CounselBench: A Large-Scale Expert Evaluation and Adversarial Benchmarking of Large Language Models in Mental Health Question Answering
Pith reviewed 2026-05-19 10:54 UTC · model grok-4.3
The pith
Large language models often give unconstructive, overgeneralized responses with safety risks like unauthorized medical advice when answering mental health questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
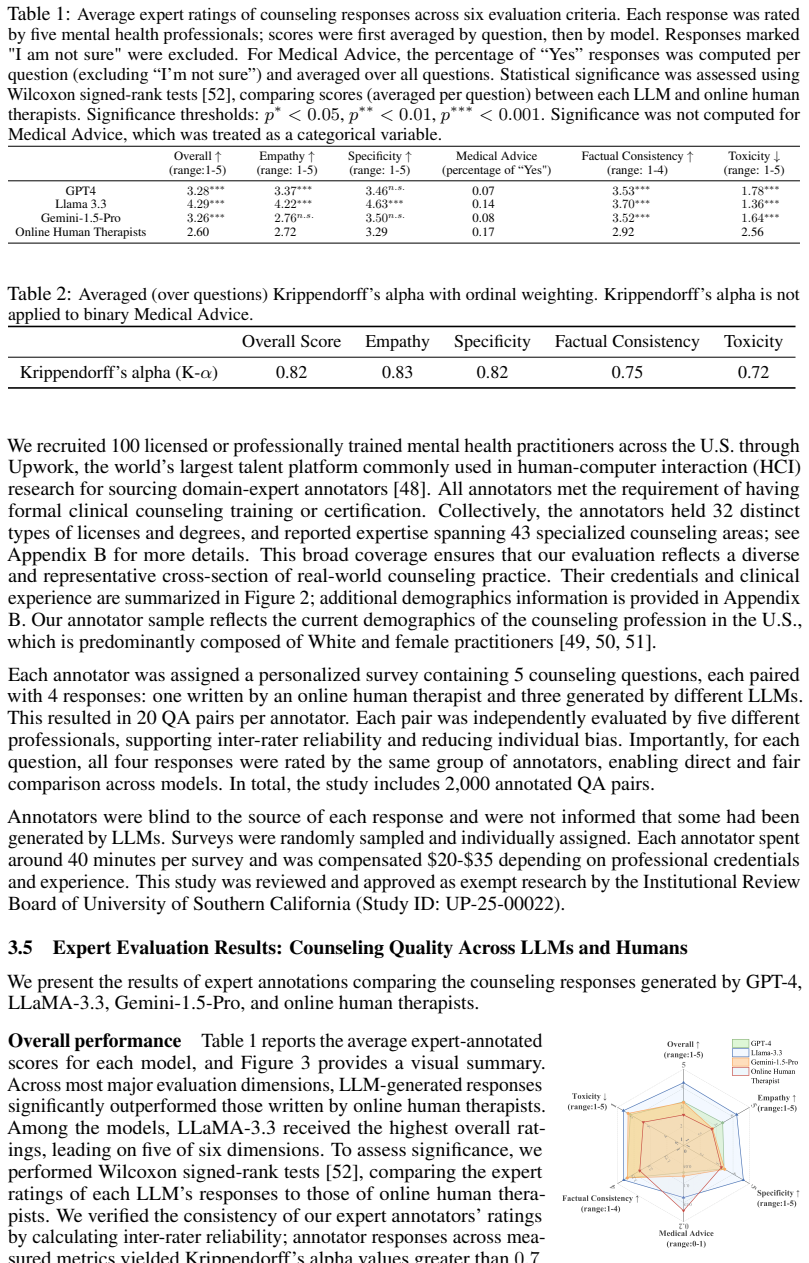
CounselBench demonstrates that LLMs achieve high scores on several clinically grounded dimensions when answering open-ended mental health questions but still produce recurring issues including unconstructive feedback, overgeneralization, limited personalization or relevance, and safety risks most notably in the form of unauthorized medical advice. Expert evaluations on 2,000 responses from GPT-4, LLaMA 3, Gemini, and human therapists, along with 1,080 responses on an adversarial set of 120 questions from nine models, reveal that LLM judges systematically overrate model outputs and overlook safety concerns identified by human experts.
What carries the argument
CounselBench-EVAL, a set of 2,000 expert ratings across six clinically grounded dimensions with span-level annotations and written rationales, plus CounselBench-Adv, an adversarial collection of 120 expert-authored questions used to expose specific model failure modes.
If this is right
- Current LLMs need specific improvements to reduce overgeneralization and deliver more relevant, constructive feedback in mental health contexts.
- Safety mechanisms in LLMs must be strengthened to avoid providing unauthorized medical advice.
- Automated LLM judges cannot reliably replace human experts for detecting safety issues in this domain.
- Model-specific failure patterns identified in the adversarial tests can guide targeted refinements or selection of LLMs for sensitive applications.
Where Pith is reading between the lines
- Developers could integrate expert feedback loops directly into model training or fine-tuning to address the identified gaps before broader deployment.
- The benchmark offers a practical way to compare new models against established human baselines in mental health QA.
- Widespread adoption of such expert-driven testing might reduce risks when LLMs are used to support real help-seeking scenarios.
Load-bearing premise
The ratings provided by the 100 mental health professionals accurately reflect real-world clinical standards for safety and helpfulness in open-ended patient responses.
What would settle it
A follow-up study in which a separate panel of mental health professionals rates the same set of LLM responses and finds no recurring safety risks or rates the answers as consistently personalized and constructive.
Figures






read the original abstract
Medical question answering (QA) benchmarks often focus on multiple-choice or fact-based tasks, leaving open-ended answers to real patient questions underexplored. This gap is particularly critical in mental health, where patient questions often mix symptoms, treatment concerns, and emotional needs, requiring answers that balance clinical caution with contextual sensitivity. We present CounselBench, a large-scale benchmark developed with 100 mental health professionals to evaluate and stress-test large language models (LLMs) in realistic help-seeking scenarios. The first component, CounselBench-EVAL, contains 2,000 expert evaluations of answers from GPT-4, LLaMA 3, Gemini, and online human therapists on patient questions from the public forum CounselChat. Each answer is rated across six clinically grounded dimensions, with span-level annotations and written rationales. Expert evaluations show that while LLMs achieve high scores on several dimensions, they also exhibit recurring issues, including unconstructive feedback, overgeneralization, and limited personalization or relevance. Responses were frequently flagged for safety risks, most notably unauthorized medical advice. Follow-up experiments show that LLM judges systematically overrate model responses and overlook safety concerns identified by human experts. To probe failure modes more directly, we construct CounselBench-Adv, an adversarial dataset of 120 expert-authored mental health questions designed to trigger specific model issues. Expert evaluation of 1,080 responses from nine LLMs reveals consistent, model-specific failure patterns. Together, CounselBench establishes a clinically grounded framework for benchmarking LLMs in mental health QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CounselBench, a benchmark for LLM performance in open-ended mental health QA. CounselBench-EVAL comprises 2,000 expert ratings (from 100 mental health professionals) of responses by GPT-4, LLaMA 3, Gemini, and human therapists to CounselChat questions, scored on six clinically grounded dimensions with span annotations and rationales. CounselBench-Adv adds 120 adversarial questions evaluated on 1,080 responses from nine LLMs. Key findings are that LLMs score well on some dimensions yet show recurring problems (unconstructive feedback, overgeneralization, limited personalization) and frequent safety flags (especially unauthorized medical advice), that LLM judges overrate responses relative to experts, and that model-specific failure patterns appear under adversarial probing.
Significance. If the expert ratings prove reliable, the work supplies a clinically grounded, large-scale resource for mental-health QA benchmarking that goes beyond multiple-choice or factoid tasks. Strengths include the involvement of 100 domain experts, span-level annotations, written rationales, and the adversarial construction that surfaces consistent failure modes. These elements could support reproducible evaluation and targeted improvement of LLMs in sensitive domains.
major comments (2)
- [§3] §3 (CounselBench-EVAL construction) and the abstract treat the 100 professionals' ratings on the six dimensions and binary safety flags as ground truth for identifying recurring issues and safety risks, yet no inter-rater reliability statistics (Fleiss' kappa, ICC, or pairwise agreement) are reported. Without these numbers the observed model-specific patterns and safety flags cannot be distinguished from rater idiosyncrasies, directly weakening the central empirical claims.
- [abstract and follow-up experiments] The comparison that LLM judges systematically overrate model responses and overlook safety concerns (abstract and follow-up experiments) rests on the same unverified expert ratings; any inconsistency among the 100 raters would propagate into the reported divergence between human and LLM judges.
minor comments (2)
- [§3] Exact definitions of the six clinically grounded dimensions and the criteria for safety flags are not fully specified in the abstract or §3, making it difficult to replicate the annotation protocol.
- Data-release details (whether the 2,000 evaluations, span annotations, and adversarial questions will be publicly available) are not stated, which limits the benchmark's utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on CounselBench. We agree that inter-rater reliability is essential for validating the expert ratings and will incorporate the requested statistics in the revised manuscript to strengthen the empirical claims.
read point-by-point responses
-
Referee: [§3] §3 (CounselBench-EVAL construction) and the abstract treat the 100 professionals' ratings on the six dimensions and binary safety flags as ground truth for identifying recurring issues and safety risks, yet no inter-rater reliability statistics (Fleiss' kappa, ICC, or pairwise agreement) are reported. Without these numbers the observed model-specific patterns and safety flags cannot be distinguished from rater idiosyncrasies, directly weakening the central empirical claims.
Authors: We acknowledge that inter-rater reliability metrics were omitted from the original submission. In the revision we will compute and report Fleiss' kappa (and, where appropriate, ICC or pairwise agreement) across the six dimensions and binary safety flags, using the full set of 2,000 ratings from the 100 professionals. These statistics will be presented in §3 and the appendix, allowing readers to assess consistency and thereby supporting the reliability of the model-specific patterns and safety flags we report. revision: yes
-
Referee: [abstract and follow-up experiments] The comparison that LLM judges systematically overrate model responses and overlook safety concerns (abstract and follow-up experiments) rests on the same unverified expert ratings; any inconsistency among the 100 raters would propagate into the reported divergence between human and LLM judges.
Authors: We agree that the LLM-judge comparison depends on the expert ratings. Adding the inter-rater reliability statistics in the revision will directly address this concern by quantifying agreement among the human experts. We will also update the abstract and the relevant experimental sections to explicitly note that the observed divergence is conditioned on the now-quantified reliability of the expert annotations. revision: yes
Circularity Check
No circularity: empirical benchmark relies on external expert judgments
full rationale
This is an empirical benchmark paper that collects ratings from 100 independent mental health professionals on 2,000 LLM and human responses, plus expert-authored adversarial questions. No mathematical derivations, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the abstract or described construction. Claims about recurring issues and safety risks are grounded in the external annotations rather than reducing to the paper's own inputs by definition or construction. The study is self-contained against these external benchmarks, consistent with the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ratings from 100 mental health professionals constitute a reliable and representative measure of clinical safety and helpfulness for LLM-generated answers.
Forward citations
Cited by 3 Pith papers
-
Detecting Stealth Sycophancy in Mental-Health Dialogue with Dynamic Emotional Signature Graphs
DESG uses dynamic graphs of decoupled clinical states and asymmetric geometry to evaluate therapeutic dialogue quality, reaching 0.9353 macro-F1 on a 600-window held-out test set and outperforming LLM judges and text ...
-
Graph2Counsel: Clinically Grounded Synthetic Counseling Dialogue Generation from Client Psychological Graphs
Graph2Counsel creates 760 synthetic counseling sessions from 76 client psychological graphs, outperforming prior datasets in expert ratings on specificity, authenticity, and safety while improving fine-tuned model per...
-
Mental Health AI Safety Claims Must Preserve Temporal Evidence
Mental health AI safety evaluations that discard temporal sequence and accumulation produce invalid conclusions; the paper formalizes this as Temporal Safety Non-Identifiability and proposes SCOPE-MH as a reporting st...
Reference graph
Works this paper leans on
-
[1]
Lisa Dockery, Debra Jeffery, Oliver Schauman, Paul Williams, Simone Farrelly, Oliver Bon- nington, Jheanell Gabbidon, Francesca Lassman, George Szmukler, Graham Thornicroft, and Sarah Clement. Stigma- and non-stigma-related treatment barriers to mental healthcare reported by service users and caregivers. Psychiatry Research, 228(3):612–619, August 2015
work page 2015
-
[2]
Rachel Garg, Serena N. Muhammad, Leopoldo J. Cabassa, Amy McQueen, Niko Verdecias, Regina Greer, and Matthew W. Kreuter. Transportation and other social needs as markers of mental health conditions. Journal of Transport & Health, 25:101357, June 2022
work page 2022
-
[3]
Faye A. Gary. Stigma: Barrier to Mental Health Care Among Ethnic Minorities. Issues in Mental Health Nursing, 26(10):979–999, January 2005
work page 2005
-
[4]
Perceived barriers on mental health services by the family of patients with mental illness
Rr Dian Tristiana, Ah Yusuf, Rizki Fitryasari, Sylvia Dwi Wahyuni, and Hanik Endang Nihayati. Perceived barriers on mental health services by the family of patients with mental illness. International Journal of Nursing Sciences, 5(1):63–67, January 2018
work page 2018
- [5]
-
[6]
Chukwudi Maha, Tolulope Kolawole, and Samira Abdul. Transforming mental health care: Telemedicine as a game-changer for low-income communities in the us and africa. GSC Advanced Research and Reviews, 19:275–285, 05 2024
work page 2024
-
[7]
Enitan T Marcelle, Laura Nolting, Stephen P Hinshaw, and Adrian Aguilera. Effectiveness of a Multimodal Digital Psychotherapy Platform for Adult Depression: A Naturalistic Feasibility Study. JMIR mHealth and uHealth, 7(1):e10948, January 2019
work page 2019
-
[8]
Eunkyung Jo, Whitney-Jocelyn Kouaho, Stephen M. Schueller, and Daniel A. Epstein. Exploring User Perspectives of and Ethical Experiences With Teletherapy Apps: Qualitative Analysis of User Reviews. JMIR mental health, 10:e49684, September 2023
work page 2023
-
[9]
Rajesh Sagar and Raman Deep Pattanayak. Use of Smartphone Apps for Mental Health: Can They Translate to a Smart and Effective Mental Health Care? Journal of Mental Health and Human Behaviour, 20(1):1, 2015-01/2015-06. 10
work page 2015
-
[10]
Melvyn W. B. Zhang, Cyrus S. H. Ho, Christopher C. S. Cheok, and Roger C. M. Ho. Smart- phone apps in mental healthcare: The state of the art and potential developments. BJPsych Advances, 21(5):354–358, September 2015
work page 2015
-
[11]
Edward Neukrug, Michael Kalkbrenner, and Sandy-Ann Griffith. Barriers to Counseling Among Human Service Professionals: The Development and Validation of the Fit, Stigma, & Value Scale. Journal of Human Services, 37(1), January 2017
work page 2017
-
[12]
Jacinta Jardine, Camille Nadal, Sarah Robinson, Angel Enrique, Marcus Hanratty, and Gavin Doherty. Between Rhetoric and Reality: Real-world Barriers to Uptake and Early Engagement in Digital Mental Health Interventions. ACM Trans. Comput.-Hum. Interact., 31(2):27:1–27:59, February 2024
work page 2024
-
[13]
A review of the literature on peer support in mental health services
Julie Repper and Tim and Carter. A review of the literature on peer support in mental health services. Journal of Mental Health, 20(4):392–411, August 2011
work page 2011
-
[14]
Steve Gillard. Peer support in mental health services: Where is the research taking us, and do we want to go there? Journal of Mental Health, 28(4):341–344, July 2019
work page 2019
-
[15]
Online social networks in health care: A study of mental disorders on reddit
Bárbara Silveira Fraga, Ana Paula Couto da Silva, and Fabricio Murai. Online social networks in health care: A study of mental disorders on reddit. In 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), pages 568–573, 2018
work page 2018
-
[16]
Yirong Chen, Xiaofen Xing, Jingkai Lin, Huimin Zheng, Zhenyu Wang, Qi Liu, and Xiangmin Xu. Soulchat: Improving llms’ empathy, listening, and comfort abilities through fine-tuning with multi-turn empathy conversations, 2023
work page 2023
-
[17]
Stade, Shannon Wiltsey Stirman, Lyle H
Elizabeth C. Stade, Shannon Wiltsey Stirman, Lyle H. Ungar, Cody L. Boland, H. Andrew Schwartz, David B. Yaden, João Sedoc, Robert J. DeRubeis, Robb Willer, and Johannes C. Eichstaedt. Large language models could change the future of behavioral healthcare: A proposal for responsible development and evaluation. npj Mental Health Research, 3(1), Apr 2024
work page 2024
-
[18]
Moran, Sophia Ananiadou, Andrew Beam, and John Torous
Yining Hua, Fenglin Liu, Kailai Yang, Zehan Li, Hongbin Na, Yi han Sheu, Peilin Zhou, Lauren V . Moran, Sophia Ananiadou, Andrew Beam, and John Torous. Large language models in mental health care: a scoping review, 2024
work page 2024
-
[19]
Large language models as mental health resources: Patterns of use in the united states., 2025
Tony Rousmaniere, Xu Li, Yimeng Zhang, and Siddharth Shah. Large language models as mental health resources: Patterns of use in the united states., 2025
work page 2025
-
[20]
The opportunities and risks of large language models in mental health
Hannah R Lawrence, Renee A Schneider, Susan B Rubin, Maja J Matari´c, Daniel J McDuff, and Megan Jones Bell. The opportunities and risks of large language models in mental health. JMIR Mental Health, 11, Jul 2024
work page 2024
-
[21]
Kim Bellware and Niha Masih
-
[22]
Clare Duffy. “there are no guardrails.” this mom believes an ai chatbot is responsible for her son’s suicide | cnn business, Oct 2024
work page 2024
-
[23]
Galatzer-Levy, Daniel McDuff, Vivek Natarajan, Alan Karthikesalingam, and Matteo Malgaroli
Isaac R. Galatzer-Levy, Daniel McDuff, Vivek Natarajan, Alan Karthikesalingam, and Matteo Malgaroli. The capability of large language models to measure psychiatric functioning, 2023
work page 2023
-
[24]
Capa- bilities of gpt-4 on medical challenge problems, 2023
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capa- bilities of gpt-4 on medical challenge problems, 2023
work page 2023
-
[25]
Xuhai Xu, Bingsheng Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Marzyeh Ghassemi, Anind K. Dey, and Dakuo Wang. Mental-llm: Leveraging large language models for mental health prediction via online text data. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1):1–32, March 2024
work page 2024
-
[27]
Therapy as an nlp task: Psychologists’ comparison of llms and human peers in cbt, 2024
Zainab Iftikhar, Sean Ransom, Amy Xiao, and Jeff Huang. Therapy as an nlp task: Psychologists’ comparison of llms and human peers in cbt, 2024. 11
work page 2024
-
[28]
Alicja Chaszczewicz, Raj Sanjay Shah, Ryan Louie, Bruce A Arnow, Robert Kraut, and Diyi Yang. Multi-level feedback generation with large language models for empowering novice peer counselors, 2024
work page 2024
-
[29]
Ruiyi Wang, Stephanie Milani, Jamie C. Chiu, Jiayin Zhi, Shaun M. Eack, Travis Labrum, Samuel M. Murphy, Nev Jones, Kate Hardy, Hong Shen, Fei Fang, and Zhiyu Zoey Chen. Patient-Ψ: Using large language models to simulate patients for training mental health profes- sionals, 2024
work page 2024
-
[30]
Rosen, Michael Hogarth, Kimberly A
Ming Tai-Seale, Michael Cheung, Florin Vaida, Bernice Ruo, Amanda Walker, Rebecca L. Rosen, Michael Hogarth, Kimberly A. Fisher, Sonal Singh, Robert A. Yood, Lawrence Garber, Cassandra Saphirak, Martina Li, Albert S. Chan, Edward E. Yu, Gene Kallenberg, Christo- pher A. Longhurst, Marlene Millen, Cheryl D. Stults, and Kathleen M. Mazor. Patient-clinician ...
work page 2024
-
[31]
Inbal Nahum-Shani, Shawna N Smith, Bonnie J Spring, Linda M Collins, Katie Witkiewitz, Ambuj Tewari, and Susan A Murphy. Just-in-time adaptive interventions (jitais) in mobile health: Key components and design principles for ongoing health behavior support. Annals of Behavioral Medicine, 52(6):446–462, 12 2017
work page 2017
-
[32]
Counsel chat: Bootstrapping high-quality therapy data, 2020
Nicolas Bertagnolli. Counsel chat: Bootstrapping high-quality therapy data, 2020
work page 2020
-
[33]
Bhautesh Dinesh Jani, David N. Blane, and Stewart W. Mercer. The role of empathy in therapy and the physician-patient relationship. Forschende Komplementärmedizin / Research in Complementary Medicine, 19(5):252–257, October 2012
work page 2012
-
[34]
Steven J. Ackerman and Mark J. Hilsenroth. A review of therapist characteristics and techniques positively impacting the therapeutic alliance. Clinical Psychology Review, 23(1):1–33, February 2003
work page 2003
- [35]
-
[36]
William B. Stiles and Adam O. Horvath. Appropriate responsiveness as a contribution to therapist effects. In How and Why Are Some Therapists Better than Others?: Understanding Therapist Effects, pages 71–84. American Psychological Association, Washington, DC, US, 2017
work page 2017
-
[37]
Ueli Kramer and William B. Stiles. The responsiveness problem in psychotherapy: A review of proposed solutions. Clinical Psychology: Science and Practice, 22(3):277–295, 2015
work page 2015
-
[38]
Patel, Ana Catarino, Keisuke Takano, Tim Dalgleish, and Michael Ewbank
Caitlin Hitchcock, Julia Funk, Ronan Cummins, Shivam D. Patel, Ana Catarino, Keisuke Takano, Tim Dalgleish, and Michael Ewbank. A deep learning quantification of patient specificity as a predictor of session attendance and treatment response to internet-enabled cognitive behavioural therapy for common mental health disorders. Journal of Affective Disorder...
work page 2024
-
[39]
Hannah E. Frank, Emily M. Becker-Haimes, and Philip C. Kendall. Therapist training in evidence-based interventions for mental health: A systematic review of training approaches and outcomes. Clinical Psychology: Science and Practice, 27(3):e12330, 2020
work page 2020
-
[40]
Lyon, Shannon Wiltsey Stirman, Suzanne E
Aaron R. Lyon, Shannon Wiltsey Stirman, Suzanne E. U. Kerns, and Eric J. Bruns. Developing the Mental Health Workforce: Review and Application of Training Approaches from Multiple Disciplines. Administration and Policy in Mental Health and Mental Health Services Research, 38(4):238–253, July 2011
work page 2011
-
[41]
Hill, Sarah Knox, and Changming Duan
Clara E. Hill, Sarah Knox, and Changming Duan. Psychotherapist advice, suggestions, recom- mendations: A research review. Psychotherapy, 60(3):295–305, 2023
work page 2023
-
[42]
Megan Prass, Ewell , Arcadia, Hill , Clara E., and Dennis M. and Kivlighan Jr. Solicited and Unsolicited Therapist Advice inPsychodynamic Psychotherapy: Is it Advised? Counselling Psychology Quarterly, 34(2):253–274, April 2021. 12
work page 2021
- [43]
-
[44]
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations, April 2025
Yiyou Sun, Yu Gai, Lijie Chen, Abhilasha Ravichander, Yejin Choi, and Dawn Song. Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations, April 2025
work page 2025
-
[45]
Daniel S. Lobel. When Your Therapist Is Wrong | Psychology Today. https://www.psychologytoday.com/us/blog/my-side-of-the-couch/202311/when-your- therapist-is-wrong, February 2024
work page 2024
-
[46]
Marianne Webb, Jane Burns, and Philippa Collin. Providing online support for young people with mental health difficulties: Challenges and opportunities explored. Early Intervention in Psychiatry, 2(2):108–113, 2008
work page 2008
-
[47]
Mental health help-seeking behaviours in young adults
Caroline Mitchell, Brian McMillan, and Teresa Hagan. Mental health help-seeking behaviours in young adults. British Journal of General Practice, 67(654):8–9, January 2017
work page 2017
-
[48]
Cooperation in the gig economy: Insights from upwork freelancers
Zachary Fulker and Christoph Riedl. Cooperation in the gig economy: Insights from upwork freelancers. Proc. ACM Hum.-Comput. Interact., 8(CSCW1), April 2024
work page 2024
-
[49]
Thomas G. McGuire and Jeanne Miranda. Racial and Ethnic Disparities in Mental Health Care: Evidence and Policy Implications. Health affairs (Project Hope), 27(2):393–403, 2008
work page 2008
-
[50]
Emmanuelle Verdieu. Why aren’t more people of color in the mental health work- force? https://www.christenseninstitute.org/blog/why-arent-more-people-of-color-in-the- mental-health-workforce/, January 2024
work page 2024
-
[51]
CWS Data Tool: Demographics of the U.S
American Psychological Association. CWS Data Tool: Demographics of the U.S. Psychology Workforce. https://www.apa.org/workforce/data-tools/demographics, 2022
work page 2022
-
[52]
R. F. Woolson. Wilcoxon Signed-Rank Test. Wiley, 1 edition, February 2005
work page 2005
-
[53]
Antonia Zapf, Stefanie Castell, Lars Morawietz, and André Karch. Measuring inter-rater reliability for nominal data – which coefficients and confidence intervals are appropriate? BMC Medical Research Methodology, 16(1):93, December 2016
work page 2016
-
[54]
Victoria Clarke and Virginia Braun. Thematic analysis. The Journal of Positive Psychology, 12(3):297–298, May 2017
work page 2017
-
[55]
National Institute of Mental Health. Mental health medications. https://www.nimh.nih. gov/health/topics/mental-health-medications, 2025
work page 2025
-
[56]
The GEM benchmark: Natural language generation, its evaluation and metrics
Sebastian Gehrmann, Tosin Adewumi, Karmanya Aggarwal, Pawan Sasanka Ammanamanchi, Anuoluwapo Aremu, Antoine Bosselut, Khyathi Raghavi Chandu, Miruna-Adriana Clinciu, Dipanjan Das, Kaustubh Dhole, Wanyu Du, Esin Durmus, Ond ˇrej Dušek, Chris Chinenye Emezue, Varun Gangal, Cristina Garbacea, Tatsunori Hashimoto, Yufang Hou, Yacine Jernite, Harsh Jhamtani, Y...
work page 2021
-
[57]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Informat...
work page 2023
-
[58]
SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[59]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page 2024
-
[60]
Verónica Pérez-Rosas, Xinyi Wu, Kenneth Resnicow, and Rada Mihalcea. What makes a good counselor? learning to distinguish between high-quality and low-quality counseling conversations. In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 926–935, Florence...
work page 2019
-
[61]
Anno-mi: A dataset of expert-annotated counselling dialogues
Zixiu Wu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Ehud Reiter, Diego Reforgiato Recu- pero, and Daniele Riboni. Anno-mi: A dataset of expert-annotated counselling dialogues. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6177–6181, 2022
work page 2022
-
[62]
Cuempathy: A counseling speech dataset for psychotherapy research
Dehua Tao, Harold Chui, Sarah Luk, and Tan Lee. Cuempathy: A counseling speech dataset for psychotherapy research. In 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP), pages 354–358, 2022
work page 2022
-
[63]
Ganeshan Malhotra, Abdul Waheed, Aseem Srivastava, Md Shad Akhtar, and Tanmoy Chakraborty. Speaker and time-aware joint contextual learning for dialogue-act classification in counselling conversations. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , WSDM ’22, page 735–745, New York, NY , USA, 2022. Association ...
work page 2022
-
[64]
PAIR: Prompt- aware margIn ranking for counselor reflection scoring in motivational interviewing
Do June Min, Verónica Pérez-Rosas, Kenneth Resnicow, and Rada Mihalcea. PAIR: Prompt- aware margIn ranking for counselor reflection scoring in motivational interviewing. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 148–158, Abu Dhabi, United Arab E...
work page 2022
-
[65]
Tulika Saha, Saraansh Chopra, Sriparna Saha, Pushpak Bhattacharyya, and Pankaj Kumar. A large-scale dataset for motivational dialogue system: An application of natural language generation to mental health. In 2021 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2021
work page 2021
-
[66]
The distress analysis interview corpus of human and computer interviews
Jonathan Gratch, Ron Artstein, Gale Lucas, Giota Stratou, Stefan Scherer, Angela Nazarian, Rachel Wood, Jill Boberg, David DeVault, Stacy Marsella, David Traum, Skip Rizzo, and Louis- Philippe Morency. The distress analysis interview corpus of human and computer interviews. In Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, Hrafn Loftsson, Bente Ma...
work page 2014
-
[67]
Mentalchat16k: A benchmark dataset for conversational mental health assistance, 2025
Jia Xu, Tianyi Wei, Bojian Hou, Patryk Orzechowski, Shu Yang, Ruochen Jin, Rachael Paulbeck, Joost Wagenaar, George Demiris, and Li Shen. Mentalchat16k: A benchmark dataset for conversational mental health assistance, 2025
work page 2025
-
[68]
Convcounsel: A conversational dataset for student counseling, 2024
Po-Chuan Chen, Mahdin Rohmatillah, You-Teng Lin, and Jen-Tzung Chien. Convcounsel: A conversational dataset for student counseling, 2024
work page 2024
-
[69]
Medic: A multimodal empathy dataset in counseling
Zhouan Zhu, Chenguang Li, Jicai Pan, Xin Li, Yufei Xiao, Yanan Chang, Feiyi Zheng, and Shangfei Wang. Medic: A multimodal empathy dataset in counseling. In Proceedings of the 31st ACM International Conference on Multimedia, MM ’23, page 6054–6062, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[70]
Shalin, Krish- naprasad Thirunarayan, Amit Sheth, and I
Thilini Wijesiriwardene, Hale Inan, Ugur Kursuncu, Manas Gaur, Valerie L. Shalin, Krish- naprasad Thirunarayan, Amit Sheth, and I. Budak Arpinar. Alone: A dataset for toxic behavior among adolescents on twitter. In Social Informatics: 12th International Conference, SocInfo 2020, Pisa, Italy, October 6–9, 2020, Proceedings, page 427–439, Berlin, Heidelberg...
work page 2020
-
[71]
Lord, Md Shad Akhtar, and Tanmoy Chakraborty
Aseem Srivastava, Tharun Suresh, Sarah P. Lord, Md Shad Akhtar, and Tanmoy Chakraborty. Counseling summarization using mental health knowledge guided utterance filtering. In Pro- ceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, page 3920–3930, New York, NY , USA, 2022. Association for Computing Machinery. 15
work page 2022
-
[72]
Philipp Steigerwald and Jens Albrecht. Comparing large language models for automated subject line generation in e-mental health: A performance study. In Proceedings of the 11th International Conference on Information and Communication Technologies for Ageing Well and e-Health - Volume 1: ICT4AWE, pages 70–77. INSTICC, SciTePress, 2025
work page 2025
-
[74]
Anqi Li, Yu Lu, Nirui Song, Shuai Zhang, Lizhi Ma, and Zhenzhong Lan. Understanding the therapeutic relationship between counselors and clients in online text-based counseling using LLMs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1280–1303, Miami, Florida, US...
work page 2024
-
[75]
A computational framework for behavioral assessment of llm therapists, 2024
Yu Ying Chiu, Ashish Sharma, Inna Wanyin Lin, and Tim Althoff. A computational framework for behavioral assessment of llm therapists, 2024
work page 2024
-
[76]
Jordyn Young, Laala M Jawara, Diep N Nguyen, Brian Daly, Jina Huh-Yoo, and Afsaneh Razi. The role of ai in peer support for young people: A study of preferences for human- and ai-generated responses. In Proceedings of the CHI Conference on Human Factors in Computing Systems, CHI ’24, page 1–18. ACM, May 2024
work page 2024
-
[77]
Ian Steenstra, Farnaz Nouraei, and Timothy Bickmore. Scaffolding empathy: Training coun- selors with simulated patients and utterance-level performance visualizations. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, page 1–22. ACM, April 2025
work page 2025
-
[78]
Towards a client-centered assessment of llm therapists by client simulation, 2024
Jiashuo Wang, Yang Xiao, Yanran Li, Changhe Song, Chunpu Xu, Chenhao Tan, and Wenjie Li. Towards a client-centered assessment of llm therapists by client simulation, 2024
work page 2024
-
[79]
Assessing motivational interviewing sessions with AI-generated patient simulations
Stav Yosef, Moreah Zisquit, Ben Cohen, Anat Klomek Brunstein, Kfir Bar, and Doron Friedman. Assessing motivational interviewing sessions with AI-generated patient simulations. In Andrew Yates, Bart Desmet, Emily Prud’hommeaux, Ayah Zirikly, Steven Bedrick, Sean MacAvaney, Kfir Bar, Molly Ireland, and Yaakov Ophir, editors, Proceedings of the 9th Workshop ...
work page 2024
-
[80]
Esc-eval: Evaluating emotion support conversations in large language models, 2024
Haiquan Zhao, Lingyu Li, Shisong Chen, Shuqi Kong, Jiaan Wang, Kexin Huang, Tianle Gu, Yixu Wang, Wang Jian, Dandan Liang, Zhixu Li, Yan Teng, Yanghua Xiao, and Yingchun Wang. Esc-eval: Evaluating emotion support conversations in large language models, 2024
work page 2024
-
[81]
Junlei Zhang, Hongliang He, Lizhi Ma, Nirui Song, Shuyuan He, Shuai Zhang, Huachuan Qiu, Zhanchao Zhou, Anqi Li, Yong Dai, Renjun Xu, and Zhenzhong Lan. Conceptpsy: A comprehensive benchmark suite for hierarchical psychological concept understanding in llms. Neurocomputing, 637:130070, July 2025
work page 2025
-
[82]
Mary L. Smith. Sex bias in counseling and psychotherapy. Psychological Bulletin , 87(2):392–407, 1980
work page 1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.