Recognition: 2 theorem links
· Lean TheoremForge: Quality-Aware Reinforcement Learning for NP-Hard Optimization in LLMs
Pith reviewed 2026-05-12 02:36 UTC · model grok-4.3
The pith
Quality-aware reinforcement learning on OPT-BENCH enables small LLMs to find high-quality solutions to NP-hard optimization problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
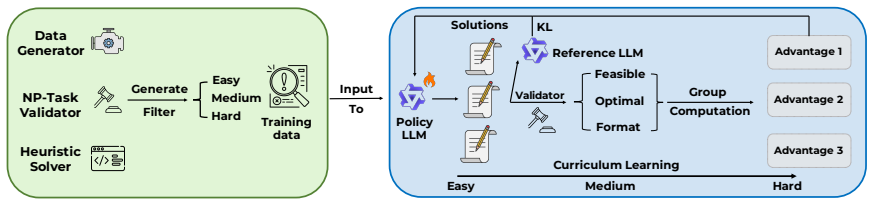
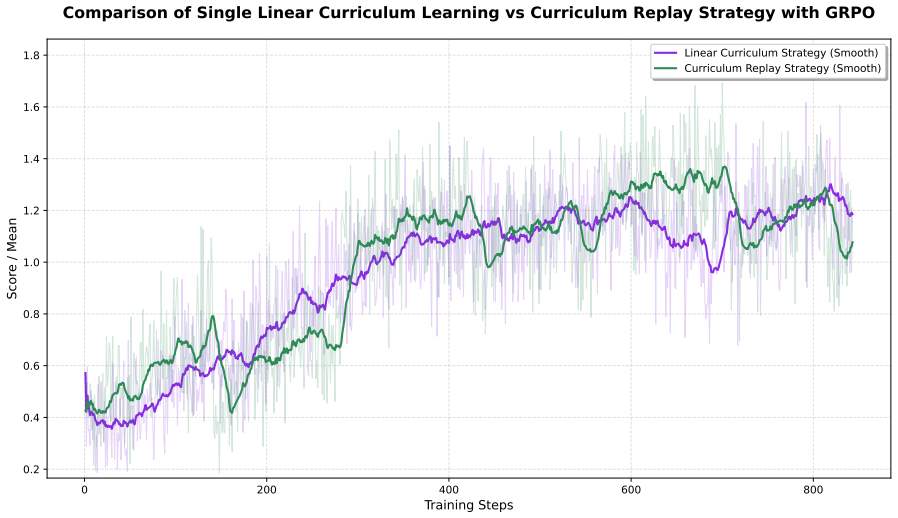
OPT-BENCH supplies scalable training infrastructure, a 1,000-instance benchmark measuring both Success Rate and Quality Ratio, and quality-aware rewards that replace binary correctness signals; training Qwen2.5-7B-Instruct-1M on 15K examples produces 93.1 percent SR and 46.6 percent QR while outperforming GPT-4o and transferring to unrelated reasoning domains.
What carries the argument
Quality-aware rewards that assign continuous scores reflecting solution optimality instead of binary feasibility checks.
Load-bearing premise
Quality verifiers can accurately score how close any solution is to the true optimum even when the optimum itself cannot be computed for the test instances.
What would settle it
Compute exact optimal solutions for a fresh set of NP-hard instances and measure whether the quality ratios produced by models trained on OPT-BENCH match the 46.6 percent benchmark figure.
Figures


read the original abstract
Large Language Models (LLMs) have achieved remarkable success on reasoning benchmarks through Reinforcement Learning with Verifiable Rewards (RLVR), excelling at tasks such as math, coding, logic, and puzzles. However, existing benchmarks evaluate only correctness, while overlooking optimality, namely the ability to find the best solutions under constraints. We propose OPT-BENCH, the first comprehensive framework for training and evaluating LLMs on NP-hard optimization problems through quality-aware RLVR. OPT-BENCH provides three key components: a scalable training infrastructure with instance generators, quality verifiers, and optimal baselines across 10 tasks; a rigorous benchmark with 1,000 instances evaluating both feasibility, measured by Success Rate, and quality, measured by Quality Ratio; and quality-aware rewards that enable continuous improvement beyond binary correctness. Training on Qwen2.5-7B-Instruct-1M with 15K examples achieves 93.1% SR and 46.6% QR, significantly outperforming GPT-4o, which achieves 29.6% SR and 14.6% QR. Beyond optimization, training on OPT-BENCH transfers to diverse tasks, including mathematics (+2.2%), logic (+1.2%), knowledge (+4.1%), and instruction following (+6.1%). Our analysis reveals that quality-aware rewards improve solutions by 28.8% over binary rewards, and that task diversity drives generalization more than data quantity, offering insights into RLVR scaling for complex reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OPT-BENCH, a framework for training and evaluating LLMs on NP-hard optimization problems via quality-aware Reinforcement Learning with Verifiable Rewards (RLVR). It comprises instance generators, quality verifiers, and optimal baselines for 10 tasks; a 1,000-instance benchmark assessing feasibility via Success Rate (SR) and optimality via Quality Ratio (QR); and quality-aware rewards that support continuous improvement beyond binary correctness. Training Qwen2.5-7B-Instruct-1M on 15K examples yields 93.1% SR and 46.6% QR, outperforming GPT-4o (29.6% SR, 14.6% QR). Quality-aware rewards improve solutions by 28.8% over binary rewards, with positive transfer to mathematics (+2.2%), logic (+1.2%), knowledge (+4.1%), and instruction following (+6.1%). Task diversity is shown to drive generalization more than data quantity.
Significance. If the quality verifiers are shown to track true optimality, the work would be significant for extending RLVR to optimization quality on NP-hard problems rather than binary correctness alone. The release of generators, verifiers, and baselines for 10 tasks provides a reusable infrastructure that could accelerate research in this area. The transfer gains and analysis of diversity versus quantity offer concrete insights for scaling RLVR on complex reasoning tasks. The benchmark itself is a clear contribution even if the numerical claims require further substantiation.
major comments (2)
- [Abstract and §3 (Methods)] Abstract and §3 (Methods): The central numerical claims (93.1% SR / 46.6% QR, 28.8% gain from quality-aware rewards, and superiority over GPT-4o) rest on the Quality Ratio metric. For NP-hard problems where exact optima are unavailable on the 1,000-instance test set, the manuscript must demonstrate that the quality verifiers correlate with true optimality. Validation against known optima on smaller, solvable instances (via exhaustive search or exact solvers) is required; without it, QR and the reported gains risk reflecting verifier heuristics rather than genuine optimization improvement. This is load-bearing for the primary results.
- [§4 (Results) and Table 1 (presumed)] §4 (Results) and Table 1 (presumed): No error bars, standard deviations, or statistical tests accompany the reported SR and QR values or the 28.8% improvement. Given the stochasticity of LLM sampling and RL training, multiple independent runs are needed to establish that the outperformance over GPT-4o and the reward-type ablation are reliable rather than run-specific.
minor comments (3)
- [Title and Abstract] The title refers to 'Forge' while the abstract and body introduce 'OPT-BENCH'; clarify whether Forge is the RL method, the full system, or a synonym, and ensure consistent nomenclature throughout.
- [§4 (Results)] Missing details on baseline construction: how GPT-4o and other models were prompted or sampled for the benchmark (e.g., temperature, few-shot examples, decoding strategy) should be specified to enable reproduction.
- [§5 (Transfer Experiments)] The transfer results (+2.2% math, etc.) are reported without specifying the evaluation benchmarks or whether the same quality-aware training was used; add precise cross-task evaluation protocols.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the manuscript. We provide point-by-point responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §3 (Methods)] Abstract and §3 (Methods): The central numerical claims (93.1% SR / 46.6% QR, 28.8% gain from quality-aware rewards, and superiority over GPT-4o) rest on the Quality Ratio metric. For NP-hard problems where exact optima are unavailable on the 1,000-instance test set, the manuscript must demonstrate that the quality verifiers correlate with true optimality. Validation against known optima on smaller, solvable instances (via exhaustive search or exact solvers) is required; without it, QR and the reported gains risk reflecting verifier heuristics rather than genuine optimization improvement. This is load-bearing for the primary results.
Authors: We agree that validating the quality verifiers' correlation with true optimality is essential to substantiate the Quality Ratio metric and the reported improvements. The original manuscript describes the quality verifiers and optimal baselines but does not include explicit validation experiments on small instances. In the revised manuscript, we will add a validation study in Section 3, where we generate small instances solvable by exact methods (e.g., dynamic programming or solvers for subsets of tasks), compute true optima, and report correlation coefficients (such as Spearman rank correlation) between verifier scores and true quality. This will confirm that QR reflects genuine optimization progress. revision: yes
-
Referee: [§4 (Results) and Table 1 (presumed)] §4 (Results) and Table 1 (presumed): No error bars, standard deviations, or statistical tests accompany the reported SR and QR values or the 28.8% improvement. Given the stochasticity of LLM sampling and RL training, multiple independent runs are needed to establish that the outperformance over GPT-4o and the reward-type ablation are reliable rather than run-specific.
Authors: We recognize the need for statistical rigor in reporting results from stochastic processes like LLM sampling and RL training. The presented results are from single training runs, which limits the assessment of variability. To address this, we will conduct multiple independent runs with different random seeds for the main experiments in the revised version. We will update Table 1 and the results section to include mean values with standard deviations or error bars, and perform statistical tests (e.g., t-tests) to assess the significance of the differences over GPT-4o and between reward types. revision: yes
Circularity Check
No circularity: empirical results rest on external benchmarks and verifiers rather than self-referential definitions or fitted predictions
full rationale
The paper presents an empirical RLVR training pipeline on OPT-BENCH, reporting measured Success Rate and Quality Ratio on a held-out 1,000-instance benchmark after training on 15K generated examples. No equations, derivations, or first-principles claims appear in the provided text that reduce the reported performance numbers (93.1% SR, 46.6% QR, 28.8% improvement) to quantities defined from the same fitted outputs or self-citations. The quality verifiers and optimal baselines are described as external components of the benchmark infrastructure; the superiority claims are statistical comparisons against GPT-4o on fixed test instances, not algebraic identities or renamings of inputs. This is the normal case of a self-contained empirical study whose central numbers are falsifiable against the benchmark rather than forced by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesRoptimal = Ms/Mh (maximization) or Mh/Ms (minimization); QR measures solution quality relative to heuristic baselines
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearFORGE-BENCH evaluates Success Rate and Quality Ratio on 10 NP-hard tasks with heuristic solvers
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Finereason: Evaluating and improving llms’ deliberate reasoning through reflective puzzle solving
FINEREASON: Evaluating and Improving LLMs' Deliberate Reasoning through Reflective Puzzle Solving , author=. arXiv preprint arXiv:2502.20238 , year=
-
[3]
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
work page 2024
-
[4]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
What, how, where, and how well? a survey on test-time scaling in large language models , author=. arXiv preprint arXiv:2503.24235 , year=
work page internal anchor Pith review arXiv
-
[5]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[6]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
FCoReBench: Can Large Language Models Solve Challenging First-Order Combinatorial Reasoning Problems? , author=. 2025 , eprint=
work page 2025
-
[8]
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond , author=. arXiv preprint arXiv:2503.10460 , year=
-
[9]
Greg Kamradt , title =
-
[10]
Jiayi Pan and Junjie Zhang and Xingyao Wang and Lifan Yuan and Hao Peng and Alane Suhr , title =
-
[11]
arXiv preprint arXiv:2406.12172 , year=
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems , author=. arXiv preprint arXiv:2406.12172 , year=
-
[12]
On the Measure of Intelligence
On the measure of intelligence , author=. arXiv preprint arXiv:1911.01547 , year=
work page internal anchor Pith review arXiv 1911
-
[13]
Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100,
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning , author=. arXiv preprint arXiv:2502.01100 , year=
-
[14]
Phd knowledge not required: A reasoning challenge for large language models
Phd knowledge not required: A reasoning challenge for large language models , author=. arXiv preprint arXiv:2502.01584 , year=
-
[15]
arXiv preprint arXiv:2410.06526 , year=
Kor-bench: Benchmarking language models on knowledge-orthogonal reasoning tasks , author=. arXiv preprint arXiv:2410.06526 , year=
-
[16]
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models , author=. arXiv preprint arXiv:2502.17387 , year=
-
[17]
arXiv preprint arXiv:2504.11456 , year=
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author=. arXiv preprint arXiv:2504.11456 , year=
-
[18]
arXiv preprint arXiv:2505.00551 , year=
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models , author=. arXiv preprint arXiv:2505.00551 , year=
-
[19]
Exploring data scaling trends and effects in reinforcement learning from human feedback , author=. arXiv preprint arXiv:2503.22230 , year=
-
[20]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding , author=. arXiv preprint arXiv:2503.02951 , year=
-
[21]
arXiv preprint arXiv:2502.14768 , year=
Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2502.14768 , year=
-
[22]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
VAPO: Efficient and reliable reinforcement learning for advanced reasoning tasks , author=. arXiv preprint arXiv:2504.05118 , year=
work page internal anchor Pith review arXiv
-
[24]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yuzhi Zhang, and Yue Wang
Reinforcement Learning for Reasoning in Large Language Models with One Training Example , author=. arXiv preprint arXiv:2504.20571 , year=
- [26]
-
[27]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
- [28]
-
[29]
arXiv preprint arXiv:2312.14925
A survey of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2312.14925 , volume=
-
[30]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
What’s behind ppo’s collapse in long-cot? value optimization holds the secret, 2025
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret , author=. arXiv preprint arXiv:2503.01491 , year=
-
[32]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
- [33]
- [34]
-
[35]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2503.18470 , year=
Code-r1: Reproducing r1 for code with reliable rewards , author=. arXiv preprint arXiv:2503.18470 , year=
-
[38]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. arXiv preprint arXiv:2503.24290 , year=
work page internal anchor Pith review arXiv
-
[39]
5: Advancing superb reasoning models with reinforcement learning , author=
Seed-thinking-v1. 5: Advancing superb reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2504.13914 , year=
-
[40]
FOLIO: Natural Language Reasoning with First-Order Logic
Folio: Natural language reasoning with first-order logic , author=. arXiv preprint arXiv:2209.00840 , year=
-
[41]
arXiv preprint arXiv:2112.05742 , year=
A Puzzle-Based Dataset for Natural Language Inference , author=. arXiv preprint arXiv:2112.05742 , year=
-
[42]
Transactions on Machine Learning Research , issn=
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[43]
Assessing and Enhancing the Robustness of Large Language Models with Task Structure Variations for Logical Reasoning , author=. arXiv preprint arXiv:2310.09430 , year=
-
[44]
Large language models are not strong abstract reasoners
Gendron, Ga\". Large language models are not strong abstract reasoners , year =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , articleno =. doi:10.24963/ijcai.2024/693 , abstract =
-
[45]
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles , author=. 2025 , eprint=
work page 2025
-
[46]
62nd Annual Meeting of the Association for Computational Linguistics, ACL 2024 , pages=
NPHardEval: Dynamic Benchmark on Reasoning Ability of Large Language Models via Complexity Classes , author=. 62nd Annual Meeting of the Association for Computational Linguistics, ACL 2024 , pages=. 2024 , organization=
work page 2024
-
[47]
arXiv preprint arXiv:2504.11239 , year=
Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs , author=. arXiv preprint arXiv:2504.11239 , year=
-
[48]
arXiv preprint arXiv:2505.02735 , year=
Formalmath: Benchmarking formal mathematical reasoning of large language models , author=. arXiv preprint arXiv:2505.02735 , year=
-
[49]
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai , author=. arXiv preprint arXiv:2411.04872 , year=
-
[50]
arXiv preprint arXiv:2506.04894 , year=
ICPC-Eval: Probing the Frontiers of LLM Reasoning with Competitive Programming Contests , author=. arXiv preprint arXiv:2506.04894 , year=
-
[51]
arXiv preprint arXiv:2506.10764 , year=
OPT-BENCH: Evaluating LLM Agent on Large-Scale Search Spaces Optimization Problems , author=. arXiv preprint arXiv:2506.10764 , year=
- [52]
-
[53]
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling , author=. 2025 , eprint=
work page 2025
-
[54]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[55]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
work page 2025
-
[56]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
- [57]
-
[58]
GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning , author=. 2025 , eprint=
work page 2025
-
[59]
SPPO: Sequence-Level PPO for Long-Horizon Reasoning Tasks , author=. 2026 , eprint=
work page 2026
-
[60]
Anchored Policy Optimization: Mitigating Exploration Collapse Via Support-Constrained Rectification , author=. 2026 , eprint=
work page 2026
-
[61]
Timely Machine: Awareness of Time Makes Test-Time Scaling Agentic , author=. 2026 , eprint=
work page 2026
-
[62]
Escaping the Context Bottleneck: Active Context Curation for LLM Agents via Reinforcement Learning , author=. 2026 , eprint=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.