Recognition: no theorem link
Revisiting Mixture Policies in Entropy-Regularized Actor-Critic
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
A marginalized reparameterization estimator lets mixture policies match or beat Gaussian performance in entropy-regularized actor-critic methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that the marginalized reparameterization estimator supplies unbiased gradients of lower variance than likelihood-ratio gradients for mixture policies, allowing entropy-regularized actor-critic agents that use mixtures to reach solution quality and entropy robustness on par with, and in several tasks above, the Gaussian policies that currently dominate practice.
What carries the argument
The marginalized reparameterization (MRP) estimator, which re-expresses the policy gradient by first integrating out the discrete mixture choice and then differentiating the resulting marginal density.
If this is right
- Mixture policies equipped with the MRP estimator significantly outperform the same policies trained with likelihood-ratio gradients.
- MRP mixture policies reach parity with, and in some environments exceed, the performance of standard Gaussian policies across Gym MuJoCo, DeepMind Control Suite, and MetaWorld.
- The added representational capacity of mixtures translates into measurable gains once the gradient-variance barrier is removed.
- Entropy regularization interacts more favorably with the richer support of mixture policies when low-variance gradients are available.
Where Pith is reading between the lines
- The same marginalization idea may reduce variance for other discrete-continuous hybrid policies where direct reparameterization is unavailable.
- Tasks whose optimal action distributions are naturally multimodal could become reliably solvable without hand-designed policy classes.
- The variance reduction may compound with other low-variance techniques such as value-function baselines or control variates.
Load-bearing premise
The estimator can be computed exactly or with negligible bias even when mixture components overlap and when the entropy term couples them.
What would settle it
A direct comparison on a simple two-component Gaussian mixture policy showing that the empirical gradient variance of the MRP estimator is not lower than that of the likelihood-ratio estimator would falsify the central variance-reduction claim.
Figures






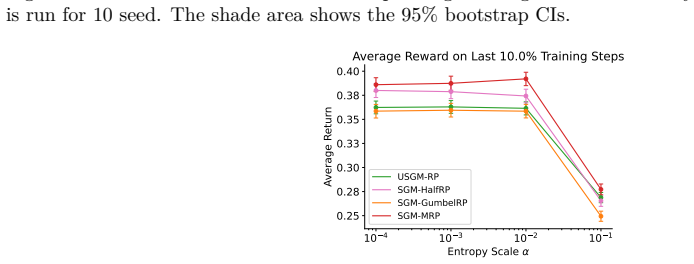











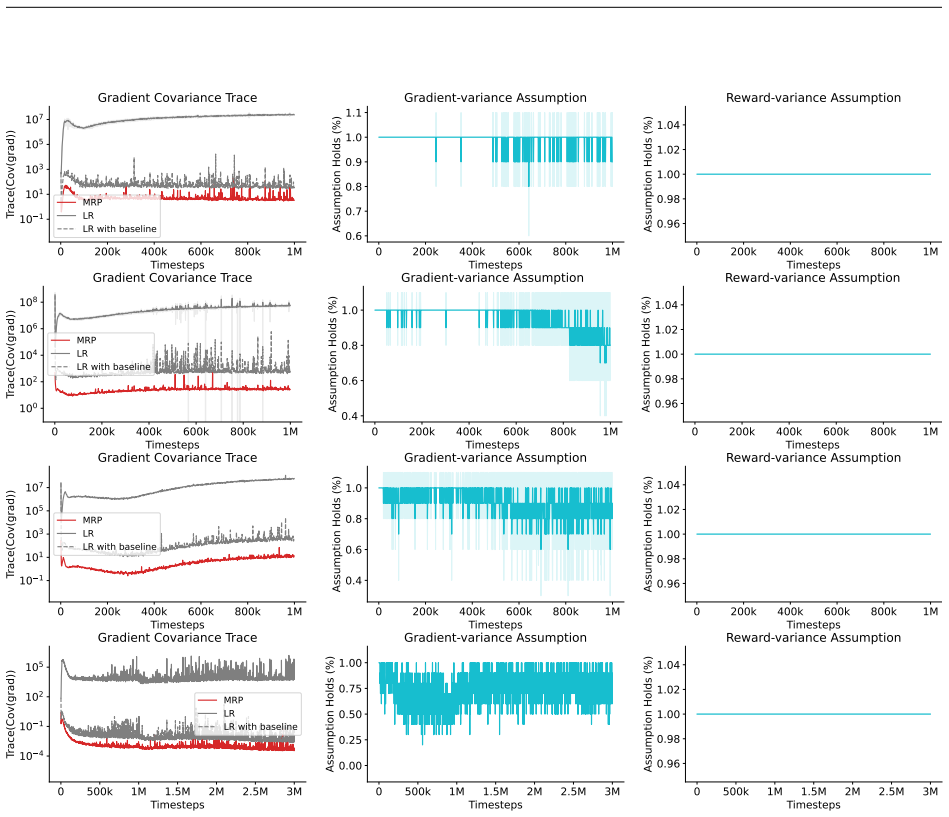



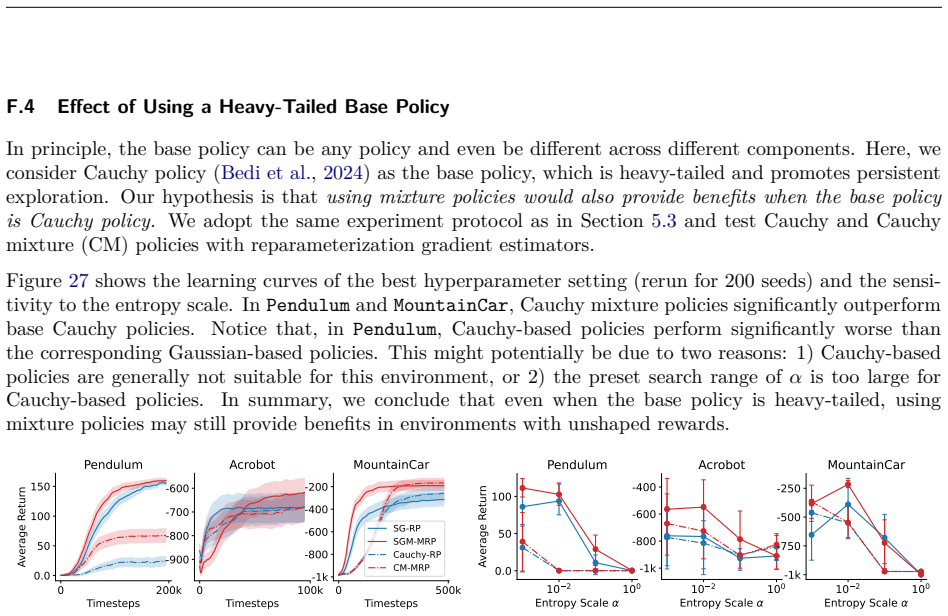

read the original abstract
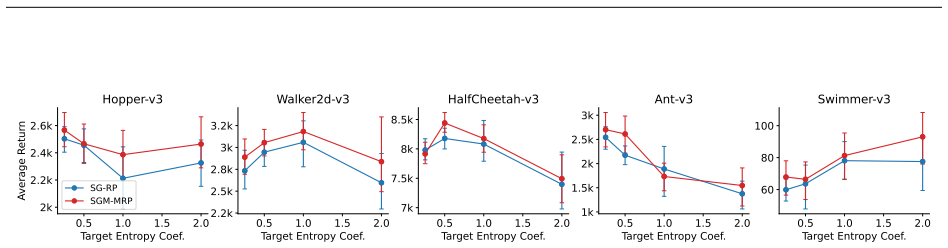
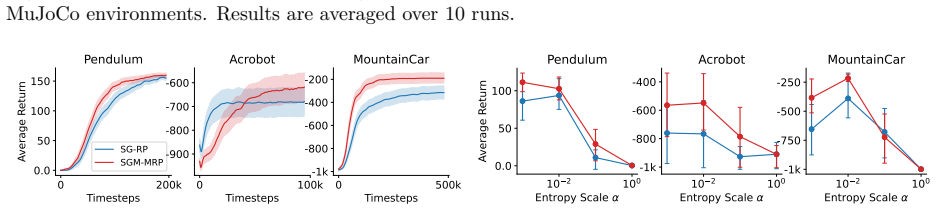
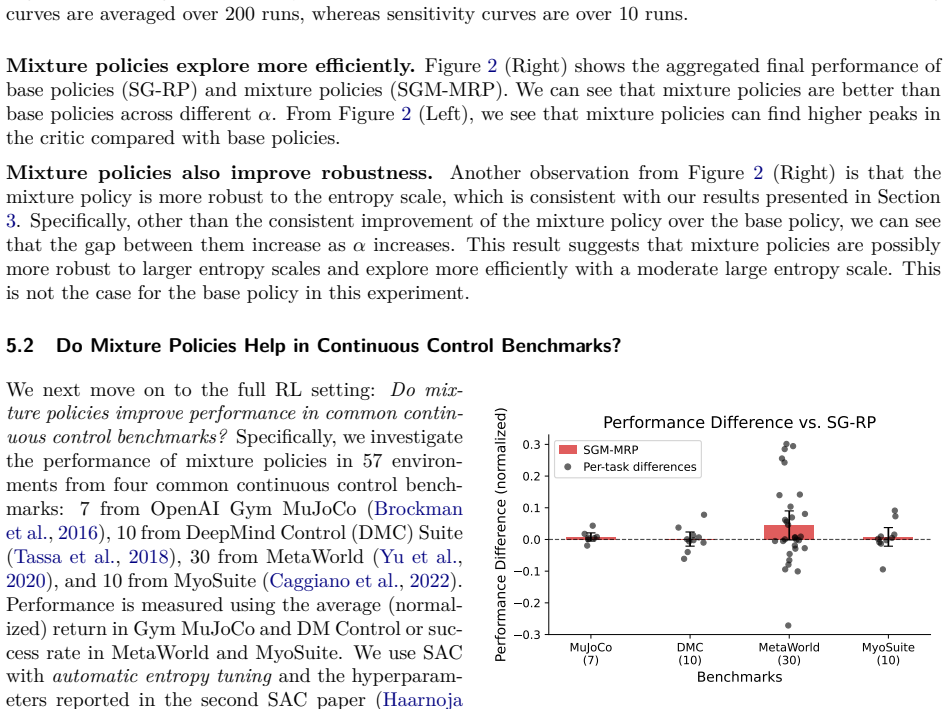
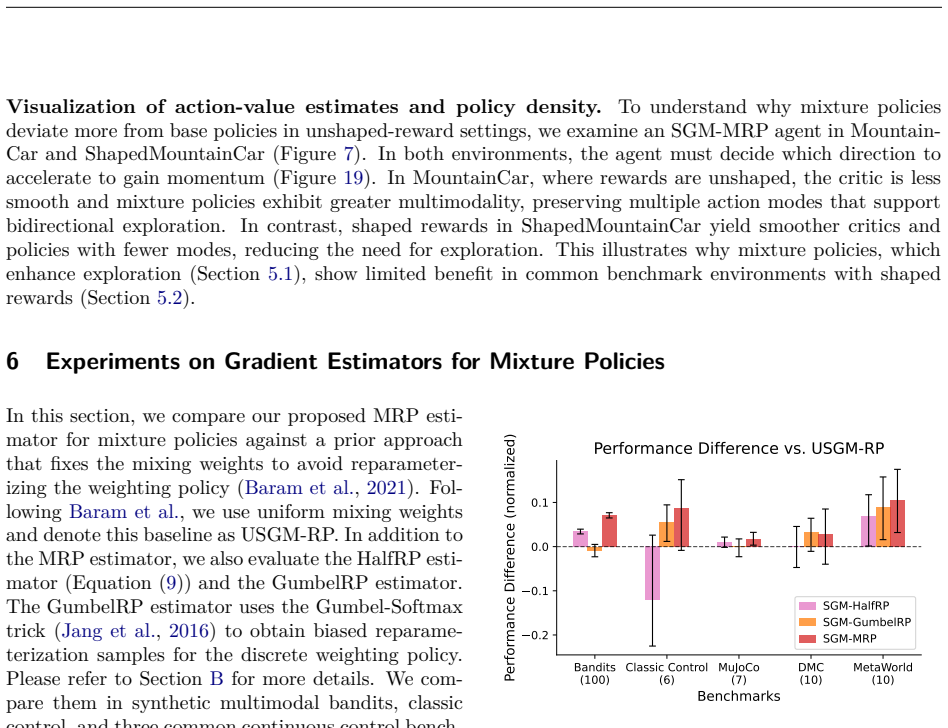
Mixture policies theoretically offer greater flexibility than unimodal policies in continuous action reinforcement learning, but the practical benefits of this complexity remain elusive. Mixture policies are notably absent from most state-of-the-art algorithms, raising a fundamental question: Is the added representational overhead useful? We show that increased flexibility can theoretically enhance solution quality and entropy robustness. Yet standard algorithms like SAC do not leverage these advantages. A core issue is the lack of a low-variance reparameterization trick for mixtures, a luxury Gaussian policies enjoy. We propose a marginalized reparameterization (MRP) estimator to address this, proving it offers lower variance than the standard likelihood-ratio (LR) approach. Our experiments across Gym MuJoCo, DeepMind Control Suite, and MetaWorld show that MRP mixture policies significantly outperform their LR ones, and reach parity (sometimes better) with Gaussian counterparts. In addition, we do find several cases where MRP mixture policies exhibit clear empirical advantages. In this paper, we provide a clearer understanding of the trade-offs involved, elevating MRP mixture policies from theoretical curiosity to a practical tool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that mixture policies provide theoretical advantages in flexibility and entropy robustness for entropy-regularized actor-critic methods like SAC, but are underused due to the absence of a low-variance reparameterization gradient estimator. The authors introduce a marginalized reparameterization (MRP) estimator, prove that it has strictly lower variance than the standard likelihood-ratio (LR) estimator, and present experiments on Gym MuJoCo, DeepMind Control Suite, and MetaWorld showing that MRP mixture policies outperform LR mixtures and reach parity (sometimes better) with Gaussian policies, with some environments exhibiting clear empirical gains.
Significance. If the MRP estimator delivers unbiased lower-variance gradients for mixture policies in the presence of entropy regularization and overlapping component supports, the work would make mixture policies a practical alternative to unimodal Gaussians, enabling more expressive policies without sacrificing sample efficiency. The multi-benchmark evaluation and explicit comparison to both LR mixtures and Gaussians strengthen the empirical case for revisiting mixture policies.
major comments (2)
- [§4] §4 (MRP estimator and variance proof): The claimed proof that MRP has lower variance than LR must explicitly verify that marginalization remains unbiased (or that any bias is negligible) when mixture components have overlapping supports, which is typical for learned policies; the entropy-regularized objective couples the entropy bonus to the full mixture density, so any inner approximation in the marginalization step can interact with the regularization term in ways not covered by a basic variance comparison between estimators.
- [§5] §5 (Experiments): The statement that MRP mixtures 'reach parity (sometimes better)' with Gaussian counterparts and exhibit 'clear empirical advantages' in 'several cases' requires quantification of effect sizes, number of environments showing gains, and statistical significance tests across seeds; without these, the practical superiority claim rests on qualitative description rather than load-bearing evidence.
minor comments (2)
- Notation for the mixture density and the marginalization operator should be introduced earlier and used consistently to avoid ambiguity when the entropy term is written in terms of the full mixture.
- The abstract and introduction would benefit from a short explicit statement of the assumptions under which the variance proof holds (e.g., exact marginalization, non-overlapping supports).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (MRP estimator and variance proof): The claimed proof that MRP has lower variance than LR must explicitly verify that marginalization remains unbiased (or that any bias is negligible) when mixture components have overlapping supports, which is typical for learned policies; the entropy-regularized objective couples the entropy bonus to the full mixture density, so any inner approximation in the marginalization step can interact with the regularization term in ways not covered by a basic variance comparison between estimators.
Authors: We appreciate this observation. The MRP estimator marginalizes exactly over the discrete component choice using the law of total expectation: the reparameterized sample is drawn conditionally on the component and then averaged with the mixture weights, yielding an unbiased estimator of the policy gradient for the mixture density irrespective of support overlap. The entropy term is computed directly from the closed-form mixture log-density log(∑_k π_k(a|s)) and its gradient is obtained analytically without approximation; the MRP estimator is applied solely to the expected-return portion of the objective. We will revise §4 to include an explicit unbiasedness lemma under overlapping supports together with a short derivation separating the entropy gradient from the MRP term. revision: yes
-
Referee: [§5] §5 (Experiments): The statement that MRP mixtures 'reach parity (sometimes better)' with Gaussian counterparts and exhibit 'clear empirical advantages' in 'several cases' requires quantification of effect sizes, number of environments showing gains, and statistical significance tests across seeds; without these, the practical superiority claim rests on qualitative description rather than load-bearing evidence.
Authors: We agree that quantitative support is necessary. In the revised version we will augment §5 and the appendix with tables that report, for every environment and seed, mean return ± standard deviation, Cohen’s d effect sizes relative to the Gaussian baseline, the exact count of environments in which MRP mixtures outperform Gaussians, and p-values from paired t-tests (or Wilcoxon signed-rank tests when normality assumptions are violated) across the 5–10 random seeds used in each benchmark. These additions will replace the current qualitative phrasing with concrete statistical evidence. revision: yes
Circularity Check
No circularity: MRP variance proof and experiments are self-contained
full rationale
The paper introduces the MRP estimator as a new technical contribution and states that it proves lower variance than the LR estimator. This proof is presented as an independent mathematical argument within the manuscript rather than reducing to a fitted parameter, a self-citation chain, or an ansatz imported from prior work by the same authors. The experimental comparisons are downstream validations of the estimator rather than inputs that define the claimed variance reduction. No load-bearing step in the derivation chain collapses to a tautology or to the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of the policy gradient theorem and entropy-regularized objective in continuous action spaces hold.
invented entities (1)
-
Marginalized reparameterization (MRP) estimator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning: Theory and algorithms
Alekh Agarwal, Nan Jiang, Sham M Kakade, and Wen Sun. Reinforcement learning: Theory and algorithms. CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep, 32: 0 96, 2019
work page 2019
-
[2]
Understanding the impact of entropy on policy optimization
Zafarali Ahmed, Nicolas Le Roux, Mohammad Norouzi, and Dale Schuurmans. Understanding the impact of entropy on policy optimization. In International conference on machine learning, pp.\ 151--160. PMLR, 2019
work page 2019
-
[3]
Maximum entropy reinforcement learning with mixture policies
Nir Baram, Guy Tennenholtz, and Shie Mannor. Maximum entropy reinforcement learning with mixture policies. arXiv preprint arXiv:2103.10176, 2021
-
[4]
On the sample complexity and metastability of heavy-tailed policy search in continuous control
Amrit Singh Bedi, Anjaly Parayil, Junyu Zhang, Mengdi Wang, and Alec Koppel. On the sample complexity and metastability of heavy-tailed policy search in continuous control. Journal of Machine Learning Research, 25 0 (39): 0 1--58, 2024
work page 2024
-
[5]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas L \'e onard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[6]
JAX : composable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/jax-ml/jax
work page 2018
-
[7]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
On upper and lower bounds for the variance of a function of a random variable
Theophilos Cacoullos. On upper and lower bounds for the variance of a function of a random variable. The Annals of Probability, 10 0 (3): 0 799--809, 1982
work page 1982
-
[9]
Myosuite: A contact-rich simulation suite for musculoskeletal motor control
Vittorio Caggiano, Huawei Wang, Guillaume Durandau, Massimo Sartori, and Vikash Kumar. Myosuite: A contact-rich simulation suite for musculoskeletal motor control. In Learning for Dynamics and Control Conference, pp.\ 492--507. PMLR, 2022
work page 2022
-
[10]
Specializing versatile skill libraries using local mixture of experts
Onur Celik, Dongzhuoran Zhou, Ge Li, Philipp Becker, and Gerhard Neumann. Specializing versatile skill libraries using local mixture of experts. In Conference on Robot Learning, 2022
work page 2022
-
[11]
Po-Wei Chou, Daniel Maturana, and Sebastian Scherer. Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution. In International conference on machine learning, pp.\ 834--843. PMLR, 2017
work page 2017
-
[12]
Hierarchical relative entropy policy search
Christian Daniel, Gerhard Neumann, and Jan Peters. Hierarchical relative entropy policy search. In Artificial Intelligence and Statistics, pp.\ 273--281. PMLR, 2012
work page 2012
-
[13]
Model-free reinforcement learning with continuous action in practice
Thomas Degris, Patrick M Pilarski, and Richard S Sutton. Model-free reinforcement learning with continuous action in practice. In 2012 American control conference (ACC), pp.\ 2177--2182. IEEE, 2012
work page 2012
-
[14]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In Jennifer Dy and Andreas Krause (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1587--1596. PMLR, 10--15 Jul 2018. URL https://proceedings.mlr.press/v8...
work page 2018
-
[15]
Yarin Gal. Uncertainty in deep learning. PhD thesis, University of Cambridge, 2016
work page 2016
-
[16]
Acquiring diverse robot skills via maximum entropy deep reinforcement learning
Tuomas Haarnoja. Acquiring diverse robot skills via maximum entropy deep reinforcement learning. PhD thesis, University of California, Berkeley, 2018
work page 2018
-
[17]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In International conference on machine learning, pp.\ 1352--1361. PMLR, 2017
work page 2017
-
[18]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pp.\ 1861--1870. PMLR, 2018 a
work page 2018
-
[19]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018 b
work page internal anchor Pith review arXiv 2018
-
[20]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905, 2018 c
work page internal anchor Pith review arXiv 2018
-
[21]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pp.\ 2555--2565. PMLR, 2019
work page 2019
-
[22]
Learning continuous control policies by stochastic value gradients
Nicolas Heess, Gregory Wayne, David Silver, Timothy Lillicrap, Tom Erez, and Yuval Tassa. Learning continuous control policies by stochastic value gradients. Advances in neural information processing systems, 28, 2015
work page 2015
-
[23]
Zhimin Hou, Kuangen Zhang, Yi Wan, Dongyu Li, Chenglong Fu, and Haoyong Yu. Off-policy maximum entropy reinforcement learning: Soft actor-critic with advantage weighted mixture policy (sac-awmp). arXiv preprint arXiv:2002.02829, 2020
-
[24]
Generalization in dexterous manipulation via geometry-aware multi-task learning
Wenlong Huang, Igor Mordatch, Pieter Abbeel, and Deepak Pathak. Generalization in dexterous manipulation via geometry-aware multi-task learning. arXiv preprint arXiv:2111.03062, 2021
-
[25]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations, 2016
work page 2016
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Student-t policy in reinforcement learning to acquire global optimum of robot control
Taisuke Kobayashi. Student-t policy in reinforcement learning to acquire global optimum of robot control. Applied Intelligence, 49 0 (12): 0 4335--4347, 2019
work page 2019
-
[28]
Model-free policy learning with reward gradients
Qingfeng Lan, Samuele Tosatto, Homayoon Farrahi, and Rupam Mahmood. Model-free policy learning with reward gradients. In International Conference on Artificial Intelligence and Statistics, pp.\ 4217--4234. PMLR, 2022
work page 2022
-
[29]
Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model
Alex X Lee, Anusha Nagabandi, Pieter Abbeel, and Sergey Levine. Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model. Advances in Neural Information Processing Systems, 33: 0 741--752, 2020
work page 2020
-
[30]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
The concrete distribution: A continuous relaxation of discrete random variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. In International Conference on Learning Representations, 2016
work page 2016
-
[32]
Leveraging exploration in off-policy algorithms via normalizing flows
Bogdan Mazoure, Thang Doan, Audrey Durand, Joelle Pineau, and R Devon Hjelm. Leveraging exploration in off-policy algorithms via normalizing flows. In Conference on Robot Learning, pp.\ 430--444. PMLR, 2020
work page 2020
-
[33]
S\ 2\ AC : Energy-based reinforcement learning with stein soft actor critic
Safa Messaoud, Billel Mokeddem, Zhenghai Xue, Linsey Pang, Bo An, Haipeng Chen, and Sanjay Chawla. S\ 2\ AC : Energy-based reinforcement learning with stein soft actor critic. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=rAHcTCMaLc
work page 2024
-
[34]
Reducing reparameterization gradient variance
Andrew Miller, Nick Foti, Alexander D'Amour, and Ryan P Adams. Reducing reparameterization gradient variance. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[35]
Monte carlo gradient estimation in machine learning
Shakir Mohamed, Mihaela Rosca, Michael Figurnov, and Andriy Mnih. Monte carlo gradient estimation in machine learning. Journal of Machine Learning Research, 21 0 (132): 0 1--62, 2020
work page 2020
-
[36]
Robot skill adaptation via soft actor-critic gaussian mixture models
Iman Nematollahi, Erick Rosete-Beas, Adrian R \"o fer, Tim Welschehold, Abhinav Valada, and Wolfram Burgard. Robot skill adaptation via soft actor-critic gaussian mixture models. In 2022 International Conference on Robotics and Automation (ICRA), pp.\ 8651--8657. IEEE, 2022
work page 2022
-
[37]
Greedy actor-critic: A new conditional cross-entropy method for policy improvement
Samuel Neumann, Sungsu Lim, Ajin George Joseph, Yangchen Pan, Adam White, and Martha White. Greedy actor-critic: A new conditional cross-entropy method for policy improvement. In The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[38]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019
work page 2019
-
[39]
Matthias Plappert, Marcin Andrychowicz, Alex Ray, Bob McGrew, Bowen Baker, Glenn Powell, Jonas Schneider, Josh Tobin, Maciek Chociej, Peter Welinder, et al. Multi-goal reinforcement learning: Challenging robotics environments and request for research. arXiv preprint arXiv:1802.09464, 2018
-
[40]
Probabilistic mixture-of-experts for efficient deep reinforcement learning
Jie Ren, Yewen Li, Zihan Ding, Wei Pan, and Hao Dong. Probabilistic mixture-of-experts for efficient deep reinforcement learning. arXiv preprint arXiv:2104.09122, 2021
-
[41]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Strength through diversity: Robust behavior learning via mixture policies
Tim Seyde, Wilko Schwarting, Igor Gilitschenski, Markus Wulfmeier, and Daniela Rus. Strength through diversity: Robust behavior learning via mixture policies. In Conference on Robot Learning, pp.\ 1144--1155. PMLR, 2022
work page 2022
-
[43]
Reinforcement learning: An introduction
Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[44]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999
work page 1999
-
[45]
Implicit policy for reinforcement learning
Yunhao Tang and Shipra Agrawal. Implicit policy for reinforcement learning. arXiv preprint arXiv:1806.06798, 2018
-
[46]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[47]
SciPy 1.0: fundamental algorithms for scientific computing in Python
Pauli Virtanen, Ralf Gommers, Travis E Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, et al. SciPy 1.0: fundamental algorithms for scientific computing in Python . Nature methods, 17 0 (3): 0 261--272, 2020
work page 2020
-
[48]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=AHvFDPi-FA
work page 2023
-
[49]
Simple statistical gradient-following algorithms for connectionist reinforcement learning
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8: 0 229--256, 1992
work page 1992
-
[50]
Variance reduction properties of the reparameterization trick
Ming Xu, Matias Quiroz, Robert Kohn, and Scott A Sisson. Variance reduction properties of the reparameterization trick. In The 22nd international conference on artificial intelligence and statistics, pp.\ 2711--2720. PMLR, 2019
work page 2019
-
[51]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning, pp.\ 1094--1100. PMLR, 2020
work page 2020
-
[52]
Latent state marginalization as a low-cost approach for improving exploration
Dinghuai Zhang, Aaron Courville, Yoshua Bengio, Qinqing Zheng, Amy Zhang, and Ricky TQ Chen. Latent state marginalization as a low-cost approach for improving exploration. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[53]
Model-based reparameterization policy gradient methods: Theory and practical algorithms
Shenao Zhang, Boyi Liu, Zhaoran Wang, and Tuo Zhao. Model-based reparameterization policy gradient methods: Theory and practical algorithms. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.