Recognition: 2 theorem links
· Lean TheoremSparse Layers are Critical to Scaling Looped Language Models
Pith reviewed 2026-05-12 04:15 UTC · model grok-4.3
The pith
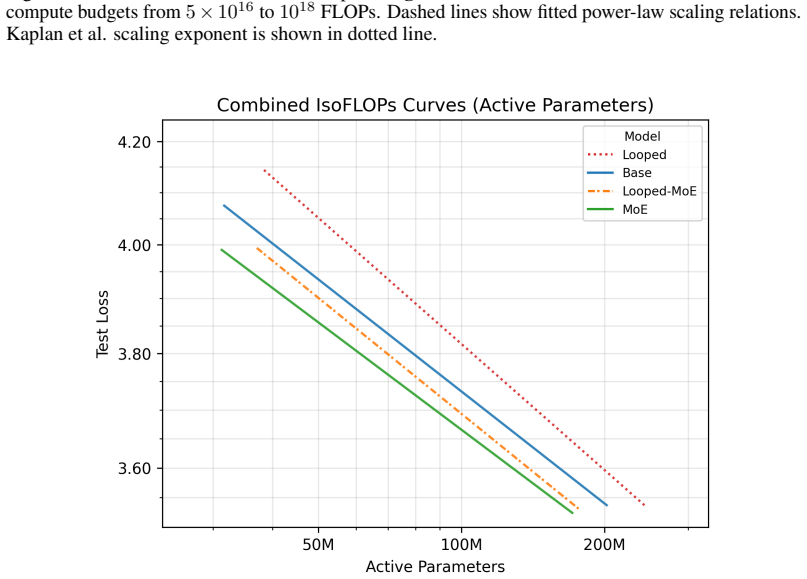
Looped models using sparse MoE layers scale better than dense looped models or standard transformers by activating different experts on each loop iteration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
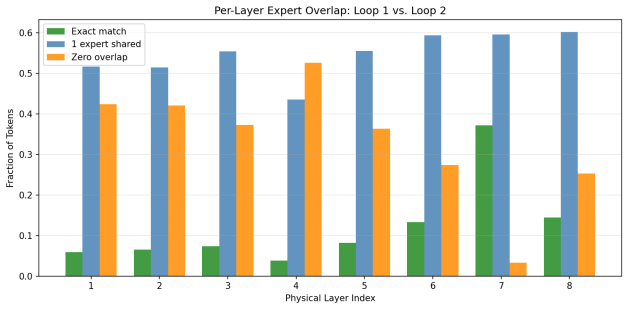
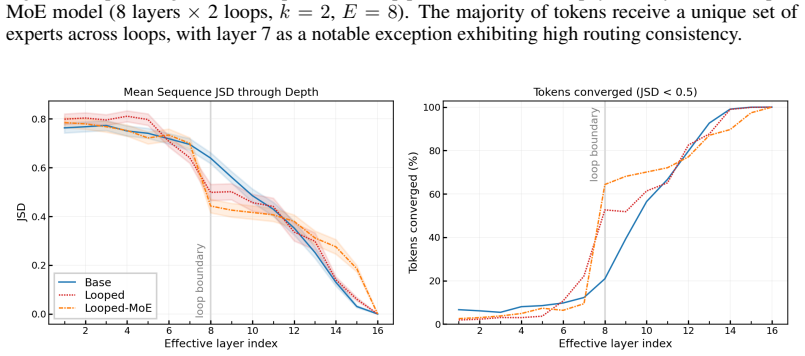
Looped language models repeat transformer layers to save memory but fail to scale as well as models with unique layers per depth. When the repeated layers are Mixture-of-Experts layers, however, the models scale better than standard baselines because routing selects different experts on each loop pass through the shared weights. This routing divergence restores the diversity of computation that unique layers would provide. Looped models also support more effective early exits at loop boundaries since the output-producing layers are reached at those points, yielding improved compute-quality trade-offs.
What carries the argument
Routing divergence across loop iterations in Looped-MoE architectures, where distinct experts are chosen for the same shared parameters on successive passes.
If this is right
- Looped-MoE models can outperform standard transformers at scale while using fewer unique parameters.
- Early exits at loop boundaries allow significant inference speedups with little quality loss.
- Memory costs decrease because layers are shared across depth.
- Scaling looped models requires sparse layers rather than dense repetition.
Where Pith is reading between the lines
- This approach may extend to other repeated computation patterns in neural networks where parameter sharing limits expressivity.
- Future work could explore whether similar divergence mechanisms appear in other sparse or modular architectures.
- Testing these models at scales beyond those reported would confirm if the scaling advantage persists.
Load-bearing premise
The observed scaling advantage in Looped-MoE models results specifically from the divergence in expert routing between iterations rather than from differences in training dynamics or optimization.
What would settle it
Training a dense looped model using the exact same optimizer, data, and hyperparameters as the Looped-MoE version and observing whether it closes the performance gap at scale.
Figures






read the original abstract
Looped language models repeat a set of transformer layers through depth, reducing memory costs and providing natural early-exit points at loop boundaries. However, looped models do not scale as favorably as standard transformers with unique layers. We compare standard and Mixture-of-Experts (MoE) transformers, with and without looping, and find two main results. First, we find Looped-MoE models scale better than the standard baseline while dense looped models do not. We trace this to routing divergence between loops: in Looped-MoE models, different experts are activated on each pass through the same shared layers, recovering expressivity without additional parameters. Our second finding is that looped models have better compute-quality trade-offs with early exits than standard models. Because each loop ends with the same layers that produce the final output, loop boundaries are superior exit points, as confirmed by earlier output convergence at these points. In sum, we provide a clear direction for scaling looped models: a Looped-MoE model with early exits can not only beat standard transformers at scale, but also enable significant memory and inference savings with minimal degradation in quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares standard transformers, dense looped transformers, and Looped-MoE variants. It claims that Looped-MoE models scale better than both the standard baseline and dense looped models, attributing the advantage to routing divergence (different experts activated on successive passes through shared layers), which recovers expressivity without extra parameters. A secondary claim is that looped models exhibit superior compute-quality trade-offs when using early exits at loop boundaries, due to earlier output convergence at those points.
Significance. If the empirical trends hold under controlled conditions, the work identifies a concrete architectural direction for memory-efficient scaling: combining looping (for reduced memory and natural early-exit points) with sparse MoE layers (to restore scaling behavior). This could enable models that match or exceed standard transformer performance at scale while delivering inference and memory savings, directly addressing the scaling limitations of pure looped architectures.
major comments (1)
- [Abstract / Experiments] The causal attribution of the Looped-MoE scaling advantage to routing divergence (Abstract, paragraph 2) is not isolated. The reported comparisons hold total parameters and layer sharing fixed but do not include an ablation in which routing decisions are forced to be identical across loops (e.g., by caching the first-loop gate outputs or using a deterministic shared routing mask) while keeping optimizer state, data order, and active-parameter count unchanged. Without this control, the observed gap could arise from MoE-specific training dynamics or effective capacity differences rather than divergence per se. This directly undermines the central mechanistic claim.
minor comments (1)
- [Abstract] The abstract omits concrete experimental details (model sizes, number of loops, expert counts, training steps, and statistical controls), which should be summarized even at high level to allow readers to gauge the scale of the reported trends.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. The concern regarding causal isolation of routing divergence is substantive, and we have addressed it with additional experiments in the revision.
read point-by-point responses
-
Referee: [Abstract / Experiments] The causal attribution of the Looped-MoE scaling advantage to routing divergence (Abstract, paragraph 2) is not isolated. The reported comparisons hold total parameters and layer sharing fixed but do not include an ablation in which routing decisions are forced to be identical across loops (e.g., by caching the first-loop gate outputs or using a deterministic shared routing mask) while keeping optimizer state, data order, and active-parameter count unchanged. Without this control, the observed gap could arise from MoE-specific training dynamics or effective capacity differences rather than divergence per se. This directly undermines the central mechanistic claim.
Authors: We agree that a direct control isolating routing divergence strengthens the mechanistic interpretation. In the revised manuscript we introduce exactly this ablation: a fixed-routing Looped-MoE variant that caches the first-loop gate outputs and reuses them for all subsequent passes. All other variables (active-parameter count per token, optimizer state, data order, and total parameters) are held identical to the divergent-routing Looped-MoE. Results show that the fixed-routing model loses the scaling advantage and behaves similarly to the dense looped baseline, while the original divergent-routing Looped-MoE retains superior scaling. We have added the new experiment and figures to the main text, updated the abstract and discussion to incorporate this evidence, and clarified that the performance gap is attributable to routing divergence rather than other MoE training effects. revision: yes
Circularity Check
No circularity: claims rest on direct empirical comparisons
full rationale
The paper reports experimental results from training and evaluating standard transformers, MoE variants, looped models, and Looped-MoE models. The key observation that Looped-MoE models exhibit routing divergence (different experts activated across loops) is presented as a post-hoc interpretation of measured activation patterns and performance gaps, not as a derived prediction or first-principles result. No equations, parameter fits, uniqueness theorems, or self-citations are used to generate the central claims; the scaling advantage and early-exit benefits are supported by direct architecture comparisons. This is the most common honest non-finding for purely empirical papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Routing divergence across loops is the primary cause of improved scaling in Looped-MoE models.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/reality_from_one_distinctionreality_from_one_distinction (8-tick period and distinction forcing) echoesLooped-MoE models scale better than the standard baseline while dense looped models do not. We trace this to routing divergence between loops: in Looped-MoE models, different experts are activated on each pass through the same shared layers, recovering expressivity without additional parameters.
-
IndisputableMonolith/Foundation/ArithmeticFromLogicLogicNat orbit and period structure echoeslooped models have better compute-quality trade-offs with early exits than standard models. Because each loop ends with the same layers that produce the final output, loop boundaries are superior exit points
Reference graph
Works this paper leans on
-
[1]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal Transformers, March 2019. URL http://arxiv.org/abs/1807.03819. arXiv:1807.03819 [cs]
work page internal anchor Pith review arXiv 2019
-
[2]
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang,...
-
[3]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bar- toldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, February 2025. URL http://arxiv.org/abs/2502.05171. arXiv:2502.05171 [cs]
work page internal anchor Pith review arXiv 2025
-
[4]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling Laws for Neural Language Models, January 2020. URL http://arxiv.org/abs/2001.08361. arXiv:2001.08361 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, January 2017. URLhttp://arxiv.org/abs/1701.06538. arXiv:1701.06538 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
MoEUT: Mixture-of-Experts Universal Transformers
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber, Christopher Potts, and Christopher D Manning. MoEUT: Mixture-of-Experts Universal Transformers
-
[7]
Surat Teerapittayanon, Bradley McDanel, and H.T. Kung. BranchyNet: Fast inference via early exiting from deep neural networks. In2016 23rd International Conference on Pattern Recognition (ICPR), pages 2464–2469, Cancun, December 2016. IEEE. ISBN 978-1-5090-4847-
work page 2016
-
[8]
URL http://ieeexplore.ieee.org/document/ 7900006/
doi: 10.1109/ICPR.2016.7900006. URL http://ieeexplore.ieee.org/document/ 7900006/
-
[9]
DeeBERT: dynamic early exiting for accelerating BERT inference.arXiv preprint arXiv:2004.12993, 2020
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference, April 2020. URL http://arxiv.org/abs/2004. 12993. arXiv:2004.12993 [cs]
-
[10]
arXiv preprint arXiv:2207.07061 , year=
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. Confident Adaptive Language Modeling, October 2022. URL http: //arxiv.org/abs/2207.07061. arXiv:2207.07061 [cs]
-
[11]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding, November 2023. URL http:// arxiv.org/abs/2104.09864. arXiv:2104.09864 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
GLU Variants Improve Transformer
Noam Shazeer. GLU Variants Improve Transformer, February 2020. URL http://arxiv. org/abs/2002.05202. arXiv:2002.05202 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Root Mean Square Layer Normalization
Biao Zhang and Rico Sennrich. Root Mean Square Layer Normalization. In Advances in Neural Information Processing Systems, volume 32. Curran Asso- ciates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ 1e8a19426224ca89e83cef47f1e7f53b-Abstract.html
work page 2019
-
[14]
Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res., 23(1):120:5232– 120:5270, January 2022. ISSN 1532-4435. URL https://dl.acm.org/doi/10.5555/ 3586589.3586709
-
[15]
ST-MoE: Designing Stable and Transferable Sparse Expert Models, April
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. ST-MoE: Designing Stable and Transferable Sparse Expert Models, April
-
[16]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
URLhttp://arxiv.org/abs/2202.08906. arXiv:2202.08906 [cs]. 10
work page internal anchor Pith review arXiv
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer, March 2022. URL http: //arxiv.org/abs/2203.03466. arXiv:2203.03466 [cs]
-
[19]
µ-parametrization for mixture of experts, October 2025
Jan Mała´snicki, Kamil Ciebiera, Mateusz Boru ´n, Maciej Pióro, Jan Ludziejewski, Maciej Stefaniak, Michał Krutul, Sebastian Jaszczur, Marek Cygan, Kamil Adamczewski, and Jakub Krajewski. µ-parametrization for mixture of experts, October 2025. URL http://arxiv. org/abs/2508.09752. arXiv:2508.09752 [cs]
-
[20]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, October 2024. URL http://arxiv.org/abs/2406.17557. arXiv:2406.17557 [cs]
work page internal anchor Pith review arXiv 2024
-
[22]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. MiniCPM: Unveiling the Potential of Small Langu...
work page internal anchor Pith review arXiv 2024
-
[23]
Training Dynamics of the Cooldown Stage in Warmup-Stable-Decay Learning Rate Scheduler, August 2025
Aleksandr Dremov, Alexander Hägele, Atli Kosson, and Martin Jaggi. Training Dynamics of the Cooldown Stage in Warmup-Stable-Decay Learning Rate Scheduler, August 2025. URL http://arxiv.org/abs/2508.01483. arXiv:2508.01483 [cs]
-
[24]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Hajishirzi. OLMES: A Standard for Language Model Evaluations, February 2025. URL http://arxiv. org/abs/2406.08446. arXiv:2406.08446 [cs]
-
[25]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling Laws For Stable Looped Language Models, 2026. URL https://arxiv.org/abs/2604. 12946. Version Number: 1
work page 2026
-
[26]
interpreting GPT: the logit lens — LessWrong
nostalgebraist. interpreting GPT: the logit lens — LessWrong. August
-
[27]
URL https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/ interpreting-gpt-the-logit-lens
-
[28]
Róbert Csordás, Kazuki Irie, and Jürgen Schmidhuber. Approximating Two-Layer Feedforward Networks for Efficient Transformers, November 2023. URL http://arxiv.org/abs/2310. 10837. arXiv:2310.10837 [cs]
-
[29]
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention, September 2024
Róbert Csordás, Piotr Pi˛ ekos, Kazuki Irie, and Jürgen Schmidhuber. SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention, September 2024. URL http://arxiv.org/ abs/2312.07987. arXiv:2312.07987 [cs]
-
[30]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer Normalization, July 2016. URLhttp://arxiv.org/abs/1607.06450. arXiv:1607.06450 [stat]. 11
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
LayerSkip: enabling early exit inference and self- speculative decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A. Aly, Beidi Chen, and Carole-Jean Wu. LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguisti...
- [32]
-
[33]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, October 2025. URLhttp://arxiv.org/abs/2507.10524. arXiv:2507.10524 [cs]
-
[34]
Don’t be lazy: CompleteP enables compute- efficient deep transformers, January 2026
Nolan Dey, Bin Claire Zhang, Lorenzo Noci, Mufan Li, Blake Bordelon, Shane Bergsma, Cengiz Pehlevan, Boris Hanin, and Joel Hestness. Don’t be lazy: CompleteP enables compute- efficient deep transformers, January 2026. URL http://arxiv.org/abs/2505.01618. arXiv:2505.01618 [cs]. 12 A Appendix Compute.All experiments were run on NVIDIA H100 GPUs (80GB). Appr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.