Recognition: 1 theorem link
· Lean TheoremDocScope: Benchmarking Verifiable Reasoning for Trustworthy Long-Document Understanding
Pith reviewed 2026-05-15 05:06 UTC · model grok-4.3
The pith
Current multimodal models produce complete verifiable evidence chains in only 29% of correct long-document answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Answer accuracy cannot substitute for trajectory-level evaluation: even among correct answers, the highest observed rate of complete evidence chains is only 29%. Across all models, region grounding remains the weakest trajectory stage. The primary difficulty stems from aggregating evidence dispersed across long distances and multiple document clusters, while an oracle study identifies faithful perception and fact extraction as the dominant capability bottleneck. Cross-architecture comparisons further suggest that activated parameter count matters more than total scale.
What carries the argument
Four-stage evaluation protocol of Page Localization, Region Grounding, Fact Extraction, and Answer Verification with inter-stage decoupling and human-aligned judges, applied to hierarchical human annotations on PDF documents.
If this is right
- Standard end-to-end accuracy metrics are insufficient to assess trustworthiness in long-document understanding.
- Region grounding and long-range evidence aggregation must be targeted to improve verifiable reasoning.
- Enhancing perception and fact extraction capabilities will produce larger gains than further scaling.
- Activated parameter count serves as a stronger performance predictor than total model size across architectures.
- Domain-specific systems require focus on trajectory completeness beyond final answer correctness.
Where Pith is reading between the lines
- Training objectives that explicitly reward complete trajectories could reduce the gap between accuracy and verifiability.
- The benchmark could extend to multi-turn settings to test incremental evidence building across interactions.
- Similar trajectory-based evaluation may apply to other sequential modalities like video or audio documents.
- Current multimodal scaling approaches may undervalue explicit grounding mechanisms relative to parameter count.
Load-bearing premise
The four-stage evaluation protocol with inter-stage decoupling and human-aligned judges accurately measures the trustworthiness of reasoning trajectories without missing important failure modes or introducing judge bias.
What would settle it
A study identifying many cases where models score high across all four stages yet human reviewers rate the overall reasoning as untrustworthy, or low stage scores paired with trustworthy reasoning.
Figures






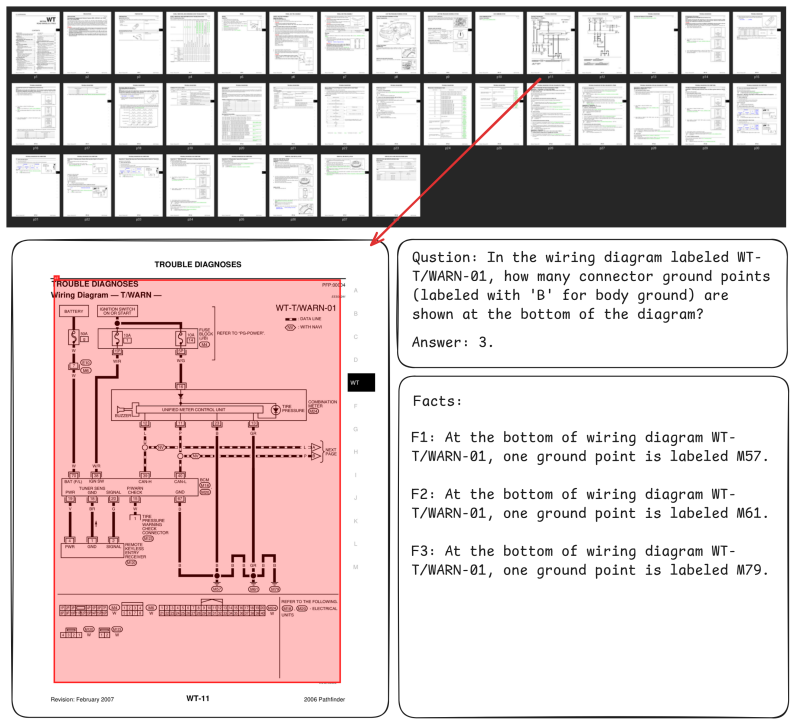

















read the original abstract
Evaluating whether Multimodal Large Language Models can produce trustworthy, verifiable reasoning over long, visually rich documents requires evaluation beyond end-to-end answer accuracy. We introduce DocScope, a benchmark that formulates long-document QA as a structured reasoning trajectory prediction problem: given a complete PDF document and a question, the model outputs evidence pages, supporting evidence regions, relevant factual statements, and a final answer. We design a four-stage evaluation protocol -- Page Localization, Region Grounding, Fact Extraction, and Answer Verification -- that audits each level of the trajectory independently through inter-stage decoupling, with all judges selected and calibrated via human alignment studies. DocScope comprises 1,124 questions derived from 273 documents, with all hierarchical evidence annotations completed by human annotators. We benchmark 6 proprietary models, 12 open-weight models, and several domain-specific systems. Our experiments reveal that answer accuracy cannot substitute for trajectory-level evaluation: even among correct answers, the highest observed rate of complete evidence chains is only 29\%. Across all models, region grounding remains the weakest trajectory stage. Furthermore, the primary difficulty stems from aggregating evidence dispersed across long distances and multiple document clusters, while an oracle study identifies faithful perception and fact extraction as the dominant capability bottleneck. Cross-architecture comparisons further suggest that activated parameter count matters more than total scale. The benchmark and code will be publicly released at https://github.com/MiliLab/DocScope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DocScope, a benchmark that reformulates long-document multimodal QA as a structured four-stage reasoning trajectory (page localization, region grounding, fact extraction, answer verification). It provides human-annotated hierarchical evidence for 1,124 questions across 273 PDFs, evaluates 18+ models (proprietary, open-weight, and domain-specific), and reports that answer accuracy cannot proxy for trajectory quality, with the highest complete evidence chain rate at only 29% and region grounding as the weakest stage. The primary bottlenecks identified are evidence aggregation across distant clusters and faithful perception/fact extraction.
Significance. If the four-stage protocol and human-aligned judges are shown to be reliable, DocScope would offer a useful shift from end-to-end accuracy metrics toward verifiable trajectory evaluation in long-document understanding. The public release of the benchmark and code, the scale of human annotations, and the cross-architecture finding that activated parameter count matters more than total scale are concrete strengths that could guide future work on handling dispersed visual evidence.
major comments (2)
- [four-stage evaluation protocol description] The four-stage evaluation protocol (described in the methods) relies on independent per-stage judges calibrated via human alignment studies, but the manuscript provides no quantitative results from those studies (e.g., inter-annotator agreement, calibration error rates, or agreement with human perception of dispersed evidence regions). This directly affects the validity of the headline 29% complete-chain rate and the claim that region grounding is the weakest stage.
- [experiments and results] Results section: the 29% complete evidence chain rate (even among correct answers) is reported without an explicit definition of how stages are aggregated into a 'complete chain,' without error bars, and without statistical controls for inter-model variance or document clustering effects. This makes it difficult to assess whether the gap between accuracy and trajectory quality is robust.
minor comments (2)
- [oracle study] The abstract and results mention 'oracle study' identifying perception and fact extraction as bottlenecks, but the manuscript does not clarify how the oracle was constructed or whether it controls for the same judge calibration issues.
- [figures and tables] Figure captions and table legends could more explicitly state the exact criteria used for 'region grounding' success in visually rich PDFs (e.g., IoU thresholds or human alignment thresholds).
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on DocScope. The comments highlight important aspects of clarity and validation that we address below. We have revised the manuscript to incorporate quantitative results from the alignment studies and to strengthen the statistical presentation of the results.
read point-by-point responses
-
Referee: [four-stage evaluation protocol description] The four-stage evaluation protocol (described in the methods) relies on independent per-stage judges calibrated via human alignment studies, but the manuscript provides no quantitative results from those studies (e.g., inter-annotator agreement, calibration error rates, or agreement with human perception of dispersed evidence regions). This directly affects the validity of the headline 29% complete-chain rate and the claim that region grounding is the weakest stage.
Authors: We agree that explicit quantitative validation of the judges is necessary to support the reliability of the four-stage protocol and the headline findings. Although the calibration process via human alignment studies is described in Section 3.3, we omitted the specific metrics in the initial submission. In the revised manuscript we have added a new subsection (3.3.1) and Appendix Table C.1 reporting inter-annotator agreement (Cohen’s κ = 0.84 for page localization, 0.79 for region grounding, 0.81 for fact extraction), mean calibration error rates (3.8 % across stages), and concordance with human judgments on dispersed evidence regions (84 % agreement). These results confirm that the independent judges are well-aligned with human perception and thereby support the validity of the 29 % complete-chain rate and the identification of region grounding as the weakest stage. revision: yes
-
Referee: [experiments and results] Results section: the 29% complete evidence chain rate (even among correct answers) is reported without an explicit definition of how stages are aggregated into a 'complete chain,' without error bars, and without statistical controls for inter-model variance or document clustering effects. This makes it difficult to assess whether the gap between accuracy and trajectory quality is robust.
Authors: We thank the referee for noting these presentation gaps. The definition of a complete evidence chain (all four stages judged correct in sequence) is stated in Section 4.2, but we have now made it more prominent with an explicit formula and example in the revised text. We have added error bars (standard error of the mean across the 1,124 questions) to all bar plots and tables in Section 5. To address inter-model variance and document clustering, we have inserted a new analysis (Section 5.4) that fits mixed-effects logistic regression models with random intercepts for documents and models; the accuracy–trajectory gap remains significant (p < 0.01) after these controls. These additions make the robustness of the 29 % figure and the stage-wise comparisons clearer. revision: yes
Circularity Check
No circularity: empirical benchmark rests on external human annotations
full rationale
The paper introduces DocScope as an empirical benchmark with 1,124 questions from 273 documents, all hierarchical evidence annotations completed by human annotators. The four-stage protocol (Page Localization, Region Grounding, Fact Extraction, Answer Verification) is defined via inter-stage decoupling and judges calibrated through human alignment studies, with no equations, parameter fitting, or predictions that reduce to inputs by construction. Results such as the 29% complete evidence chain rate are computed directly from model outputs against these external annotations. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps; the derivation chain is self-contained against human ground truth.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably and consistently identify evidence pages, regions, and factual statements across long documents
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four-stage evaluation protocol—Page Localization, Region Grounding, Fact Extraction, and Answer Verification—that audits each level of the trajectory independently through inter-stage decoupling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.08584, 2026a. Y uliang Liu, Biao Y ang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, and Xiang Bai. Textmonkey: An ocr-free large multimodal model for understanding document. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2026b. Jinghui Lu, Haiyang Y u, Y anjie Wang, Y ongjie Y e, Jingqun Tang, Ziwei Y ang, Bingh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
ZERO T O L E R A N C E FOR MISSING C I T A T I O N S : EVERY SINGLE se nt en ce stating a fact from ,→ the d oc um en t MUST end with EXACTLY ONE formal ci ta ti on . No e x c e p t i o n s . No ,→ excuses
-
[3]
C ITA TI ON FORMAT : The c it at ion MUST s tr ic tl y match this format : ‘[ page =N , ,→ doc _p ag e ="..." , bbox =[ x1 , y1 , x2 , y2 ]] ‘
-
[4]
The ci ta tio n MUST ,→ end with TWO right b rac ke ts ‘]] ‘ and then the period
SYNTAX ALERT : Pay close a t t e n t i o n to the closing br ac ket s . The ci ta tio n MUST ,→ end with TWO right b rac ke ts ‘]] ‘ and then the period . ( Correct : ‘0.512]]. ‘ ,→ / I n c o r r e c t : ‘0.512]. ‘)
-
[5]
F O R B I D D E N : NEVER use natural lan gu ag e to cite pages ( e . g . , DO NOT write " on ,→ page 5" , " in Table 7 on global page 51" , or " image 58") . You MUST use the ,→ bracket format
-
[6]
M A N D A T O R Y FINAL ANSWER TAG : You MUST c onc lu de your r es pon se with a concise ,→ final answer wrapped S TR IC TL Y and EXACTLY as : ‘< answer > your final answer </ answer > ‘
-
[7]
NO M AR KD OWN : Do not use headings , bold , italics , lists , or tables in your ,→ r e a s o n i n g or answer . Plain prose only ( fenced code blocks and LaTeX math ,→ are allowed when s tr ic tl y n e c e s s a r y ) . </ h ar d_c on st ra in ts > ## Page N u m b e r i n g Rule - Each page image is pr ec ede d and fol lo we d by a text marker ( e . g ...
work page 2023
-
[8]
Output your de ta ile d r e a s o n i n g process step by step
-
[9]
Pre - output Self - Check ( Perform si le nt ly ) : - Did I use the formal ‘[ page =...] ‘ format instead of saying " on page X "? - Does EVERY bbox array end with ‘]] ‘? - Does EVERY fact - bearing se nt enc e have exactly ONE c it at io n at the end ? - Is my final answer e x p l i c i t l y wrapped in ‘< answer > ‘ tags ?
-
[10]
Output your final concise answer wrapped S TR ICT LY as : ‘< answer > your final answer </ answer > ‘ C.2 Evaluation Metric Definitions This section provides the formal definitions of the metrics summarized in Section 2.4. Throughout, superscript ∗ denotes gold annotations and ˆPq = Pq ∩ P ∗ q denotes correctly retrieved pages for question q. Region Groundi...
-
[11]
Check if any Special S t r u c t u r a l Rule applies ; if so , apply it di re ct ly
-
[12]
O t h e r w i s e : locate GOLD [ i ] , form the red union , then : - GT content e f f e c t i v e l y rec al le d ? -> covered - M e a n i n g f u l overlap but s u b s t a n t i a l part missed ? -> i m p r e c i s e - O t h e r w i s e -> n o t _ c o v e r e d Tie - b re aki ng : prefer " covered " when >=90% of GT content / all s e m a n t i c a l l y...
-
[13]
Compare factual meaning , not exact wording
-
[14]
Ignore minor f o r m a t t i n g d i f f e r e n c e s such as commas , c ur ren cy symbols , ,→ capitalization , punctuation , spacing , or unit spacing . For example , "16 ,→ Mbytes " and "16 Mbytes " are c o n s i s t e n t
-
[15]
m o d e l _ a n s w e r may include extra explanation , units , or s u p p o r t i n g values if they ,→ do not c o n t r a d i c t g o l d _ a n s w e r
-
[16]
If the core number , entity , category , date , percentage , ratio , or c a l c u l a t i o n ,→ result differs from gold_answer , mark it i n c o n s i s t e n t
-
[17]
Missing ,→ req ui re d items or adding i n c o r r e c t extra items is i n c o n s i s t e n t
If the q ue st io n or g o l d _ a n s w e r r eq ui res mu lt ip le components , items , or a ,→ com pl et e list , m o d e l _ a n s w e r must include all req ui re d content . Missing ,→ req ui re d items or adding i n c o r r e c t extra items is i n c o n s i s t e n t
-
[18]
If m o d e l _ a n s w e r co nt ai ns the correct answer but also adds a false or ,→ c o n t r a d i c t o r y statement , mark it i n c o n s i s t e n t
-
[19]
If ,→ the name clearly differs , mark it i n c o n s i s t e n t
Be strict with proper names , o r g a n i z a t i o n names , product names , and labels . If ,→ the name clearly differs , mark it i n c o n s i s t e n t
-
[20]
Judge only from question , gold_answer , and ,→ m o d e l _ a n s w e r
Do not use ex te rna l k n o w l e d g e . Judge only from question , gold_answer , and ,→ m o d e l _ a n s w e r
-
[21]
If g o l d _ a n s w e r gives s ep ar at e c o m p o n e n t values but the q ue st io n asks for a ,→ com bi ne d total , a correct c omb in ed total in m o d e l _ a n s w e r is consistent , as ,→ long as it d ir ec tl y answers the qu est io n and does not c o n t r a d i c t ,→ g o l d _ a n s w e r . Return only valid JSON : {{ " c o n s i s t e n ...
work page 2000
-
[22]
Oracle Pages. The input context is restricted to the gold evidence pages while retaining the standard reasoning prompt, removing the page-localization burden
-
[23]
Oracle Regions. Building on (1), textual bounding-box descriptions of key evidence re- gions are injected into the prompt, additionally removing the region-grounding burden
-
[24]
Oracle Facts. Building on (2), the atomic facts contained in each annotated region are additionally provided, further removing the perceptual and fact-extraction burden. F .4 Oracle Evidence Access Study: Trajectory Metric Observations Beyond the answer-accuracy trends discussed in Section 4.3, we observe two consistent patterns across trajectory metrics....
-
[25]
For what purpose was the dataset created? Was there a specific task in mind? Was there a specific gap that needed to be filled? Please provide a description. A1: DocScope is a benchmark designed to evaluate the multimodal long-document understanding capabilities of models, primarily targeting question answering over long PDF documents. Unlike existing benchm...
-
[26]
Who created this dataset (e.g., which team, research group) and on behalf of which entity (e.g., company, institution, organization)? A2: This dataset is created by the authors of this paper
-
[27]
Who funded the creation of the dataset? If there is an associated grant, please provide the name of the grantor and the grant name and number . A3: N/A. H.2 Composition
-
[28]
What do the instances that comprise the dataset represent? Please provide a description. A1: DocScope currently contains 1,124 QA instances, each consisting of a question and its corre- sponding answer grounded in a long document. The questions cover both single-page understanding and multi-page reasoning scenarios, aiming to evaluate model performance un...
-
[29]
How many instances are there in total (of each type, if appropriate)? A2: There are 1,124 QA instances in total, including 1,046 answerable instances across seven ques- tion types—Visual Element Counting & Identification, Document Structure & Metadata, Numer- ical & Statistical Data, Technical Systems & Operational Procedures, Entity Attributes & Com- para...
-
[30]
The larger set consists of potential QA pairs constructed from real-world long documents
Does the dataset contain all possible instances or is it a sample? If the dataset is a sample, then what is the larger set? A3: DocScope is a curated sample rather than an exhaustive collection of all possible instances. The larger set consists of potential QA pairs constructed from real-world long documents. In DocScope, QA pairs are synthesized from rea...
-
[31]
What data does each instance consist of? Raw data or features? A4: Each instance in DocScope consists of a question, an answer, the supporting evidence required for reasoning, evidence bounding-box coordinates in the document, and the specific facts used in the reasoning process. The data are provided as raw document-based QA annotations rather than pre-ex...
-
[32]
Is there a label or target associated with each instance? If so, please provide a description. 47 A5: Y es. Each instance is associated with a target answer. For answerable questions, the target is the ground-truth answer derived from the supporting evidence in the document, along with evidence annotations such as evidences and bounding-box coordinates. F...
-
[33]
Is any information missing from individual instances? A6: No
-
[34]
Instances are explicitly categorized by question type and answerability
Are relationships between individual instances made explicit? A7: Y es. Instances are explicitly categorized by question type and answerability. Answerable instances are grouped into seven question types: Visual Element Counting & Identification, Docu- ment Structure & Metadata, Numerical & Statistical Data, Technical Systems & Operational Pro- cedures, En...
-
[35]
Are there recommended data splits (e.g., training, development/validation, testing)? A8: Y es. DocScope is primarily intended as an evaluation benchmark and is split into a validation set and a test set
-
[36]
Are there any errors, sources of noise, or redundancies in the dataset? A9: DocScope is constructed through model-assisted synthesis followed by strict review to reduce errors, noise, and unsupported annotations. However, as the QA pairs are synthesized from complex real-world long documents, residual annotation errors or ambiguous cases may still exist
-
[37]
Is the dataset self-contained, or does it link to or otherwise rely on external resources? A10: DocScope is self-contained. The released dataset will include the source PDF documents, questions, answers, supporting evidence, evidence bounding-box coordinates, and factual reasoning annotations
-
[38]
Does the dataset contain data that might be considered confidential? A11: No. The source documents are publicly available documents, and the dataset does not inten- tionally contain confidential information
-
[39]
Does the dataset contain data that might be offensive? A12: DocScope is not intended to contain offensive content. Manual review and filtering were conducted to remove or mitigate offensive, toxic, or sensitive content. H.3 Collection Process
-
[40]
QA pairs were synthesized using Claude-Opus-4.6 and then strictly reviewed
How was the data associated with each instance acquired? A1: DocScope instances were acquired from publicly available real-world long documents. QA pairs were synthesized using Claude-Opus-4.6 and then strictly reviewed
-
[41]
What mechanisms or procedures were used to collect the data? A2: DocScope was built through a model-assisted and human-reviewed pipeline, including docu- ment collection, QA synthesis, evidence annotation, and quality review
-
[42]
If the dataset is a sample from a larger set, what was the sampling strategy? A3: Purposeful sampling was used to cover representative long-document QA scenarios, including different evidence scopes, answerability settings, and question types
-
[43]
The annotators worked for approximately five days and were compensated
Who was involved in the data collection process? A4: DocScope was created by the authors, with 13 additional dedicated annotators involved in annotation and review. The annotators worked for approximately five days and were compensated
-
[44]
48 H.4 Preprocessing/cleaning/labeling
Over what timeframe was the data collected? A5: The data collection, synthesis, annotation, and review process took approximately two weeks. 48 H.4 Preprocessing/cleaning/labeling
-
[45]
Was any preprocessing/cleaning/labeling of the data done? A1: Y es. The dataset construction involved QA synthesis, evidence annotation, bounding-box an- notation, factual reasoning annotation, and strict review. The review process was used to verify that each answer was supported by the corresponding document evidence and that unanswerable questions were...
-
[46]
Was a data decontamination strategy employed? A2: Y es. Data decontamination was conducted through manual review and experimental checks to remove contaminated and duplicate instances
-
[47]
The tools and scripts used for data generation will be released
Is the software used to preprocess/clean/label the instances available? A3: Y es. The tools and scripts used for data generation will be released. H.5 Uses
-
[48]
Has the dataset been used for any tasks already? If so, please provide a description. A1: Y es. DocScope is used to evaluate multimodal long-document question answering. It supports fine-grained diagnosis of model abilities in evidence localization, information extraction, cross-page reasoning, answer generation, and hallucination control
-
[49]
Is there a repository that links to any or all papers or systems that use the dataset? If so, please provide a link or other access point. A2: N/A
-
[50]
What (other) tasks could the dataset be used for? A3: In addition to long-document question answering, DocScope can be used for evaluating evi- dence localization, multimodal information extraction, cross-page reasoning, visual grounding in documents, hallucination detection, and the robustness of models on unanswerable document-based questions
-
[51]
Is there anything about the composition of the dataset or the way it was collected that might impact future uses? Is there anything a future user could do to mitigate these undesirable harms? A4: Since the QA pairs are synthesized using a strong multimodal model and then reviewed, the dataset may reflect the coverage and biases of the source documents and ...
-
[52]
Are there tasks for which the dataset should not be used? If so, please provide a description. A5: No. H.6 Distribution
- [53]
-
[54]
How will the dataset will be distributed? Does the dataset have a digital object identifier (DOI)? A2: DocScope will be distributed through GitHub and Hugging Face. No DOI is currently available
-
[55]
When will the dataset be distributed? A3: The dataset will be distributed after the paper is accepted. 49
-
[56]
Will the dataset be distributed under a copyright or other license? A4: Y es. The dataset will be distributed under the Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License (CC BY -NC-SA 4.0)
-
[57]
Have any third parties imposed IP-based or other restrictions on the data associated with the instances? A5: No. The source documents are from publicly available resources, and no third-party IP-based or other restrictions have been imposed on the dataset
-
[58]
Do any export controls or other regulatory restrictions apply to the dataset or to individual instances? A6: No. H.7 Maintenance
-
[59]
Who will be supporting/hosting/maintaining the dataset? A1: The authors
-
[60]
How can the owner/curator/manager of the dataset be contacted (e.g., email address)? A2: Email addresses will be provided on the project homepage post-publication
-
[61]
A3: Any errata will be posted on the project GitHub repository
Is there an erratum? If so, please provide a link or other access point. A3: Any errata will be posted on the project GitHub repository
-
[62]
Will the dataset be updated? If so, please describe how often, by whom, and how updates will be communicated to users? A4: Y es. The authors plan to update the dataset, and updates will be communicated through the official GitHub and Hugging Face repositories
- [63]
-
[64]
If others want to extend/augment/build on/contribute to the dataset, is there a mechanism for them to do so? A6: N/A. 50
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.