Recognition: no theorem link
PrepBench: How Far Are We from Natural-Language-Driven Data Preparation?
Pith reviewed 2026-05-12 00:57 UTC · model grok-4.3
The pith
State-of-the-art LLMs still struggle to realize natural-language-driven data preparation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PrepBench is a benchmark for evaluating natural language driven data preparation that covers interactive disambiguation, prep code generation and code to workflow translation. Built by crawling and extending Preppin Data Challenges it includes tasks with 3 to 18 steps and up to 300 lines of Python code. The evaluation demonstrates that despite recent progress state of the art LLMs find it challenging to perform these tasks effectively.
What carries the argument
The PrepBench benchmark which tests LLMs on interactive disambiguation, prep-code generation, and code-to-workflow translation for data preparation tasks.
If this is right
- Data preparation workflows may remain dependent on GUI tools until LLMs improve at handling ambiguous intents.
- Long and complex code generation for data prep continues to be a bottleneck for LLM agents.
- Code-to-workflow translation is essential for validation and must be prioritized in future LLM developments.
- The benchmark provides a way to measure progress toward NL-driven data preparation over time.
Where Pith is reading between the lines
- Improving performance on PrepBench could enable more intuitive data analysis tools accessible without programming expertise.
- Similar benchmarks might be developed for other data-intensive tasks like feature engineering or visualization specification.
- The focus on interpretable workflows suggests a need for LLMs to output explanations alongside code in data contexts.
- Testing with real user interactions beyond the benchmark could reveal additional practical limitations.
Load-bearing premise
The tasks constructed by crawling and extending Preppin' Data Challenges accurately represent the key real-world characteristics of natural-language-driven data preparation, including ambiguous intents and the need for interpretable workflows.
What would settle it
An experiment where a state-of-the-art LLM completes the majority of PrepBench tasks with correct disambiguation, accurate code, and valid workflow translations would falsify the claim that the paradigm shift remains challenging.
Figures











read the original abstract
Data preparation is a central and time-consuming stage in data analysis workflows. Traditionally, commercial tools have relied on graphical user interfaces (GUIs) to simplify data preparation, allowing users to define transformations through visual operators and workflows. Recent advances in large language models (LLMs) raise the possibility of a paradigm shift toward natural language (NL)-driven data preparation, in which users can specify preparation intents in NL directly. However, it remains unclear how far current LLM-based agents are from this paradigm shift in practice. Existing code generation benchmarks do not capture key characteristics of data preparation, including ambiguous user intents, imperfect real-world data, and the need to translate code into interpretable workflows for validation. To bridge this gap, we present PrepBench, a benchmark designed to evaluate NL-driven data preparation along three core capabilities: interactive disambiguation, prep-code generation, and code-to-workflow translation. We crawl data from the Preppin' Data Challenges, and then extend it into a systematically designed benchmark. The benchmark covers diverse domains, and each task involves 3 to 18 data preparation steps. Nearly half of the tasks require over 100 lines of Python code, and the longest solutions approach 300 lines. Our evaluation shows that, despite recent progress, realizing this paradigm shift remains challenging for state-of-the-art LLMs. PrepBench provides a principled benchmark for measuring this gap and helps identify key challenges toward realizing NL-driven data preparation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrepBench, a benchmark for NL-driven data preparation constructed by crawling and extending Preppin' Data Challenges. It targets three capabilities—interactive disambiguation, prep-code generation, and code-to-workflow translation—across tasks with 3–18 steps, diverse domains, and solutions up to ~300 lines of Python. The central claim is that, despite recent LLM progress, state-of-the-art models still face substantial challenges in realizing this paradigm shift.
Significance. If the benchmark faithfully captures real-world characteristics such as natural ambiguity and the need for interpretable workflows, PrepBench would be a useful addition to the field by filling a gap left by existing code-generation benchmarks. The systematic extension of an existing challenge set, coverage of long workflows, and focus on end-to-end capabilities (disambiguation through validation) provide a concrete resource for tracking progress in LLM-based data-preparation agents.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: the claim that the extended tasks accurately reflect ambiguous user intents and the need for interpretable workflows rests on the assumption that crawling Preppin' Data Challenges plus author extensions produce naturally occurring ambiguity rather than synthetic disambiguation steps. If the original challenges contain relatively explicit intents, the reported LLM difficulties with disambiguation and workflow translation may not generalize to real user interactions, directly weakening the headline evaluation result.
- [Evaluation] Evaluation section: the abstract asserts that the evaluation demonstrates challenges for SOTA LLMs, yet the provided description supplies no quantitative metrics, baselines, success rates, or details on how the three core capabilities were measured or how tasks were extended. Without these, the strength of the central claim cannot be assessed.
minor comments (1)
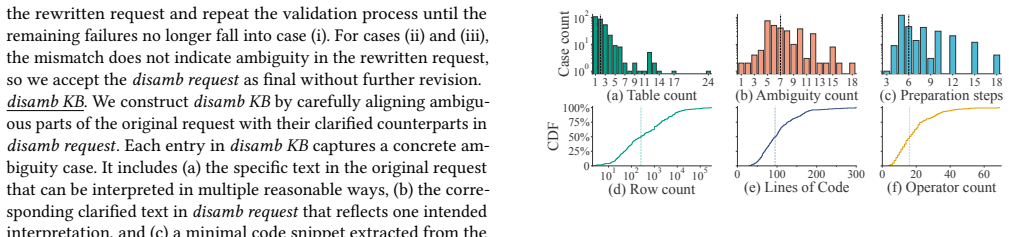
- The abstract states that nearly half the tasks require over 100 lines of code and the longest approach 300 lines; a table or figure summarizing the distribution of task lengths, domains, and step counts would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment point by point below, explaining how we will revise the manuscript to improve clarity and rigor while preserving the core contributions of PrepBench.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: the claim that the extended tasks accurately reflect ambiguous user intents and the need for interpretable workflows rests on the assumption that crawling Preppin' Data Challenges plus author extensions produce naturally occurring ambiguity rather than synthetic disambiguation steps. If the original challenges contain relatively explicit intents, the reported LLM difficulties with disambiguation and workflow translation may not generalize to real user interactions, directly weakening the headline evaluation result.
Authors: We appreciate the referee's concern regarding the naturalness of the ambiguities introduced in PrepBench. The Preppin' Data Challenges originate from real practitioner-submitted data preparation problems, which commonly feature underspecified intents (e.g., high-level goals like 'prepare the sales data for analysis' without detailing column mappings or outlier handling). Our extensions were not arbitrary but systematically derived by analyzing the original challenge statements for points of potential ambiguity and adding disambiguation steps that mirror typical user-LLM interactions in data prep. To address this directly, we will revise the Benchmark Construction section to include a new subsection detailing the crawling methodology, the criteria used to identify natural ambiguities from the source challenges, and concrete before/after examples of task descriptions. This will provide stronger evidence that the benchmark reflects realistic rather than purely synthetic ambiguity. revision: yes
-
Referee: [Evaluation] Evaluation section: the abstract asserts that the evaluation demonstrates challenges for SOTA LLMs, yet the provided description supplies no quantitative metrics, baselines, success rates, or details on how the three core capabilities were measured or how tasks were extended. Without these, the strength of the central claim cannot be assessed.
Authors: We agree that the Evaluation section requires more explicit quantitative detail to fully substantiate the claims. The manuscript does contain an evaluation reporting results across the three capabilities (disambiguation via clarification success rate, code generation via execution accuracy on test cases, and workflow translation via fidelity and interpretability metrics), with comparisons against several SOTA LLMs and baselines. However, to resolve the referee's valid point, we will substantially expand this section with dedicated tables summarizing success rates, error breakdowns, and precise measurement protocols (e.g., how interactive disambiguation was scored and how workflow interpretability was assessed). We will also add statistics on task extensions (e.g., average added steps and ambiguity types). These changes will make the central claim more transparent and assessable. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper introduces PrepBench by crawling and extending Preppin' Data Challenges into tasks for evaluating LLM capabilities in disambiguation, code generation, and workflow translation. The central claim—that SOTA LLMs struggle with NL-driven data prep—is supported solely by direct empirical results on these tasks. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the derivation. The benchmark construction is described as systematic extension of external challenges, but the evaluation outcome does not reduce to the construction by definition or self-reference. This is a standard empirical benchmark paper whose result is falsifiable against the released tasks and LLM outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks from Preppin' Data Challenges can be systematically extended into a benchmark that tests interactive disambiguation, prep-code generation, and code-to-workflow translation.
Reference graph
Works this paper leans on
-
[1]
Anaconda, Inc. 2020. State of Data Science 2020. https://www.anaconda.com/ resources/whitepaper/state-of-data-science-2020 Accessed Jan. 11, 2026
work page 2020
- [2]
-
[3]
Sibei Chen, Nan Tang, Ju Fan, Xuemi Yan, Chengliang Chai, Guoliang Li, and Xi- aoyong Du. 2023. Haipipe: Combining human-generated and machine-generated pipelines for data preparation.Proceedings of the ACM on Management of Data1, 1 (2023), 1–26
work page 2023
-
[4]
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. TabFact: A Large- scale Dataset for Table-based Fact Verification. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=rkeJRhNYDH
work page 2020
-
[5]
Wei-Hao Chen, Weixi Tong, Amanda Case, and Tianyi Zhang. 2025. Dango: A Mixed-Initiative Data Wrangling System using Large Language Model. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–28
work page 2025
-
[6]
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao, Hangyu Mao, and Fuzheng Zhang. 2025. SheetAgent: towards a generalist agent for spreadsheet reasoning and manipulation via large language models. In Proceedings of the ACM on Web Conference 2025. 158–177
work page 2025
- [7]
-
[8]
Michele Dallachiesa, Amr Ebaid, Ahmed Eldawy, Ahmed Elmagarmid, Ihab F Ilyas, Mourad Ouzzani, and Nan Tang. 2013. NADEEF: a commodity data cleaning system. InProceedings of the 2013 ACM SIGMOD International Conference on Management of Data. 541–552. 14
work page 2013
-
[9]
Mingwen Dong, Nischal Ashok Kumar, Yiqun Hu, Anuj Chauhan, Chung-Wei Hang, Shuaichen Chang, Lin Pan, Wuwei Lan, Henghui Zhu, Jiarong Jiang, et al
-
[10]
PRACTIQ: A practical conversational text-to-SQL dataset with ambiguous and unanswerable queries. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 255–273
work page 2025
- [11]
-
[12]
Meihao Fan, Ju Fan, Nan Tang, Lei Cao, Guoliang Li, and Xiaoyong Du. 2025. AutoPrep: Natural Language Question-Aware Data Preparation with a Multi- Agent Framework.Proc. VLDB Endow.18, 10 (2025), 3504–3517. https://doi.org/ 10.14778/3748191.3748211
- [13]
-
[14]
Shubha Guha, Falaah Arif Khan, Julia Stoyanovich, and Sebastian Schelter. 2024. Automated data cleaning can hurt fairness in machine learning-based decision making.IEEE Transactions on Knowledge and Data Engineering36, 12 (2024), 7368–7379
work page 2024
-
[15]
Vivek Gupta, Pranshu Kandoi, Mahek Vora, Shuo Zhang, Yujie He, Ridho Reinanda, and Vivek Srikumar. 2023. TempTabQA: Temporal question answering for semi-structured tables. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2431–2453
work page 2023
-
[16]
Mazhar Hameed and Felix Naumann. 2020. Data preparation: A survey of commercial tools.ACM sigmod record49, 3 (2020), 18–29
work page 2020
-
[17]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, et al. 2025. Data interpreter: An LLM agent for data science. InFindings of the Association for Computational Linguistics: ACL 2025. 19796–19821
work page 2025
-
[18]
Xueyu Hu, Ziyu Zhao, Shuang Wei, Ziwei Chai, Qianli Ma, Guoyin Wang, Xuwu Wang, Jing Su, Jingjing Xu, Ming Zhu, Yao Cheng, Jianbo Yuan, Jiwei Li, Kun Kuang, Yang Yang, Hongxia Yang, and Fei Wu. 2024. InfiAgent-DABench: Evalu- ating Agents on Data Analysis Tasks. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 2...
work page 2024
-
[19]
Yiming Huang, Jianwen Luo, Yan Yu, Yitong Zhang, Fangyu Lei, Yifan Wei, Shizhu He, Lifu Huang, Xiao Liu, Jun Zhao, and Kang Liu. 2024. DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, Y...
- [20]
-
[21]
Zezhou Huang and Eugene Wu. 2024. Cocoon: Semantic table profiling using large language models. InProceedings of the 2024 Workshop on Human-In-the-Loop Data Analytics. 1–7
work page 2024
-
[22]
Nan Huo, Xiaohan Xu, Jinyang Li, Per Jacobsson, Shipei Lin, Bowen Qin, Binyuan Hui, Xiaolong Li, Ge Qu, Shuzheng Si, Linheng Han, Edward Alexander, Xintong Zhu, Rui Qin, Ruihan Yu, Yiyao Jin, Feige Zhou, Weihao Zhong, Yun Chen, Hongyu Liu, Chenhao Ma, Fatma Özcan, Yannis Papakonstantinou, and Reynold Cheng. 2025. BIRD-INTERACT: Re-imagining Text-to-SQL Ev...
- [23]
-
[24]
Sean Kandel, Andreas Paepcke, Joseph Hellerstein, and Jeffrey Heer. 2011. Wran- gler: Interactive visual specification of data transformation scripts. InProceedings of the sigchi conference on human factors in computing systems. 3363–3372
work page 2011
- [25]
-
[26]
Eugenie Lai, Gerardo Vitagliano, Ziyu Zhang, Om Chabra, Sivaprasad Sudhir, Anna Zeng, Anton A Zabreyko, Chenning Li, Ferdi Kossmann, Jialin Ding, et al
- [27]
-
[28]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettle- moyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. DS-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning. PMLR, 18319–18345
work page 2023
-
[29]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. InThe Thirteenth International Conference on Learning Repr...
work page 2025
-
[30]
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhao-Xiang Zhang. 2023. SheetCopilot: Bringing software productivity to the next level through large language models.Advances in Neural Information Processing Systems36 (2023), 4952–4984
work page 2023
-
[31]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2023. Can LLM already serve as A database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2023), 42330–42357
work page 2023
- [32]
-
[33]
Luyi Ma, Nikhil Thakurdesai, Jiao Chen, Jianpeng Xu, Evren Korpeoglu, Sushant Kumar, and Kannan Achan. 2023. LLMs with User-defined prompts as generic data operators for reliable data processing. In2023 IEEE International Conference on big data (BigData). IEEE, 3144–3148
work page 2023
-
[34]
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. 2024. Spreadsheetbench: Towards challenging real world spreadsheet manipulation.Advances in Neural Information Processing Systems37 (2024), 94871–94908
work page 2024
-
[35]
Avanika Narayan, Ines Chami, Laurel J. Orr, and Christopher Ré. 2022. Can Foundation Models Wrangle Your Data?Proc. VLDB Endow.16, 4 (2022), 738–746. https://doi.org/10.14778/3574245.3574258
-
[36]
OpenAI. 2024. ChatGPT. https://chatgpt.com Accessed Jan. 11, 2026
work page 2024
- [37]
-
[38]
Ralph Peeters, Aaron Steiner, and Christian Bizer. 2025. Entity Matching using Large Language Models. InProceedings 28th International Conference on Extend- ing Database Technology, EDBT 2025, Barcelona, Spain, March 25-28, 2025, Alkis Simitsis, Bettina Kemme, Anna Queralt, Oscar Romero, and Petar Jovanovic (Eds.). OpenProceedings.org, 529–541. https://do...
-
[39]
Preppin’ Data. 2024. Preppin’ Data Challenges. https://www.preppindata.com/ challenges Accessed Jan. 11, 2026
work page 2024
-
[40]
Danrui Qi, Zhengjie Miao, and Jiannan Wang. 2025. CleanAgent: Automat- ing Data Standardization with LLM-based Agents. InVLDB 2025 Workshop: Data Driven AI. https://www.vldb.org/2025/Workshops/VLDB-Workshops- 2025/DATAI/DATAI25_8.pdf Artifact available at https://github.com/sfu- db/CleanAgent
work page 2025
-
[41]
Zhangcheng Qiang, Weiqing Wang, and Kerry Taylor. 2024. Agent-OM: Leverag- ing LLM Agents for Ontology Matching.Proc. VLDB Endow.18, 3 (2024), 516–529. https://doi.org/10.14778/3712221.3712222
-
[42]
Vijayshankar Raman. 2001. Potter’s wheel: An interactive data cleaning system. InVLDB, Vol. 1. 381–390
work page 2001
-
[43]
Theodoros Rekatsinas, Xu Chu, Ihab F. Ilyas, and Christopher Ré. 2017. Holo- Clean: Holistic Data Repairs with Probabilistic Inference.Proc. VLDB Endow.10, 11 (2017), 1190–1201. https://doi.org/10.14778/3137628.3137631
-
[44]
El Kindi Rezig, Lei Cao, Michael Stonebraker, Giovanni Simonini, Wenbo Tao, Samuel Madden, Mourad Ouzzani, Nan Tang, and Ahmed K Elmagarmid. 2019. Data civilizer 2.0: A holistic framework for data preparation and analytics. (2019)
work page 2019
- [45]
-
[46]
SAS Institute. 2024. SAS Data Preparation. https://www.sas.com/en_us/software/ data-preparation.html Accessed Jan. 11, 2026
work page 2024
-
[47]
Sebastian Schelter, Dustin Lange, Philipp Schmidt, Meltem Celikel, Felix Biess- mann, and Andreas Grafberger. 2018. Automating large-scale data quality verifi- cation.Proceedings of the VLDB Endowment11, 12 (2018), 1781–1794
work page 2018
-
[48]
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, and Dongmei Zhang. 2024. Table Meets LLM: Can large language models understand structured table data? a benchmark and empirical study. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 645–654
work page 2024
-
[49]
Tableau Software. 2024. Tableau Prep. https://www.tableau.com/products/prep Accessed Jan. 11, 2026
work page 2024
-
[50]
Enzo Veltri, Gilbert Badaro, Mohammed Saeed, and Paolo Papotti. 2023. Data ambiguity profiling for the generation of training examples. In2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 450–463
work page 2023
-
[51]
Tianshu Wang, Xiaoyang Chen, Hongyu Lin, Xuanang Chen, Xianpei Han, Le Sun, Hao Wang, and Zhenyu Zeng. 2025. Match, compare, or select? an investigation of large language models for entity matching. InProceedings of the 31st International Conference on Computational Linguistics. 96–109
work page 2025
-
[52]
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. 2024. MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=jp3gWrMuIZ 15
work page 2024
-
[53]
Pengcheng Yin, Wen-Ding Li, Kefan Xiao, Abhishek Rao, Yeming Wen, Kensen Shi, Joshua Howland, Paige Bailey, Michele Catasta, Henryk Michalewski, et al
-
[54]
Natural language to code generation in interactive data science notebooks. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 126–173
-
[55]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir R. Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Pro...
-
[56]
Haochen Zhang, Yuyang Dong, Chuan Xiao, and Masafumi Oyamada. 2024. Large Language Models as Data Preprocessors. InProceedings of Workshops at the 50th International Conference on Very Large Data Bases, VLDB 2024, Guangzhou, China, August 26-30, 2024. VLDB.org. https://vldb.org/workshops/2024/proceedings/ TaDA/TaDA.11.pdf
work page 2024
-
[57]
Michael J. Q. Zhang, W. Bradley Knox, and Eunsol Choi. 2025. Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=cwuSAR7EKd
work page 2025
-
[58]
Yuge Zhang, Qiyang Jiang, XingyuHan XingyuHan, Nan Chen, Yuqing Yang, and Kan Ren. 2024. Benchmarking data science agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5677–5700
work page 2024
- [59]
- [60]
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.