Recognition: 1 theorem link
· Lean TheoremCATO: Charted Attention for Neural PDE Operators
Pith reviewed 2026-05-12 01:47 UTC · model grok-4.3
The pith
CATO learns a continuous latent chart to remap mesh points so axial attention can solve PDEs on complex geometries more accurately and efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
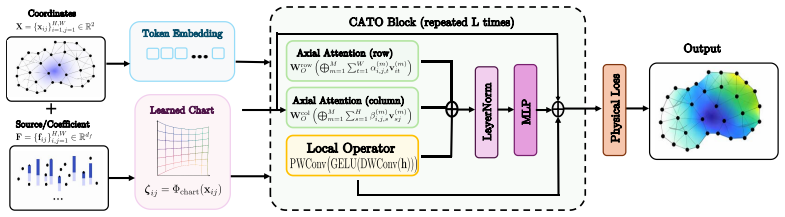
CATO learns a continuous latent chart that maps mesh coordinates into a chart space where chart-conditioned axial attention can represent low-rank axial solution operators with controlled error, and pairs this with a derivative-aware physics loss supervising solution values, gradients, and flux fields to achieve higher accuracy on PDEs over general geometries.
What carries the argument
The learned continuous latent chart, which remaps physical mesh coordinates into a space that makes axial attention efficient while preserving the geometry of physical interactions.
If this is right
- Under a favorable chart, charted axial attention approximates low-rank axial solution operators with bounded error.
- Small perturbations to the learned chart cause only bounded degradation in the approximation quality.
- The derivative-aware loss jointly supervising values, gradients, and flux improves physical fidelity and reduces oversmoothing for steady-state PDEs.
- CATO delivers an average 26.76 percent accuracy gain over the strongest baselines while cutting parameter count by 81.98 percent.
Where Pith is reading between the lines
- The same chart-learning step could be tested on time-dependent or nonlinear PDEs where the underlying geometry evolves.
- The latent-chart idea might transfer to other mesh-based tasks such as fluid simulation or structural analysis that currently rely on fixed coordinate attention.
- Explicit regularization of the chart mapping against known geometric invariants would be a direct way to test whether distortion remains controlled in practice.
Load-bearing premise
A trainable continuous latent chart can map arbitrary mesh coordinates so that physical interactions stay faithfully represented without distortion that would break the axial attention approximation.
What would settle it
A controlled experiment on a PDE with known solution over complex geometry in which the learned chart produces higher error than direct-attention baselines or the observed approximation error exceeds the theoretical bound after small chart perturbations.
Figures






read the original abstract
Neural operators have emerged as powerful data-driven solvers for PDEs, offering substantial acceleration over classical numerical methods. However, existing transformer-based operators still face critical challenges when modeling PDEs on complex geometries: directly processing over massive mesh points is computationally expensive, while operating in raw discretization coordinates may obscure the intrinsic geometry where physical interactions are more naturally expressed. To address these limitations, we introduce the Charted Axial Transformer Operator (CATO), a geometry-adaptive and derivative-aware neural operator for PDEs on general geometries. Instead of applying attention directly in the physical coordinate system, CATO learns a continuous latent chart that maps mesh coordinates into a learned chart space, where chart-conditioned axial attention efficiently captures long-range dependencies with reduced computational cost. In addition, CATO introduces a derivative-aware physics loss for steady-state PDEs that jointly supervises solution values, mesh-consistent gradients, and an auxiliary flux-like field, improving physical fidelity and reducing oversmoothing. We further provide a theoretical approximation result showing that, under a favorable chart, charted axial attention can represent low-rank axial solution operators with controlled error, and that small chart perturbations induce bounded approximation degradation. CATO achieves the best performance across all evaluated datasets, yielding an average improvement of approximately 26.76\% over the strongest competing baselines while reducing the number of parameters by 81.98\%. These results highlight the effectiveness of learning geometry-adaptive charts and derivative-aware physical supervision for accurate and efficient PDE operator learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Charted Axial Transformer Operator (CATO), a neural operator for PDEs on complex geometries. It learns a continuous latent chart mapping mesh coordinates to a chart space for efficient chart-conditioned axial attention, adds a derivative-aware physics loss supervising solution values, mesh-consistent gradients, and an auxiliary flux field, provides a theoretical approximation guarantee that charted axial attention represents low-rank axial operators with controlled error under a favorable chart (with bounded degradation under small perturbations), and reports state-of-the-art results with an average 26.76% improvement over baselines and 81.98% parameter reduction across evaluated datasets.
Significance. If the empirical gains hold under rigorous protocols and the learned charts can be shown to remain sufficiently close to the favorable regime for the approximation bound to apply, this could meaningfully advance geometry-adaptive neural operators by combining reduced-complexity attention with physics-informed supervision. The explicit theoretical result and parameter efficiency are notable strengths relative to prior transformer-based operators.
major comments (2)
- [Theoretical approximation result] Theoretical section (approximation result): The guarantee that charted axial attention represents low-rank axial solution operators with controlled error holds only under a favorable chart, with small perturbations inducing bounded degradation. The construction trains a continuous latent chart via the overall objective but provides no mechanism, constraint, or post-hoc verification to ensure the optimized chart remains within the small-perturbation regime; without this, the theoretical bound does not transfer to the reported experiments on general geometries.
- [Experiments] Experiments section: The abstract and results claim best performance with 26.76% average improvement and 81.98% parameter reduction, yet the manuscript supplies no explicit statement of dataset details, train/test splits, number of runs, or error-bar computation protocol. This is load-bearing for assessing whether the gains are robust or sensitive to post-hoc choices.
minor comments (2)
- [Method] The derivative-aware loss is described as jointly supervising value, gradient, and flux terms; clarify the exact weighting coefficients and how mesh-consistency of gradients is enforced in the implementation.
- [Preliminaries] Notation for the chart mapping function and axial attention operator should be introduced with a single consistent symbol set early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. We believe these clarifications and planned revisions will strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical approximation result] Theoretical section (approximation result): The guarantee that charted axial attention represents low-rank axial solution operators with controlled error holds only under a favorable chart, with small perturbations inducing bounded degradation. The construction trains a continuous latent chart via the overall objective but provides no mechanism, constraint, or post-hoc verification to ensure the optimized chart remains within the small-perturbation regime; without this, the theoretical bound does not transfer to the reported experiments on general geometries.
Authors: We appreciate the referee's observation on the conditions required for the theoretical guarantee. Our theoretical analysis in the manuscript derives the approximation bound specifically for favorable charts and provides a perturbation result showing that small deviations lead to bounded error increases. Although the chart is learned end-to-end without an explicit constraint enforcing the favorable regime, the joint optimization with the physics-informed loss encourages the discovery of charts that align with the underlying geometry, as evidenced by the superior empirical performance. To bridge the gap between theory and experiments, we will add a new subsection in the revised manuscript presenting a post-hoc verification procedure. This will involve computing the deviation of the learned chart from a constructed favorable chart (e.g., via principal component analysis on the mesh or similar) and confirming that the perturbations remain small enough for the bound to hold with high probability across our datasets. We agree that this verification is important for the claim's validity and will implement it in the revision. revision: partial
-
Referee: [Experiments] Experiments section: The abstract and results claim best performance with 26.76% average improvement and 81.98% parameter reduction, yet the manuscript supplies no explicit statement of dataset details, train/test splits, number of runs, or error-bar computation protocol. This is load-bearing for assessing whether the gains are robust or sensitive to post-hoc choices.
Authors: We acknowledge that the current manuscript lacks sufficient detail on the experimental setup, which is essential for reproducibility and for evaluating the robustness of the results. In the revised manuscript, we will expand the Experiments section (and add an appendix if necessary) to explicitly describe: the full specifications of each dataset including their origins and preprocessing steps; the train/test split ratios and the rationale for their selection; the number of independent training runs conducted for each method and dataset; and the exact method used to compute error bars, such as reporting mean and standard deviation over multiple seeds. These additions will allow for a thorough assessment of the reported performance gains and parameter reductions. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The abstract and description present CATO as introducing a learned continuous latent chart and a derivative-aware loss, together with a new theoretical approximation result that holds under a favorable chart condition. No equation or step is quoted that reduces a claimed prediction, bound, or performance metric to a fitted parameter or prior self-citation by construction. The approximation theorem is stated as an independent contribution rather than a tautology, and the reported improvements are empirical. This matches the default case of a paper whose central claims retain independent content outside any internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A continuous latent chart mapping exists that preserves the intrinsic geometry of the physical domain for attention purposes
invented entities (2)
-
Charted axial attention operator
no independent evidence
-
Derivative-aware physics loss (value + gradient + flux)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019. 2
work page 2019
-
[2]
Hamlet: Graph transformer neural operator for partial differential equations
Andrey Bryutkin, Jiahao Huang, Zhongying Deng, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Hamlet: Graph transformer neural operator for partial differential equations. InInternational Conference on Machine Learning, pages 4624–4641. PMLR, 2024. 2
work page 2024
-
[3]
Shuhao Cao. Choose a transformer: Fourier or galerkin.Advances in neural information processing systems, 34:24924–24940, 2021. 2, 3, 7, 8
work page 2021
-
[4]
Chun-Wun Cheng, Bin Dong, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Pde solvers should be local: Fast, stable rollouts with learned local stencils.arXiv preprint arXiv:2509.26186, 2025. 2
-
[5]
Mamba neural operator: Who wins? transformers vs
Chun-Wun Cheng, Jiahao Huang, Yi Zhang, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Mamba neural operator: Who wins? transformers vs. state-space models for pdes.Journal of Computational Physics, page 114567, 2025. 2
work page 2025
-
[6]
Spectral methods for partial differential equations.CUBO, A Mathematical Journal, 6(4):1–32, 2004
Bruno Costa. Spectral methods for partial differential equations.CUBO, A Mathematical Journal, 6(4):1–32, 2004. 1
work page 2004
-
[7]
Linear partial differential equations
Lokenath Debnath. Linear partial differential equations. InNonlinear partial differential equations for scientists and engineers, pages 1–147. Springer, 2012. 1
work page 2012
-
[8]
Gaurav Gupta, Xiongye Xiao, and Paul Bogdan. Multiwavelet-based operator learning for differential equations.Advances in neural information processing systems, 34:24048–24062,
-
[9]
Noir: Neural operator mapping for implicit representations.arXiv preprint arXiv:2603.13118, 2026
Sidaty El Hadramy, Nazim Haouchine, Michael Wehrli, and Philippe C Cattin. Noir: Neural operator mapping for implicit representations.arXiv preprint arXiv:2603.13118, 2026. 2
-
[10]
Gnot: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. Gnot: A general neural operator transformer for operator learning. InInternational Conference on Machine Learning, pages 12556–12569. PMLR, 2023. 2, 3, 7, 8
work page 2023
-
[11]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raoni ´c, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel De Bezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. Advances in Neural Information Processing Systems, 37:72525–72624, 2024. 2 10
work page 2024
-
[12]
Coarse-to-fine 3d mri reconstruction via 3d neural operators
Armeet Singh Jatyani, Jiayun Wang, Ryan Y Lin, Valentin Duruisseaux, and Anima Anandku- mar. Coarse-to-fine 3d mri reconstruction via 3d neural operators. InNeurIPS 2025 Workshop for Imageomics: Discovering Biological Knowledge from Images Using AI. 2
work page 2025
-
[13]
Jussi Leinonen, Boris Bonev, Thorsten Kurth, and Yair Cohen. Modulated adaptive fourier neural operators for temporal interpolation of weather forecasts.arXiv preprint arXiv:2410.18904,
-
[14]
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.arXiv preprint arXiv:2205.13671, 2022. 2, 3, 7, 8
-
[15]
Scalable transformer for pde surrogate modeling
Zijie Li, Dule Shu, and Amir Barati Farimani. Scalable transformer for pde surrogate modeling. Advances in Neural Information Processing Systems, 36:28010–28039, 2023. 3, 7, 8
work page 2023
-
[16]
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023. 2, 7, 8, 21, 22
work page 2023
-
[17]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.arXiv preprint arXiv:2010.08895, 2020. 2, 7, 8, 22, 24
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Moham- mad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry-informed neural operator for large-scale 3d pdes.Advances in Neural Information Processing Systems, 36:35836–35854, 2023. 2
work page 2023
-
[19]
Xinliang Liu, Bo Xu, Shuhao Cao, and Lei Zhang. Mitigating spectral bias for the multiscale operator learning.Journal of Computational Physics, 506:112944, 2024. 8
work page 2024
-
[20]
Ht-net: Hierarchical transformer based operator learning model for multiscale pdes
Xinliang Liu, Bo Xu, and Lei Zhang. Ht-net: Hierarchical transformer based operator learning model for multiscale pdes. 2022. 2, 3, 7
work page 2022
-
[21]
Lu Lu, Pengzhan Jin, and George Em Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193, 2019. 2
work page internal anchor Pith review arXiv 1910
-
[22]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[23]
U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
Md Ashiqur Rahman, Zachary E Ross, and Kamyar Azizzadenesheli. U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022. 2, 7, 8
-
[24]
Pavel ˆSolín.Partial differential equations and the finite element method. John Wiley & Sons,
-
[25]
Factorized fourier neural operators.arXiv preprint arXiv:2111.13802, 2021
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. Factorized fourier neural operators.arXiv preprint arXiv:2111.13802, 2021. 7, 8
-
[26]
H., Sankaran, S., Wang, H., Pappas, G
Sifan Wang, Jacob H Seidman, Shyam Sankaran, Hanwen Wang, George J Pappas, and Paris Perdikaris. Cvit: Continuous vision transformer for operator learning.arXiv preprint arXiv:2405.13998, 2024. 2
-
[27]
Yuan Wang, Surya T Sathujoda, Krzysztof Sawicki, Kanishk Gandhi, Angelica I Aviles-Rivero, and Pavlos G Lagoudakis. A fourier neural operator approach for modelling exciton-polariton condensate systems.Communications Physics, 2025. 2
work page 2025
-
[28]
U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow
Gege Wen, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M Benson. U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow. Advances in Water Resources, 163:104180, 2022. 2, 7, 8 11
work page 2022
-
[29]
Solving high-dimensional PDEs with latent spectral models
Haixu Wu, Tengge Hu, Huakun Luo, Jianmin Wang, and Mingsheng Long. Solving high- dimensional pdes with latent spectral models.arXiv preprint arXiv:2301.12664, 2023. 2, 7, 8
-
[30]
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for pdes on general geometries.arXiv preprint arXiv:2402.02366, 2024. 2, 3, 7, 8, 24
-
[31]
Improved operator learning by orthogonal attention.arXiv preprint arXiv:2310.12487, 2023
Zipeng Xiao, Zhongkai Hao, Bokai Lin, Zhijie Deng, and Hang Su. Improved operator learning by orthogonal attention.arXiv preprint arXiv:2310.12487, 2023. 2, 3, 7, 8, 23
-
[32]
Saot: An enhanced locality-aware spectral transformer for solving pdes
Chenhong Zhou, Jie Chen, and Zaifeng Yang. Saot: An enhanced locality-aware spectral transformer for solving pdes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28928–28936, 2026. 2, 3, 7, 8
work page 2026
-
[33]
Hang Zhou, Yuezhou Ma, Haixu Wu, Haowen Wang, and Mingsheng Long. Unisolver: Pde- conditional transformers towards universal neural pde solvers.arXiv preprint arXiv:2405.17527,
-
[34]
23 D.2 Hyperparameters and architecture details
2 12 CATO: Charted Attention for Neural PDE Operators – Appendix Contents A Table of Notation 13 B Further Theoretical Results 16 C Benchmarks Details 21 D Implementation details 23 D.1 Training Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 D.2 Hyperparameters and architecture details . . . . . . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.