Recognition: no theorem link
LLM-Agnostic Semantic Representation Attack
Pith reviewed 2026-05-12 01:09 UTC · model grok-4.3
The pith
Optimizing adversarial prompts for malicious semantic meaning rather than exact affirmative phrases guarantees convergence and cross-model transfer in LLM attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
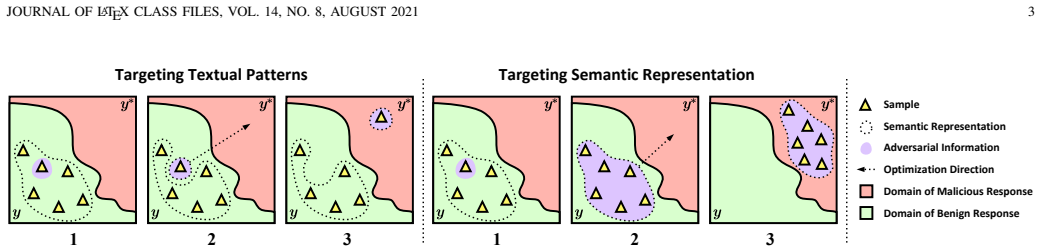
By targeting malicious semantic representations instead of exact textual templates and enforcing semantic coherence during discrete token optimization, the method establishes that coherence guarantees both white-box semantic convergence and black-box transferability, operationalized through incremental chunk expansion to achieve 99.71 percent average attack success across 26 LLMs.
What carries the argument
The Semantic Representation Heuristic Search (SRHS) algorithm, which expands adversarial prompts by adding coherent token chunks while preserving overall semantic meaning and structural interpretability.
Where Pith is reading between the lines
- Safety techniques would need to move from surface-phrase detection to semantic intent monitoring to remain effective.
- The same coherence principle could be tested for improving non-adversarial prompt engineering tasks such as instruction following.
- Closed-source models might be evaluated by measuring how well open-model attack prompts transfer when semantic targets are used.
Load-bearing premise
Semantic coherence can be reliably detected and maintained when optimizing prompts in discrete token space so that it produces convergence and transfer.
What would settle it
Applying the coherence-preserving search to a held-out collection of LLMs and finding that high measured semantic coherence does not produce high attack success or transfer would falsify the claimed relationship.
Figures



read the original abstract
Large Language Models (LLMs) increasingly employ alignment techniques to prevent harmful outputs. Despite these safeguards, attackers can circumvent them by crafting adversarial prompts. Predominant token-level optimization methods primarily rely on optimizing for exact affirmative templates (e.g., ``\textit{Sure, here is...}''). However, these paradigms frequently encounter bottlenecks such as suboptimal convergence, compromised prompt naturalness, and poor cross-model generalization. To address these limitations, we propose Semantic Representation Attack (SRA), a novel LLM-agnostic paradigm that fundamentally reconceptualizes adversarial objectives from exact textual targeting to malicious semantic representations. Theoretically, we establish the semantic Coherence-Convergence Relationship and derive a Cross-Model Semantic Generalization bound, proving that maintaining semantic coherence guarantees both white-box semantic convergence and black-box transferability. Technically, we operationalize this framework via the Semantic Representation Heuristic Search (SRHS) algorithm, which preserves interpretability and structural coherence of the adversarial prompts during incremental discrete token chunk expansion. Extensive evaluations demonstrate that our framework achieves a 99.71% average attack success rate across 26 open-source LLMs, with strong transferability and stealth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Representation Attack (SRA), a new LLM-agnostic adversarial prompting paradigm that targets malicious semantic representations instead of exact affirmative text templates. It claims to establish the semantic Coherence-Convergence Relationship and derive a Cross-Model Semantic Generalization bound proving that semantic coherence guarantees white-box convergence and black-box transferability. The SRHS algorithm implements this via incremental discrete token chunk expansion to preserve interpretability, and experiments report a 99.71% average attack success rate across 26 open-source LLMs with strong transferability and stealth.
Significance. If the theoretical relationships and bound are rigorously derived without circularity and the empirical results prove robust, the work could meaningfully advance adversarial attack research on aligned LLMs by moving beyond token-level optimization to semantic-level methods that improve naturalness and cross-model generalization.
major comments (3)
- [Theoretical claims] Theoretical section on Coherence-Convergence Relationship and Cross-Model Semantic Generalization bound: the manuscript asserts these relationships are established and proven to guarantee convergence and transferability, yet supplies no equations, proof sketches, or derivation steps, making it impossible to determine whether the results are independent of the SRHS heuristics or rest on unstated assumptions.
- [SRHS description and bound] SRHS algorithm and generalization bound: the bound derivation likely relies on continuous or Lipschitz-bounded semantic neighborhood properties (standard for such proofs), but SRHS performs discrete token chunk expansions that can produce semantic jumps outside any coherence neighborhood without detection; this gap directly undermines the claimed guarantee that coherence maintenance ensures transferability.
- [Evaluation] Experimental results: the 99.71% average ASR across 26 models is presented without baselines, error bars, statistical tests, or protocol details, so it cannot be assessed whether it validates the theoretical claims or merely reflects heuristic performance.
minor comments (1)
- [Abstract] The abstract is dense with new terminology (SRA, SRHS, Coherence-Convergence Relationship) introduced without forward references to where they are formally defined.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications where possible and committing to revisions that strengthen the presentation of our theoretical and empirical contributions without altering the core claims.
read point-by-point responses
-
Referee: Theoretical section on Coherence-Convergence Relationship and Cross-Model Semantic Generalization bound: the manuscript asserts these relationships are established and proven to guarantee convergence and transferability, yet supplies no equations, proof sketches, or derivation steps, making it impossible to determine whether the results are independent of the SRHS heuristics or rest on unstated assumptions.
Authors: We acknowledge that the current manuscript presents the Coherence-Convergence Relationship and Cross-Model Semantic Generalization bound primarily at a conceptual level without the full set of equations or proof sketches. This omission was intended to maintain readability but has hindered verification. The relationships are derived from properties of semantic embedding spaces and coherence metrics, and are designed to be independent of the specific heuristics in SRHS. In the revised version, we will include the key equations defining semantic coherence, the statement of the bound, the main assumptions (e.g., bounded distances in embedding space), and an outline of the derivation steps to allow readers to assess independence from implementation details. revision: yes
-
Referee: SRHS algorithm and generalization bound: the bound derivation likely relies on continuous or Lipschitz-bounded semantic neighborhood properties (standard for such proofs), but SRHS performs discrete token chunk expansions that can produce semantic jumps outside any coherence neighborhood without detection; this gap directly undermines the claimed guarantee that coherence maintenance ensures transferability.
Authors: The referee correctly identifies a potential tension between the continuous assumptions typical of generalization bounds and the discrete token expansions performed by SRHS. We will revise the manuscript to clarify how the incremental chunk expansion is constrained to remain within coherence neighborhoods, for example by introducing an explicit coherence threshold and a mechanism to detect and revert jumps. If the bound requires Lipschitz continuity, we will either extend the theoretical analysis to discrete settings or provide supporting analysis showing that observed expansions satisfy the neighborhood condition in practice. This addresses the gap while preserving the claim that maintained coherence supports transferability. revision: partial
-
Referee: Experimental results: the 99.71% average ASR across 26 models is presented without baselines, error bars, statistical tests, or protocol details, so it cannot be assessed whether it validates the theoretical claims or merely reflects heuristic performance.
Authors: We agree that the experimental reporting requires additional rigor to substantiate the theoretical claims. The reported average ASR will be supplemented in the revision with comparisons against established baselines (including token-level methods such as GCG), error bars derived from multiple independent runs, appropriate statistical tests for significance, and a complete experimental protocol detailing model versions, evaluation criteria, and hyperparameter settings. These additions will enable clearer assessment of whether the results align with the predicted benefits of semantic coherence for convergence and transfer. revision: yes
Circularity Check
No significant circularity in theoretical derivation
full rationale
The paper first states the establishment of the semantic Coherence-Convergence Relationship and derivation of the Cross-Model Semantic Generalization bound as independent theoretical contributions that prove guarantees for convergence and transferability. These precede the description of the SRHS algorithm as an operationalization in discrete token space. No load-bearing step reduces the bound or relationship to a fitted parameter, self-citation chain, or definitional tautology; the reported ASR is presented as empirical outcome rather than a constructed prediction. The derivation chain is therefore self-contained against the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Semantic Coherence-Convergence Relationship
invented entities (2)
-
Semantic Representation Attack (SRA)
no independent evidence
-
Semantic Representation Heuristic Search (SRHS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
T. B. Brown, “Language models are few-shot learners,”arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
A survey on multimodal large language models for autonomous driving,
C. Cui, Y . Ma, X. Cao, W. Ye, Y . Zhou, K. Liang, J. Chen, J. Lu, Z. Yang, K.-D. Liaoet al., “A survey on multimodal large language models for autonomous driving,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 958– 979
work page 2024
-
[5]
Lmdrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 120–15 130
work page 2024
-
[6]
Language models meet world models: Embodied experiences enhance language models,
J. Xiang, T. Tao, Y . Gu, T. Shu, Z. Wang, Z. Yang, and Z. Hu, “Language models meet world models: Embodied experiences enhance language models,”Advances in neural information processing systems, vol. 36, 2024
work page 2024
-
[7]
Large language models as generalizable policies for embodied tasks,
A. Szot, M. Schwarzer, H. Agrawal, B. Mazoure, R. Metcalf, W. Talbott, N. Mackraz, R. D. Hjelm, and A. T. Toshev, “Large language models as generalizable policies for embodied tasks,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[8]
Large language models in medicine,
A. J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, L. Gutierrez, T. F. Tan, and D. S. W. Ting, “Large language models in medicine,”Nature medicine, vol. 29, no. 8, pp. 1930–1940, 2023
work page 1930
-
[9]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohlet al., “Large language models encode clinical knowledge,”Nature, vol. 620, no. 7972, pp. 172– 180, 2023
work page 2023
-
[10]
Scaling instruction-finetuned language models,
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y . Tay, W. Fedus, Y . Li, X. Wang, M. Dehghani, S. Brahmaet al., “Scaling instruction-finetuned language models,”Journal of Machine Learning Research, vol. 25, no. 70, pp. 1–53, 2024
work page 2024
-
[11]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
work page 2023
-
[12]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[13]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,”Advances in neural information processing systems, vol. 30, 2017. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 17
work page 2017
-
[14]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Fast adversarial attacks on language models in one gpu minute,
V . S. Sadasivan, S. Saha, G. Sriramanan, P. Kattakinda, A. Chegini, and S. Feizi, “Fast adversarial attacks on language models in one gpu minute,” inForty-first International Conference on Machine Learning, 2024
work page 2024
-
[16]
Does refusal training in llms generalize to the past tense?
M. Andriushchenko and N. Flammarion, “Does refusal training in llms generalize to the past tense?” inThe Thirteenth International Conference on Learning Representations, 2025, pp. 85 406–85 420
work page 2025
-
[17]
Obscure but effective: Classical chinese jailbreak prompt optimization via bio-inspired search,
X. Huang, S. Qin, X. Jia, R. Duan, H. Yan, Z. Zeng, F. Yang, Y . Liu, and X. Jia, “Obscure but effective: Classical chinese jailbreak prompt optimization via bio-inspired search,” inThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[18]
Improved techniques for optimization-based jailbreaking on large language models,
X. Jia, T. Pang, C. Du, Y . Huang, J. Gu, Y . Liu, X. Cao, and M. Lin, “Improved techniques for optimization-based jailbreaking on large language models,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[19]
Intriguing properties of neural networks,
C. Szegedy, “Intriguing properties of neural networks,” inInternational Conference on Learning Representations, 2014
work page 2014
-
[20]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inInternational Conference on Learning Repre- sentations, 2015
work page 2015
-
[21]
Defense against adversarial attacks using high-level representation guided denoiser,
F. Liao, M. Liang, Y . Dong, T. Pang, X. Hu, and J. Zhu, “Defense against adversarial attacks using high-level representation guided denoiser,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1778–1787
work page 2018
-
[22]
Ensemble adversarial training: Attacks and defenses,
F. Tram `er, A. Kurakin, N. Papernot, I. Goodfellow, D. Boneh, and P. McDaniel, “Ensemble adversarial training: Attacks and defenses,” in International Conference on Learning Representations, 2018
work page 2018
-
[23]
Adversarial attacks and defenses for large language models (llms): methods, frameworks & challenges,
P. Kumar, “Adversarial attacks and defenses for large language models (llms): methods, frameworks & challenges,”International Journal of Multimedia Information Retrieval, vol. 13, no. 3, p. 26, 2024
work page 2024
-
[24]
Adversarial attacks on large language models,
J. Zou, S. Zhang, and M. Qiu, “Adversarial attacks on large language models,” inInternational Conference on Knowledge Science, Engineer- ing and Management. Springer, 2024, pp. 85–96
work page 2024
-
[25]
E. Shayegani, M. A. A. Mamun, Y . Fu, P. Zaree, Y . Dong, and N. Abu- Ghazaleh, “Survey of vulnerabilities in large language models revealed by adversarial attacks,”arXiv preprint arXiv:2310.10844, 2023
-
[26]
Ignore previous prompt: Attack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inNeurIPS ML Safety Workshop, 2022
work page 2022
-
[27]
Does refusal training in llms generalize to the past tense?
M. Andriushchenko and N. Flammarion, “Does refusal training in llms generalize to the past tense?”arXiv preprint arXiv:2407.11969, 2024
-
[28]
Autodan: Generating stealthy jailbreak prompts on aligned large language models,
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[29]
Autodan: Interpretable gradient-based ad- versarial attacks on large language models,
S. Zhu, R. Zhang, B. An, G. Wu, J. Barrow, Z. Wang, F. Huang, A. Nenkova, and T. Sun, “Autodan: Interpretable gradient-based ad- versarial attacks on large language models,” inFirst Conference on Language Modeling, 2024
work page 2024
-
[30]
Z. S. Harris and Z. S. Harris,Co-occurrence and transformation in linguistic structure. Springer, 1970
work page 1970
-
[31]
Paraphrasing with bilingual parallel corpora,
C. Bannard and C. Callison-Burch, “Paraphrasing with bilingual parallel corpora,” inProceedings of the 43rd annual meeting of the Association for Computational Linguistics (ACL’05), 2005, pp. 597–604
work page 2005
-
[32]
Vicuna: An open-source chatbot impressing gpt- 4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalez, I. Stoica, and E. P. Xing, “Vicuna: An open-source chatbot impressing gpt- 4 with 90%* chatgpt quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
work page 2023
-
[33]
Semantic representation attack against aligned large language models,
J. Lian, J. Pan, L. Wang, Y . Wang, S. Mei, and L.-P. Chau, “Semantic representation attack against aligned large language models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Sys- tems, 2025
work page 2025
-
[34]
Diffusion models for imperceptible and transferable adversarial attack,
J. Chen, H. Chen, K. Chen, Y . Zhang, Z. Zou, and Z. Shi, “Diffusion models for imperceptible and transferable adversarial attack,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 961–977, 2024
work page 2024
-
[35]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inInternational Conference on Learning Representations, 2018
work page 2018
-
[36]
Adversarial examples in the physical world,
A. Kurakin, I. J. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” inArtificial intelligence safety and security. Chapman and Hall/CRC, 2018, pp. 99–112
work page 2018
-
[37]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in2017 ieee symposium on security and privacy (sp). Ieee, 2017, pp. 39–57
work page 2017
-
[38]
Physical adversarial attacks for surveillance: A survey,
K. Nguyen, T. Fernando, C. Fookes, and S. Sridharan, “Physical adversarial attacks for surveillance: A survey,”IEEE Transactions on Neural Networks and Learning Systems, 2023
work page 2023
-
[39]
Fooling automated surveil- lance cameras: adversarial patches to attack person detection,
S. Thys, W. Van Ranst, and T. Goedem ´e, “Fooling automated surveil- lance cameras: adversarial patches to attack person detection,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019, pp. 0–0
work page 2019
-
[40]
Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition,
M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter, “Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition,” inProceedings of the 2016 acm sigsac conference on computer and communications security, 2016, pp. 1528–1540
work page 2016
-
[41]
Cba: Contextual background attack against optical aerial detection in the physical world,
J. Lian, X. Wang, Y . Su, M. Ma, and S. Mei, “Cba: Contextual background attack against optical aerial detection in the physical world,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1– 16, 2023
work page 2023
-
[42]
Unified adversarial patch for visible-infrared cross-modal attacks in the physical world,
X. Wei, Y . Huang, Y . Sun, and J. Yu, “Unified adversarial patch for visible-infrared cross-modal attacks in the physical world,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 4, pp. 2348–2363, 2023
work page 2023
-
[43]
Blackboxbench: A comprehensive benchmark of black-box adversarial attacks,
M. Zheng, X. Yan, Z. Zhu, H. Chen, and B. Wu, “Blackboxbench: A comprehensive benchmark of black-box adversarial attacks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 9, pp. 7867–7885, 2025
work page 2025
-
[44]
a ger, MHI Abdalla, Johannes Gasteiger, and Stephan G \
S. Geisler, T. Wollschl ¨ager, M. Abdalla, J. Gasteiger, and S. G¨unnemann, “Attacking large language models with projected gradient descent,” arXiv preprint arXiv:2402.09154, 2024
-
[45]
Gradient-based adversarial attacks against text transformers,
C. Guo, A. Sablayrolles, H. J ´egou, and D. Kiela, “Gradient-based adversarial attacks against text transformers,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 5747–5757
work page 2021
-
[46]
Semantic equivalent adversarial data augmentation for visual question answering,
R. Tang, C. Ma, W. E. Zhang, Q. Wu, and X. Yang, “Semantic equivalent adversarial data augmentation for visual question answering,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIX 16. Springer, 2020, pp. 437–453
work page 2020
-
[47]
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits, “Is bert really robust? a strong baseline for natural language attack on text classification and entailment,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, 2020, pp. 8018–8025
work page 2020
-
[48]
Adversarial attack on sentiment classification,
Y .-T. Tsai, M.-C. Yang, and H.-Y . Chen, “Adversarial attack on sentiment classification,” inProceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP, 2019, pp. 233–240
work page 2019
-
[49]
Jailbroken: How does llm safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llm safety training fail?”Advances in Neural Information Processing Sys- tems, vol. 36, 2024
work page 2024
-
[50]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1671–1685
work page 2024
-
[51]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,”Proceedings of Machine Learning Research, vol. 235, pp. 35 181–35 224, 2024
work page 2024
-
[52]
Jailbreaking Black Box Large Language Models in Twenty Queries
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,”arXiv preprint arXiv:2310.08419, 2023
work page internal anchor Pith review arXiv 2023
-
[53]
Tree of attacks: Jailbreaking black-box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box llms automatically,”Advances in Neural Information Processing Systems, vol. 37, pp. 61 065–61 105, 2024
work page 2024
-
[54]
Does safety training of llms generalize to semantically related natural prompts?
S. Addepalli, Y . Varun, A. Suggala, K. Shanmugam, and P. Jain, “Does safety training of llms generalize to semantically related natural prompts?” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[55]
Jailbreaking leading safety-aligned llms with simple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned llms with simple adaptive attacks,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[56]
Are aligned neural networks adversarially aligned?
N. Carlini, M. Nasr, C. A. Choquette-Choo, M. Jagielski, I. Gao, P. W. W. Koh, D. Ippolito, F. Tramer, and L. Schmidt, “Are aligned neural networks adversarially aligned?”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[57]
Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery,
Y . Wen, N. Jain, J. Kirchenbauer, M. Goldblum, J. Geiping, and T. Gold- stein, “Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery,”Advances in Neural Information Processing Systems, vol. 36, pp. 51 008–51 025, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18
work page 2023
-
[58]
Universal adversarial triggers for attacking and analyzing nlp,
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh, “Universal adversarial triggers for attacking and analyzing nlp,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019
work page 2019
-
[59]
Logan IV, Eric Wallace, and Sameer Singh
T. Shin, Y . Razeghi, R. L. Logan IV , E. Wallace, and S. Singh, “Auto- prompt: Eliciting knowledge from language models with automatically generated prompts,”arXiv preprint arXiv:2010.15980, 2020
-
[60]
Red teaming language models with language models,
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3419–3448
work page 2022
-
[61]
Y . Zeng, H. Lin, J. Zhang, D. Yang, R. Jia, and W. Shi, “How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 14 322–14 350
work page 2024
-
[62]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Baichuan 2: Open large-scale language models,
A. Yang, B. Xiao, B. Wang, B. Zhang, C. Bian, C. Yin, C. Lv, D. Pan, D. Wang, D. Yanet al., “Baichuan 2: Open large-scale language models,” arXiv preprint arXiv:2309.10305, 2023
-
[66]
Koala: A dialogue model for academic research,
X. Geng, A. Gudibande, H. Liu, E. Wallace, P. Abbeel, S. Levine, and D. Song, “Koala: A dialogue model for academic research,” Blog post, April 2023. [Online]. Available: https://bair.berkeley.edu/blog/2023/04/ 03/koala/
work page 2023
-
[67]
Orca 2: Teaching small language models how to reason.arXiv preprint arXiv:2311.11045, 2023
A. Mitra, L. Del Corro, S. Mahajan, A. Codas, C. Simoes, S. Agarwal, X. Chen, A. Razdaibiedina, E. Jones, K. Aggarwalet al., “Orca 2: Teaching small language models how to reason,”arXiv preprint arXiv:2311.11045, 2023
-
[68]
Zephyr: Direct distillation of lm alignment,
L. Tunstall, E. E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y . Belkada, S. Huang, L. V on Werra, C. Fourrier, N. Habibet al., “Zephyr: Direct distillation of lm alignment,” inFirst Conference on Language Modeling, 2024
work page 2024
-
[69]
Solar 10.7 b: Scaling large language models with simple yet effective depth up-scaling,
S. Kim, D. Kim, C. Park, W. Lee, W. Song, Y . Kim, H. Kim, Y . Kim, H. Lee, J. Kimet al., “Solar 10.7 b: Scaling large language models with simple yet effective depth up-scaling,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), 2024...
work page 2024
-
[70]
Openchat: Advancing open-source language models with mixed-quality data,
G. Wang, S. Cheng, X. Zhan, X. Li, S. Song, and Y . Liu, “Openchat: Advancing open-source language models with mixed-quality data,” in The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[71]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[72]
A. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. Chaplot, D. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnieret al., “Mistral 7b. arxiv 2023,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Starling-7b: Improving llm helpfulness & harmlessness with rlaif,
B. Zhu, E. Frick, T. Wu, H. Zhu, and J. Jiao, “Starling-7b: Improving llm helpfulness & harmlessness with rlaif,” November 2023
work page 2023
-
[74]
Smoothllm: Defend- ing large language models against jailbreaking attacks,
A. Robey, E. Wong, H. Hassani, and G. J. Pappas, “Smoothllm: Defend- ing large language models against jailbreaking attacks,”Transactions on Machine Learning Research, 2025
work page 2025
-
[75]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts,”arXiv preprint arXiv:2309.10253, 2023
work page internal anchor Pith review arXiv 2023
-
[76]
Purple llama CyberSecEval : A secure coding benchmark for language models
M. Bhatt, S. Chennabasappa, C. Nikolaidis, S. Wan, I. Evtimov, D. Gabi, D. Song, F. Ahmad, C. Aschermann, L. Fontanaet al., “Purple llama cyberseceval: A secure coding benchmark for language models,”arXiv preprint arXiv:2312.04724, 2023
-
[77]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” in 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 23–42. Jiawei Lianis pursuing dual Ph.D. degrees through the joint Ph.D. program between Northwestern Polytechnical University (...
work page 2025
-
[78]
Her research interests include AI for science, AI safety, and few-shot learning
She is currently a postdoctoral researcher at the Hong Kong Institute of AI for Science, City University of Hong Kong, Hong Kong SAR. Her research interests include AI for science, AI safety, and few-shot learning. Yi Wang(Member, IEEE) received the B.Eng. degree in electronic informa- tion engineering and the M.Eng. degree in information and signal proce...
work page 2013
-
[79]
= exp − 1 |c|+|y ∗ 1| |c|+|y∗ 1 |X i=1 logP(t i|t<i) = exp − 1 |c|+|y ∗ 1| |c|X i=1 logP(c i|c<i) + |y∗ 1 |X j=1 logP(y ∗ 1,j|c, y∗ 1,<j) . (23) Given thatH PPL(c⊕y ∗ 1)< τ, we can derive: exp − 1 |c|+|y ∗ 1| |c|X i=1 logP(c i|c<i) + |y∗ 1 |X j=1 logP(y ∗ 1,j|c, y∗ 1,<j) < τ − |y∗ 1 |X j=1 logP(y ∗ 1,j|c, y∗ 1,<j) − |c...
-
[80]
= mX i=1 log Pθ(y∗ 1,i|c, y∗ 1,<i) Pθ(y∗ 2,i|c, y∗ 2,<i) .(27) This sequence log-probability ratio quantifies token-level differences between two sequences in autoregressive con- texts. This formulation is particularly appropriate for language models because it captures the cumulative divergence in the model’s predictive behavior when generating semantica...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.