Recognition: no theorem link
A Geometric Perspective on Next-Token Prediction in Large Language Models: Three Emerging Phases
Pith reviewed 2026-05-12 02:14 UTC · model grok-4.3
The pith
Large language models organize next-token prediction into three geometric phases across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
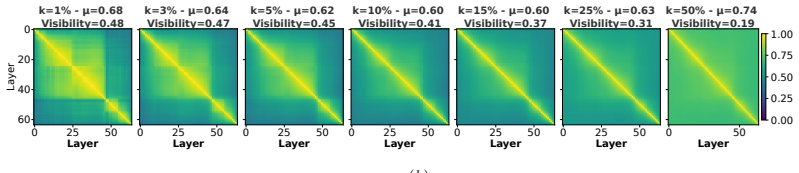
Across models, the trajectory of the dominant singular subspace of each layer's learned affine map shows three phases distinguished by rank dynamics: Seeding Multiplexing expands the candidate set in superposition with attention and feed-forward layers, the final token rising to lead in 20 to 35 percent of positions; Hoisting Overriding keeps rank stable while overriding existing subspaces to concentrate the distribution; Focal Convergence uses high-energy low-rank updates to align the winner with the unembedding direction. All updates remain approximately orthogonal to the residual stream, and phases one and three grow slowly with depth while phase two grows linearly.
What carries the argument
The predictive readout subspace, the leading k-dimensional singular subspace of a learned affine map from residual stream to next-token logits, whose successive positions on the Grassmann manifold trace the similarity profile that defines the phases.
If this is right
- The first phase seeds a candidate set in superposition whose leading member is the final token in 20 to 35 percent of positions.
- The second phase concentrates the candidate distribution by overriding subspaces without increasing effective rank.
- The third phase writes the selected token into a direction aligned with the unembedding matrix.
- Phases one and three lengthen slowly with added depth while phase two lengthens linearly, so most new capacity goes to disambiguation.
- The same three-phase structure appears for any k between 1 percent and 50 percent of the residual dimension.
Where Pith is reading between the lines
- If the phases are mechanistic, targeted edits at the boundaries between them could alter candidate generation or final selection independently.
- The linear scaling of the middle phase offers a geometric account for why depth improves performance on tasks that require resolving ambiguity among many options.
- The same subspace-tracking method could be applied to other sequence models to test whether analogous geometric phases appear outside language.
Load-bearing premise
The dominant singular subspaces of these affine maps locate the actual predictive information and their Grassmann trajectories mark real mechanistic phase boundaries rather than depending on the arbitrary choice of k.
What would settle it
Whether additional models outside the Qwen2.5 and OLMo2 families produce the same unimodal rise-plateau-descent similarity profiles whose segments align with the same three patterns of rank expansion, stabilization, and concentration.
Figures




















read the original abstract
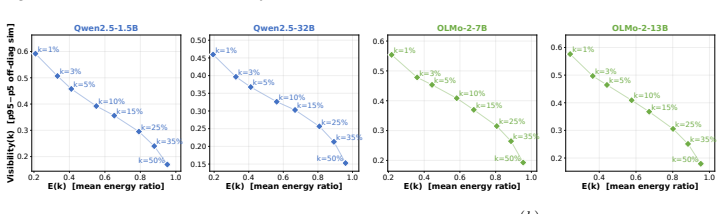
We investigate the geometry of predictive information across the layers of large language models (LLMs). We repurpose representation lenses-learned affine maps trained to predict the next token from intermediate residual streams-as geometric diagnostic tools. Rather than asking what the model predicts at each layer, we ask where predictive information resides and how it evolves across depth. We define at each layer a predictive readout subspace as the dominant k-dimensional singular subspace of such a map on the d-dimensional residual stream (where k is a resolution parameter), and track its trajectory on the Grassmann manifold as a similarity profile across layers. The profile is well described by unimodal distributions exhibiting a rise, near-plateau, and descent; varying k from 1% to 50% of d traces a Pareto frontier between visibility and energy retention, yet the same structure emerges at all scales. Across eight models from two families (Qwen2.5 and OLMo2, 1B-32B), we identify three geometric phases. Updates are approximately orthogonal to the residual stream throughout; what distinguishes the phases is their effect on the effective rank, which expands, stabilizes, and concentrates. In the first, Seeding Multiplexing, feed-forward memories and attention layers seed a candidate set in superposition in family-specific proportions, with the final token rising as leading candidate from 20% to 35% of positions across this phase. In the second, Hoisting Overriding, updates override existing subspaces to concentrate the candidate distribution without expanding the rank. In the third, Focal Convergence, high-energy low-rank updates write the winner into a form aligned with the unembedding direction. Phases 1 and 3 grow slowly with model depth, while Phase 2 expands linearly. The additional capacity of deeper LLMs is largely absorbed by candidate disambiguation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by fitting per-layer affine probes to predict next tokens from residual streams and tracking the trajectory of their dominant k-dimensional singular subspaces on the Grassmann manifold, three geometric phases emerge across depth in LLMs: Seeding Multiplexing (expanding effective rank via candidate superposition), Hoisting Overriding (stabilizing rank while overriding subspaces), and Focal Convergence (concentrating rank to align with the unembedding). This unimodal rise-plateau-descent structure in subspace similarity holds across eight models (Qwen2.5 and OLMo2, 1B-32B) and k ranging from 1% to 50% of d, with deeper models using extra capacity primarily for candidate disambiguation rather than expanding the candidate set.
Significance. If the phase distinctions prove robust, the work offers a geometric lens on how predictive information is organized and refined through LLM layers, with the empirical scope across two model families and multiple scales providing a useful baseline for interpretability research. The observation that Phase 2 scales linearly with depth while Phases 1 and 3 grow slowly is a concrete, falsifiable claim that could inform scaling laws and mechanistic understanding.
major comments (2)
- [Abstract / §3] Abstract and §3 (or equivalent methods/results): the assertion that 'the same structure emerges at all scales' for k from 1% to 50% of d lacks quantitative support such as measured stability of phase boundaries (e.g., layer indices where effective-rank transitions occur), error bars across models, or statistical tests for invariance under k. Since the three phases are defined precisely by whether updates expand, stabilize, or concentrate the effective rank of the k-subspace, sensitivity of these transitions to the resolution parameter k is load-bearing for the central claim.
- [Abstract / §4] Abstract and §4 (results on subspace alignment): no controls are reported comparing the alignment of the learned k-subspaces with next-token prediction against random k-dimensional subspaces of the residual stream or against the full d-dimensional space. Without such baselines, it remains unclear whether the reported Grassmann trajectories and phase distinctions capture predictive signal beyond what would arise from any k-dimensional projection, undermining the mechanistic interpretation of the phases.
minor comments (2)
- [§2] Notation for the Grassmann manifold distance or similarity profile should be defined explicitly (e.g., via principal angles) rather than left implicit when describing the 'similarity profile across layers'.
- [§5] The paper would benefit from a table summarizing the layer ranges or token positions assigned to each phase across the eight models to make the scaling claims (Phase 2 linear, others slow) directly verifiable.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the presentation of our geometric analysis. We address each major comment below and will incorporate the requested quantitative support and controls in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (or equivalent methods/results): the assertion that 'the same structure emerges at all scales' for k from 1% to 50% of d lacks quantitative support such as measured stability of phase boundaries (e.g., layer indices where effective-rank transitions occur), error bars across models, or statistical tests for invariance under k. Since the three phases are defined precisely by whether updates expand, stabilize, or concentrate the effective rank of the k-subspace, sensitivity of these transitions to the resolution parameter k is load-bearing for the central claim.
Authors: We agree that quantitative metrics are needed to substantiate invariance across k. In the revision we will report: (i) mean and standard deviation of phase-boundary layer indices (onset of rank expansion, onset of stabilization, onset of convergence) across all eight models for each k in {1%,5%,10%,25%,50%} of d; (ii) error bars on the Grassmann similarity curves; and (iii) a non-parametric test (Kruskal-Wallis with post-hoc Dunn) for differences in phase lengths across k values. These statistics will be added to §3 and a new appendix table. The existing qualitative observation that the unimodal rise-plateau-descent shape persists will be supplemented by these measures, confirming that phase distinctions remain stable within the tested range. revision: yes
-
Referee: [Abstract / §4] Abstract and §4 (results on subspace alignment): no controls are reported comparing the alignment of the learned k-subspaces with next-token prediction against random k-dimensional subspaces of the residual stream or against the full d-dimensional space. Without such baselines, it remains unclear whether the reported Grassmann trajectories and phase distinctions capture predictive signal beyond what would arise from any k-dimensional projection, undermining the mechanistic interpretation of the phases.
Authors: We accept that explicit baselines are required. We will add two controls to §4: (1) random k-dimensional subspaces sampled uniformly from the residual stream at each layer, and (2) the full d-dimensional residual stream itself. For both, we will compute the same Grassmann similarity profiles to the final unembedding direction and overlay them on the learned-subspace curves. Statistical significance will be assessed via permutation tests (10,000 shuffles) comparing the plateau-phase alignment of the learned subspaces against the random controls. These results will demonstrate that the learned subspaces exhibit reliably higher alignment than random projections of equal dimension, thereby supporting the claim that the observed phases reflect next-token predictive geometry rather than generic low-rank structure. revision: yes
Circularity Check
No circularity: phases are descriptive labels on empirical subspace trajectories
full rationale
The paper defines the predictive readout subspace via the dominant k-dimensional singular subspace of a learned affine map on the residual stream and tracks its Grassmannian trajectory as an empirical similarity profile across layers. The three phases (Seeding Multiplexing, Hoisting Overriding, Focal Convergence) are then assigned as descriptive labels based on observed changes in effective rank and candidate concentration; these labels do not enter the definition of the subspaces, the singular-value decomposition, or the manifold distance metric. No equations reduce the reported phase boundaries or structures to quantities fitted from the same data by construction, and the analysis is replicated across independent model families without self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- k
axioms (1)
- domain assumption The dominant k-dimensional singular subspace of the learned affine map captures the location of predictive information in the residual stream.
invented entities (1)
-
Three geometric phases (Seeding Multiplexing, Hoisting Overriding, Focal Convergence)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Associ- ation for Computational Linguistics and the 11th International Joint Conference on Nat- ural Langua...
-
[2]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.568. URL https://aclanthology.org/2021.acl-long.568/
-
[3]
Understanding intermediate layers using linear classifier probes, 2017
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2017. URLhttps://openreview.net/forum?id=ryF7rTqgl
work page 2017
-
[4]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[5]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Alberto Bietti, Minsu Roy, Antoine Mialon, Julien Mairal, Shariq Nikzad, Max Tänzer, Vered Rassin, A. Lajoie, et al. Eliciting latent predictions from transformers with the Tuned Lens.arXiv preprint arXiv:2303.08112, 2023. URL https://arxiv.org/abs/2303. 08112
work page internal anchor Pith review arXiv 2023
-
[6]
A multiscale analysis of mean-field transformers in the moderate interaction regime
Giuseppe Bruno, Federico Pasqualotto, and Andrea Agazzi. A multiscale analysis of mean-field transformers in the moderate interaction regime. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= WCRPgBpbcA
work page 2026
-
[7]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[8]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[9]
Privileged bases in the transformer residual stream.Transformer Circuits Thread, 2023
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. Privileged bases in the transformer residual stream.Transformer Circuits Thread, 2023. URL https://transformer-circuits. pub/2023/privileged-basis/index.html
work page 2023
-
[10]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen- tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic, November ...
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[11]
Patchscopes: a unifying framework for inspecting hidden representations of language models
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. Patchscopes: a unifying framework for inspecting hidden representations of language models. ICML’24. JMLR.org, 2024
work page 2024
-
[12]
When models manipulate manifolds: The geometry of a counting task, 2026
Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, and Joshua Batson. When models manipulate manifolds: The geometry of a counting task, 2026. URLhttps://arxiv.org/abs/2601.04480. 10
-
[13]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam.CoRR, abs/1711.05101, 2017. URLhttp://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088
work page 2022
-
[15]
Emergent linear representations in world models of self-supervised sequence models
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models. In Yonatan Belinkov, Sophie Hao, Jaap Jumelet, Na- joung Kim, Arya McCarthy, and Hosein Mohebbi, editors,Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 16–30, Singapore, ...
-
[16]
URLhttps://aclanthology.org/2023.blackboxnlp-1.2/
work page 2023
-
[17]
Interpreting GPT: the logit lens
nostalgebraist. Interpreting GPT: the logit lens. https://www.lesswrong.com/posts/ AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens, 2020
work page 2020
-
[18]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models, 2024. URLhttps://arxiv.org/abs/2311.03658
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
-
[21]
Riechers, Lucas Teixeira, Alexander Gietelink Oldenziel, and Sarah Marzen
Adam Shai, Paul M. Riechers, Lucas Teixeira, Alexander Gietelink Oldenziel, and Sarah Marzen. Transformers represent belief state geometry in their residual stream. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=YIB7REL8UC
work page 2024
-
[22]
Zhiqiang Shen, Tianhua Tao, Liqun Ma, Willie Neiswanger, Zhengzhong Liu, Hongyi Wang, Bowen Tan, Joel Hestness, Natalia Vassilieva, Daria Soboleva, and Eric Xing. Slimpajama-dc: Understanding data combinations for llm training, 2024. URL https://arxiv.org/abs/ 2309.10818
-
[23]
Low-rank lens for scalable llms interpretability
Giuseppe Trimigno, Gianfranco Lombardo, and Stefano Cagnoni. Low-rank lens for scalable llms interpretability. pages 35–40, 01 2026. doi: 10.14428/esann/2026.ES2026-221
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Jump to conclusions: Short-cutting transformers with linear transformations
Alexander Yom Din, Taelin Karidi, Leshem Choshen, and Mor Geva. Jump to conclusions: Short-cutting transformers with linear transformations. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.