Recognition: 2 theorem links
· Lean TheoremContextual Plackett-Luce: An Efficient Neural Model for Probabilistic Sequence Selection under Ambiguity
Pith reviewed 2026-05-12 04:53 UTC · model grok-4.3
The pith
Contextual Plackett-Luce builds selection probabilities in parallel then refines them through incremental logit updates to handle ambiguous sequence targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contextual Plackett-Luce extends the classical Plackett-Luce model to a context-dependent setting following an Ising-style parameterization with unary and pairwise interaction terms. The model constructs its parameters in a fully parallel manner, then performs a lightweight autoregressive selection process in which each step applies incremental updates to contextual logits. This decoupling of parallel scoring and sequential selection enables efficient computation without sacrificing expressivity on multi-modal path prediction and representative subset selection tasks.
What carries the argument
Contextual Plackett-Luce, which constructs unary and pairwise parameters in parallel before performing incremental autoregressive selection on contextual logits.
If this is right
- Parameters for the full selection distribution can be computed once on GPU before any sequential choice begins.
- Each selection step only updates a small set of logits rather than re-running the entire network.
- Structural consistency improves on multi-modal path prediction relative to non-autoregressive baselines.
- Robustness to single-sample supervision increases on representative subset selection tasks.
Where Pith is reading between the lines
- The same parallel-then-incremental pattern could be tried on other structured outputs such as parse trees or molecule graphs where full autoregression is costly.
- If pairwise terms prove insufficient on a given domain, the framework could be extended by adding a small number of learned higher-order factors without losing the parallel construction step.
- The lightweight update rule suggests a natural way to trade off accuracy against speed by varying how many selection steps are performed.
Load-bearing premise
Unary and pairwise interaction terms are enough to capture the multi-modal dependencies that matter for coherent sequence selection.
What would settle it
If CPL matches or underperforms a purely parallel baseline on a dataset whose valid sequences are known to require higher-order interactions, the hybrid's claimed expressivity gain would be falsified.
Figures




read the original abstract
Selecting a coherent sequence or subset of elements is a fundamental problem in structured prediction, arising in tasks such as detection, trajectory forecasting, and representative subset selection. In many such settings, the target is inherently ambiguous: each input admits multiple valid outputs, while supervision provides only a single sampled instance. This induces a mismatch between the underlying multi-modal target distribution and the observed training signal. We propose Contextual Plackett-Luce (CPL), a structured probabilistic model for sequence selection that extends the classical Plackett-Luce model to a context-dependent setting following an Ising-style parameterization with unary and pairwise interaction terms. CPL can be viewed as a hybrid between fully autoregressive prediction and parallel sequence selection: autoregressive models effectively capture uncertainty but are computationally expensive on modern parallel hardware such as GPUs, while parallel methods are efficient but struggle to represent multi-modal dependencies. CPL combines the strengths of both by constructing the parameters of a probabilistic selection model in a fully parallel manner, followed by a lightweight autoregressive selection process in which each step applies incremental updates to contextual logits. This decoupling of parallel scoring and sequential selection enables efficient computation without sacrificing expressivity. We evaluate CPL on two structured selection tasks: multi-modal path prediction and representative subset selection. CPL achieves improved structural consistency and robustness under ambiguous supervision compared to strong parallel baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Contextual Plackett-Luce (CPL), a structured probabilistic model extending the classical Plackett-Luce ranking model to context-dependent sequence selection via an Ising-style parameterization using unary and pairwise interaction terms. Parameters are constructed in a fully parallel manner, followed by a lightweight autoregressive selection process applying incremental updates to contextual logits. This hybrid is positioned as combining the efficiency of parallel methods with the expressivity of autoregressive ones for tasks with ambiguous, multi-modal targets. Evaluation is reported on multi-modal path prediction and representative subset selection, with claims of improved structural consistency and robustness under single-sample ambiguous supervision relative to strong parallel baselines.
Significance. If the empirical results and modeling assumptions hold, CPL offers a computationally attractive approach for GPU-efficient modeling of multi-modal structured outputs in applications such as trajectory forecasting and subset selection. The explicit decoupling of parallel scoring from sequential selection, grounded in standard Plackett-Luce and Ising forms, is a clear strength that could be adopted more broadly. The work directly targets the mismatch between multi-modal targets and single-sample supervision, a common issue in structured prediction.
major comments (2)
- [Model definition / parameterization] Model parameterization (Ising-style unary/pairwise terms): The central expressivity claim—that the parallel construction of unary and pairwise contextual logits plus incremental autoregressive updates suffices to represent multi-modal target distributions—rests on the assumption that pairwise interactions capture the necessary dependencies. This is load-bearing for the robustness claim, yet no theoretical argument or ablation demonstrates why higher-order terms (e.g., global trajectory consistency or exclusion patterns in path prediction) are unnecessary. Tasks like multi-modal path prediction routinely exhibit non-pairwise structure that pairwise models cannot encode, risking under-expression of the target even with the autoregressive step.
- [Experiments / evaluation] Evaluation and ablations: The abstract and claims of improved structural consistency rest on unshown quantitative results, ablations, and comparisons. Without reported metrics, baseline details, or controls isolating the contribution of the incremental logit updates versus the Ising parameterization, it is impossible to verify that the hybrid actually outperforms parallel baselines on the multi-modality axis rather than on other factors.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key equation for the contextual logit update or the Plackett-Luce probability form to make the hybrid construction concrete.
- [Method] Notation for the incremental logit updates during selection should be clarified with an explicit recurrence or algorithm box to distinguish it from standard autoregressive decoding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Model definition / parameterization] Model parameterization (Ising-style unary/pairwise terms): The central expressivity claim—that the parallel construction of unary and pairwise contextual logits plus incremental autoregressive updates suffices to represent multi-modal target distributions—rests on the assumption that pairwise interactions capture the necessary dependencies. This is load-bearing for the robustness claim, yet no theoretical argument or ablation demonstrates why higher-order terms (e.g., global trajectory consistency or exclusion patterns in path prediction) are unnecessary. Tasks like multi-modal path prediction routinely exhibit non-pairwise structure that pairwise models cannot encode, risking under-expression of the target even with the autoregressive step.
Authors: We acknowledge that pairwise interactions alone may not capture all higher-order dependencies present in some tasks. The incremental autoregressive selection step in CPL is designed to propagate information about prior selections through logit updates, which can implicitly account for certain sequential and exclusionary effects beyond static pairwise terms. Nevertheless, we agree a more explicit analysis would strengthen the work. In the revision we will add a dedicated discussion subsection on the model's expressivity limits relative to higher-order models and include an ablation comparing CPL to a variant with explicit triplet or global terms on the path prediction task. revision: partial
-
Referee: [Experiments / evaluation] Evaluation and ablations: The abstract and claims of improved structural consistency rest on unshown quantitative results, ablations, and comparisons. Without reported metrics, baseline details, or controls isolating the contribution of the incremental logit updates versus the Ising parameterization, it is impossible to verify that the hybrid actually outperforms parallel baselines on the multi-modality axis rather than on other factors.
Authors: Quantitative results, including structural consistency metrics and robustness measures under single-sample supervision, are presented in Section 4 of the full manuscript along with baseline descriptions. To address the concern, we will expand the abstract and Section 4 to explicitly reference these metrics, add a new ablation table that isolates the incremental logit update component from the Ising parameterization, and include controls that compare against purely parallel and fully autoregressive variants. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs Contextual Plackett-Luce by extending the classical Plackett-Luce model to a context-dependent setting via an explicit Ising-style parameterization with unary and pairwise terms, followed by parallel parameter construction and a lightweight autoregressive selection step with incremental logit updates. This hybrid structure is presented as derived from standard Plackett-Luce and Ising forms rather than self-referential definitions or fitted quantities renamed as predictions. No load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the abstract or description; the central claims of efficiency and expressivity follow directly from the stated decoupling without reducing to tautology by the model's own equations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ising-style unary and pairwise terms adequately represent multi-modal dependencies in sequence selection targets
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
extends the classical Plackett-Luce model to a context-dependent setting following an Ising-style parameterization with unary and pairwise interaction terms
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lightweight autoregressive selection process in which each step applies incremental updates to contextual logits
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Structured prediction energy networks
David Belanger and Andrew McCallum. Structured prediction energy networks. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 983–992. PMLR, 2016
work page 2016
-
[3]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V . Le, Mohammad Norouzi, and Samy Bengio. Neural combi- natorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page Pith review arXiv 2016
-
[4]
Christopher M. Bishop. Mixture density networks. Technical Report NCRG/94/004, Aston University, 1994
work page 1994
-
[5]
Fast differentiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differentiable sorting and ranking. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 950–959. PMLR, 2020
work page 2020
-
[6]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11621–11631, 2020
work page 2020
-
[7]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InComputer Vision – ECCV 2020, volume 12346 ofLecture Notes in Computer Science, pages 213–229. Springer, 2020
work page 2020
-
[8]
MultiPath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction
Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. MultiPath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. InProceedings of the Conference on Robot Learning, volume 100 ofProceedings of Machine Learning Research, pages 86–99. PMLR, 2020
work page 2020
-
[9]
Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection. InInternational Conference on Learning Representations, 2022
work page 2022
-
[10]
Stochastic optimization of sorting networks via continuous relaxations
Aditya Grover, Eric Wang, Aaron Zweig, and Stefano Ermon. Stochastic optimization of sorting networks via continuous relaxations. InInternational Conference on Learning Representations, 2019
work page 2019
-
[11]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[12]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
Jonathan Ho, Ajay N. Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc., 2020
work page 2020
-
[14]
Daniel P. Huttenlocher, Gregory A. Klanderman, and William J. Rucklidge. Comparing images using the hausdorff distance.IEEE Transactions on Pattern Analysis and Machine Intelligence, 15(9):850–863, 1993
work page 1993
-
[15]
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 9902–9915. PMLR, 2022
work page 2022
-
[16]
Motiondiffuser: Controllable multi-agent motion prediction using diffusion
Chiyu Max Jiang, Andre Cornman, Cheolho Park, Benjamin Sapp, Yin Zhou, and Dragomir Anguelov. Motiondiffuser: Controllable multi-agent motion prediction using diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9644–9653, 2023. 11
work page 2023
-
[17]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Efficient inference in fully connected crfs with gaussian edge potentials
Philipp Krahenbuhl and Vladlen Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. InAdvances in Neural Information Processing Systems, volume 24, pages 109–117, 2011
work page 2011
-
[19]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[20]
Harold W. Kuhn. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1–2):83–97, 1955
work page 1955
-
[21]
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.F oundations and Trends in Machine Learning, 5(2–3):123–286, 2012
work page 2012
-
[22]
Lafferty, Andrew McCallum, and Fernando C
John D. Lafferty, Andrew McCallum, and Fernando C. N. Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. InProceedings of the Eigh- teenth International Conference on Machine Learning, pages 282–289, 2001
work page 2001
-
[23]
Set transformer: A framework for attention-based permutation-invariant neural networks
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. InPro- ceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3744–3753. PMLR, 2019
work page 2019
-
[24]
Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
Stuart Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
work page 1982
-
[25]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[26]
Duncan Luce.Individual Choice Behavior: A Theoretical Analysis
R. Duncan Luce.Individual Choice Behavior: A Theoretical Analysis. John Wiley & Sons, New York, 1959
work page 1959
-
[27]
Fast and accurate inference of Plackett–Luce models
Lucas Maystre and Matthias Grossglauser. Fast and accurate inference of Plackett–Luce models. InAdvances in Neural Information Processing Systems, volume 28, pages 172–180, 2015
work page 2015
-
[28]
Gonzalo E. Mena, David Belanger, Scott W. Linderman, and Jasper Snoek. Learning latent permutations with Gumbel–Sinkhorn networks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[29]
Boulton, Oscar Beijbom, and Eric M
Tung Phan-Minh, Elena Corina Grigore, Freddy A. Boulton, Oscar Beijbom, and Eric M. Wolff. CoverNet: Multimodal behavior prediction using trajectory sets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14074–14083, 2020
work page 2020
-
[30]
R. L. Plackett. The analysis of permutations.Journal of the Royal Statistical Society: Series C (Applied Statistics), 24(2):193–202, 1975
work page 1975
-
[31]
Nicholas Rhinehart, Kris M. Kitani, and Paul Vernaza. R2P2: A reparameterized pushfor- ward policy for diverse, precise generative path forecasting. InProceedings of the European Conference on Computer Vision, pages 794–811, 2018
work page 2018
-
[32]
Christian Rupprecht, Iro Laina, Robert DiPietro, Maximilian Baust, Federico Tombari, Nassir Navab, and Gregory D. Hager. Learning in an uncertain world: Representing ambiguity through multiple hypotheses. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[33]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei- Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015
work page 2015
-
[34]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. 12
work page 2021
-
[35]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, volume 30, pages 5998–6008, 2017
work page 2017
-
[36]
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. InAdvances in Neural Information Processing Systems, volume 28, pages 2692–2700, 2015
work page 2015
-
[37]
Ronald J. Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks.Neural Computation, 1(2):270–280, 1989
work page 1989
-
[38]
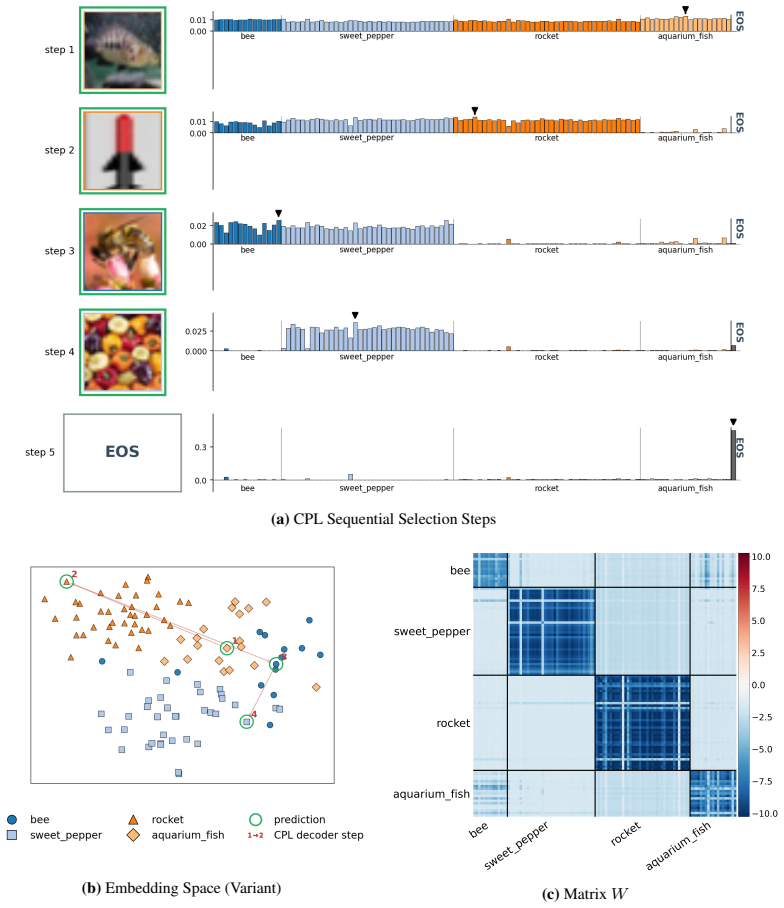
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabás Póczos, Ruslan Salakhutdinov, and Alexander J. Smola. Deep sets. InAdvances in Neural Information Processing Systems, volume 30, pages 3391–3401, 2017. 13 A Visualizations of CPL selection process In this section, we provide additional qualitative examples of the CPL selection process. Figures 2 a...
work page 2017
-
[39]
Greedy decoding is capped at 20 selections. The AR baseline uses the same encoder, a 2-layer Transformer decoder [35] with 4 attention heads and feed-forward width 1024, and a pointer-network readout [36] over the bag plus EOS. Evaluation and runtime.BCE and Hungarian are decoded by sweeping sigmoid thresholds {0.1,0.2, . . . ,0.9,0.95} , and the table re...
-
[40]
Thus, the expected cost is: E[∆] = 1 2(1.25) + 1 2 2 3 = 23 24 ≈0.96. Interpretation.Although {d, e} is not a valid solution under any mode, it achieves lower expected loss than either valid subset. This occurs because a deterministic matching-based predictor trained under expected set cost can favor intermediate configurations that partially match multip...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.