Recognition: 2 theorem links
· Lean TheoremThe Global Empirical NTK: Self-Referential Bias and Dimensionality of Gradient Descent Learning
Pith reviewed 2026-05-12 02:47 UTC · model grok-4.3
The pith
The global empirical NTK decomposes into a Kronecker-core Gram matrix times a state-dependency operator, imposing a low-rank bottleneck on gradient descent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
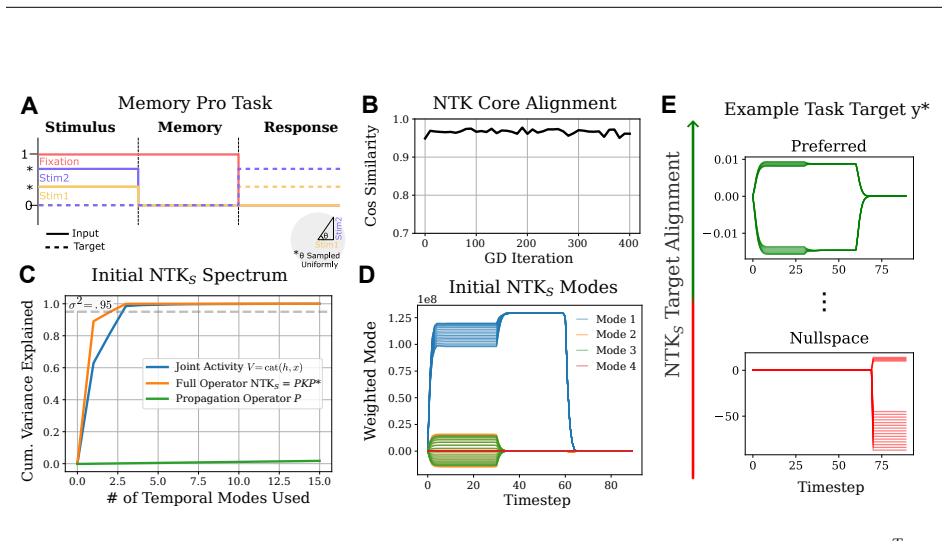
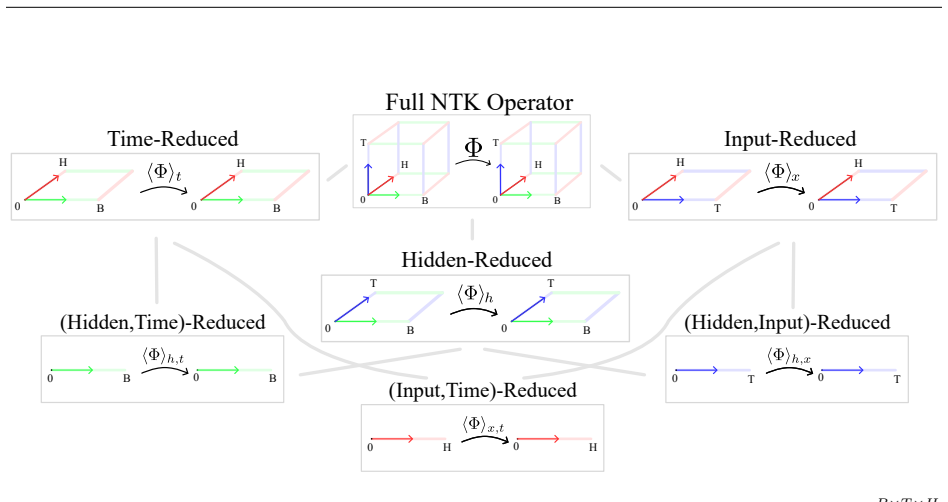
Formulating the model state as the solution to a single global implicit constraint yields the global empirical NTK as the product of operators K and P. For RNNs, transformers and other weight-based models a universal Kronecker-core theorem establishes that K is exactly the Gram matrix of the weight-site variables. The resulting structure shows the NTK is bottlenecked in rank, producing a self-referential bias that directs gradient descent toward the principal modes of joint hidden and input activity. The spectrum of the NTK in recurrent models is accordingly biased and low-rank in space or time, and initialization dynamics further restrict the learnable subspace. The same low-rank constraint
What carries the argument
The universal Kronecker-core theorem, which shows that the immediate parameter-to-state operator K equals the exact Gram matrix of weight-site variables.
Load-bearing premise
The model state can be expressed as the solution to a single global implicit constraint that lets the NTK factor exactly into operators K and P.
What would settle it
Direct numerical computation of the global empirical NTK for a small finite-width RNN or transformer and verification that it does not equal the predicted product of the weight-site Gram matrix and the state-dependency operator would falsify the Kronecker-core claim.
Figures







read the original abstract
In training a neural network with gradient descent (GD), each iteration induces a linear operator that governs first-order updates to a model's internal state variables. We define this operator as the Global Empirical Neural Tangent Kernel (NTK). In finite-width networks, the NTK is typically intractable to form, leading prior work to focus on restrictive settings such as tracking outputs only or taking infinite-width limits. Here, we study the structure of the NTK for a range of models. Formulating the model state as the solution to a single global implicit constraint, we derive the NTK as a product of two operators: K, accounting for immediate parameter-to-state interactions, and P, describing internal state-to-state dependencies. For a broad class of weight-based models, including RNNs and transformers, we prove a universal Kronecker-core theorem showing that K admits an exact, computable form given by the Gram matrix of weight-site variables. This core structure reveals that the NTK is structurally bottlenecked, constraining its effective rank and giving rise to a self-referential bias whereby GD preferentially learns within dominant modes of joint hidden and input activity. For recurrent models, we examine the spectrum of the NTK and show when it is biased and low-rank in space or time under the proposed decomposition. We further demonstrate that model dynamics at initialization bias the NTK, restricting learning and preventing task components from being learned effectively. Finally, we show that the NTK associated with a self-attention transformer is likewise structurally constrained to be low-rank. Overall, we show that the NTK possesses tractable structure that explains GD bias toward task solutions and the emergence of low-rank representations. To enable use of the NTK as a practical metric, we build kpflow, a library relying on randomized matrix-free numerical linear algebra.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines the Global Empirical Neural Tangent Kernel (NTK) as the linear operator induced by each gradient-descent iteration on a model's internal state variables. Formulating the model state as the exact solution to a single global implicit constraint, it derives the NTK as the product of operators K (immediate parameter-to-state interactions) and P (internal state-to-state dependencies). For weight-based models including RNNs and transformers, it proves a universal Kronecker-core theorem asserting that K equals the Gram matrix of weight-site variables, implying a structural rank bottleneck, self-referential bias in which GD preferentially learns dominant modes of joint hidden-input activity, spectral properties for recurrent models, initialization-induced restrictions on learnable task components, and low-rank structure for self-attention transformers. A randomized matrix-free library (kpflow) is provided to make the NTK practical.
Significance. If the derivations and the global-constraint formulation hold exactly for the claimed architectures, the work supplies a tractable structural account of finite-width NTK behavior that explains GD biases and the emergence of low-rank representations without relying on infinite-width limits. The Kronecker-core result and the accompanying computational library constitute concrete, usable contributions that could inform analysis of training dynamics across recurrent and attention-based models.
major comments (3)
- [Abstract and derivation of NTK = K P] The derivation of NTK = K P and the exact Kronecker-core theorem (K as Gram matrix of weight-site variables) rests on the model state being formulated as the exact solution to one global implicit constraint. For RNNs the recurrence unfolds over explicit time steps and for transformers self-attention and layer norms are computed sequentially; the manuscript must clarify whether this constraint holds exactly or requires additional fixed-point assumptions not stated for the broad class, because any gap directly undermines the claimed exact computable form, rank bottleneck, and self-referential bias.
- [Kronecker-core theorem and bias discussion] The self-referential bias claim (GD preferentially learns within dominant modes of joint hidden and input activity) is presented as a direct consequence of the low-rank structure induced by the Kronecker core. The manuscript should supply the explicit spectral decomposition or mode-identification step that converts the Gram-matrix form of K into this preferential-learning statement, because the bias is load-bearing for the paper's explanation of GD behavior.
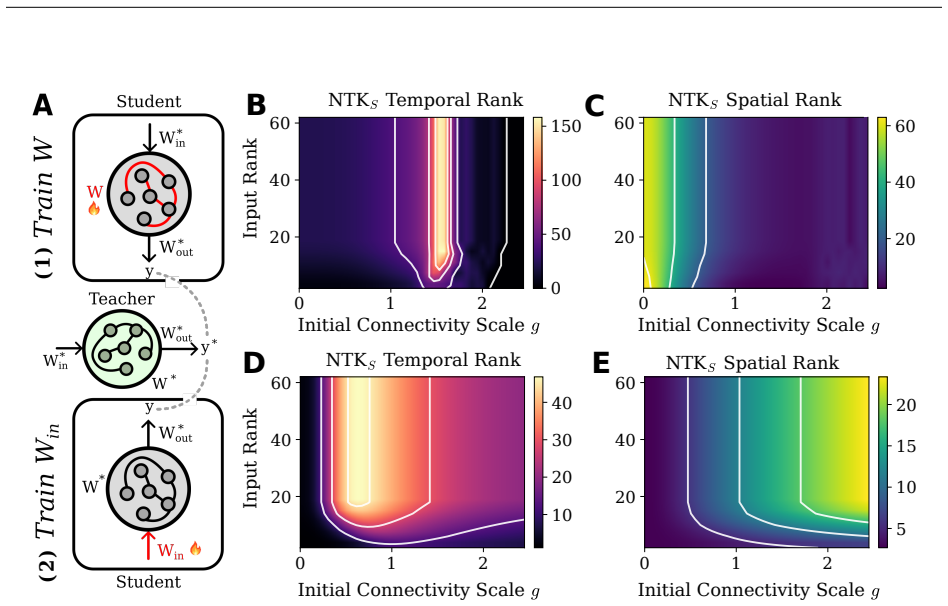
- [Spectrum and transformer sections] The spectral analysis for recurrent models and the low-rank demonstration for transformers are asserted to follow from the K-P decomposition. The manuscript must state the precise assumptions on the weight-site variables and the P operator that guarantee the reported rank bounds and bias in space/time, because these results are used to support the universal applicability of the theorem.
minor comments (2)
- [Introduction] Notation for the operators K and P is introduced without an early summary table relating them to standard NTK components; a brief comparison would aid readability.
- [Final section] The kpflow library is mentioned as enabling practical use, but no pseudocode or complexity statement for the randomized matrix-free routines appears in the main text.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract and derivation of NTK = K P] The derivation of NTK = K P and the exact Kronecker-core theorem (K as Gram matrix of weight-site variables) rests on the model state being formulated as the exact solution to one global implicit constraint. For RNNs the recurrence unfolds over explicit time steps and for transformers self-attention and layer norms are computed sequentially; the manuscript must clarify whether this constraint holds exactly or requires additional fixed-point assumptions not stated for the broad class, because any gap directly undermines the claimed exact computable form, rank bottleneck, and self-referential bias.
Authors: The global implicit constraint is defined directly as the equation satisfied by the full model state vector after the complete forward pass, with the computation graph (including unfolded recurrence or sequential layers) serving as the exact map from parameters to states. For RNNs this means the state equations at every time step are satisfied simultaneously by the unfolded trajectory; for transformers the layer-wise equations (including self-attention and norms) are satisfied by the sequential computation. No iterative fixed-point solver or extra assumptions are introduced beyond the standard forward pass, which solves the constraint by construction. We will add a short clarifying subsection in the methods that states this equivalence explicitly for the architectures considered. revision: yes
-
Referee: [Kronecker-core theorem and bias discussion] The self-referential bias claim (GD preferentially learns within dominant modes of joint hidden and input activity) is presented as a direct consequence of the low-rank structure induced by the Kronecker core. The manuscript should supply the explicit spectral decomposition or mode-identification step that converts the Gram-matrix form of K into this preferential-learning statement, because the bias is load-bearing for the paper's explanation of GD behavior.
Authors: Under the Kronecker-core theorem, K is the Gram matrix G = V^TV where the columns of V are the weight-site variables (concatenated input and hidden activations at each parameter location). The eigendecomposition G = U Lambda U^T therefore has eigenvectors U that are precisely the principal components of these joint activity vectors. Because the NTK is the composition KP, its action projects parameter updates onto the dominant subspace spanned by these modes, yielding the stated self-referential bias. We will insert the explicit decomposition together with the mode-identification argument immediately after the theorem statement and reference it in the bias discussion. revision: yes
-
Referee: [Spectrum and transformer sections] The spectral analysis for recurrent models and the low-rank demonstration for transformers are asserted to follow from the K-P decomposition. The manuscript must state the precise assumptions on the weight-site variables and the P operator that guarantee the reported rank bounds and bias in space/time, because these results are used to support the universal applicability of the theorem.
Authors: The weight-site variables are finite-dimensional vectors in R^{d_in + d_hidden} formed by concatenating the input and hidden activations at each weight. The operator P is the Jacobian of the internal state-to-state map and is taken to be full rank (or invertible) in the generic case; for recurrent models the spectrum is analyzed on the time-unfolded product of per-step Jacobians. For transformers the self-attention weights define the sites and the low-rank bound follows when the attention Gram is rank-deficient. We will add an explicit paragraph listing these assumptions immediately before the spectral and transformer results, together with a brief note on where the bounds continue to hold under relaxed conditions. revision: yes
Circularity Check
No significant circularity; derivation follows from explicit assumption without reduction by construction
full rationale
The paper defines the Global Empirical NTK as the linear operator governing first-order GD updates to internal state variables. It then states the modeling choice 'Formulating the model state as the solution to a single global implicit constraint' and derives the decomposition NTK = K P together with the Kronecker-core theorem that K equals the Gram matrix of weight-site variables. This is a direct consequence of the stated formulation rather than a self-referential loop in which the result is presupposed. No parameters are fitted on data and then relabeled as predictions, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled through prior work. The claims of rank bottleneck and self-referential bias are logical corollaries of the derived operator structure for the claimed model class. The derivation chain is therefore self-contained under its own premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model state is the solution to a single global implicit constraint
invented entities (3)
-
Global Empirical NTK
no independent evidence
-
K operator
no independent evidence
-
P operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Formulating the model state as the solution to a single global implicit constraint, we derive NTKS as a product of two operators: K ... and P ... For a broad class of weight-based models ... universal Kronecker-core theorem showing that K admits an exact, computable form given by the Gram matrix of weight-site variables.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NTKS = P K P* ... K = V V* ⊗ I ... self-referential bias whereby GD preferentially learns within dominant modes of joint hidden and input activity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2311.10869 , year=
Evolutionary algorithms as an alternative to backpropagation for supervised training of Biophysical Neural Networks and Neural ODEs , author=. arXiv preprint arXiv:2311.10869 , year=
-
[2]
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
work page 2015
-
[3]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[4]
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[5]
Papyan, Vardan and Han, X. Y. and Donoho, David L. , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =
work page 2020
-
[6]
Organizing recurrent network dynamics by task-computation to enable continual learning , url =
Duncker, Lea and Driscoll, Laura and Shenoy, Krishna V and Sahani, Maneesh and Sussillo, David , booktitle =. Organizing recurrent network dynamics by task-computation to enable continual learning , url =
-
[7]
Tishby, Naftali and Pereira, Fernando C. and Bialek, William , title =. Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing , year =
-
[8]
Frederickson, Paul and Kaplan, J. L. and Yorke, E. D. and Yorke, J. A. , title =. Journal of Differential Equations , volume =
-
[9]
The Mathematical Theory of Optimal Processes , author =. 1962 , publisher =
work page 1962
-
[10]
Rumelhart, D. E. and Hinton, G. E. and Williams, R. J. , title =. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations , year =
-
[11]
Neural Machine Translation by Jointly Learning to Align and Translate , author=. 2016 , eprint=
work page 2016
-
[12]
Transition to Chaos in Random Neuronal Networks , author=. Physical Review X , volume=. 2015 , publisher=
work page 2015
-
[13]
Dynamically Learning to Integrate in Recurrent Neural Networks , author=. 2025 , eprint=
work page 2025
-
[14]
Lyapunov spectra of chaotic recurrent neural networks , author=. 2020 , eprint=
work page 2020
- [15]
-
[16]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. 2019 , eprint=
work page 2019
-
[17]
Surrogate Gradient Learning in Spiking Neural Networks , author=. 2019 , eprint=
work page 2019
-
[18]
Exploring the Impact of Activation Functions in Training Neural
Tianxiang Gao and Siyuan Sun and Hailiang Liu and Hongyang Gao , booktitle=. Exploring the Impact of Activation Functions in Training Neural. 2025 , url=
work page 2025
-
[19]
The Journal of physiology , volume=
A quantitative description of membrane current and its application to conduction and excitation in nerve , author=. The Journal of physiology , volume=. 1952 , doi=
work page 1952
-
[20]
The interplay between randomness and structure during learning in RNNs , url =
Schuessler, Friedrich and Mastrogiuseppe, Francesca and Dubreuil, Alexis and Ostojic, Srdjan and Barak, Omri , booktitle =. The interplay between randomness and structure during learning in RNNs , url =
-
[21]
Optimize-Discretize for Time-Series Regression and Continuous Normalizing Flows , author=
Discretize-Optimize vs. Optimize-Discretize for Time-Series Regression and Continuous Normalizing Flows , author=. 2020 , eprint=
work page 2020
-
[22]
Neural Networks: Tricks of the Trade , pages =
Efficient BackProp , author =. Neural Networks: Tricks of the Trade , pages =. 1998 , publisher =
work page 1998
-
[23]
Advances in Neural Information Processing Systems , volume =
Neural Ordinary Differential Equations , author =. Advances in Neural Information Processing Systems , volume =
-
[24]
arXiv preprint arXiv:1711.00579 , year =
A Proposal on Machine Learning via Dynamical Systems , author =. arXiv preprint arXiv:1711.00579 , year =
-
[25]
Des premiers travaux de Le Verrier \`a la d\'ecouverte de Neptune
Stable Architectures for Deep Neural Networks , author =. arXiv preprint arXiv:1710.03688 , year =
-
[26]
Optimal Stopping and the Sufficiency of Randomized Threshold Strategies
Maximum Principle Based Algorithms for Deep Learning , author =. arXiv preprint arXiv:1708.01038 , year =
-
[27]
Automatic Differentiation of Algorithms , pages =
Gradient Calculations for Dynamic Systems , author =. Automatic Differentiation of Algorithms , pages =. 1995 , publisher =
work page 1995
-
[28]
Advances in Neural Information Processing Systems , volume=
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Machine Learning , year=
A Convergence Theory for Deep Learning via Over-Parameterization , author=. International Conference on Machine Learning , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Mean-field theory of two-layer neural networks: dimension-free bounds and kernel limit , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
The Recurrent Neural Tangent Kernel , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of COMPSTAT'2010 , pages=
Large-Scale Machine Learning with Stochastic Gradient Descent , author=. Proceedings of COMPSTAT'2010 , pages=. 2010 , publisher=
work page 2010
- [33]
-
[34]
Adam: A Method for Stochastic Optimization
Adam: A Method for Stochastic Optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [35]
-
[36]
Journal of Computational Physics , volume=
Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations , author=. Journal of Computational Physics , volume=. 2019 , publisher=
work page 2019
-
[37]
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners , author=. arXiv preprint arXiv:2005.14165 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[38]
Journal of Machine Learning Research , volume=
Automatic Differentiation in Machine Learning: a Survey , author=. Journal of Machine Learning Research , volume=
-
[39]
International Conference on Learning Representations , year=
Gradient Descent Provably Optimizes Over-parameterized Neural Networks , author=. International Conference on Learning Representations , year=
-
[40]
Learning representations by back-propagating errors , author=. Nature , volume=. 1986 , publisher=
work page 1986
-
[41]
Proceedings of COMPSTAT , pages=
Large-Scale Machine Learning with Stochastic Gradient Descent , author=. Proceedings of COMPSTAT , pages=. 2010 , publisher=
work page 2010
- [42]
-
[43]
Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting , author=. 2007 , publisher=
work page 2007
-
[44]
Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition , author=. 2014 , publisher=
work page 2014
-
[45]
Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems , author=. 2001 , publisher=
work page 2001
-
[46]
Context-dependent computation by recurrent dynamics in prefrontal cortex , author=. Nature , volume=. 2013 , publisher=. doi:10.1038/nature12742 , PMID=
-
[47]
Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks , author=. Neural Computation , volume=. 2013 , publisher=. doi:10.1162/NECO\_a\_00409 , PMID=
-
[48]
The Twelfth International Conference on Learning Representations , year=
How connectivity structure shapes rich and lazy learning in neural circuits , author=. The Twelfth International Conference on Learning Representations , year=
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
On Lazy Training in Differentiable Programming , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[50]
Task representations in neural networks trained to perform many cognitive tasks , author=. Nature Neuroscience , volume=. 2019 , doi=
work page 2019
-
[51]
Turner, Elia and Barak, Omri , booktitle =. The Simplicity Bias in Multi-Task RNNs: Shared Attractors, Reuse of Dynamics, and Geometric Representation , url =
-
[52]
Flexible multitask computation in recurrent networks utilizes shared dynamical motifs , author=. Nature Neuroscience , volume=. 2024 , doi=
work page 2024
-
[53]
Open the Black Box of Recurrent Neural Network by Decoding the Internal Dynamics , year=
Tang, Jiacheng and Yin, Hao and Kang, Qi , booktitle=. Open the Black Box of Recurrent Neural Network by Decoding the Internal Dynamics , year=
-
[54]
Current Opinion in Neurobiology , volume=
From lazy to rich to exclusive task representations in neural networks and neural codes , author=. Current Opinion in Neurobiology , volume=. 2023 , doi=
work page 2023
-
[55]
Frontiers in Systems Neuroscience , volume=
Exploring Flip Flop Memories and Beyond: Training Recurrent Neural Networks with Key Insights , author=. Frontiers in Systems Neuroscience , volume=. 2024 , month=. doi:10.3389/fnsys.2024.1269190 , pmid=
-
[56]
Physical Review Letters , volume=
Chaos in random neural networks , author=. Physical Review Letters , volume=. 1988 , publisher=
work page 1988
-
[57]
Physical Review Letters , volume=
Eigenvalue spectra of random matrices for neural networks , author=. Physical Review Letters , volume=. 2006 , publisher=
work page 2006
-
[58]
Generating coherent patterns of activity from chaotic neural networks , author=. Neuron , volume=. 2009 , publisher=
work page 2009
-
[59]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Exponential expressivity in deep neural networks through transient chaos , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[60]
Frontiers in Applied Mathematics and Statistics , volume=
On Lyapunov Exponents for RNNs: Understanding Information Propagation Using Dynamical Systems Tools , author=. Frontiers in Applied Mathematics and Statistics , volume=. 2022 , doi=
work page 2022
-
[61]
Physical Review Letters , volume=
Finite-time Lyapunov exponents of deep neural networks , author=. Physical Review Letters , volume=. 2024 , publisher=
work page 2024
-
[62]
Advances in neural information processing systems , volume=
On the difficulty of learning chaotic dynamics with RNNs , author=. Advances in neural information processing systems , volume=
-
[63]
arXiv preprint arXiv:2402.18377 , year=
Out-of-domain generalization in dynamical systems reconstruction , author=. arXiv preprint arXiv:2402.18377 , year=
-
[64]
Publications Mathématiques de l'IHÉS , volume=
Ergodic theory of differentiable dynamical systems , author=. Publications Mathématiques de l'IHÉS , volume=. 1979 , publisher=
work page 1979
-
[65]
Lecun, Y. and Bottou, L. and Bengio, Y. and Haffner, P. , journal=. Gradient-based learning applied to document recognition , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Which Neural Net Architectures Give Rise To Exploding and Vanishing Gradients? , author=. Advances in Neural Information Processing Systems , volume=. 2018 , publisher=
work page 2018
-
[67]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , author=. arXiv preprint arXiv:1312.6120 , year=
-
[68]
NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning , year=
From Lazy to Rich: Exact Learning Dynamics in Deep Linear Networks , author=. NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning , year=
work page 2024
-
[69]
Nonlinear dimensionality reduction by locally linear embedding , author=. Science , volume=. 2000 , publisher=
work page 2000
-
[70]
Neural constraints on learning , author=. Nature , volume=. 2014 , publisher=. doi:10.1038/nature13665 , url=
-
[71]
Charles R. Harris and K. Jarrod Millman and St. Array programming with. 2020 , month = sep, journal =. doi:10.1038/s41586-020-2649-2 , publisher =
- [72]
-
[73]
Introductory Functional Analysis with Applications , author=. 1989 , publisher=
work page 1989
-
[74]
SciPy 1.0: fundamental algorithms for scientific computing in Python , author=. Nature Methods , volume=. 2020 , publisher=
work page 2020
-
[75]
Proceedings of the 32nd International Conference on Machine Learning , volume=
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author=. Proceedings of the 32nd International Conference on Machine Learning , volume=
-
[76]
Advances in Neural Information Processing Systems , volume=
Understanding Approximate Fisher Information for Fast Convergence of Natural Gradient Descent in Wide Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Fast Neural Tangent Kernel Alignment, Norm and Effective Rank via Trace Estimation , author=. 2025 , eprint=
work page 2025
-
[78]
Advances in Neural Information Processing Systems , volume=
Limitations of the Empirical Fisher Approximation for Natural Gradient Descent , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Paul J. Werbos , title =. Proceedings of the IEEE , volume =. 1990 , doi =
work page 1990
-
[80]
Proceedings of the 38th International Conference on Machine Learning , pages =
Tensor Programs IV: Feature Learning in Infinite-Width Neural Networks , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.