Recognition: 2 theorem links
· Lean TheoremConstant-Target Energy Matching: A Unified Framework for Continuous and Discrete Density Estimation
Pith reviewed 2026-05-12 03:04 UTC · model grok-4.3
The pith
Constant-Target Energy Matching recovers the log-density from samples alone by training against a constant target of 1 using a bounded energy-difference transform.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTEM replaces ordinary density-ratio regression with a bounded energy-difference transform and derives from it a sample-only training objective with the constant target 1. The learned scalar potential recovers log p without partition-function estimation or explicit unbounded ratio regression.
What carries the argument
The bounded energy-difference transform, which converts the problem of matching densities into minimizing a simple loss against the constant value 1.
If this is right
- CTEM provides a unified objective for density estimation on continuous, discrete, and mixed-variable data.
- The learned potential directly approximates log p up to a constant, eliminating the need for partition function estimation.
- Training requires only samples from the data distribution, with no explicit negative samples or ratio targets.
- Across benchmarks, it yields improved density estimates and higher-quality samples compared to existing methods.
Where Pith is reading between the lines
- This constant-target formulation could extend naturally to other energy-based generative models that currently rely on ratio estimation.
- Applying CTEM to very high-dimensional discrete spaces, such as molecular configurations, would test its scalability without modification.
- Since the method avoids unbounded targets, it may reduce the need for specialized regularization in low-probability regions.
Load-bearing premise
The bounded energy-difference transform produces a training objective whose minimizer exactly recovers the log-density up to a constant on general state spaces.
What would settle it
Train CTEM on samples from a standard normal distribution in one dimension and check whether the learned potential matches the true log-density up to a constant shift on a grid of test points; a large mismatch would falsify the recovery claim.
Figures



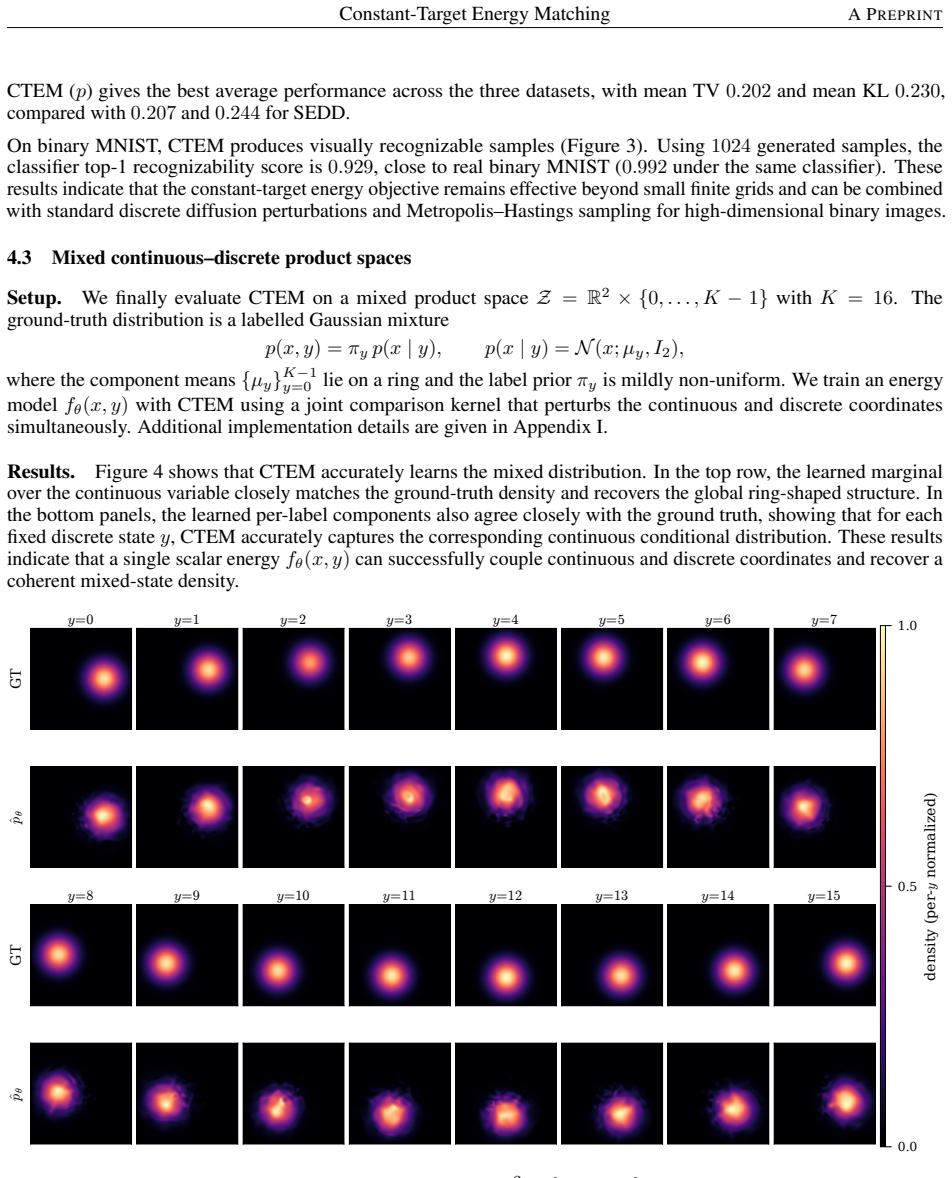
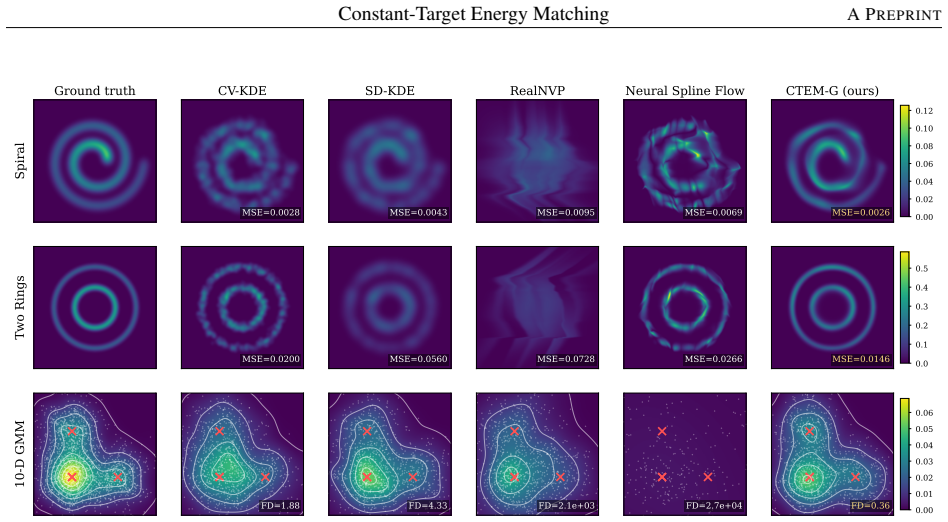
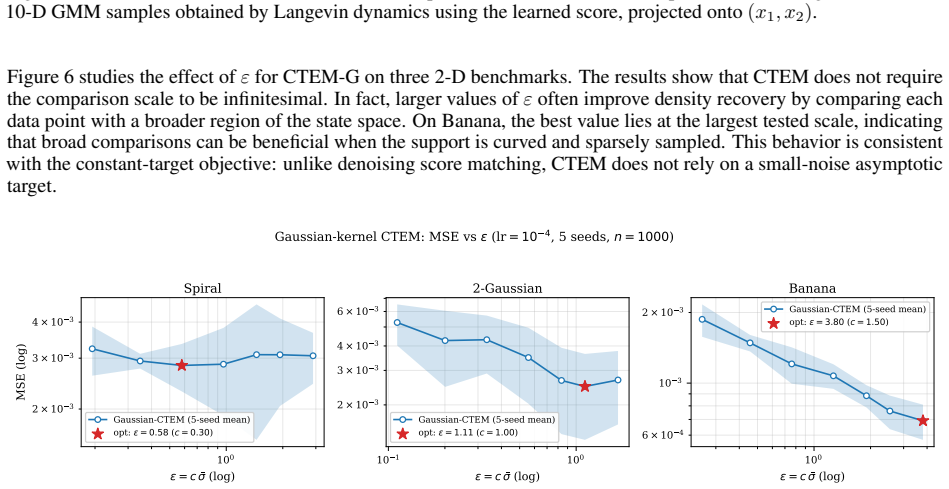



read the original abstract
Density estimation is a central primitive in probabilistic modeling, yet continuous, discrete, and mixed-variable domains are often treated by separate objectives, limiting the ability to exploit a common statistical structure across data types. Continuous score-based methods rely on log-density gradients, while discrete extensions typically use concrete score whose unbounded targets become unstable near low-probability states. We introduce Constant-Target Energy Matching (CTEM), a unified energy-based framework for density estimation on general state spaces. CTEM replaces ordinary density-ratio regression with a bounded energy-difference transform and derives from it a sample-only training objective with the constant target 1. The learned scalar potential recovers log p without partition-function estimation or explicit unbounded ratio regression. Across continuous, discrete, and mixed-variable benchmarks, CTEM substantially improves density estimation over competitive baselines and yields higher-quality samples under standard sampling procedures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Constant-Target Energy Matching (CTEM), a unified energy-based framework for density estimation on continuous, discrete, and mixed state spaces. It replaces standard density-ratio regression with a bounded energy-difference transform to derive a sample-only training objective whose target is the constant 1. The central claim is that the learned scalar potential recovers log p (up to an additive constant) without partition-function estimation or explicit unbounded ratio regression. Empirical evaluations across benchmarks in each domain report improved density estimation and sample quality relative to competitive baselines.
Significance. If the exact recovery property holds on general state spaces, CTEM would provide a meaningful unification that avoids domain-specific instabilities (e.g., unbounded targets near low-probability discrete states) while remaining sample-only. The constant-target formulation is attractive for implementation and could simplify modeling of heterogeneous data. The reported benchmark gains add practical value, but overall significance is limited by the need to confirm that the minimizer is exactly log p without hidden dependence on the reference measure.
major comments (2)
- [Theoretical derivation of the CTEM objective] The claim that the constant-target objective has a minimizer that recovers log p exactly (up to constant) for arbitrary state spaces is load-bearing. The bounded energy-difference transform must be constructed so its expectation is invariant to the choice of reference measure (counting measure on discrete spaces versus Lebesgue on continuous). The manuscript should supply the explicit derivation (likely in the main theoretical section or appendix) showing how the stationary point equals log p and confirming that no additional regularity conditions on p or measure-specific adjustments are required.
- [Proof or analysis of recovery property] No derivation steps, error analysis, or proof sketch for the log-density recovery appear in the provided abstract or high-level description. If such material exists in the full text (e.g., Section 3 or Appendix A), it must be clearly signposted; otherwise the central theoretical guarantee remains unverified and the empirical improvements cannot be confidently attributed to exact recovery.
minor comments (1)
- [Method section] Clarify the precise definition of the bounded energy-difference transform and its dependence (or independence) on the reference measure early in the method section to aid readers working across discrete and continuous domains.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which help strengthen the theoretical presentation of our work. Below, we respond to each major comment and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Theoretical derivation of the CTEM objective] The claim that the constant-target objective has a minimizer that recovers log p exactly (up to constant) for arbitrary state spaces is load-bearing. The bounded energy-difference transform must be constructed so its expectation is invariant to the choice of reference measure (counting measure on discrete spaces versus Lebesgue on continuous). The manuscript should supply the explicit derivation (likely in the main theoretical section or appendix) showing how the stationary point equals log p and confirming that no additional regularity conditions on p or measure-specific adjustments are required.
Authors: We agree that an explicit derivation of the stationary point and measure invariance is essential to support the central claim. The bounded energy-difference transform is constructed precisely so that its expectation under the data distribution is independent of the reference measure, yielding a stationary point at log p (up to additive constant) with no measure-specific adjustments or extra regularity conditions on p beyond standard integrability. We will revise the manuscript to include this full explicit derivation, together with a short proof sketch, in the main theoretical section (Section 3) and appendix. revision: yes
-
Referee: [Proof or analysis of recovery property] No derivation steps, error analysis, or proof sketch for the log-density recovery appear in the provided abstract or high-level description. If such material exists in the full text (e.g., Section 3 or Appendix A), it must be clearly signposted; otherwise the central theoretical guarantee remains unverified and the empirical improvements cannot be confidently attributed to exact recovery.
Authors: We acknowledge that the abstract and high-level description do not contain derivation steps or a proof sketch, which limits immediate verification of the recovery property. We will revise the manuscript to add clear signposting (e.g., an explicit forward reference in the abstract and introduction to 'Section 3 for the derivation of log-density recovery') and to expand the proof sketch plus basic error analysis in Section 3 and the appendix. This will make the theoretical guarantee transparent and allow confident attribution of the reported empirical gains. revision: yes
Circularity Check
No significant circularity; derivation presented as independent of fitted inputs
full rationale
The abstract and reader's summary describe CTEM as replacing density-ratio regression with a bounded energy-difference transform, then deriving a sample-only objective with fixed target 1 whose minimizer recovers log p. No equations or steps are exhibited that reduce the claimed recovery to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain. The constant target is stated as independent of any learned quantities. The skeptic concern about reference-measure dependence is a potential correctness or assumption issue, not a circularity reduction by construction. Per hard rules, absent explicit quotes showing Eq. X = Eq. Y by construction or load-bearing self-citation, the score remains 0 and steps empty.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A bounded energy-difference transform produces a training objective whose minimizer recovers log p on general state spaces.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Lemma 1 (Bounded modified-ratio identity). For any z,˜z∈Z with ρ(z),ρ(˜z)>0, tanh((logρ(z)−logρ(˜z))/2)=(ρ(z)−ρ(˜z))/(ρ(z)+ρ(˜z)).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection (coupling combiner forces bilinear branch with J(1)=0) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 1 … yields a sample-only objective Lω(θ)=∬[tanh((fθ(z)−fθ(˜z))/2)−1]² ω(z,˜z)ρ(z)ν(dz)ν(d˜z) with constant regression target 1.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Density Estimation for Statistics and Data Analysis , author =. 1986 , publisher =
work page 1986
-
[2]
A Tutorial on Energy-Based Learning , author =. 2006 , institution =
work page 2006
-
[3]
Advances in Neural Information Processing Systems , year =
Implicit Generation and Modeling with Energy-Based Models , author =. Advances in Neural Information Processing Systems , year =
-
[4]
Journal of Machine Learning Research , volume =
Estimation of Non-Normalized Statistical Models by Score Matching , author =. Journal of Machine Learning Research , volume =
-
[5]
A Connection Between Score Matching and Denoising Autoencoders , author =. Neural Computation , volume =
-
[6]
Uncertainty in Artificial Intelligence (UAI) , year =
Sliced Score Matching: A Scalable Approach to Density and Score Estimation , author =. Uncertainty in Artificial Intelligence (UAI) , year =
-
[7]
Computational Statistics & Data Analysis , volume =
Some Extensions of Score Matching , author =. Computational Statistics & Data Analysis , volume =
-
[8]
Dinh, Laurent and Krueger, David and Bengio, Yoshua , booktitle =
-
[9]
Dinh, Laurent and Sohl-Dickstein, Jascha and Bengio, Samy , booktitle =. Density Estimation Using
-
[10]
International Conference on Machine Learning , year =
Variational Inference with Normalizing Flows , author =. International Conference on Machine Learning , year =
-
[11]
and Dhariwal, Prafulla , booktitle =
Kingma, Diederik P. and Dhariwal, Prafulla , booktitle =. Glow: Generative Flow with Invertible
-
[12]
Advances in Neural Information Processing Systems , year =
Masked Autoregressive Flow for Density Estimation , author =. Advances in Neural Information Processing Systems , year =
-
[13]
Grathwohl, Will and Chen, Ricky T. Q. and Bettencourt, Jesse and Sutskever, Ilya and Duvenaud, David , booktitle =
-
[14]
Advances in Neural Information Processing Systems , year =
Generative Modeling by Estimating Gradients of the Data Distribution , author =. Advances in Neural Information Processing Systems , year =
-
[15]
Advances in Neural Information Processing Systems , year =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , year =
-
[16]
International Conference on Learning Representations , year =
Score-Based Generative Modeling Through Stochastic Differential Equations , author =. International Conference on Learning Representations , year =
-
[17]
Advances in Neural Information Processing Systems , year =
Elucidating the Design Space of Diffusion-Based Generative Models , author =. Advances in Neural Information Processing Systems , year =
-
[18]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[19]
Advances in Neural Information Processing Systems , year =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , year =
-
[20]
Advances in Neural Information Processing Systems , year =
Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions , author =. Advances in Neural Information Processing Systems , year =
-
[21]
Advances in Neural Information Processing Systems , year =
A Continuous Time Framework for Discrete Denoising Models , author =. Advances in Neural Information Processing Systems , year =
-
[22]
Advances in Neural Information Processing Systems , year =
Concrete Score Matching: Generalized Score Matching for Discrete Data , author =. Advances in Neural Information Processing Systems , year =
-
[23]
International Conference on Machine Learning , year =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. International Conference on Machine Learning , year =
-
[24]
Advances in Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[25]
Advances in Neural Information Processing Systems , year =
Simplified and Generalized Masked Diffusion for Discrete Data , author =. Advances in Neural Information Processing Systems , year =
-
[26]
International Conference on Learning Representations , year =
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author =. International Conference on Learning Representations , year =
-
[27]
Advances in Neural Information Processing Systems , year =
Discrete Flow Matching , author =. Advances in Neural Information Processing Systems , year =
-
[28]
International Conference on Machine Learning , year =
The Diffusion Duality , author =. International Conference on Machine Learning , year =
-
[29]
Advances in Neural Information Processing Systems , year =
Neural Spline Flows , author =. Advances in Neural Information Processing Systems , year =
-
[30]
Frontiers in Probabilistic Inference: Learning meets Sampling , year =
Score-Debiased Kernel Density Estimation , author =. Frontiers in Probabilistic Inference: Learning meets Sampling , year =
-
[31]
The Annals of Mathematical Statistics , volume =
Remarks on Some Nonparametric Estimates of a Density Function , author =. The Annals of Mathematical Statistics , volume =
-
[32]
An Alternative Method of Cross-Validation for the Smoothing of Density Estimates , author=. Biometrika , volume=
-
[33]
Advances in Neural Information Processing Systems , volume =
Maximum Likelihood Training of Score-Based Diffusion Models , author =. Advances in Neural Information Processing Systems , volume =
-
[34]
The MNIST Database of Handwritten Digits , author =. 1998 , howpublished =
work page 1998
-
[35]
International Conference on Learning Representations , year =
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author =. International Conference on Learning Representations , year =
-
[36]
International Conference on Machine Learning , pages =
Consistency Models , author =. International Conference on Machine Learning , pages =
-
[37]
Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence , pages =
Interpretation and Generalization of Score Matching , author =. Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.