Recognition: no theorem link
Local LMO: Constrained Gradient Optimization via a Local Linear Minimization Oracle
Pith reviewed 2026-05-12 01:12 UTC · model grok-4.3
The pith
Local LMO replaces the global linear minimization oracle of Frank-Wolfe with a local version over a small ball, allowing it to match the convergence rates of projected gradient descent without assuming a bounded feasible set or function
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Local LMO performs the update by solving a linear minimization problem over the constraint set intersected with a ball of radius t_k centered at the current iterate. This scheme transfers the known convergence rates of projected gradient descent to the projection-free setting across multiple function classes, including sublinear rates for convex functions with bounded gradients without needing curvature assumptions, linear rates for smooth strongly convex functions, and sharp rates in smooth convex, non-convex, and stochastic settings, all without requiring the feasible set to be bounded.
What carries the argument
The local linear minimization oracle, which finds the point in the intersection of the feasible set and a small ball that minimizes the inner product with the gradient, serving as a localized projection-free step that generalizes gradient descent.
Load-bearing premise
The analysis assumes that positive radii t_k can be chosen appropriately to achieve the desired convergence rates under the various function regimes.
What would settle it
Finding a convex function with bounded gradients over an unbounded set where no sequence of radii t_k lets Local LMO achieve the sublinear rate known for projected gradient descent would disprove the rate transfer.
Figures
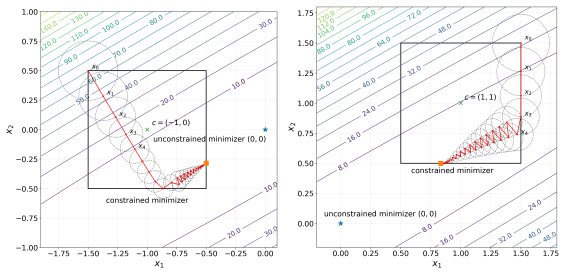



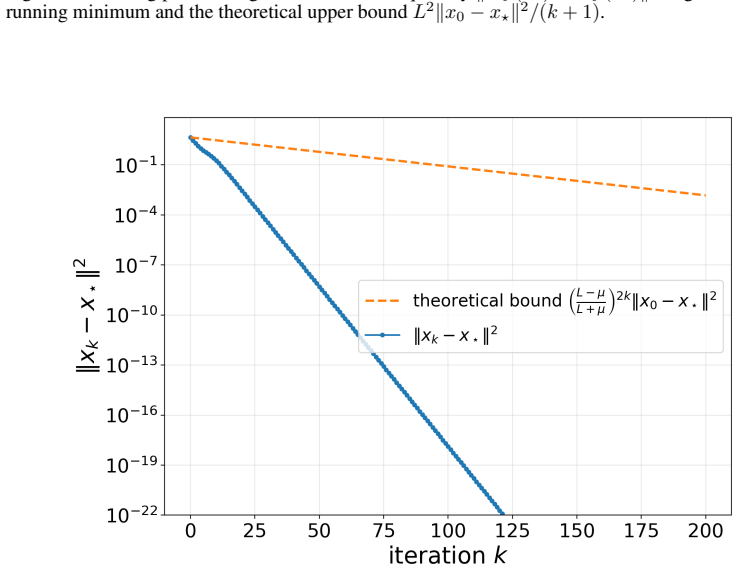

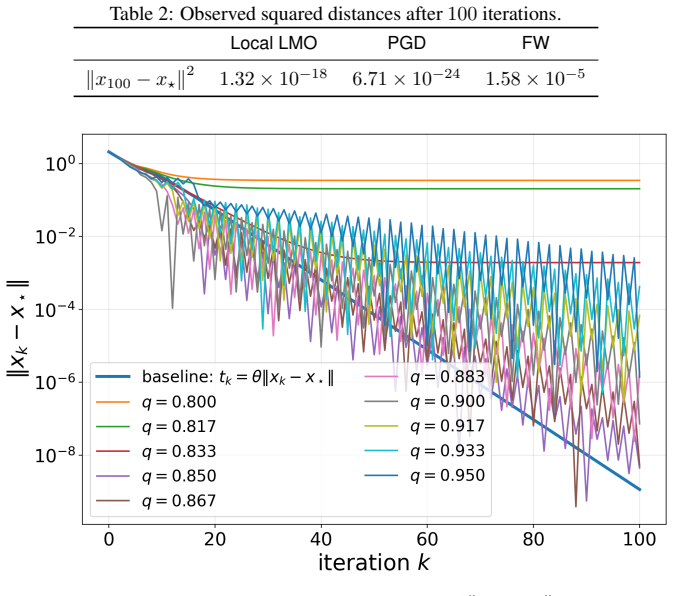
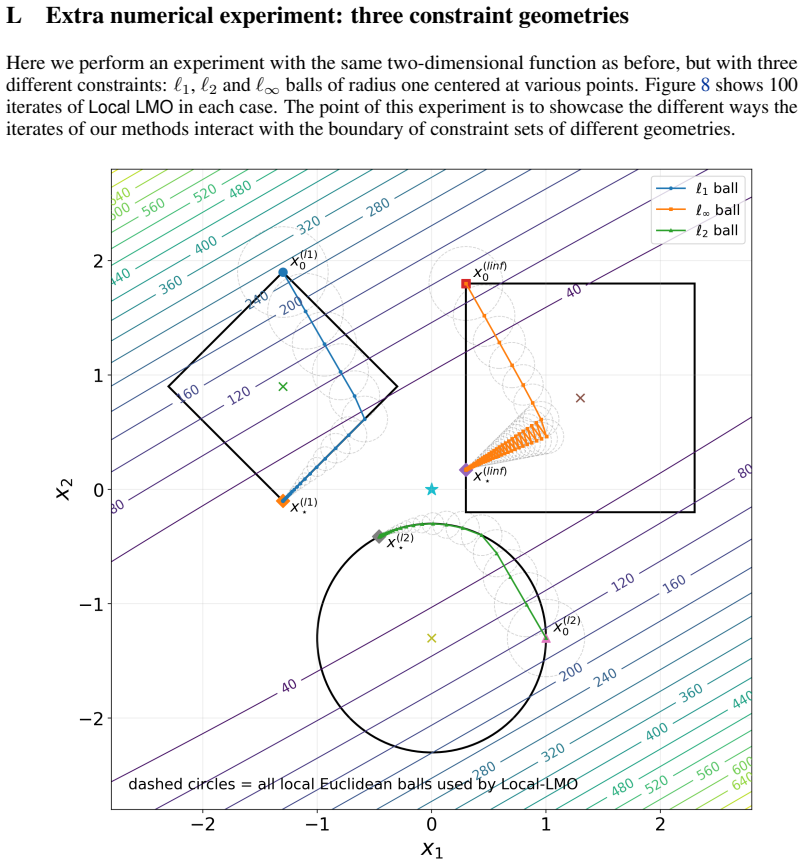
read the original abstract
We design Local LMO - a new projection-free gradient-type method for constrained optimization. The key algorithmic idea is to replace the global linear minimization oracle over the constraint set used by Frank-Wolfe (FW) with a local linear minimization oracle over the intersection of the constraint set and a "small" ball centered at the current iterate. In particular, when minimizing $f:\mathbb{R}^d\to \mathbb{R}$ over a constraint $\emptyset\neq\mathcal{X}\subseteq\mathbb{R}^d$, Local LMO performs the iteration \[x_{k+1}\in \arg\min_{z\in\mathcal{X}\cap\mathcal{B}(x_{k},t_k)}\langle\nabla f(x_{k}), z \rangle,\] where $x_0\in\mathcal{X}$, and $t_k>0$ is a suitably chosen radius which can be interpreted as an effective stepsize. While designed as an alternative to FW, Local LMO is perhaps best viewed as a generalization of Gradient Descent (GD) rather than a modification of FW. Indeed, it is easy to see that Local LMO reduces to GD in the unconstrained setting and, more generally, to GD restricted to an affine subspace if the constraint $\mathcal{X}$ is affine. We prove that this simple algorithmic scheme transfers the known (unaccelerated) convergence rates of Projected Gradient Descent (PGD) to the projection-free world in several important regimes, some of which are beyond the reach of FW. In contrast to FW theory, i) our guarantees hold without requiring the feasible set $\mathcal{X}$ to be bounded, ii) our theory does not require the "curvature" assumption, which allows us to establish a standard sublinear rate for convex functions with bounded gradients, iii) we obtain a linear rate in the smooth strongly convex regime. Furthermore, we obtain sharp sublinear rates in the smooth convex and non-convex regimes, in the $(L_0,L_1)$-smooth convex regime, and in stochastic and non-differentiable settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Local LMO, a projection-free gradient method for minimizing f over a constraint set X. It replaces the global linear minimization oracle of Frank-Wolfe with a local one over X intersect the ball of radius t_k centered at the current iterate x_k, yielding the update x_{k+1} in argmin_{z in X cap B(x_k,t_k)} <grad f(x_k), z>. The central claim is that, for suitably chosen t_k > 0, this transfers the known unaccelerated convergence rates of Projected Gradient Descent to the projection-free setting across multiple regimes (linear rate for smooth strongly convex; sublinear rates for smooth convex, non-convex, (L0,L1)-smooth convex, stochastic, and non-differentiable cases), without requiring boundedness of X or the curvature assumption needed by FW. The method reduces to GD when X is unconstrained or affine.
Significance. If the claimed rate transfers are rigorously established, the result would be significant: it provides a simple, projection-free scheme that achieves PGD rates in regimes where FW is either inapplicable or slower, while avoiding the need for global oracles or bounded domains. This could broaden the practical reach of projection-free methods in settings where local linear minimization is tractable.
major comments (2)
- [Abstract] Abstract: the claim that t_k can be chosen to transfer PGD rates in the smooth strongly convex, smooth convex, and bounded-gradient convex regimes is load-bearing, yet the abstract provides neither the explicit selection rule for t_k nor any indication of how the existence of such radii is proved; without these details the rate-transfer statements cannot be verified.
- [Abstract] Abstract: the statement that Local LMO 'transfers the known (unaccelerated) convergence rates of PGD' assumes that the local-oracle iteration can be analyzed by direct reduction to PGD; the abstract does not indicate whether this reduction is exact or requires additional arguments to control the difference between the local and global minimizers.
minor comments (1)
- The notation B(x_k, t_k) is not defined in the provided text; it should be stated whether this is the Euclidean ball or another norm.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for clarity on how the abstract summarizes the technical contributions. We address each major comment below. The manuscript body contains the full derivations, explicit choices of t_k, and proofs of the rate transfers; the abstract is kept concise as is conventional.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that t_k can be chosen to transfer PGD rates in the smooth strongly convex, smooth convex, and bounded-gradient convex regimes is load-bearing, yet the abstract provides neither the explicit selection rule for t_k nor any indication of how the existence of such radii is proved; without these details the rate-transfer statements cannot be verified.
Authors: The abstract serves as a high-level summary and therefore omits the explicit formulas for t_k and the existence proofs, which appear in the main text. In Section 3 we derive concrete choices (e.g., t_k = min{1/L, c / ||grad f(x_k)||} for appropriate constants c, or t_k proportional to the strong-convexity parameter in the linear-rate regime) and prove that such positive radii always exist under the stated smoothness and convexity assumptions. The existence argument proceeds by showing that the local linear minimization over X cap B(x_k, t_k) coincides with the projected-gradient step up to an O(t_k^2) error that can be made arbitrarily small while still guaranteeing descent; the rate-transfer theorems then follow by standard PGD analysis with this controlled perturbation. We do not believe the abstract requires these technical details. revision: no
-
Referee: [Abstract] Abstract: the statement that Local LMO 'transfers the known (unaccelerated) convergence rates of PGD' assumes that the local-oracle iteration can be analyzed by direct reduction to PGD; the abstract does not indicate whether this reduction is exact or requires additional arguments to control the difference between the local and global minimizers.
Authors: The reduction is not exact. The paper develops additional arguments that bound the difference between the local LMO solution and the true PGD iterate. Specifically, the proofs establish that ||x_{k+1} - P_X(x_k - eta grad f(x_k))|| = O(t_k) for step-size eta chosen consistently with the smoothness constant; by selecting t_k small enough relative to the current gradient norm (yet large enough to ensure sufficient progress), the extra error terms are absorbed into the standard PGD convergence bounds without degrading the rates. This controlled-approximation analysis is carried out in detail for each regime (smooth strongly convex, smooth convex, bounded-gradient convex, etc.) and yields the claimed transfer of unaccelerated PGD rates. The abstract's use of 'transfers' refers to this rigorously justified transfer rather than an exact equivalence. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract defines the Local LMO iteration directly as the argmin of the linear functional over the intersection of the constraint set X with a ball of radius t_k centered at the current point. It notes that the scheme reduces to standard gradient descent when X is unconstrained or affine, and states that convergence rates are transferred from known (external) results on unaccelerated projected gradient descent. No equations or claims in the provided text reduce a prediction or rate to a fitted parameter, self-citation, or definitional tautology; the t_k choice is presented as an assumption whose existence is to be verified in the (unavailable) analysis rather than presupposed by the result itself. The derivation chain therefore remains self-contained against standard external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- t_k
axioms (1)
- domain assumption Standard assumptions on f (smoothness, convexity, strong convexity, bounded gradients) as needed for each convergence regime.
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2202.08711 , title =
J\'er\^. arXiv preprint arXiv:2202.08711 , title =
-
[3]
Complexity bounds for primal-dual methods mini-mizing the model of objective function
Yurii Nesterov , journal =. Complexity bounds for primal-dual methods mini-mizing the model of objective function. , 2017 , year =
work page 2017
-
[4]
Alp Yurtsever and Olivier Fercoq and Francesco Locatello and Volkan Cevher , booktitle =. A Conditional Gradient Framework for Composite Convex Minimizationwith Applications to Semidefinite Programming , year =
-
[5]
Naval Research Logistics Quarterly , volume =
Frank, Marguerite and Wolfe, Philip , title =. Naval Research Logistics Quarterly , volume =
-
[6]
Proceedings of the 30th International Conference on Machine Learning (ICML) , pages =
Martin Jaggi , title =. Proceedings of the 30th International Conference on Machine Learning (ICML) , pages =
-
[7]
Advances in Neural Information Processing Systems , pages =
Dan Garber and Elad Hazan , title =. Advances in Neural Information Processing Systems , pages =
-
[8]
Advances in Neural Information Processing Systems , volume=
Faster projection-free convex optimization over the spectrahedron , author=. Advances in Neural Information Processing Systems , volume=
- [9]
-
[10]
Journal of Machine Learning Research , volume=
Optimization with non-differentiable constraints with applications to fairness, recall, churn, and other goals , author=. Journal of Machine Learning Research , volume=
-
[11]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Fast Projection-Free Approach (without Optimization Oracle) for Optimization over Compact Convex Set , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[12]
Dai, Josef and Pan, Xuehai and Sun, Ruiyang and Ji, Jiaming and Xu, Xinbo and Liu, Mickel and Wang, Yizhou and Yang, Yaodong , journal=. Safe
-
[13]
Advances in Neural Information Processing Systems , volume=
Constrained optimization to train neural networks on critical and under-represented classes , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2601.04849 , year=
Stability of Constrained Optimization Models for Structured Signal Recovery , author=. arXiv preprint arXiv:2601.04849 , year=
-
[15]
Real-Time Convex Optimization in Signal Processing , volume =
Mattingley, John and Boyd, Stephen , year =. Real-Time Convex Optimization in Signal Processing , volume =. Signal Processing Magazine, IEEE , doi =
-
[16]
On portfolio optimization: Imposing the right constraints , journal =
Patrick Behr and Andre Guettler and Felix Miebs , keywords =. On portfolio optimization: Imposing the right constraints , journal =. 2013 , issn =
work page 2013
-
[17]
Richard J. Hathaway , title =. The Annals of Statistics , number =. 1985 , doi =
work page 1985
-
[18]
Density Estimation under Constraints , urldate =
Peter Hall and Brett Presnell , journal =. Density Estimation under Constraints , urldate =
-
[19]
Advances in Neural Information Processing Systems , volume=
Empirical risk minimization under fairness constraints , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Deep neural network training with
Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max , journal=. Deep neural network training with
-
[21]
Safety-constrained reinforcement learning with a distributional safety critic , volume =
Yang, Qisong and Simão, Thiago and Tindemans, Simon and Spaan, Matthijs , year =. Safety-constrained reinforcement learning with a distributional safety critic , volume =. Machine Learning , doi =
-
[22]
arXiv preprint arXiv:1309.5550 , year=
The complexity of large-scale convex programming under a linear optimization oracle , author=. arXiv preprint arXiv:1309.5550 , year=
-
[23]
Gu\'. Some comments on. Math. Program. , month = may, pages =. 1986 , issue_date =
work page 1986
-
[24]
Levitin, Evgeny S. and Polyak, Boris T. , year =. Constrained Minimization Methods , volume =. USSR Computational Mathematics and Mathematical Physics , doi =
-
[25]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =
-
[26]
Training Deep Learning Models with Norm-Constrained
Pethick, Thomas and Xie, Wanyun and Antonakopoulos, Kimon and Zhu, Zhenyu and Silveti-Falls, Antonio and Cevher, Volkan , journal=. Training Deep Learning Models with Norm-Constrained
-
[27]
Riabinin, Artem and Shulgin, Egor and Gruntkowska, Kaja and Richt. Gluon: Making. arXiv preprint arXiv:2505.13416 , year=
- [28]
- [29]
-
[30]
Mathematical Programming , year =
Nesterov, Yurii , title =. Mathematical Programming , year =
- [31]
-
[32]
On the global linear convergence of
Lacoste-Julien, Simon and Jaggi, Martin , journal=. On the global linear convergence of
-
[33]
Sinkhorn barycenters with free support via
Luise, Giulia and Salzo, Saverio and Pontil, Massimiliano and Ciliberto, Carlo , journal=. Sinkhorn barycenters with free support via
-
[34]
arXiv preprint arXiv:2312.11200 , year=
Solving the optimal experiment design problem with mixed-integer convex methods , author=. arXiv preprint arXiv:2312.11200 , year=
-
[35]
Roux, Christophe and Zimmer, Max and d'Aspremont, Alexandre and Pokutta, Sebastian , journal=. Don't Be Greedy, Just Relax!
-
[36]
Efficient Image and Video Co-localization with F rank- W olfe Algorithm
Joulin, Armand and Tang, Kevin and Fei-Fei, Li. Efficient Image and Video Co-localization with F rank- W olfe Algorithm. Computer Vision -- ECCV 2014. 2014
work page 2014
-
[37]
A Unified Continuous Greedy Algorithm for Submodular Maximization , year=
Feldman, Moran and Naor, Joseph and Schwartz, Roy , booktitle=. A Unified Continuous Greedy Algorithm for Submodular Maximization , year=
-
[38]
Mathematical Programming , volume=
Submodular functions: from discrete to continuous domains , author=. Mathematical Programming , volume=. 2019 , publisher=
work page 2019
-
[39]
Lacoste-Julien, Simon and Jaggi, Martin and Schmidt, Mark and Pletscher, Patrick , booktitle=. Block-coordinate. 2013 , organization=
work page 2013
-
[40]
N. Stochastic. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[41]
Designolle, S. Improved local models and new. Physical Review Research , volume=. 2023 , publisher=
work page 2023
-
[42]
Halbey, Jannis and Deza, Daniel and Zimmer, Max and Roux, Christophe and Stellato, Bartolomeo and Pokutta, Sebastian , journal=. Lower Bounds for
-
[43]
arXiv preprint arXiv:2211.14103 , year=
Conditional gradient methods , author=. arXiv preprint arXiv:2211.14103 , year=
-
[44]
arXiv preprint arXiv:2602.22608 , year=
Lower Bounds for Linear Minimization Oracle Methods Optimizing over Strongly Convex Sets , author=. arXiv preprint arXiv:2602.22608 , year=
- [45]
- [46]
-
[47]
SIAM Journal on Optimization , volume=
A linearly convergent variant of the conditional gradient algorithm under strong convexity, with applications to online and stochastic optimization , author=. SIAM Journal on Optimization , volume=. 2016 , publisher=
work page 2016
-
[48]
J. B. Rosen , journal =. The Gradient Projection Method for Nonlinear Programming. Part I. Linear Constraints , urldate =
-
[49]
Gilmore, Paul C. and Gomory, Ralph E. , year =. A Linear Programming Approach to the Cutting Stock Problem I , volume =. Oper Res , doi =
-
[50]
New Variants of Bundle Methods , volume =
Lemar. New Variants of Bundle Methods , volume =. Math. Program. , doi =. 1995 , month =
work page 1995
-
[51]
Geometric Algorithms and Combinatorial Optimization , publisher =
Gr. Geometric Algorithms and Combinatorial Optimization , publisher =. 1993 , doi =
work page 1993
-
[52]
Sparse Approximate Solutions to Semidefinite Programs
Hazan, Elad. Sparse Approximate Solutions to Semidefinite Programs. LATIN 2008: Theoretical Informatics. 2008
work page 2008
-
[53]
Nemirovski, Arkadi and Yudin, David , title =
- [54]
-
[55]
Exponentiated Gradient versus Gradient Descent for Linear Predictors , journal =. 1997 , issn =
work page 1997
-
[56]
Pokutta, Sebastian , journal=. The. 2024 , publisher=
work page 2024
- [57]
- [58]
- [59]
-
[60]
Moondra, Jai and Mortagy, Hassan and Gupta, Swati , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
work page 2021
-
[61]
arXiv preprint arXiv:1603.00522 , year=
Solving combinatorial games using products, projections and lexicographically optimal bases , author=. arXiv preprint arXiv:1603.00522 , year=
- [62]
- [63]
- [64]
-
[65]
arXiv preprint arXiv:1309.1541 , year=
Projection onto the probability simplex: An efficient algorithm with a simple proof, and an application , author=. arXiv preprint arXiv:1309.1541 , year=
-
[66]
Duchi, John and Shalev-Shwartz, Shai and Singer, Yoram and Chandra, Tushar , title =. 2008 , isbn =. doi:10.1145/1390156.1390191 , booktitle =
-
[67]
Rutkowski, Krzysztof E. , journal=. Closed-form expressions for projectors onto polyhedral sets in. 2017 , publisher=
work page 2017
-
[68]
The Thirteenth International Conference on Learning Representations , year=
Methods for Convex (L\_0, L\_1) -Smooth Optimization: Clipping, Acceleration, and Adaptivity , author=. The Thirteenth International Conference on Learning Representations , year=
-
[69]
Vyguzov, AA and Stonyakin, FS , journal=. Frank-
-
[70]
Journal of the Royal Statistical Society: Series B (Methodological) , volume =
Tibshirani, Robert , title =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =. 1996 , month =
work page 1996
-
[71]
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization , author=. SIAM review , volume=. 2010 , publisher=
work page 2010
-
[72]
Blei, David M. and Ng, Andrew Y. and Jordan, Michael I. , title =. J. Mach. Learn. Res. , month = mar, pages =. 2003 , issue_date =
work page 2003
-
[73]
Pinet: Optimizing hard-constrained neural networks with orthogonal projection layers , author=. arXiv preprint arXiv:2508.10480 , year=
-
[74]
International Conference on Machine Learning , pages=
On orthogonality and learning recurrent networks with long term dependencies , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[75]
Advances in Neural Information Processing Systems , volume=
Can we gain more from orthogonality regularizations in training deep networks? , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Artificial Intelligence and Statistics , pages=
Fairness constraints: Mechanisms for fair classification , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
work page 2017
-
[79]
Proceedings of the 35th International Conference on Machine Learning , pages =
A Reductions Approach to Fair Classification , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
work page 2018
-
[80]
Optimization Algorithms on Matrix Manifolds
Absil, Pierre-Antoine and Mahony, Robert and Sepulchre, Rodolphe. Optimization Algorithms on Matrix Manifolds
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.