Recognition: no theorem link
Mental Health AI Safety Claims Must Preserve Temporal Evidence
Pith reviewed 2026-05-12 03:09 UTC · model grok-4.3
The pith
Safety evaluations for mental health AI cannot certify properties that depend on conversation sequence or accumulation if they discard temporal structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
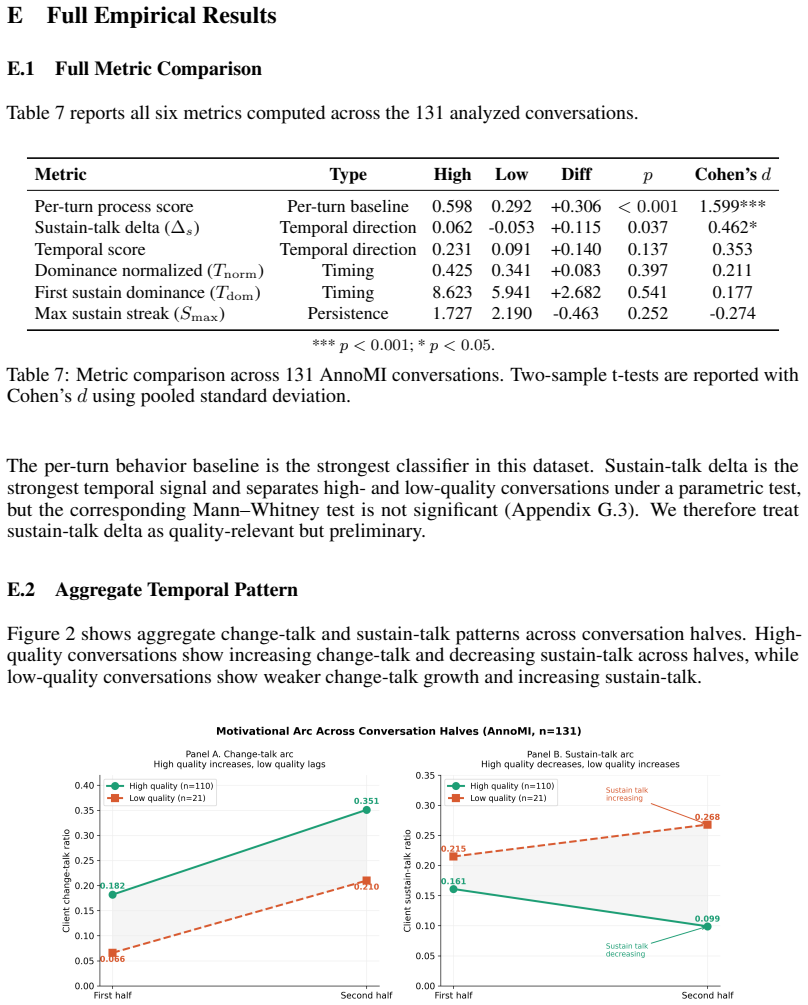
The paper claims that safety properties depending on sequence, timing, accumulation, or recovery cannot be certified by protocols that discard those features. It formalizes this limitation as Temporal Safety Non-Identifiability and derives the SCOPE principle requiring that safety claims match the temporal evidence an evaluation actually keeps. SCOPE-MH applies this to mental health dialogues, and its use on the AnnoMI dataset surfaces mechanisms such as dependency formation and failed repair that standard scoring does not represent. The authors conclude that evaluation preserving temporal evidence is necessary for safety-critical mental health AI deployment.
What carries the argument
Temporal Safety Non-Identifiability, the formal account showing why sequence-dependent or accumulation-dependent safety properties cannot be certified from evaluations that remove order and timing information.
If this is right
- Current per-turn or endpoint scoring methods can yield invalid safety certifications for properties that unfold over multiple turns.
- Mental health AI deployment requires evaluation protocols that retain full interaction sequences rather than summaries or single responses.
- SCOPE-MH supplies a reporting standard that forces explicit alignment between a safety claim and the temporal evidence retained.
- Analysis of existing annotated dialogue datasets such as AnnoMI can expose failure mechanisms missed by conventional metrics.
- Safety claims for mental health AI must be treated as provisional until temporal-preserving evidence is supplied.
Where Pith is reading between the lines
- The same temporal non-identifiability issue likely appears in other long-horizon AI interaction settings, such as chronic care chatbots or educational tutors.
- New datasets that record complete conversation histories with outcome labels would allow direct tests of whether temporal preservation alters safety verdicts.
- Regulatory frameworks for healthcare AI could incorporate requirements for temporal evidence retention as a condition for certification.
- Model training objectives might need explicit penalties for sequence-level patterns that current per-turn losses overlook.
Load-bearing premise
Clinically consequential failures in mental health AI arise primarily from the order and accumulation of interactions rather than from isolated responses or aggregate quality.
What would settle it
A controlled comparison on the same set of mental health conversations in which adding full temporal history to the evaluation produces a different safety conclusion than per-turn or aggregate scoring, with the difference traceable to a documented clinical outcome.
Figures


read the original abstract
The safety of mental health AI is often judged at the wrong temporal scale. Current evaluations typically score isolated responses, endpoint outcomes, or aggregate dialogue quality, while clinically consequential failures may arise from the order and accumulation of interactions themselves, including delayed escalation, repeated reinforcement, dependency formation, failed repair, and gradual deterioration across turns. This paper argues that this mismatch is not merely a limitation of evaluation coverage but a source of invalid safety conclusions. We introduce Temporal Safety Non-Identifiability, a formal account of why safety properties that depend on sequence, timing, accumulation, or recovery cannot be certified by protocols that discard those features. From this formalization, we develop SCOPE (Safety Claims Over Preserved Evidence) as a general principle for aligning safety claims with the evidence an evaluation actually retains, and instantiate it as SCOPE-MH, a mental-health instantiation of this reporting standard. We operationalize SCOPE-MH through a proof-of-concept on the AnnoMI dataset of expert-annotated motivational interviewing conversations, which reveals mechanisms of failure that per-turn behavior scoring does not represent. We propose SCOPE-MH as a diagnostic complement to existing evaluation infrastructure and argue that evaluation preserving temporal evidence is necessary, not optional, for safety-critical mental health AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that safety evaluations for mental health AI typically assess isolated responses, endpoint outcomes, or aggregate dialogue quality, but clinically relevant failures often depend on sequence, timing, accumulation, recovery, delayed escalation, repeated reinforcement, or gradual deterioration. It introduces Temporal Safety Non-Identifiability as a formal account of why such properties cannot be certified by protocols that discard temporal features. From this, the paper derives the SCOPE principle for aligning safety claims with retained evidence and instantiates it as SCOPE-MH, which is then demonstrated via a proof-of-concept on the AnnoMI dataset of expert-annotated motivational interviewing conversations that reveals failure mechanisms invisible to per-turn scoring.
Significance. If the formalization can be strengthened beyond a definitional observation, the work could usefully highlight a structural limitation in current evaluation practices for safety-critical mental health AI. The conceptual framing and AnnoMI illustration draw attention to the mismatch between temporal dependence in clinical interactions and static or aggregated metrics, which may encourage more appropriate reporting standards. The proof-of-concept is presented as diagnostic rather than conclusive, so its influence would depend on subsequent quantitative validation.
major comments (2)
- [Formal account of Temporal Safety Non-Identifiability] The formalization of Temporal Safety Non-Identifiability (introduced after the abstract) reduces to the definitional statement that a property P defined over full history H is not recoverable from a projection whenever P is not constant on the fibers of that projection. No additional structure—such as a parameterized family of failure modes, an information-loss bound, or a proof that clinically relevant P cannot be approximated by any statistic of the discarded data—is supplied. This makes the central claim immediate from the definitions rather than a non-trivial identifiability result that would constrain existing protocols.
- [Proof-of-concept on the AnnoMI dataset] The AnnoMI proof-of-concept illustrates mechanisms of failure not captured by per-turn behavior scoring, but provides no quantitative comparison (e.g., certification error rates, divergence in safety conclusions, or statistical tests) showing that temporal preservation materially changes safety verdicts under current protocols. Without such metrics or an error analysis, the example remains illustrative and does not yet establish that the identified mechanisms produce certification errors in practice.
minor comments (1)
- [Abstract and introduction] The abstract and introduction could more explicitly separate the conceptual argument from the empirical component so readers can assess the strength of each independently.
Simulated Author's Rebuttal
We thank the referee for the constructive and precise feedback. The comments correctly identify opportunities to strengthen both the formal account and the empirical illustration. We respond to each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Formal account of Temporal Safety Non-Identifiability] The formalization of Temporal Safety Non-Identifiability (introduced after the abstract) reduces to the definitional statement that a property P defined over full history H is not recoverable from a projection whenever P is not constant on the fibers of that projection. No additional structure—such as a parameterized family of failure modes, an information-loss bound, or a proof that clinically relevant P cannot be approximated by any statistic of the discarded data—is supplied. This makes the central claim immediate from the definitions rather than a non-trivial identifiability result that would constrain existing protocols.
Authors: We agree that the initial formalization is definitional in character. In the revised manuscript we will augment the section with a parameterized family of temporal failure modes (delayed escalation, cumulative reinforcement, failed repair sequences) together with an explicit information-loss bound showing that, for these modes, no statistic of the non-temporal projection can achieve bounded approximation error. This addition will make the non-identifiability result more constraining for existing evaluation protocols. revision: yes
-
Referee: [Proof-of-concept on the AnnoMI dataset] The AnnoMI proof-of-concept illustrates mechanisms of failure not captured by per-turn behavior scoring, but provides no quantitative comparison (e.g., certification error rates, divergence in safety conclusions, or statistical tests) showing that temporal preservation materially changes safety verdicts under current protocols. Without such metrics or an error analysis, the example remains illustrative and does not yet establish that the identified mechanisms produce certification errors in practice.
Authors: We accept that the current AnnoMI analysis is illustrative. In revision we will add quantitative diagnostics: the fraction of dialogues in which temporal analysis flags safety issues missed by per-turn scoring, and a simple divergence measure between temporal and non-temporal safety verdicts. A full statistical error analysis with ground-truth temporal labels would require a larger annotated corpus; we will note this limitation and present the available quantitative indicators from the existing dataset. revision: partial
Circularity Check
Temporal Safety Non-Identifiability reduces to a definitional observation without a non-trivial identifiability theorem
specific steps
-
self definitional
[Abstract]
"We introduce Temporal Safety Non-Identifiability, a formal account of why safety properties that depend on sequence, timing, accumulation, or recovery cannot be certified by protocols that discard those features."
The formal account is presented as deriving the non-certifiability conclusion, yet the conclusion holds tautologically once a property is defined to depend on the discarded temporal features and the evaluation protocol is defined to retain only their projection; no non-trivial identifiability theorem, uniqueness result, or bound on approximation error is supplied beyond this definitional equivalence.
full rationale
The paper's core derivation introduces Temporal Safety Non-Identifiability as a formal account explaining why sequence-dependent safety properties cannot be certified from protocols that discard temporal features. This account, however, follows immediately from the definitions of the property (as depending on full history) and the protocol (as discarding it), without additional structure such as a parameterized failure model, information-loss bound, or proof that clinically relevant properties resist approximation by any retained statistic. SCOPE and its mental-health instantiation are then derived directly from this premise, rendering the central safety claim self-contained within the initial definitional framing rather than supported by independent theorem or external evidence. The AnnoMI proof-of-concept illustrates mechanisms but does not independently establish or quantify the non-identifiability.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Clinically consequential failures in mental health AI arise from sequence, timing, accumulation, or recovery across interactions
- domain assumption Safety claims are valid only when the retained evidence matches the temporal scope of the property being certified
invented entities (2)
-
Temporal Safety Non-Identifiability
no independent evidence
-
SCOPE-MH
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[2]
Ratna Kandala, Niva Manchanda, Akshata Kishore Moharir, and Ananth Kandala
doi: 10.1002/wps.21352. Ratna Kandala, Niva Manchanda, Akshata Kishore Moharir, and Ananth Kandala. Echoguard: An agentic framework with knowledge-graph memory for detecting manipulative communication in longitudinal dialogue.arXiv preprint arXiv:2603.04815,
-
[3]
MHSafeEval: Role-Aware Interaction-Level Evaluation of Mental Health Safety in Large Language Models
Suhyun Lee, Palakorn Achananuparp, Neemesh Yadav, Ee-Peng Lim, and Yang Deng. Mhsafeeval: Role-aware interaction-level evaluation of mental health safety in large language models.arXiv preprint arXiv:2604.17730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2506.08584 (2025)
Yahan Li, Jifan Yao, John Bosco S Bunyi, Adam C Frank, Angel Hsing-Chi Hwang, and Ruishan Liu. Counselbench: a large-scale expert evaluation and adversarial benchmarking of large language models in mental health question answering.arXiv preprint arXiv:2506.08584,
-
[5]
Holistic Evaluation of Language Models
URLhttps://arxiv.org/abs/2211.09110. Ryan K McBain, Robert Bozick, Melissa Diliberti, Li Ang Zhang, Fang Zhang, Alyssa Burnett, Aaron Kofner, Benjamin Rader, Joshua Breslau, Bradley D Stein, et al. Use of generative ai for mental health advice among us adolescents and young adults.JAMA Network Open, 8(11): e2542281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https: //mental.jmir.org/2026/1/e91454
doi: 10.2196/91454. URL https: //mental.jmir.org/2026/1/e91454. Theresa B. Moyers, L. N. Rowell, Jennifer K. Manuel, Denise Ernst, and Jon M. Houck. The motivational interviewing treatment integrity code (MITI 4): Rationale, preliminary reliability and validity.Journal of Substance Abuse Treatment, 65:36–42,
-
[7]
Harold Ngabo-Woods, Larisa Dunai, and Isabel Seguí Verdú
doi: 10.1016/j.jsat.2016.01.001. Harold Ngabo-Woods, Larisa Dunai, and Isabel Seguí Verdú. A prognostic theory of treatment response for major depressive disorder: A dynamic systems framework for forecasting clinical trajectories.Applied Sciences,
-
[8]
URL https://api.semanticscholar.org/CorpusID: 283371129. Jung In Park, Mahyar Abbasian, Iman Azimi, Dawn T Bounds, Angela Jun, Jaesu Han, Robert M McCarron, Jessica Borelli, Parmida Safavi, Sanaz Mirbaha, et al. Building trust in mental health chatbots: safety metrics and llm-based evaluation tools.arXiv preprint arXiv:2408.04650,
-
[9]
doi: 10.1037/pri0000292. Advance online publication. Heather Stringer. Ai, neuroscience, and data are fueling personalized mental health care.Monitor on Psychology, 57(1):56, January/February
-
[10]
URL https://www.apa.org/monitor/2026/ 01-02/trends-personalized-mental-health-care. Michael Tanana, Kevin A. Hallgren, Zac E. Imel, David C. Atkins, and Vivek Srikumar. A comparison of natural language processing methods for automated coding of motivational interviewing.Journal of Substance Abuse Treatment, 65:43–50,
work page 2026
-
[11]
doi: 10.1016/j.jsat.2016.01.006. 10 Zixiu Wu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Ehud Reiter, Diego Reforgiato Recupero, and Daniele Riboni. Anno-mi: A dataset of expert-annotated counselling dialogues. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE,
-
[12]
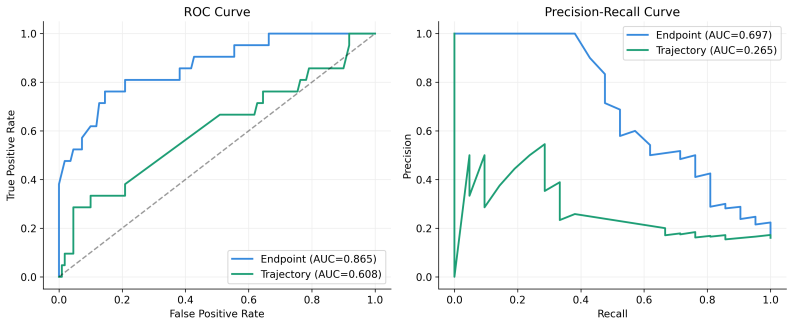
These curves confirm that the per-turn behavior baseline remains the stronger classifier overall, while the temporal signal behaves as a more selective audit trigger at the selected full-conversation threshold. 18 Figure 3: ROC and precision-recall curves on AnnoMI ( n= 131 ). In the plot legend, “Endpoint” refers to the per-turn behavior baseline, and “T...
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.