Recognition: no theorem link
Structure-Centric Graph Foundation Model via Geometric Bases
Pith reviewed 2026-05-12 01:24 UTC · model grok-4.3
The pith
Learnable geometric bases define a shared structural coordinate system that aligns heterogeneous graphs via Gromov-Wasserstein distances for transferable representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCGFM introduces learnable geometric bases that define a shared structural coordinate system. Graphs are aligned to these bases via Gromov-Wasserstein distances, yielding structure-aligned latent representations that accommodate heterogeneous graph topologies. To address feature incompatibility, SCGFM employs a structure-aware feature re-encoding mechanism that unifies node representations without assuming a fixed feature dimensionality or requiring dataset-specific preprocessing.
What carries the argument
Learnable geometric bases that serve as a shared structural coordinate system, to which input graphs are aligned by minimizing Gromov-Wasserstein distances between their metric measure spaces.
If this is right
- Representations become transferable between graphs whose node features have different dimensionalities and whose topologies differ substantially.
- No dataset-specific preprocessing is required to handle varying graph structures.
- Both graph-level and node-level tasks show improved in-domain and cross-domain accuracy over prior graph foundation model baselines.
- Topology is treated as the dominant carrier of knowledge, with features handled secondarily through re-encoding.
Where Pith is reading between the lines
- The same bases could be applied to other data types that admit metric-space descriptions, such as point clouds or simplicial complexes.
- If the learned bases prove stable, they might serve as a diagnostic tool to compare structural similarity between unrelated graph collections.
- The approach suggests that future graph models might separate structural alignment from feature processing more explicitly than current end-to-end architectures.
Load-bearing premise
Graph topology supplies the main transferable signal across domains and Gromov-Wasserstein alignment plus structure-aware re-encoding can produce unified representations without fixed feature sizes.
What would settle it
A cross-domain experiment in which adding the geometric bases and Gromov-Wasserstein alignment produces no measurable gain over a standard graph encoder that ignores structural alignment.
Figures



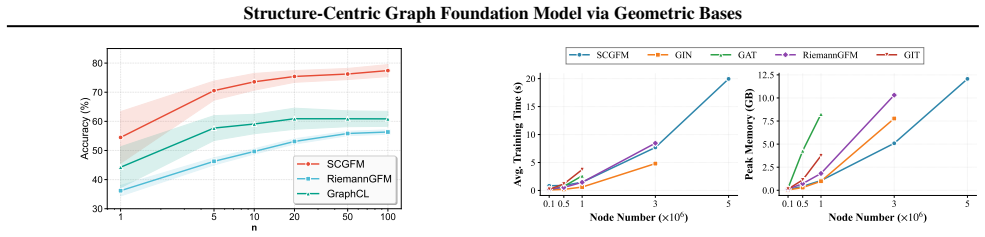





read the original abstract
Graph foundation models (GFMs) seek transferable representations across graph domains but are limited by structural heterogeneity and incompatible node feature spaces. We propose Structure-Centric Graph Foundation Models (SCGFM), which treat graph topology as the primary source of transferable knowledge. Modeling graphs as metric measure spaces, SCGFM introduces learnable geometric bases that define a shared structural coordinate system. Graphs are aligned to these bases via Gromov-Wasserstein distances, yielding structure-aligned latent representations that accommodate heterogeneous graph topologies. To address feature incompatibility, SCGFM employs a structure-aware feature re-encoding mechanism that unifies node representations without assuming a fixed feature dimensionality or requiring dataset-specific preprocessing. Experiments on graph- and node-level tasks demonstrate strong in-domain and cross-domain generalization, outperforming existing GFM approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Structure-Centric Graph Foundation Models (SCGFM) that model graphs as metric measure spaces and introduce learnable geometric bases to define a shared structural coordinate system. Graphs are aligned to these bases via Gromov-Wasserstein distances to obtain structure-aligned latent representations that accommodate heterogeneous topologies. A structure-aware feature re-encoding mechanism is introduced to unify node representations without assuming fixed feature dimensionality or dataset-specific preprocessing. Experiments on graph- and node-level tasks are reported to demonstrate strong in-domain and cross-domain generalization, outperforming prior GFM approaches.
Significance. If the central construction holds, the work offers a topology-first route to graph foundation models that could reduce reliance on feature alignment and enable transfer across structurally diverse domains. The explicit use of Gromov-Wasserstein alignment to a learnable basis and the structure-aware re-encoding are concrete technical contributions that address two persistent obstacles in GFM literature.
major comments (2)
- [§3.2] §3.2 (Geometric Bases): the claim that the learnable bases define a 'parameter-free' shared coordinate system appears to be contradicted by the fact that the bases themselves are optimized; the alignment objective therefore depends on the number and initialization of these bases, which should be stated explicitly as hyperparameters.
- [§4.3] §4.3 (Cross-domain Experiments): the reported gains on cross-domain node classification are presented without an ablation that isolates the contribution of the Gromov-Wasserstein alignment versus the structure-aware re-encoding; without this separation it is difficult to attribute the improvement to the claimed structural unification.
minor comments (3)
- [§2] Notation for the metric measure space (X, d, μ) is introduced in §2 but not consistently reused in the alignment loss; a single consistent symbol set would improve readability.
- [Figure 2] Figure 2 (alignment visualization) would benefit from an additional panel showing the learned bases in the original graph space rather than only the aligned latent space.
- [Abstract / §3.3] The abstract states that the method 'accommodates heterogeneous graph topologies' but does not mention the maximum graph size or density for which the GW solver remains tractable; this practical limit should be stated in §3.3.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and have incorporated revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Geometric Bases): the claim that the learnable bases define a 'parameter-free' shared coordinate system appears to be contradicted by the fact that the bases themselves are optimized; the alignment objective therefore depends on the number and initialization of these bases, which should be stated explicitly as hyperparameters.
Authors: We agree that the terminology requires clarification. The phrase 'parameter-free' was intended to indicate that the shared coordinate system imposes no additional dataset-specific structural constraints or preprocessing steps once the bases are determined. However, the bases are indeed optimized, and both their number (K) and initialization are hyperparameters that influence the Gromov-Wasserstein alignment. In the revised manuscript we will (i) explicitly list K and the initialization strategy as hyperparameters in Section 3.2 and the experimental protocol, and (ii) rephrase the description to avoid any implication that the bases themselves are parameter-free. revision: yes
-
Referee: [§4.3] §4.3 (Cross-domain Experiments): the reported gains on cross-domain node classification are presented without an ablation that isolates the contribution of the Gromov-Wasserstein alignment versus the structure-aware re-encoding; without this separation it is difficult to attribute the improvement to the claimed structural unification.
Authors: The referee correctly identifies that an explicit ablation would improve attribution. The current experiments demonstrate the joint effectiveness of SCGFM, but do not separate the two mechanisms. We will add a targeted ablation study to the revised Section 4.3 that evaluates cross-domain node classification performance under three controlled variants: (1) full SCGFM, (2) SCGFM without Gromov-Wasserstein alignment (replaced by a baseline matching procedure), and (3) SCGFM without the structure-aware re-encoding step. This will allow readers to quantify the individual contributions to the observed gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core construction introduces learnable geometric bases as parameters that are optimized to align input graphs via Gromov-Wasserstein distances, producing structure-aligned representations. This is a standard modeling choice (bases are fitted during training to serve as a common reference frame) rather than a self-referential loop where the claimed output is presupposed in the definition of the inputs. No equations or steps in the provided abstract reduce a prediction to a fitted quantity by construction, nor do they rely on self-citations for uniqueness or load-bearing premises. The structure-aware re-encoding is presented as an independent mechanism for feature unification. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable geometric bases
axioms (1)
- domain assumption Graphs can be modeled as metric measure spaces
invented entities (1)
-
learnable geometric bases
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =
Pat Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
- [2]
-
[3]
M. J. Kearns , title =
-
[4]
Machine learning - an artificial intelligence approach , publisher =. Symbolic computation , year =
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork , title =
-
[6]
Foundations of Computational Mathematics , volume=
Gromov--Wasserstein distances and the metric approach to object matching , author=. Foundations of Computational Mathematics , volume=. 2011 , publisher=
work page 2011
-
[7]
International Conference on Machine Learning (ICML 2016) , series =
Gromov-Wasserstein averaging of kernel and distance matrices , author=. International Conference on Machine Learning (ICML 2016) , series =. 2016 , organization=
work page 2016
-
[8]
On the geometry of metric measure spaces , author=. Acta Mathematica , volume=. 2006 , publisher=
work page 2006
-
[9]
Vayer, Titouan and Flamary, R. Sliced. 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) , year=
work page 2019
-
[10]
Metric Structures for
-
[11]
Advances in Neural Information Processing Systems (NeurIPS 2017) , volume=
Wasserstein generative adversarial networks , author=. Advances in Neural Information Processing Systems (NeurIPS 2017) , volume=
work page 2017
-
[12]
Foundations and Trends in Machine Learning , volume=
Computational Optimal Transport , author=. Foundations and Trends in Machine Learning , volume=
-
[13]
Petar Velickovic and William Fedus and William L. Hamilton and Pietro Li. Deep Graph Infomax , booktitle =
-
[14]
Advances in Neural Information Processing Systems (NeurIPS 2020) , volume =
Graph contrastive learning with augmentations , author =. Advances in Neural Information Processing Systems (NeurIPS 2020) , volume =
work page 2020
-
[15]
Advances in Neural Information Processing Systems (NeurIPS 2023) , volume =
Simple and asymmetric graph contrastive learning without augmentations , author =. Advances in Neural Information Processing Systems (NeurIPS 2023) , volume =
work page 2023
- [16]
-
[17]
Hou, Zhenyu and He, Yufei and Cen, Yukuo and Liu, Xiao and Dong, Yuxiao and Kharlamov, Evgeny and Tang, Jie , booktitle =. Graph. 2023 , publisher =
work page 2023
-
[18]
Tan, Qiaoyu and Liu, Ninghao and Huang, Xiao and Choi, Soo-Hyun and Li, Li and Chen, Rui and Hu, Xia , booktitle =. 2023 , publisher =
work page 2023
-
[19]
International Conference on Learning Representations (ICLR 2024) , year =
One For All: Towards Training One Graph Model For All Classification Tasks , author =. International Conference on Learning Representations (ICLR 2024) , year =
work page 2024
-
[20]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =
Towards Graph Foundation Models: Learning Generalities Across Graphs via Task-Trees , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =. 2025 , series =
work page 2025
-
[21]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =
Multi-Domain Graph Foundation Models: Robust Knowledge Transfer via Topology Alignment , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =. 2025 , series =
work page 2025
-
[22]
Chen, Haibo and Wang, Xin and Zhang, Zeyang and Li, Haoyang and Feng, Ling and Zhu, Wenwu , booktitle =. Auto. 2025 , series =
work page 2025
- [23]
-
[24]
IEEE Transactions on Knowledge and Data Engineering (TKDE 2023) , volume =
Graph Self-Supervised Learning: A Survey , author =. IEEE Transactions on Knowledge and Data Engineering (TKDE 2023) , volume =
work page 2023
-
[25]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023) , volume =
Self-Supervised Learning of Graph Neural Networks: A Unified Review , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023) , volume =
work page 2023
-
[26]
ACM Transactions on Intelligent Systems and Technology , volume =
A Survey on Graph Representation Learning Methods , author =. ACM Transactions on Intelligent Systems and Technology , volume =
-
[27]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2025) , volume =
Graph Foundation Models: Concepts, Opportunities and Challenges , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2025) , volume =
work page 2025
-
[28]
Graph foundation models: A comprehensive survey,
Graph Foundation Models: A Comprehensive Survey , author=. arXiv preprint arXiv:2505.15116 , volume =
-
[29]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
D evlin, J acob and C hang, M ing- W ei and L ee, K enton and T outanova, K ristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (NAACL-HLT 2019). 2019
work page 2019
-
[30]
Advances in Neural Information Processing Systems (NeurIPS 2020) , pages =
Language Models are Few-Shot Learners , volume =. Advances in Neural Information Processing Systems (NeurIPS 2020) , pages =
work page 2020
-
[31]
International Conference on Learning Representations (ICLR 2021) , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations (ICLR 2021) , year=
work page 2021
-
[32]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =
Hierarchical Graph Tokenization for Molecule-Language Alignment , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =. 2025 , volume =
work page 2025
-
[33]
Masked Autoencoders Are Scalable Vision Learners , booktitle =
He, Kaiming and Chen, Xinlei and Xie, Saining and Li, Yanghao and Doll. Masked Autoencoders Are Scalable Vision Learners , booktitle =
-
[34]
Ye, Ruosong and Zhang, Caiqi and Wang, Runhui and Xu, Shuyuan and Zhang, Yongfeng. Language is All a Graph Needs. Findings of the Association for Computational Linguistics: EACL 2024. 2024
work page 2024
-
[35]
Can Language Models Solve Graph Problems in Natural Language? , volume =
Wang, Heng and Feng, Shangbin and He, Tianxing and Tan, Zhaoxuan and Han, Xiaochuang and Tsvetkov, Yulia , booktitle =. Can Language Models Solve Graph Problems in Natural Language? , volume =
-
[36]
Zhao, Haiteng and Liu, Shengchao and Chang, Ma and Xu, Hannan and Fu, Jie and Deng, Zhihong and Kong, Lingpeng and Liu, Qi , booktitle =
-
[37]
Haonan Yuan and Qingyun Sun and Junhua Shi and Xingcheng Fu and Bryan Hooi and Jianxin Li and Philip S. Yu , booktitle=. How Much Can Transfer?
-
[38]
Spectral Networks and Locally Connected Networks on Graphs , author=. CoRR , year=
-
[39]
8th International Conference on Learning Representations (ICLR 2020) , year=
Strategies for Pre-training Graph Neural Networks , author=. 8th International Conference on Learning Representations (ICLR 2020) , year=
work page 2020
-
[40]
Recipe for a General, Powerful, Scalable Graph Transformer , volume =
Ramp\'. Recipe for a General, Powerful, Scalable Graph Transformer , volume =. Advances in Neural Information Processing Systems (NeurIPS 2022) , pages =
work page 2022
-
[41]
Zeng, Zhichen and Zhu, Ruike and Xia, Yinglong and Zeng, Hanqing and Tong, Hanghang , title =. 2023 , booktitle =
work page 2023
-
[42]
Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , pages =
Online Graph Dictionary Learning , author =. Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , pages =. 2021 , volume =
work page 2021
-
[43]
arXiv preprint arXiv:1704.00805 , year=
On the properties of the softmax function with application in game theory and reinforcement learning , author=. arXiv preprint arXiv:1704.00805 , year=
-
[44]
Differential Properties of Sinkhorn Approximation for Learning with Wasserstein Distance , volume =
Luise, Giulia and Rudi, Alessandro and Pontil, Massimiliano and Ciliberto, Carlo , booktitle =. Differential Properties of Sinkhorn Approximation for Learning with Wasserstein Distance , volume =
-
[45]
5th International Conference on Learning Representations (ICLR 2017) , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. 5th International Conference on Learning Representations (ICLR 2017) , year=
work page 2017
-
[46]
7th International Conference on Learning Representations (ICLR 2019) , address=
How Powerful are Graph Neural Networks? , author=. 7th International Conference on Learning Representations (ICLR 2019) , address=
work page 2019
-
[47]
6th International Conference on Learning Representations (ICLR 2018) , year=
Graph Attention Networks , author=. 6th International Conference on Learning Representations (ICLR 2018) , year=
work page 2018
-
[48]
Sun, Xiangguo and Cheng, Hong and Li, Jia and Liu, Bo and Guan, Jihong , title =. 2024 , booktitle =
work page 2024
-
[49]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =
Equivalence is All: A Unified View for Self-supervised Graph Learning , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =. 2025 , address =
work page 2025
-
[50]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =
Self-supervised Masked Graph Autoencoder via Structure-aware Curriculum , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , pages =. 2025 , volume =
work page 2025
-
[51]
Proceedings of the ACM Web Conference 2026 , pages=
RAG-GFM: Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation , author=. Proceedings of the ACM Web Conference 2026 , pages=
work page 2026
-
[52]
The Fourteenth International Conference on Learning Representations , year=
SAGA: Structural Aggregation Guided Alignment with Dynamic View and Neighborhood Order Selection for Multiview Graph Domain Adaptation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graph domain adaptation via homophily-agnostic reconstructing structure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
From Subtle to Significant: Prompt-Driven Self-Improving Optimization in Test-Time Graph OOD Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
Proceedings of the ACM on Web Conference 2025 , year=
SAMGPT: Text-free Graph Foundation Model for Multi-domain Pre-training and Cross-domain Adaptation , author=. Proceedings of the ACM on Web Conference 2025 , year=
work page 2025
-
[56]
Wang, Xingliang and Liu, Zemin and Han, Junxiao and Deng, Shuiguang , booktitle =. RAG4GFM: Bridging Knowledge Gaps in Graph Foundation Models through Graph Retrieval Augmented Generation , volume =
-
[57]
Proceedings of the 36th International Conference on Machine Learning , pages =
Optimal Transport for structured data with application on graphs , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , volume =
work page 2019
- [58]
-
[59]
Proceedings of the 40th International Conference on Machine Learning , pages =
Beyond Homophily: Reconstructing Structure for Graph-agnostic Clustering , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
work page 2023
-
[60]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Cooperation of Experts: Fusing Heterogeneous Information with Large Margin , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =
work page 2025
-
[61]
Beyond Redundancy: Information-aware Unsupervised Multiplex Graph Structure Learning , volume =
Shen, Zhixiang and Wang, Shuo and Kang, Zhao , booktitle =. Beyond Redundancy: Information-aware Unsupervised Multiplex Graph Structure Learning , volume =. doi:10.52202/079017-0993 , editor =
-
[62]
Shen, Zhixiang and Kang, Zhao , journal=. When Heterophily Meets Heterogeneous Graphs: Latent Graphs Guided Unsupervised Representation Learning , year=
-
[63]
International conference on learning representations , volume=
On the benefits of attribute-driven graph domain adaptation , author=. International conference on learning representations , volume=
-
[64]
Proceedings of the AAAI conference on artificial intelligence , volume=
Pc-conv: Unifying homophily and heterophily with two-fold filtering , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[65]
Yu, Guangxi and Guo, Jie and Zhu, Xinyu and Feng, Ling and Zhang, Wenwu , booktitle =. 2025 , pages =
work page 2025
-
[66]
He, Yufei and Sui, Yuan and He, Xiaoxin and Hooi, Bryan , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (KDD 2025) , pages =. 2025 , publisher =
work page 2025
-
[67]
New Perspectives in Graph Machine Learning , year=
Turning Tabular Foundation Models into Graph Foundation Models , author=. New Perspectives in Graph Machine Learning , year=
-
[68]
Xingliang Wang and Zemin Liu and Junxiao Han and Shuiguang Deng , booktitle=
-
[69]
Hanqing Zeng and Hongkuan Zhou and Ajitesh Srivastava and Rajgopal Kannan and Viktor Prasanna , booktitle=. Graph
- [70]
-
[71]
Journal of Chemical Information and Computer Sciences , volume=
Spline-fitting with a genetic algorithm: a method for developing classification structure-activity relationships , author=. Journal of Chemical Information and Computer Sciences , volume=. 2003 , publisher=
work page 2003
-
[72]
Knowledge and Information Systems , volume=
Comparison of descriptor spaces for chemical compound retrieval and classification , author=. Knowledge and Information Systems , volume=
-
[73]
Correlation with molecular orbital energies and hydrophobicity , author=
Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. Correlation with molecular orbital energies and hydrophobicity , author=. Journal of Medicinal Chemistry , volume=. 1991 , publisher=
work page 1991
- [74]
-
[75]
Knyazev, Boris and Taylor, Graham W. and Amer, Mohamed R. , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS 2019) , pages =. 2019 , publisher =
work page 2019
-
[76]
Borgwardt, Karsten M. and Ong, Cheng Soon and Sch\". Protein function prediction via graph kernels , year =. Bioinformatics , month = jan, pages =
-
[77]
Proceedings of The 33rd International Conference on Machine Learning (ICML 2016) , pages =
Revisiting Semi-Supervised Learning with Graph Embeddings , author =. Proceedings of The 33rd International Conference on Machine Learning (ICML 2016) , pages =. 2016 , volume =
work page 2016
- [78]
-
[79]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2017) , pages =. 2017 , publisher =
work page 2017
-
[80]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.