Recognition: no theorem link
Lost in Translation? Exploring the Shift in Grammatical Gender from Latin to Occitan
Pith reviewed 2026-05-12 03:51 UTC · model grok-4.3
The pith
An interpretable neural framework shows grammatical gender cues shifting from Latin word forms to Occitan sentence context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
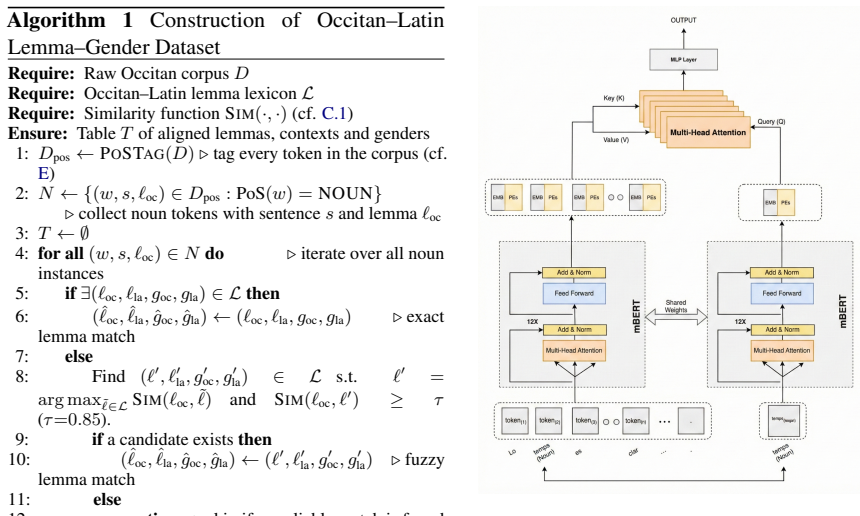
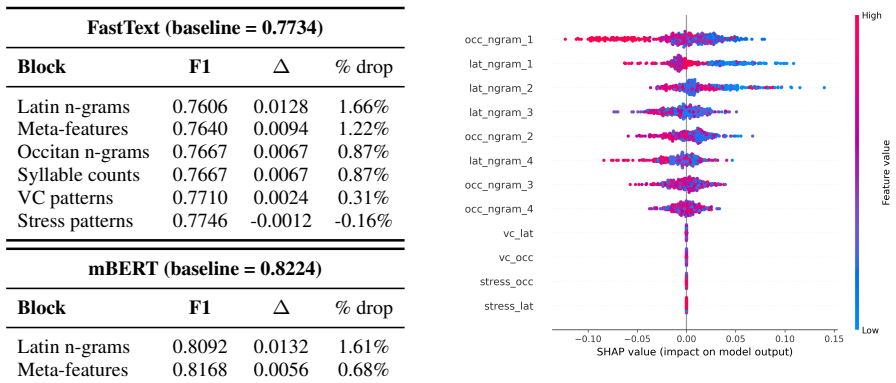
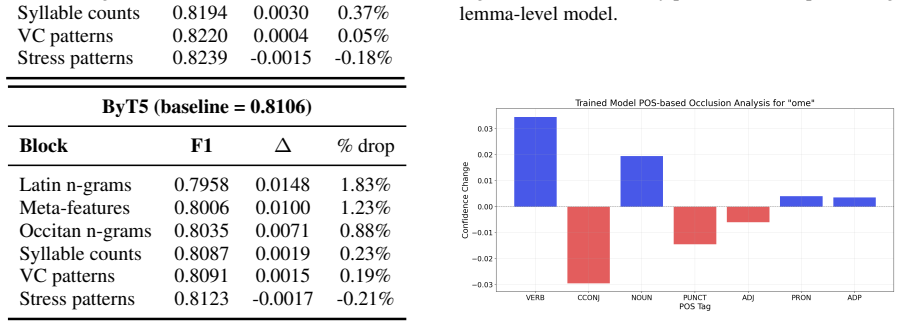
We introduce an interpretable deep learning framework to investigate the restructuring of grammatical gender from a tripartite to a bipartite system at both lexical and contextual levels. Analyses show that a custom tokenizer outperforms standard ones on low-resource historical data, morphological features contribute to lexical gender prediction, and different part-of-speech categories contribute variably to contextual prediction, together characterizing the distribution of gender information between the lemma and its sentential context.
What carries the argument
The interpretable deep learning framework using feature attributions to measure morphological contributions at the lexical level and part-of-speech contributions at the contextual level for gender prediction.
If this is right
- Custom tokenization improves model performance over conventional strategies in low-resource historical settings.
- Morphological features of lemmas contribute substantially to gender prediction at the lexical level.
- Contributions from different part-of-speech categories can be quantified for grammatical gender at the contextual level.
- The gender information is distributed between the lemma and its sentential context in a measurable way.
Where Pith is reading between the lines
- Similar frameworks could quantify shifts in other grammatical categories like case or number across language families.
- Applying this to larger corpora of other Romance languages might reveal if the pattern of increasing contextual dependence is general.
- The public release of code and data enables direct testing on additional historical periods or languages.
Load-bearing premise
That the neural network's feature attributions on limited historical data capture genuine diachronic changes in language rather than artifacts of the model or data scarcity.
What would settle it
If expert linguists annotate the gender-carrying elements in sample Latin and Occitan sentences and these annotations do not match the model's attributed contributions from lemmas versus contexts.
Figures






read the original abstract
The diachronic evolution from Latin to the Romance languages involved a restructuring of the grammatical gender system from a tripartite configuration (masculine, feminine, neuter) to a bipartite one (masculine, feminine). In this work, we introduce an interpretable deep learning framework to investigate this phenomenon at both lexical and contextual levels. First, we show that conventional tokenization strategies are insufficiently robust for this low-resource historical setting, and that our proposed tokenizer improves performance over these baselines. At the lexical level, we evaluate the contribution of morphological features to gender prediction. At the contextual level, we quantify the contributions of different part-of-speech categories to grammatical gender prediction. Together, these analyses characterize the distribution of gender information between the lemma and its sentential context. We make our codebase, datasets, and results publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce an interpretable deep learning framework for investigating the diachronic shift in grammatical gender from Latin's tripartite (masculine, feminine, neuter) to Occitan's bipartite (masculine, feminine) system. It argues that conventional tokenizers are insufficient for this low-resource historical setting and that a proposed custom tokenizer improves performance; at the lexical level it evaluates morphological feature contributions to gender prediction, and at the contextual level it quantifies part-of-speech category contributions, together characterizing the distribution of gender information between the lemma and sentential context. Code, datasets, and results are released publicly.
Significance. If the empirical results prove robust and the feature attributions align with established philological observations on neuter loss and gender merger, the work could offer a quantitative, interpretable bridge between computational methods and historical linguistics. The public release of code and data is a clear strength that supports reproducibility and extension by others in the field.
major comments (2)
- Abstract: the central claim that the framework characterizes the genuine distribution of gender information between lemma and context requires that model predictions and attributions recover linguistic reality rather than artifacts; however, no external validation against established facts on neuter loss or merger patterns is referenced, leaving the quantified POS and morphological contributions open to the possibility that they reflect data scarcity or inductive biases instead.
- Results section on tokenizer evaluation: the assertion that the custom tokenizer improves performance over conventional baselines is load-bearing for the low-resource setting claim, yet the abstract supplies no metrics, baseline definitions, error bars, or statistical tests; without these the improvement cannot be assessed as substantive rather than marginal or artifactual.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: Abstract: the central claim that the framework characterizes the genuine distribution of gender information between lemma and context requires that model predictions and attributions recover linguistic reality rather than artifacts; however, no external validation against established facts on neuter loss or merger patterns is referenced, leaving the quantified POS and morphological contributions open to the possibility that they reflect data scarcity or inductive biases instead.
Authors: We agree that explicit linkage to philological knowledge strengthens interpretability claims. The manuscript's analyses are motivated by and consistent with known patterns of neuter loss and gender merger in the Latin-to-Romance transition, but we did not include a dedicated comparison subsection. In the revised version we will add a short Discussion paragraph that directly maps our morphological and POS attribution results to established historical linguistics findings (e.g., loss of neuter in specific semantic classes and merger trajectories), citing the relevant philological sources. This addition will make the alignment with linguistic reality explicit and reduce the risk that readers interpret the numbers as purely model-driven artifacts. revision: yes
-
Referee: Results section on tokenizer evaluation: the assertion that the custom tokenizer improves performance over conventional baselines is load-bearing for the low-resource setting claim, yet the abstract supplies no metrics, baseline definitions, error bars, or statistical tests; without these the improvement cannot be assessed as substantive rather than marginal or artifactual.
Authors: The Results section already reports the full tokenizer comparison, including accuracy/F1 deltas, baseline tokenizers, standard deviations across runs, and statistical tests. The abstract, however, states the improvement only qualitatively. We will revise the abstract to include one concise quantitative clause (e.g., “our custom tokenizer yields a 4.2-point absolute F1 improvement over subword baselines, significant at p<0.01”) while keeping the abstract within length limits. This change makes the load-bearing claim immediately verifiable without altering the paper’s technical content. revision: yes
Circularity Check
No circularity: empirical framework with independent evaluations
full rationale
The paper's claims rest on training interpretable models, comparing tokenizer performance against baselines, and quantifying POS/morphological contributions via feature attributions on held-out historical data. No equations, derivations, or predictions are shown that reduce to fitted parameters or self-citations by construction. The distribution characterization follows directly from the model's learned behavior on external data splits rather than any self-definitional loop or renamed input.
Axiom & Free-Parameter Ledger
free parameters (2)
- tokenizer hyperparameters
- neural network hyperparameters
axioms (1)
- domain assumption Grammatical gender in historical texts can be reliably recovered from lemma morphology and sentential context via neural networks.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 1st Workshop on Multilingual Representation Learning , pages=
Do not neglect related languages: The case of low-resource Occitan cross-lingual word embeddings , author=. Proceedings of the 1st Workshop on Multilingual Representation Learning , pages=
-
[2]
Shaping the Future of Endangered and Low-Resource Languages---Our Role in the Age of LLMs: A Keynote at ECIR 2024 , author=. ACM SIGIR Forum , volume=. 2024 , organization=
work page 2024
-
[3]
Journal of Quantitative Linguistics , volume=
Stability of meanings versus rate of replacement of words: an experimental test , author=. Journal of Quantitative Linguistics , volume=. 2021 , publisher=
work page 2021
-
[4]
Development of gender classifications: Modeling the historical change from Latin to French , author=. Language , volume=. 2003 , publisher=
work page 2003
-
[5]
Acta Antiqua Academiae Scientiarum Hungaricae , volume=
Preliminary examination of the Latin neuter on inscriptions , author=. Acta Antiqua Academiae Scientiarum Hungaricae , volume=. 2023 , publisher=
work page 2023
-
[6]
C orpus A ri \`e ja: Building an Annotated Corpus with Variation in O ccitan
Poujade, Clamenca and Bras, Myriam and Urieli, Assaf. C orpus A ri \`e ja: Building an Annotated Corpus with Variation in O ccitan. Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages @ LREC-COLING 2024. 2024
work page 2024
-
[7]
arXiv preprint arXiv:2506.17715 , year=
Unveiling Factors for Enhanced POS Tagging: A Study of Low-Resource Medieval Romance Languages , author=. arXiv preprint arXiv:2506.17715 , year=
- [8]
-
[9]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[10]
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
work page 2022
-
[11]
Recurrent Neural Networks (RNNs): A gentle Introduction and Overview , author=. 2019 , eprint=
work page 2019
-
[12]
Computational linguistics , volume=
The mathematics of statistical machine translation: Parameter estimation , author=. Computational linguistics , volume=
-
[13]
Proceedings of the IJCNLP-08 Workshop on NLP for Less Privileged Languages , year=
Natural Language Processing for Less Privileged Languages: Where do we come from? Where are we going? , author=. Proceedings of the IJCNLP-08 Workshop on NLP for Less Privileged Languages , year=
-
[14]
Natural Language Engineering , volume=
Natural language processing for similar languages, varieties, and dialects: A survey , author=. Natural Language Engineering , volume=. 2020 , publisher=
work page 2020
-
[15]
Efficient Estimation of Word Representations in Vector Space
Efficient estimation of word representations in vector space , author=. arXiv preprint arXiv:1301.3781 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Enriching word vectors with subword information.arXiv preprint arXiv:1607.04606, 2016
Enriching Word Vectors with Subword Information , author=. arXiv preprint arXiv:1607.04606 , year=
-
[17]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[18]
Unsupervised cross-lingual representation learning at scale , author=. arXiv preprint arXiv:1911.02116 , year=
-
[19]
Transactions of the Association for Computational Linguistics , volume=
ByT5: Towards a token-free future with pre-trained byte-to-byte models , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
work page 2022
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Recall@ k surrogate loss with large batches and similarity mixup , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
Proceedings of the international conference on web intelligence , pages=
Mrr: an unsupervised algorithm to rank reviews by relevance , author=. Proceedings of the international conference on web intelligence , pages=
-
[22]
A Theoretical Analysis of NDCG Type Ranking Measures , author=. 2013 , eprint=
work page 2013
-
[23]
Neural Machine Translation of Rare Words with Subword Units
Neural machine translation of rare words with subword units , author=. arXiv preprint arXiv:1508.07909 , year=
work page internal anchor Pith review arXiv
-
[24]
arXiv preprint arXiv:1804.10959 , year=
Subword regularization: Improving neural network translation models with multiple subword candidates , author=. arXiv preprint arXiv:1804.10959 , year=
-
[25]
2025 IEEE International Conference on Electro Information Technology (eIT) , pages=
Tokenization matters: Improving zero-shot ner for indic languages , author=. 2025 IEEE International Conference on Electro Information Technology (eIT) , pages=. 2025 , organization=
work page 2025
-
[26]
Journal of machine learning research , volume=
A neural probabilistic language model , author=. Journal of machine learning research , volume=
- [27]
-
[28]
Learning internal representations by error propagation , author=
-
[29]
IEEE 1988 International Conference on Neural Networks , pages=
Backpropagation: Past and future , author=. IEEE 1988 International Conference on Neural Networks , pages=. 1988 , organization=
work page 1988
-
[30]
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[31]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling , author=. 2014 , eprint=
work page 2014
-
[32]
Neural Machine Translation by Jointly Learning to Align and Translate , author=. 2016 , eprint=
work page 2016
-
[33]
Improving language understanding by generative pre-training , author=. 2018 , publisher=
work page 2018
-
[34]
Deep contextualized word representations
Peters, Matthew E. and Neumann, Mark and Iyyer, Mohit and Gardner, Matt and Clark, Christopher and Lee, Kenton and Zettlemoyer, Luke. Deep Contextualized Word Representations. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10...
-
[35]
A Unified Approach to Interpreting Model Predictions , author=. 2017 , eprint=
work page 2017
- [36]
-
[37]
Semi-Supervised Classification with Graph Convolutional Networks , author=. 2017 , eprint=
work page 2017
-
[38]
The Year’s Work in Modern Language Studies , volume=
Occitan Studies: Language and Linguistics , author=. The Year’s Work in Modern Language Studies , volume=. 2019 , publisher=
work page 2019
-
[39]
Gender from Latin to Romance: History, geography, typology , author=. 2018 , publisher=
work page 2018
-
[40]
The nature and origin of the noun genders in the Indo-European languages: A lecture delivered on the occasion of the sesquicentennial celebration of Princeton University , author=. 1897 , publisher=
-
[41]
Corbett, Greville G. , year=. Gender , publisher=
-
[42]
Journal of French Language Studies , volume=
Predictability in French gender attribution: A corpus analysis , author=. Journal of French Language Studies , volume=. 2006 , publisher=
work page 2006
-
[43]
What ' s in a name? I n some languages, grammatical gender
Nastase, Vivi and Popescu, Marius. What ' s in a name? I n some languages, grammatical gender. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. 2009
work page 2009
-
[44]
Quantifying the Semantic Core of Gender Systems
Williams, Adina and Blasi, Damian and Wolf-Sonkin, Lawrence and Wallach, Hanna and Cotterell, Ryan. Quantifying the Semantic Core of Gender Systems. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1577
-
[45]
Minimally Supervised Induction of Grammatical Gender
Cucerzan, Silviu and Yarowsky, David. Minimally Supervised Induction of Grammatical Gender. Proceedings of the 2003 Human Language Technology Conference of the North A merican Chapter of the Association for Computational Linguistics. 2003
work page 2003
-
[46]
Natural Language Engineering , volume=
Efficiently generating correction suggestions for garbled tokens of historical language , author=. Natural Language Engineering , volume=. 2011 , publisher=
work page 2011
-
[47]
Morphological disambiguation and text normalization for southern quechua varieties , author=. Proceedings of the First Workshop on Applying NLP Tools to Similar Languages, Varieties and Dialects , pages=
-
[48]
Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages=
Automatic normalisation of early Modern French , author=. Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages=
-
[49]
The Oxford guide to the Romance languages , author=. 2016 , publisher=
work page 2016
-
[50]
International Conference on Artificial Neural Networks , pages=
Text generation in discrete space , author=. International Conference on Artificial Neural Networks , pages=. 2020 , organization=
work page 2020
-
[51]
Zhang, Yingji and Carvalho, Danilo and Valentino, Marco and Pratt-Hartmann, Ian and Freitas, Andre. Improving Semantic Control in Discrete Latent Spaces with Transformer Quantized Variational Autoencoders. Findings of the Association for Computational Linguistics: EACL 2024. 2024
work page 2024
-
[52]
Sprachdatenbasierte Modellierung von Wissensnetzen in der mittelalterlichen Romania (ALMA): Projektskizze , author=. Zeitschrift f. 2023 , publisher=
work page 2023
-
[53]
2025 , month = may, howpublished =
Wiedner, Marinus , title =. 2025 , month = may, howpublished =. doi:10.5281/zenodo.15300719 , url =
-
[54]
Dictionnaire de l’occitan médiéval (DOM) , howpublished =
-
[55]
ALMA: Knowledge Networks of Medieval Romance-Speaking Europe , author =
-
[56]
Degradation Prediction of Semiconductor Lasers Using Conditional Variational Autoencoder , volume=
Abdelli, Khouloud and Grieser, Helmut and Neumeyr, Christian and Hohenleitner, Robert and Pachnicke, Stephan , year=. Degradation Prediction of Semiconductor Lasers Using Conditional Variational Autoencoder , volume=. Journal of Lightwave Technology , publisher=. doi:10.1109/jlt.2022.3188831 , number=
-
[57]
Soft edit distance for differentiable comparison of symbolic sequences , author=. 2019 , eprint=
work page 2019
-
[58]
Jaccard Metric Losses: Optimizing the Jaccard Index with Soft Labels , author=. 2024 , eprint=
work page 2024
-
[59]
Categorical Reparameterization with Gumbel-Softmax , author=. 2017 , eprint=
work page 2017
-
[60]
Improving Lemmatization of Non-Standard Languages with Joint Learning
Manjavacas, Enrique and K \'a d \'a r, \'A kos and Kestemont, Mike. Improving Lemmatization of Non-Standard Languages with Joint Learning. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1153
-
[61]
Automatic Transcription of Handwritten Old O ccitan Language
Garces Arias, Esteban and Pai, Vallari and Sch. Automatic Transcription of Handwritten Old O ccitan Language. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.953
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.