al. First return, entropy-eliciting explore.arXiv preprint arXiv:2507.07017,
-
[32]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning.arXiv preprint arXiv:2506.01347, 2025a. Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025b. GitHub repository....
-
[33]
D.2 Empirical Verification Details for Token coupling and Additional Results For the masked-update experiments reported in Table 1 and Figure 3, we deliberately use SGD with a learning rate of 1e−1 and no momentum rather than Adam. The reason is that Adam’s first parameter update reduces to an approximate sign-descent step (see Appendix D.3 for a formal d...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.