Recognition: no theorem link
ParityFuzz: Finding Inconsistencies across Solidity Compilers via Fine-Grained Mutation and Differential Analysis
Pith reviewed 2026-05-12 02:26 UTC · model grok-4.3
The pith
ParityFuzz identifies inconsistencies among Solidity compilers by mutating contracts and comparing normalized outputs across different environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
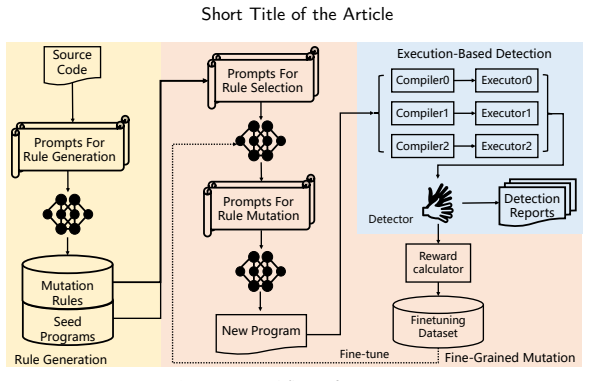
ParityFuzz operates in three stages: deriving syntax- and boundary-oriented mutation rules by examining compilers and execution environments, using reinforcement learning to choose effective mutations for generating test programs, and compiling plus executing those programs across multiple compilers followed by normalization and comparison to locate inconsistencies.
What carries the argument
Fine-grained mutation rules combined with reinforcement learning selection and cross-environment differential analysis after result normalization.
If this is right
- Up to 18 times higher compilation success rate than prior fuzzers.
- 1.8 times higher code coverage than state-of-the-art tools.
- Detection of 64 previously unknown inconsistencies across six compilers.
- Eleven issues have been fixed in the affected compilers.
- Findings have produced a bounty from the Polkadot community.
Where Pith is reading between the lines
- The same mutation-plus-normalization pattern could be adapted to test consistency in other languages that have several independent compilers.
- Inconsistencies found this way may indicate deeper semantic mismatches that could be turned into exploits if left unaddressed.
- Developers migrating contracts should add cross-compiler checks as a standard step before deployment.
Load-bearing premise
The normalization process and cross-environment comparisons separate real compiler differences from artifacts introduced by the testing setup or normalization rules themselves.
What would settle it
Re-running the same mutated contracts in a single shared execution environment and checking whether the reported inconsistencies remain or disappear would show if they stem from genuine compiler behavior.
Figures















read the original abstract
The Solidity smart contract ecosystem has rapidly grown, leading to multiple compilers targeting different blockchain platforms or improving compilation efficiency. Although many compilers aim to be compatible with the primary Solidity compiler (Solc), significant inconsistencies in compilation and execution remain. These inconsistencies hinder contract migration, mislead developers during debugging, and may introduce exploitable vulnerabilities, causing financial losses. Existing testing techniques mainly focus on bugs within a single compiler or perform differential testing in the same execution environment. However, they are insufficient for detecting cross-compiler inconsistencies, as they lack mechanisms to explore triggering conditions and compare bytecode across environments. We propose ParityFuzz, a cross-compiler differential testing framework for Solidity. It operates in three stages. First, it derives mutation rules, including syntax- and boundary-oriented rules, by analyzing compilers and execution environments. Second, it uses reinforcement learning to select effective mutation rules for test generation. Third, it compiles and executes programs across multiple compilers, then normalizes and compares results to detect inconsistencies. Our evaluation shows ParityFuzz is efficient and effective. It achieves up to 18x higher compilation success rate and 1.8x higher code coverage than state-of-the-art fuzzers. It uncovers 64 previously unknown inconsistencies across six compilers. Notably, 11 issues have been fixed, and our findings received a bounty from the Polkadot community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ParityFuzz, a three-stage cross-compiler differential testing framework for Solidity. Stage 1 derives syntax- and boundary-oriented mutation rules by analyzing compilers and execution environments; Stage 2 applies reinforcement learning to select effective rules for generating test programs; Stage 3 compiles and executes the programs across six compilers, normalizes the outputs, and compares them to detect inconsistencies. Evaluation reports up to 18x higher compilation success rate and 1.8x higher code coverage than prior fuzzers, plus discovery of 64 previously unknown inconsistencies (11 fixed, with a Polkadot bounty).
Significance. If the normalization and comparison reliably isolate true semantic inconsistencies rather than harness or platform artifacts, the work would be a useful contribution to compiler compatibility and security in the Solidity ecosystem. The practical outcomes (fixes and bounty) provide concrete evidence of impact. However, the empirical claims rest on an under-specified comparison step whose soundness directly determines whether the 64 findings and performance gains are trustworthy.
major comments (2)
- [Evaluation] Evaluation section: the normalization rules and cross-environment comparison procedure (the core of Stage 3) receive no concrete description, pseudocode, or examples. No ablation study is reported that shows how altering or removing the normalization changes the count of 64 inconsistencies, and no independent validation (manual review, re-execution oracle, or false-positive rate) is provided. This directly undermines the central claim that the detected differences are previously unknown semantic inconsistencies rather than artifacts of the testing harness, gas accounting, memory layout, or EVM/WASM differences.
- [Approach] Approach, third stage: the exact comparison metric used to declare an inconsistency (e.g., bytecode equality after normalization, execution trace equivalence, or output equality) is not stated, nor is any mechanism described for controlling false positives arising from environment setup. Without these details the reported 18x success-rate and 1.8x coverage gains cannot be assessed or reproduced.
minor comments (2)
- [Abstract] Abstract: the phrase 'up to 18x higher compilation success rate' is not accompanied by the identity of the baseline fuzzer or the precise experimental conditions, making the headline claim difficult to interpret at a glance.
- The paper would benefit from a small table or figure illustrating one concrete normalization rule and the before/after effect on a pair of compiler outputs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the normalization rules and cross-environment comparison procedure (the core of Stage 3) receive no concrete description, pseudocode, or examples. No ablation study is reported that shows how altering or removing the normalization changes the count of 64 inconsistencies, and no independent validation (manual review, re-execution oracle, or false-positive rate) is provided. This directly undermines the central claim that the detected differences are previously unknown semantic inconsistencies rather than artifacts of the testing harness, gas accounting, memory layout, or EVM/WASM differences.
Authors: We agree that the original manuscript lacked sufficient detail on the normalization rules and cross-environment comparison procedure in Stage 3. In the revised manuscript, we will add a dedicated subsection in the Evaluation section providing a concrete description of the normalization rules (including handling of gas accounting, memory layout, and platform-specific artifacts), pseudocode for the comparison logic, and examples of programs and their normalized outputs. We will also include an ablation study quantifying the impact of normalization on the number of reported inconsistencies and report the results of a manual review of a random sample of the 64 inconsistencies, along with a false-positive rate estimate derived from re-execution oracles. These additions will directly address concerns about whether the differences represent true semantic inconsistencies. revision: yes
-
Referee: [Approach] Approach, third stage: the exact comparison metric used to declare an inconsistency (e.g., bytecode equality after normalization, execution trace equivalence, or output equality) is not stated, nor is any mechanism described for controlling false positives arising from environment setup. Without these details the reported 18x success-rate and 1.8x coverage gains cannot be assessed or reproduced.
Authors: The comparison metric used in Stage 3 is normalized output equality: after compilation and execution, we compare return values, emitted events, and final contract state across compilers once environment-specific elements (gas costs, absolute memory addresses, and EVM/WASM layout differences) have been stripped via normalization. We will explicitly state this metric and describe the false-positive controls (standardized harness, multiple re-executions per program, and filtering of transient differences) in the revised Approach section. These clarifications will allow readers to assess and reproduce both the inconsistency detections and the reported performance improvements. revision: yes
Circularity Check
No circularity: purely empirical tool paper with no derivation chain
full rationale
The paper describes a three-stage empirical fuzzing framework (mutation rule derivation from analysis, RL-based selection, and cross-compiler compilation/execution with normalization for differential comparison). No equations, predictions, uniqueness theorems, or ansatzes are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Results (64 inconsistencies, 18x/1.8x gains) are reported as experimental outcomes rather than tautological outputs of internal definitions. Normalization and comparison steps are methodological choices whose validity can be externally validated or falsified; they do not create circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bernhard, L., Scharnowski, T., Schloegel, M., Blazytko, T., Holz, T., 2022. Jit-picking: Differential fuzzing of javascript engines, in: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp. 351–364
work page 2022
-
[2]
Chen, Y., Su, T., Sun, C., Su, Z., Zhao, J., 2016. Coverage-directed differentialtestingofjvmimplementations,in:proceedingsofthe37th ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 85–99
work page 2016
-
[3]
Chen, Y., Zhong, R., Hu, H., Zhang, H., Yang, Y., Wu, D., Lee, W.,
-
[4]
One engine to fuzz’em all: Generic language processor testing with semantic validation, in: 2021 IEEE Symposium on Security and Privacy (SP), IEEE. pp. 642–658
work page 2021
- [5]
-
[6]
Solc.https://github.com/ethereum/solidity
Collective, A., 2026a. Solc.https://github.com/ethereum/solidity
-
[7]
Collective, A., 2026b. Solidity history bugs. https://github.com/ ethereum/solidity/blob/develop/docs/bugs.json
-
[8]
Solidity test programs.https://github.com/ ethereum/solidity/tree/develop/test
Collective, A., 2026c. Solidity test programs.https://github.com/ ethereum/solidity/tree/develop/test
-
[9]
Introducing solar.https://www.paradigm.xyz/ 2024/11/solar
DaniPopes, G.K., 2024. Introducing solar.https://www.paradigm.xyz/ 2024/11/solar
work page 2024
-
[10]
DefiLlama,2025. Defillama-defidashboard. https://defillama.com/
work page 2025
-
[11]
Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt
Deng, Y., Xia, C.S., Yang, C., Zhang, S.D., Yang, S., Zhang, L., 2023. Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt. arXiv preprint arXiv:2304.02014
-
[12]
Eom, J., Jeong, S., Kwon, T., 2024. Fuzzing javascript interpreters with coverage-guided reinforcement learning for llm-based mutation, in: Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 1656–1668
work page 2024
-
[13]
Even-Mendoza, K., Sharma, A., Donaldson, A.F., Cadar, C., 2023. Grayc: Greybox fuzzing of compilers and analysers for c, in: Pro- ceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 1219–1231
work page 2023
-
[14]
Protocol buffers.https://protobuf.dev/
Google, 2024. Protocol buffers.https://protobuf.dev/
work page 2024
-
[15]
Groce,A.,vanTonder,R.,Kalburgi,G.T.,LeGoues,C.,2022. Making no-fuss compiler fuzzing effective, in: Proceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction, pp. 194–204
work page 2022
-
[16]
Fuzzilli: Fuzzing for javascript jit compiler vulnerabilities., in: NDSS
Groß, S., Koch, S., Bernhard, L., Holz, T., Johns, M., 2023. Fuzzilli: Fuzzing for javascript jit compiler vulnerabilities., in: NDSS
work page 2023
-
[17]
ever-node.https://github.com/everx-labs/ever-node
Labs, E., 2023. ever-node.https://github.com/everx-labs/ever-node
work page 2023
-
[18]
Differences between sold and solc
Labs, E., 2024a. Differences between sold and solc. https:// github.com/everx-labs/TVM-Solidity-Compiler/blob/master/API.md
-
[19]
Sold.https://github.com/everx-labs/TVM-Solidity- Compiler
Labs, E., 2025. Sold.https://github.com/everx-labs/TVM-Solidity- Compiler
work page 2025
-
[20]
era-test-node.https://github.com/matter-labs/era- test-node
Labs, M., 2024b. era-test-node.https://github.com/matter-labs/era- test-node
-
[21]
Labs, M., 2026. Zksolc. https://github.com/matter-labs/era- compiler-solidity
work page 2026
-
[22]
Ma, H., Zhang, W., Shen, Q., Tian, Y., Chen, J., Cheung, S.C., 2024. Towards understanding the bugs in solidity compiler, in: Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 1312–1324
work page 2024
-
[23]
Mitropoulos,C.,Sotiropoulos,T.,Ioannidis,S.,Mitropoulos,D.,2023. Syntax-aware mutation for testing the solidity compiler, in: European SymposiumonResearchinComputerSecurity,Springer.pp.327–347
work page 2023
-
[24]
NEAR, 2025. borsh. https://borsh.io/
work page 2025
-
[25]
Ofenbeck, G., Rompf, T., Püschel, M., 2016. Randir: differential testing for embedded compilers, in: Proceedings of the 2016 7th ACM SIGPLAN Symposium on Scala, pp. 21–30
work page 2016
-
[26]
Ou, X., Li, C., Jiang, Y., Xu, C., 2024. The mutators reloaded: Fuzzing compilers with large language model generated mutation operators, in: Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4, pp. 298–312
work page 2024
-
[27]
Solar.https://github.com/paradigmxyz/solar
Paradigm, 2025. Solar.https://github.com/paradigmxyz/solar
work page 2025
-
[28]
Differences between revive and solc
Polkadot, 2026. Differences between revive and solc. https://contracts.polkadot.io/revive_compiler/differences_ yul_translation/
work page 2026
-
[29]
Qwen, 2026a. Qwen-coder-plus. https://bailian.console.aliyun. com/?tab=model#/model-market/detail/qwen-coder-plus
-
[30]
Qwen2.5-coder-0.5b-instruct.https://huggingface.co/ Qwen/Qwen2.5-Coder-0.5B-Instruct
Qwen, 2026b. Qwen2.5-coder-0.5b-instruct.https://huggingface.co/ Qwen/Qwen2.5-Coder-0.5B-Instruct
-
[31]
Qwen2.5-coder-7b-instruct.https://huggingface.co/ Qwen/Qwen2.5-Coder-7B-Instruct
Qwen, 2026c. Qwen2.5-coder-7b-instruct.https://huggingface.co/ Qwen/Qwen2.5-Coder-7B-Instruct. Bowei Su et al.:Preprint submitted to Elsevier Page 14 of 15 Short Title of the Article
-
[32]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.,
-
[33]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao,Z.,Wang,P.,Zhu,Q.,Xu,R.,Song,J.,Bi,X.,Zhang,H.,Zhang, M., Li, Y., Wu, Y., et al., 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Differences between solang and solc
Solang, 2023. Differences between solang and solc. https:// solang.readthedocs.io/en/v0.3.3/targets/solana.html#solidity- for-solana-incompatibilities-with-solidity-for-ethereum
work page 2023
-
[36]
Solang.https://github.com/hyperledger-solang/ solang
Solang, H., 2025a. Solang.https://github.com/hyperledger-solang/ solang
-
[37]
Solang, H., 2025b. Test cases in solang. https://github.com/ hyperledger-solang/solang/tree/main/tests/solana_tests
-
[38]
Contract abi specification.https://docs.soliditylang
Solidity, 2025. Contract abi specification.https://docs.soliditylang. org/en/latest/abi-spec.html
work page 2025
-
[39]
Parityfuzz.https://zenodo.org/records/19944888
Su, B., 2025. Parityfuzz.https://zenodo.org/records/19944888
-
[40]
Decoding an empty tuple causes error in solang
Subway2023, 2025a. Decoding an empty tuple causes error in solang. https://github.com/hyperledger-solang/solang/issues/1727
-
[41]
Subway2023, 2025b. Deleting an array element causes the array to be deleted in solang.https://github.com/hyperledger-solang/solang/ issues/1785
-
[42]
ripemd160 is unavailable in zksolc.https:// github.com/matter-labs/era-compiler-solidity/issues/275
Subway2023, 2025c. ripemd160 is unavailable in zksolc.https:// github.com/matter-labs/era-compiler-solidity/issues/275
-
[43]
Zksolc default codegen problem
Subway2023, 2025d. Zksolc default codegen problem. https:// github.com/matter-labs/era-compiler-solidity/issues/272
-
[44]
Sun, C., Le, V., Su, Z., 2016. Finding and analyzing compiler warning defects, in: Proceedings of the 38th International Conference on Software Engineering, pp. 203–213
work page 2016
-
[45]
Test cases in revive.https://github.com/ paritytech/revive/blob/main/crates/runner/src/lib.rs
Technologies, P., 2025. Test cases in revive.https://github.com/ paritytech/revive/blob/main/crates/runner/src/lib.rs
work page 2025
-
[46]
Technologies, P., 2026. Revive. https://github.com/paritytech/ revive
work page 2026
-
[47]
Differential testing solidity compiler through deep contract manipulation and mutation
Tian, Z., Wang, F., Chen, Y., Chen, L., 2024. Differential testing solidity compiler through deep contract manipulation and mutation
work page 2024
-
[48]
Detecting c++ compiler front-end bugs via grammar mutation and differential testing
Tu,H.,Jiang,H.,Zhou,Z.,Tang,Y.,Ren,Z.,Qiao,L.,Jiang,L.,2022. Detecting c++ compiler front-end bugs via grammar mutation and differential testing. IEEE Transactions on Reliability 72, 343–357
work page 2022
-
[49]
Isolating compiler bugs by generating effective witness programs with large language models
Tu, H., Zhou, Z., Jiang, H., Yusuf, I.N.B., Li, Y., Jiang, L., 2024. Isolating compiler bugs by generating effective witness programs with large language models. IEEE Transactions on Software Engineering
work page 2024
-
[50]
Wang, J., Chen, B., Wei, L., Liu, Y., 2019. Superion: Grammar-aware greybox fuzzing, in: 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), IEEE. pp. 724–735
work page 2019
-
[51]
Wang, J., Zhang, Z., Liu, S., Du, X., Chen, J., 2023a. {FuzzJIT}:{Oracle-Enhanced} fuzzing for {JavaScript} engine {JIT} compiler, in: 32nd USENIX Security Symposium (USENIX Security 23), pp. 1865–1882
-
[52]
Rustlantis: Randomized differential testing of the rust compiler
Wang, Q., Jung, R., 2024. Rustlantis: Randomized differential testing of the rust compiler. Proceedings of the ACM on Programming Languages 8, 1955–1981
work page 2024
-
[53]
Wang, W., Benea, A., Ivancic, F., 2023b. Zero-config fuzzing for microservices, in: 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), IEEE. pp. 1840–1845
work page 2023
-
[54]
A code knowledge graph-enhanced system for llm-based fuzz driver generation
Xu, H., Ma, W., Zhou, T., Zhao, Y., Chen, K., Hu, Q., Liu, Y., Wang, H., 2024. A code knowledge graph-enhanced system for llm-based fuzz driver generation. arXiv preprint arXiv:2411.11532
-
[55]
White-box compiler fuzzing empowered by large language models
Yang, C., Deng, Y., Lu, R., Yao, J., Liu, J., Jabbarvand, R., Zhang, L., 2023. White-box compiler fuzzing empowered by large language models. arXiv preprint arXiv:2310.15991
-
[56]
Your fix is my exploit: Enabling comprehensive dl library api fuzzing with large language models
Zhang,K.,Wang,S.,Han,J., Zhu,X.,Li,X.,Wang,S.,Wen,S.,2025. Your fix is my exploit: Enabling comprehensive dl library api fuzzing with large language models. arXiv preprint arXiv:2501.04312
-
[57]
Differences between zksolc and solc
ZKsync, 2026. Differences between zksolc and solc. https:// docs.zksync.io/zksync-protocol/differences/evm-instructions. Bowei Su et al.:Preprint submitted to Elsevier Page 15 of 15
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.