Recognition: no theorem link
How You Begin is How You Reason: Driving Exploration in RLVR via Prefix-Tuned Priors
Pith reviewed 2026-05-12 03:20 UTC · model grok-4.3
The pith
Training soft prefixes with an information-maximization reward reshapes the prior over reasoning trajectories to drive better exploration in RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
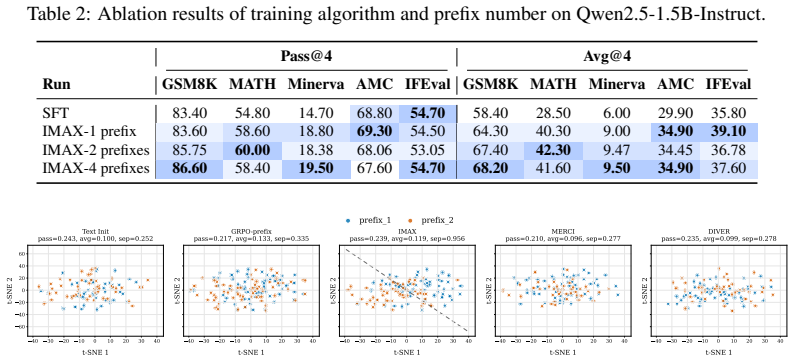
The central claim is that a pool of trainable soft prefixes can reshape the base model's prior over reasoning trajectories so that each prefix induces a distinct rollout distribution. Training these prefixes with a derived Information Maximization reward alongside the verifiable reward encourages the discovery of diverse and task-relevant reasoning behaviors. The resulting IMAX framework integrates directly into standard RLVR pipelines and yields consistent improvements in reasoning metrics.
What carries the argument
A pool of soft prefixes, each serving as a trainable control knob that induces a distinct rollout distribution from the fixed backbone, optimized via an Information Maximization reward.
If this is right
- IMAX delivers gains of up to 11.60% in Pass@4 and 10.57% in Avg@4 over baseline RLVR.
- Performance lifts appear consistently across three different backbone scales.
- The framework slots into existing RLVR training loops without altering the core algorithm.
- Entropy collapse is mitigated by expanding the set of successful reasoning trajectories that receive positive reward.
Where Pith is reading between the lines
- The same prefix mechanism might be repurposed to steer other controllable aspects of LLM output, such as reasoning depth or verification style.
- If prefixes act as strong priors, then carefully chosen initialization distributions could reduce the sample complexity of RLVR on new tasks.
- The approach raises the question of whether the number and diversity of prefixes can be scaled adaptively during training to match task difficulty.
Load-bearing premise
The information-maximization reward will produce diverse, task-relevant reasoning behaviors from the soft prefixes without adding excessive noise or lowering rollout quality.
What would settle it
A direct comparison showing that IMAX produces no increase in the number of unique successful reasoning trajectories (or a drop in generation quality) relative to standard RLVR would falsify the claim that the prefix-tuned priors improve exploration.
Figures





read the original abstract
Reinforcement learning with verifiable rewards (RLVR) recently thrives in large language model (LLM) reasoning tasks. However, the reward sparsity and the long reasoning horizon make effective exploration challenging. In practice, this challenge manifests as the \emph{entropy collapse} phenomenon, where RLVR improves single-rollout accuracy but fails to expand coverage on successful reasoning trajectories. Passive exploration techniques like entropy regularization tend to dismiss generation quality, resulting in noisy rollouts. In response to this issue, we propose an Information-Maximizing Augmented eXploration (IMAX) framework to train a pool of soft prefixes that reshapes the base model's prior over reasoning trajectories. Rather than relying on RL to incentivize exploration on top of the base model, each prefix acts as a trainable control knob that induces a distinct rollout distribution from the same backbone model. To encourage discovery of diverse and task-relevant reasoning behaviors, we derive an Information Maximization (InfoMax) reward to complement the verifiable rewards for RL training. IMAX is in general algorithm-agnostic and can be seamlessly integrated into existing RLVR pipelines. Experiment results have shown that across three backbone scales, IMAX consistently improves reasoning performance over standard RLVR, with gains up to 11.60\% in Pass@4 and 10.57\% in Avg@4.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Information-Maximizing Augmented eXploration (IMAX) framework to address entropy collapse in Reinforcement Learning with Verifiable Rewards (RLVR) for LLM reasoning. It trains a pool of soft prefixes that reshape the base model's prior over reasoning trajectories, each acting as a trainable control knob inducing distinct rollout distributions. An Information Maximization (InfoMax) reward is derived to complement verifiable rewards and encourage diverse, task-relevant behaviors. The method is claimed to be algorithm-agnostic and integrable into existing RLVR pipelines, with experiments across three backbone scales reporting consistent improvements, including gains up to 11.60% in Pass@4 and 10.57% in Avg@4 over standard RLVR.
Significance. If the InfoMax reward derivation is shown to be non-circular and the empirical gains are robust under proper controls, this work could meaningfully advance exploration techniques in RLVR by providing an active, prefix-based mechanism to expand coverage of successful reasoning trajectories without the quality degradation associated with passive entropy regularization. The algorithm-agnostic framing and reported cross-scale consistency would position it as a practical addition to existing pipelines, with potential implications for improving reasoning coverage in LLMs.
major comments (3)
- [Abstract] Abstract: The abstract states that an Information Maximization (InfoMax) reward is derived to complement verifiable rewards for RL training, but provides no equations, derivation steps, or balancing mechanism with the verifiable reward. This is load-bearing for the central claim that the reward reliably induces diverse task-relevant behaviors from the soft prefixes rather than superficial diversity or noisy rollouts.
- [Experiments] Experiments (results paragraph): The reported gains of up to 11.60% Pass@4 and 10.57% Avg@4 are presented without any description of the experimental setup, baselines, number of runs, statistical tests, or ablations that isolate the InfoMax reward contribution from prefix training alone or from increased effective compute. This prevents verification that the improvements arise from the proposed exploration mechanism.
- [§3] §3 (method): The integration of the pool of soft prefixes into RLVR pipelines is described at a high level, but no analysis is given of how the InfoMax objective interacts with the verifiable reward during training or whether it can degrade generation quality in rollouts, which directly affects the assumption that prefixes induce relevant reasoning behaviors.
minor comments (2)
- [§3] Clarify the exact parameterization and training procedure for the 'pool of soft prefixes' (e.g., how many prefixes, initialization, and optimization details) to improve reproducibility.
- [§2] Add a dedicated related-work subsection contrasting IMAX with prior entropy-regularization and prefix-tuning approaches in RL for LLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, clarifying existing content in the manuscript and indicating revisions where appropriate to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that an Information Maximization (InfoMax) reward is derived to complement verifiable rewards for RL training, but provides no equations, derivation steps, or balancing mechanism with the verifiable reward. This is load-bearing for the central claim that the reward reliably induces diverse task-relevant behaviors from the soft prefixes rather than superficial diversity or noisy rollouts.
Authors: We agree the abstract is high-level and omits details on the derivation. The full derivation of the InfoMax reward as mutual information between the soft prefix and the reasoning trajectory (I(prefix; trajectory)) appears in Section 3.2, with the balancing mechanism implemented as a weighted sum R_total = R_verifiable + λ * R_InfoMax where λ is a tunable hyperparameter. We will revise the abstract to include a brief textual description of this complementary structure and the role of λ in controlling the exploration-quality trade-off. revision: partial
-
Referee: [Experiments] Experiments (results paragraph): The reported gains of up to 11.60% Pass@4 and 10.57% Avg@4 are presented without any description of the experimental setup, baselines, number of runs, statistical tests, or ablations that isolate the InfoMax reward contribution from prefix training alone or from increased effective compute. This prevents verification that the improvements arise from the proposed exploration mechanism.
Authors: The manuscript's Experiments section (Section 4) details the setup across three model scales, baselines (standard RLVR, entropy regularization, and prefix-only variants), 5 independent runs with mean and std. dev. reporting, t-test statistical significance, and ablations in Section 4.3 that isolate the InfoMax reward from prefix training and compute effects. We will update the results paragraph to concisely reference these elements, including a pointer to the ablation table and hyperparameter details. revision: yes
-
Referee: [§3] §3 (method): The integration of the pool of soft prefixes into RLVR pipelines is described at a high level, but no analysis is given of how the InfoMax objective interacts with the verifiable reward during training or whether it can degrade generation quality in rollouts, which directly affects the assumption that prefixes induce relevant reasoning behaviors.
Authors: Section 3.3 and 3.4 describe the integration as algorithm-agnostic and provide analysis of the combined objective, showing via gradient decomposition that the InfoMax term expands trajectory coverage without circularity (it operates on the prefix-conditioned distribution independently of the verifiable reward). Experiments include quality metrics (perplexity, sequence coherence) showing no degradation. We will expand Section 3 with a new subsection on reward interaction, including training dynamics plots and a short argument against circularity. revision: yes
Circularity Check
No circularity: derivation of InfoMax reward presented as independent complement to verifiable rewards
full rationale
The paper states it derives an Information Maximization (InfoMax) reward to complement verifiable rewards for RL training of soft prefixes, with IMAX claimed algorithm-agnostic and empirically validated across backbone scales. No equations, self-citations, or reduction steps are visible in the provided text that would make the reward equivalent to its inputs by construction (e.g., no fitted parameter renamed as prediction or ansatz smuggled via prior self-work). The central claim rests on the derivation having independent grounding to induce task-relevant diversity, and the empirical gains are presented separately from any definitional loop. This is the common honest case of a self-contained proposal without detectable circularity in the derivation chain.
Axiom & Free-Parameter Ledger
invented entities (1)
-
pool of soft prefixes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bizhe Bai, Xinyue Wang, Peng Ye, and Tao Chen. Learning to explore with parameter-space noise: A deep dive into parameter-space noise for reinforcement learning with verifiable rewards. arXiv preprint arXiv:2602.02555, 2026
-
[2]
Blei, Alp Kucukelbir, and Jon D
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Variational inference: A review for statisticians.Journal of the American Statistical Association, 112(518):859–877, 2017
work page 2017
-
[3]
arXiv preprint arXiv:2504.11468 , year=
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
-
[4]
Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, et al. Seed-prover: Deep and broad reasoning for automated theorem proving.arXiv preprint arXiv:2507.23726, 2025
-
[5]
Infogan: Interpretable representation learning by information maximizing generative adversarial nets
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29, 2016
work page 2016
-
[6]
Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, et al. An empirical study on eliciting and improving r1-like reasoning models.arXiv preprint arXiv:2503.04548, 2025
-
[7]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P. Xing, and Zhiting Hu. RLPrompt: Optimizing discrete text prompts with reinforcement learning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369–3391, 2022
work page 2022
-
[12]
Jingchu Gai, Guanning Zeng, Huaqing Zhang, and Aditi Raghunathan. Differential smoothing mitigates sharpening and improves llm reasoning.arXiv preprint arXiv:2511.19942, 2025
-
[13]
arXiv preprint arXiv:2505.17621 , year=
Jingtong Gao, Ling Pan, Yejing Wang, Rui Zhong, Chi Lu, Maolin Wang, Qingpeng Cai, Peng Jiang, and Xiangyu Zhao. Navigate the unknown: Enhancing llm reasoning with intrinsic motivation guided exploration.arXiv preprint arXiv:2505.17621, 2025
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Diversity-incentivized exploration for versatile reasoning
Zican Hu, Shilin Zhang, Yafu Li, Jianhao Yan, Xuyang Hu, Leyang Cui, Xiaoye Qu, Chunlin Chen, Yu Cheng, and Zhi Wang. Diversity-incentivized exploration for versatile reasoning. arXiv preprint arXiv:2509.26209, 2025. 10
-
[17]
Guanhua Huang, Tingqiang Xu, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Ke- jiao Li, Yuhao Jiang, and Bo Zhou. Low-probability tokens sustain exploration in reinforcement learning with verifiable reward.arXiv preprint arXiv:2510.03222, 2025
-
[18]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901, 2025
-
[20]
arXiv preprint arXiv:2502.21321
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Fahad Shahbaz Khan, and Salman Khan. Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321, 2025
-
[21]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, 2021
work page 2021
-
[22]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[23]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers), pages 4582–4597, 2021
work page 2021
-
[24]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[25]
P- Tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P- Tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 61–68, 2022
work page 2022
-
[26]
Aleksandar Petrov, Philip H. S. Torr, and Adel Bibi. When do prompting and prefix-tuning work? a theory of capabilities and limitations. InInternational Conference on Learning Representations, 2024
work page 2024
-
[27]
Learning how to ask: Querying LMs with mixtures of soft prompts
Guanghui Qin and Jason Eisner. Learning how to ask: Querying LMs with mixtures of soft prompts. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5203–5212, 2021
work page 2021
-
[28]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
work page 2023
-
[29]
Devan Shah, Owen Yang, Daniel Yang, Chongyi Zheng, and Benjamin Eysenbach. Upskill: Mutual information skill learning for structured response diversity in llms.arXiv preprint arXiv:2602.22296, 2026
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Logan IV , Eric Wallace, and Sameer Singh
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV , Eric Wallace, and Sameer Singh. Auto- Prompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 4222–4235, 2020
work page 2020
-
[32]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11909–11919, 2023
work page 2023
-
[34]
Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy, 2026
Hongze Tan, Zihan Wang, Jianfei Pan, Jinghao Lin, Hao Wang, Yifan Wu, Tao Chen, Zhihang Zheng, Zhihao Tang, and Haihua Yang. Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy.arXiv preprint arXiv:2508.04349, 2025
-
[35]
SPoT: Better frozen model adaptation through soft prompt transfer
Tu Vu, Brian Lester, Noah Constant, Rami Al-Rfou, and Daniel Cer. SPoT: Better frozen model adaptation through soft prompt transfer. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 5039–5059, 2022
work page 2022
-
[36]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision, pages 631–648. Springer, 2022
work page 2022
-
[38]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
work page 2022
-
[39]
arXiv preprint arXiv:2507.14843 , year=
Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
-
[40]
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data.arXiv preprint arXiv:2405.14333, 2024
-
[41]
Towards large reasoning models: A survey of reinforced reasoning with large language models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, et al. Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprint arXiv:2501.09686, 2025
-
[42]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models.Advances in Neural Information Processing Systems, 36: 21573–21612, 2023
work page 2023
-
[46]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[47]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Xuan Zhang, Ruixiao Li, Zhijian Zhou, Long Li, Yulei Qin, Ke Li, Xing Sun, Xiaoyu Tan, Chao Qu, and Yuan Qi. Count counts: Motivating exploration in llm reasoning with count-based intrinsic rewards.arXiv preprint arXiv:2510.16614, 2025
-
[51]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
First return, entropy-eliciting explore, 2025
Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, Qian Liu, Ge Zhang, and Zejun Ma. First return, entropy-eliciting explore.arXiv preprint arXiv:2507.07017, 2025
-
[53]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surpris- ing effectiveness of negative reinforcement in llm reasoning.arXiv preprint arXiv:2506.01347, 2025. 13 Appendix A Complete Related Works We first review RLVR algorithms for LLM reasoning and then discuss the exploration challenge in RLVR. We next introduce soft prompt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.