Recognition: 2 theorem links
· Lean TheoremGenerating Leakage-Free Benchmarks for Robust RAG Evaluation
Pith reviewed 2026-05-12 02:59 UTC · model grok-4.3
The pith
SeedRG creates fresh RAG benchmark examples by replacing entities in extracted reasoning graphs to block knowledge leakage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that starting from a seed benchmark, extracting a reasoning graph from question-context pairs, and applying type-constrained entity replacement generates structurally similar yet novel instances that preserve task difficulty and are absent from parametric knowledge, after consistency and leakage verification steps.
What carries the argument
reasoning graph extraction combined with type-constrained entity replacement, which captures the underlying structure and creates new but equivalent instances.
If this is right
- RAG models can be tested on whether they truly depend on retrieved information rather than internal knowledge.
- Benchmarks can be refreshed periodically to counter the effects of models training on public data.
- Evaluation results become more trustworthy for comparing different RAG approaches.
- The method reduces the need to collect entirely new human-annotated datasets for each evaluation cycle.
Where Pith is reading between the lines
- This method could be extended to create dynamic benchmarks that evolve with model capabilities.
- It suggests that graph-based representations of reasoning may be useful for other data augmentation tasks in NLP.
- Adopting such pipelines might shift the field toward generated rather than static benchmarks for robustness testing.
Load-bearing premise
Type-constrained entity replacement on reasoning graphs from seed data will yield new instances that match the original difficulty and lie outside the model's existing knowledge.
What would settle it
Testing whether language models achieve similar accuracy on the generated examples without any retrieval as they do on the original seed questions would show if leakage persists.
Figures


read the original abstract
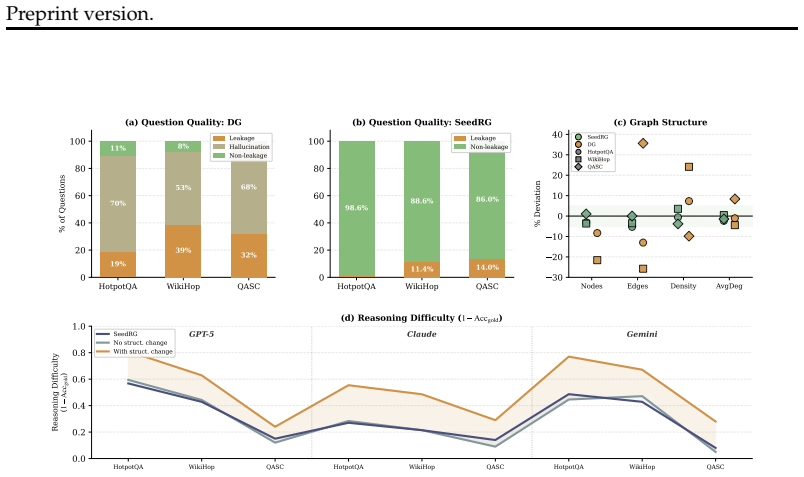
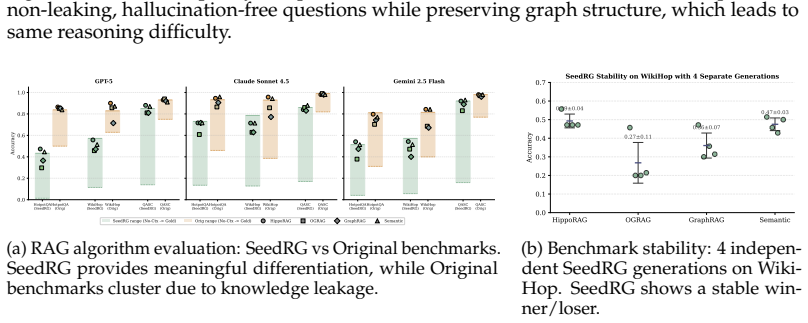
Retrieval-augmented generation (RAG) is widely used to augment large language models (LLMs) with external knowledge. However, many benchmark datasets, designed to test RAG performance, comprise many questions that can already be answered from an LLM's parametric memory. This leads to unreliable evaluation. We refer to this phenomenon as knowledge leakage: cases where RAG tasks are solvable without retrieval. This issue worsens over time due to benchmark aging. As benchmarks are reused for training, their contents are increasingly absorbed into model parameters, making them less effective for evaluating retrieval. We introduce SeedRG, a semi-synthetic benchmark generation pipeline that mitigates knowledge leakage and addresses the issue of benchmark aging. Starting from a seed benchmark dataset, SeedRG extracts a reasoning graph from question-context pairs to capture their underlying reasoning structure, and then generates new examples via type-constrained entity replacement. This process produces structurally similar but novel instances that are unlikely to exist in the model's parametric knowledge, while preserving the original reasoning patterns. To ensure quality, we incorporate two verification steps: (1) a reasoning-graph consistency check to maintain task difficulty, and (2) a knowledge-leakage filter to exclude instances answerable without retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SeedRG, a semi-synthetic benchmark generation pipeline for RAG evaluation. Starting from a seed dataset, it extracts reasoning graphs from question-context pairs, applies type-constrained entity replacement to generate novel instances that are structurally similar yet unlikely to appear in model parametric knowledge, and applies two verification steps (reasoning-graph consistency check and knowledge-leakage filter) to preserve task difficulty and exclude cases solvable without retrieval, thereby addressing knowledge leakage and benchmark aging.
Significance. If the pipeline can be shown to reliably produce leakage-free instances of equivalent difficulty, the work would provide a constructive method for generating fresh, robust RAG benchmarks that better isolate retrieval performance from parametric memorization. This directly tackles a growing practical problem in LLM evaluation as training corpora expand and benchmarks age.
major comments (2)
- [Abstract / Method outline] Abstract and pipeline description: the central claim that type-constrained entity replacement yields instances that are (a) structurally equivalent, (b) absent from parametric knowledge, and (c) of preserved difficulty rests on the leakage filter and consistency check, yet the manuscript supplies no empirical results, error analysis, or implementation details (e.g., prompt design for the filter or how graph consistency is quantified) to demonstrate these properties hold.
- [Verification steps] Verification steps: the knowledge-leakage filter is defined as excluding instances answerable without retrieval and the consistency check as preserving difficulty, but these are post-hoc and the paper does not address whether entity replacement can create easier/harder variants via rarity or domain shift, or whether a single-prompt filter misses partial parametric knowledge of new combinations.
minor comments (2)
- [Abstract] The abstract outlines the two verification steps but does not specify the exact criteria or models used; expanding this in the main text would aid reproducibility.
- [Method] Notation for the reasoning graph extraction and entity replacement could be formalized (e.g., with pseudocode or a diagram) to clarify the type-constraint mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical importance of addressing knowledge leakage and benchmark aging in RAG evaluation. We address each major comment below and outline the revisions we will make to strengthen the empirical grounding and discussion of the SeedRG pipeline.
read point-by-point responses
-
Referee: [Abstract / Method outline] Abstract and pipeline description: the central claim that type-constrained entity replacement yields instances that are (a) structurally equivalent, (b) absent from parametric knowledge, and (c) of preserved difficulty rests on the leakage filter and consistency check, yet the manuscript supplies no empirical results, error analysis, or implementation details (e.g., prompt design for the filter or how graph consistency is quantified) to demonstrate these properties hold.
Authors: We agree that the current description would be strengthened by explicit empirical validation and implementation details. In the revised manuscript we will add a dedicated evaluation section reporting results on the leakage filter and consistency check (including precision/recall against human judgments where feasible), an error analysis of failure cases, the exact prompt templates used for the knowledge-leakage filter, and the concrete metric employed to quantify reasoning-graph consistency (structural isomorphism plus node-type matching). These additions will directly support the claims of structural equivalence, novelty relative to parametric knowledge, and difficulty preservation. revision: yes
-
Referee: [Verification steps] Verification steps: the knowledge-leakage filter is defined as excluding instances answerable without retrieval and the consistency check as preserving difficulty, but these are post-hoc and the paper does not address whether entity replacement can create easier/harder variants via rarity or domain shift, or whether a single-prompt filter misses partial parametric knowledge of new combinations.
Authors: We acknowledge that post-hoc filters are not infallible and that type-constrained replacement may inadvertently alter perceived difficulty through entity rarity or subtle domain shifts, while a single-prompt filter could miss partial parametric knowledge of novel combinations. In the revision we will expand the discussion of verification limitations, include a targeted analysis (on a held-out subset) measuring difficulty shifts before and after replacement, and describe an improved multi-prompt ensemble variant of the leakage filter that we will adopt. We will also flag these issues as important directions for future robustness work. revision: partial
Circularity Check
No circularity in SeedRG constructive pipeline
full rationale
The paper presents a descriptive generation pipeline: extract reasoning graph from seed question-context pairs, apply type-constrained entity replacement to create novel instances, then run independent verification via graph-consistency check and knowledge-leakage filter. No equations, fitted parameters, or predictions appear. No self-citations are invoked as load-bearing premises. The steps are self-contained constructive operations that do not reduce any claimed output (leakage-free, difficulty-preserving instances) to a tautological redefinition of the inputs.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Reasoning graph extracted from question-context pairs accurately captures the underlying reasoning structure
- domain assumption Type-constrained entity replacement preserves reasoning patterns and task difficulty
- domain assumption Knowledge-leakage filter successfully excludes instances answerable without retrieval
invented entities (1)
-
SeedRG pipeline
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearSeedRG extracts a reasoning graph from question-context pairs ... generates new examples via type-constrained entity replacement ... reasoning-graph consistency check ... knowledge-leakage filter
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearpreserves the original reasoning patterns ... structural equivalence: Gq' ≅ Gq
Reference graph
Works this paper leans on
-
[1]
Prompt leakage effect and mitigation strategies for multi-turn llm applications
Divyansh Agarwal, Alexander Richard Fabbri, Ben Risher, Philippe Laban, Shafiq Joty, and Chien-Sheng Wu. Prompt leakage effect and mitigation strategies for multi-turn llm applications. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 1255–1275,
work page 2024
-
[2]
Manit Baser, Dinil Mon Divakaran, and Mohan Gurusamy. Thinkeval: Practical evaluation of knowledge leakage in llm editing using thought-based knowledge graphs.arXiv preprint arXiv:2506.01386,
-
[3]
Pratyush Desai, Luoxi Tang, Yuqiao Meng, and Zhaohan Xi. Safegpt: Preventing data leakage and unethical outputs in enterprise llm use.arXiv preprint arXiv:2601.06366,
-
[4]
Self-boosting large language models with synthetic preference data.arXiv preprint arXiv:2410.06961,
Qingxiu Dong, Li Dong, Xingxing Zhang, Zhifang Sui, and Furu Wei. Self-boosting large language models with synthetic preference data.arXiv preprint arXiv:2410.06961,
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From lo- cal to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexan- der Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301,
-
[7]
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707,
-
[8]
Kilt: a benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. Kilt: a benchmark for knowledge intensive language tasks. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
work page 2021
-
[9]
Og-rag: ontology-grounded retrieval- augmented generation for large language models
Kartik Sharma, Peeyush Kumar, and Yunqing Li. Og-rag: ontology-grounded retrieval- augmented generation for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 32950–32969,
work page 2025
-
[10]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdi- nov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics,
work page 2018
-
[11]
Hypothetical documents or knowledge leakage? rethinking llm-based query expansion
Yejun Yoon, Jaeyoon Jung, Seunghyun Yoon, and Kunwoo Park. Hypothetical documents or knowledge leakage? rethinking llm-based query expansion. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 19170–19187,
work page 2025
-
[12]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review arXiv
-
[13]
Benchmark leakage trap: Can we trust llm-based recommendation?arXiv preprint arXiv:2602.13626,
Mingqiao Zhang, Qiyao Peng, Yumeng Wang, Chunyuan Liu, and Hongtao Liu. Benchmark leakage trap: Can we trust llm-based recommendation?arXiv preprint arXiv:2602.13626,
-
[14]
Don’t make your llm an evaluation benchmark cheater
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. Don’t make your llm an evaluation benchmark cheater. arXiv preprint arXiv:2311.01964,
-
[15]
Kunlun Zhu, Yifan Luo, Dingling Xu, Yukun Yan, Zhenghao Liu, Shi Yu, Ruobing Wang, Shuo Wang, Yishan Li, Nan Zhang, et al. Rageval: Scenario specific rag evaluation dataset generation framework.arXiv preprint arXiv:2408.01262,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.