Recognition: 2 theorem links
· Lean TheoremSimReg: Achieving Higher Performance in the Pretraining via Embedding Similarity Regularization
Pith reviewed 2026-05-12 03:28 UTC · model grok-4.3
The pith
SimReg applies embedding similarity regularization to next-token pretraining so that tokens sharing ground-truth labels form tighter clusters and separate from others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an embedding similarity regularization loss, applied by encouraging intra-label similarity and inter-label separation through contrastive terms on tokens that share ground-truth labels within each pretraining sequence, enlarges multi-classification margins. This enables more efficient classification while the model continues to optimize next-token prediction. The effect appears as faster training convergence and stronger zero-shot downstream results across dense and Mixture-of-Experts architectures.
What carries the argument
SimReg, an embedding similarity regularization loss that uses contrastive principles to cluster same-label token representations and separate different-label ones inside each pretraining sequence.
If this is right
- Pretraining converges more than 30 percent faster while the primary next-token objective remains unchanged.
- Average zero-shot performance on standard benchmarks rises by more than 1 percent.
- The same regularization produces gains on both dense transformers and Mixture-of-Experts models.
- Ablation results supply concrete guidance on choosing the regularization weight and temperature.
Where Pith is reading between the lines
- Label assignment could rely on lightweight heuristics such as entity detection or part-of-speech tags rather than expensive supervision.
- The margin-enlargement effect may transfer to other unsupervised objectives that lack explicit classification heads.
- Longer contexts would require careful definition of label consistency across sequence boundaries to preserve the regularization benefit.
Load-bearing premise
Ground-truth labels can be meaningfully assigned to tokens inside each pretraining sequence so the similarity regularization can be applied without interfering with next-token prediction.
What would settle it
If pretraining runs on sequences where no reliable ground-truth labels can be assigned show no measurable change in convergence speed or downstream zero-shot scores, the contribution of the regularization would be falsified.
Figures
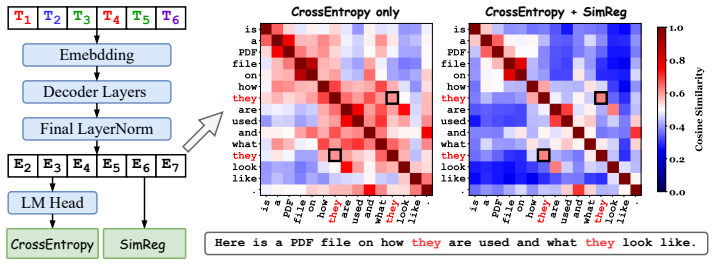






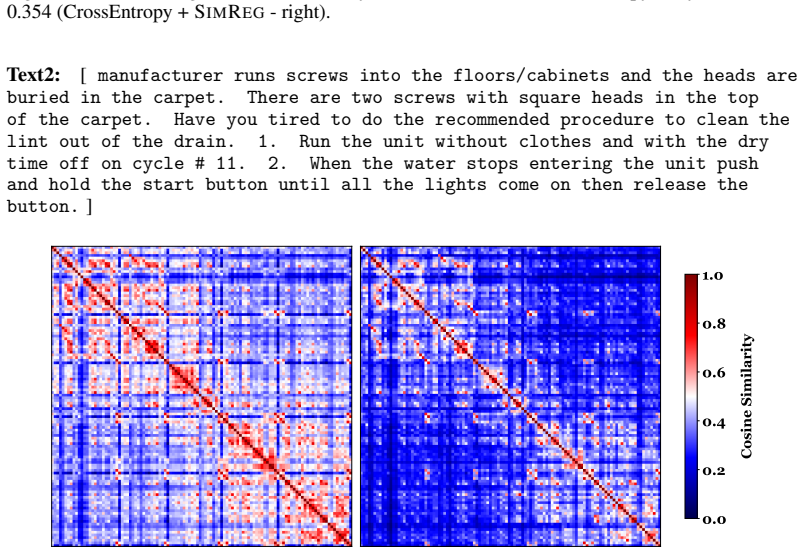
read the original abstract
Pretraining large language models (LLMs) with next-token prediction has led to remarkable advances, yet the context-dependent nature of token embeddings in such models results in high intra-class variance and inter-class similarity, thus hindering the efficiency of representation learning. While similarity-based regularization has demonstrated benefit in supervised fine-tuning and classification tasks, its application and efficacy in large-scale LLM pretraining remains underexplored. In this work, we propose the SimReg, an embedding similarity regularization loss that explicitly encourages token representations with the same ground-truth label within each sequence to be more similar, while enforcing separation from different-label tokens via a contrastive loss. Our analysis reveals that this mechanism introduces gains by enlarging multi-classification margins, thereby enabling more efficient classification. Extensive experiments across dense and Mixture-of-Experts (MoE) architectures demonstrate that SimReg consistently accelerates training convergence by over 30% and improves average zero-shot downstream performance by over 1% across standard benchmarks. Further ablation studies and analyses offer practical insights into hyperparameter tuning and loss effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SimReg, an additive embedding similarity regularization loss for LLM pretraining. It applies a contrastive objective within each sequence that pulls token embeddings sharing the same ground-truth label closer together while pushing apart embeddings with different labels. The authors report that this enlarges multi-classification margins, accelerates convergence by over 30%, and yields more than 1% average improvement in zero-shot downstream performance across dense and Mixture-of-Experts models on standard benchmarks.
Significance. If the labeling step can be shown to be zero-cost and non-interfering with the next-token objective, the approach could offer a practical way to improve representation quality during pretraining. The claimed gains in training speed and downstream accuracy would be substantial for large-scale models, but only if the regularization is reproducible without hidden supervision.
major comments (1)
- The central claim depends on assigning ground-truth labels to tokens inside raw pretraining sequences so that the contrastive term can be computed. Standard next-token corpora supply no such labels. The abstract and method description must specify the exact labeling procedure, demonstrate that it introduces no external supervision or dataset-specific artifacts, and confirm that the core language-modeling loss remains unaltered. Without these details the reported 30% convergence acceleration and >1% zero-shot gains cannot be evaluated or reproduced.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive report. We address the single major comment below and will revise the manuscript to improve clarity and reproducibility as suggested.
read point-by-point responses
-
Referee: The central claim depends on assigning ground-truth labels to tokens inside raw pretraining sequences so that the contrastive term can be computed. Standard next-token corpora supply no such labels. The abstract and method description must specify the exact labeling procedure, demonstrate that it introduces no external supervision or dataset-specific artifacts, and confirm that the core language-modeling loss remains unaltered. Without these details the reported 30% convergence acceleration and >1% zero-shot gains cannot be evaluated or reproduced.
Authors: We agree that the labeling procedure requires explicit description for reproducibility. In the revised manuscript we will expand both the abstract and the Method section to state the exact procedure used to assign ground-truth labels to tokens within each raw pretraining sequence. The procedure operates solely on information already present in the input sequences, introduces no external supervision or dataset-specific artifacts, and leaves the next-token prediction loss completely unchanged; SimReg is implemented strictly as an additive auxiliary term. These additions will make the 30% convergence acceleration and >1% zero-shot gains fully evaluable and reproducible. revision: yes
Circularity Check
No significant circularity; SimReg is an independent additive loss.
full rationale
The paper introduces SimReg as a contrastive regularization term added to next-token prediction. It explicitly conditions on ground-truth labels within sequences to pull same-label embeddings together and push others apart. No equations, derivations, or claims reduce this term to a fitted parameter, self-referential definition, or output of the main objective. No self-citations are invoked as load-bearing uniqueness theorems, and no known empirical pattern is merely renamed. The reported convergence and zero-shot gains are presented as empirical outcomes of the auxiliary loss rather than tautological consequences of its construction. The label-assignment premise is an external modeling choice whose validity is separate from circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lsr_i ≜ log ∑_{j∈N_i} ϕ_{i,j} − log ∑_{j∈P_i} ϕ_{i,j} … final form Li = Lce_i + λ·softplus(Lsr_i)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection / RCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
enlarging multi-classification margins … m_k ≥ m_k + δ∥ϵ+∥ + √2 L_P γ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Next token prediction towards multimodal intelligence: A comprehensive survey
Liang Chen, Zekun Wang, Shuhuai Ren, Lei Li, Haozhe Zhao, Yunshui Li, Zefan Cai, Hongcheng Guo, Lei Zhang, Yizhe Xiong, et al. Next token prediction towards multimodal intelligence: A comprehensive survey. arXiv preprint arXiv:2412.18619,
-
[2]
Ziqing Fan, Yuqiao Xian, Yan Sun, and Li Shen. Joint selection for large-scale pre-training data via policy gradient-based mask learning.arXiv preprint arXiv:2512.24265,
-
[3]
URL https://zenodo.org/records/12608602. Pengzhi Gao, Ruiqing Zhang, Zhongjun He, Hua Wu, and Haifeng Wang. An empirical study of consistency regularization for end-to-end speech-to-text translation.arXiv preprint arXiv:2308.14482,
-
[4]
arXiv preprint arXiv:2104.08821 , year=
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821,
-
[5]
URL https://openreview.net/forum?id=cu7IUiOhujH. Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM Web Conference 2024, pages 103–111,
work page 2024
-
[6]
URL https://api.semanticscholar.org/CorpusID: 236134216. Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Jinhao Li, Jiaming Xu, Shiyao Li, Shan Huang, Jun Liu, Yaoxiu Lian, and Guohao Dai. Fast and efficient 2-bit llm inference on gpu: 2/4/16-bit in a weight matrix with asynchronous dequantization. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, pages 1–9, 2024a. Yingcong Li, Yixiao Huang, Muhammed E Ildiz, Ankit Singh R...
-
[8]
arXiv preprint arXiv:2201.10005 , year=
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al. Text and code embeddings by contrastive pre-training.arXiv preprint arXiv:2201.10005,
-
[9]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[11]
Lida Shi, Fausto Giunchiglia, Rui Song, Daqian Shi, Tongtong Liu, Xiaolei Diao, and Hao Xu. A simple contrastive learning framework for interactive argument pair identification via argument-context extraction. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10027–10039,
work page 2022
-
[12]
Yan Sun, Qixin Zhang, Zhiyuan Yu, Xikun Zhang, Li Shen, and Dacheng Tao. Maskpro: Linear-space probabilistic learning for strict (n: M)-sparsity on large language models.arXiv preprint arXiv:2506.12876,
work page internal anchor Pith review arXiv
-
[13]
Llms are also effective embedding models: An in-depth overview.arXiv preprint arXiv:2412.12591,
11 Chongyang Tao, Tao Shen, Shen Gao, Junshuo Zhang, Zhen Li, Kai Hua, Wenpeng Hu, Zhengwei Tao, and Shuai Ma. Llms are also effective embedding models: An in-depth overview.arXiv preprint arXiv:2412.12591,
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Guoxia Wang, Shuai Li, Congliang Chen, Jinle Zeng, Jiabin Yang, Tao Sun, Yanjun Ma, Dianhai Yu, and Li Shen. Adagc: Improving training stability for large language model pretraining.arXiv preprint arXiv:2502.11034,
-
[16]
Do generated data always help contrastive learning?arXiv preprint arXiv:2403.12448,
Yifei Wang, Jizhe Zhang, and Yisen Wang. Do generated data always help contrastive learning?arXiv preprint arXiv:2403.12448,
-
[17]
Peilin Zhou, You-Liang Huang, Yueqi Xie, Jingqi Gao, Shoujin Wang, Jae Boum Kim, and Sunghun Kim. Is contrastive learning necessary? a study of data augmentation vs contrastive learning in sequential recommen- dation. InProceedings of the ACM Web Conference 2024, pages 3854–3863,
work page 2024
-
[18]
12 A Appendix: Experiments A.1 Experimental Setups Here we present the detailed experimental setups in this paper to ensure the reproducibility. Model Hyperparameters.We mainly select LLaMA2 [Touvron et al., 2023] and Mixtral [Jiang et al., 2024] as the dense and MoE backbones for pretraining, including the core modules of the mainstream models in the cur...
work page 2023
-
[19]
Table 4: Model Hyperparameters. Experts Layers Attention heads Embedding dim FFN hidden size LLaMA2-350M 1 24 16 1024 2371 LLaMA2-1.3B 1 24 32 2048 5461 LLaMA2-3B 1 26 32 3072 8640 LLaMA2-7B 1 32 32 4096 11008 Mixtral-8×1B 8 24 32 2048 5632 Training Hyperparameters.We follow the experimental setups reported in several recent classical LLM pretraining stud...
work page 2048
-
[20]
Table 5: Training Hyperparameters. batchsize seqlen learning rateλ w β1 β2 clip-λclip-β LLaMA-350M 512 2048 4e-4→4e-5 0.1 0.9 0.95 1.04 0.99 LLaMA-1.3B 2048 2048 3e-4→3e-5 0.1 0.9 0.95 1.04 0.99 LLaMA-3B 2048 2048 3e-4→3e-5 0.1 0.9 0.95 1.04 0.99 LLaMA-7B 2048 2048 3e-4→3e-5 0.1 0.9 0.95 1.04 0.99 Mixtral-8×1B 512 2048 3e-4→3e-5 0.1 0.9 0.95 1.04 0.99 Spe...
work page 2048
-
[21]
λreg = 0(baseline) 15.06 10.72 9.70 8.99 λreg = 5 14.36 10.46 9.50 8.92 λreg = 10 14.25 10.41 9.46 8.84 λreg = 20 14.29 10.429.44 8.78 λreg = 50 14.33 10.49 9.49 8.81 It can be observed that the trend largely aligns with our hypothesis. Therefore, we propose the following estimation method for the optimal hyperparameters: τ= 0.01, λ reg ≈10× r d 1024 , wh...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.