Recognition: 2 theorem links
· Lean TheoremSHIELD: Scalable Optimal Control with Certification using Duality and Convexity
Pith reviewed 2026-05-13 06:23 UTC · model grok-4.3
The pith
SHIELD uses strong convexity and Lagrangian duality to derive certificates that safely prune constraints and variables from convex optimal control problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
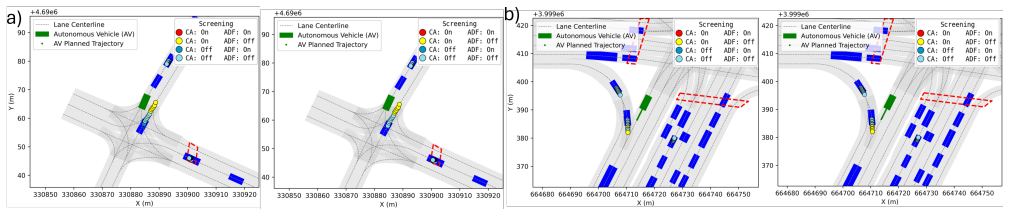
From strong convexity and Lagrangian duality, certificates are derived that safely discard constraints and decision variables in convex programs, guaranteeing that all removed constraints remain satisfied and all removed variables are null. A transformer-based deep neural network guides the dual certificate inference to accelerate the process. When applied to stochastic model predictive control in complex traffic scenarios, the reduced problems produce order-of-magnitude speedups while preserving feasibility and closed-loop safety compared with the full-dimensional formulation.
What carries the argument
Dual certificates obtained from the Lagrangian of a strongly convex problem, which certify that a constraint or variable can be removed without changing the optimal solution.
If this is right
- Real-time solution of high-dimensional stochastic MPC becomes feasible on embedded hardware.
- Closed-loop safety certificates transfer directly from the reduced problem to the original plant.
- The same pruning certificates apply to any other strongly convex program with l1 regularization.
- Training the transformer once allows repeated fast inference across varying initial conditions.
Where Pith is reading between the lines
- The method could be combined with warm-starting or active-set solvers to further cut computation in receding-horizon loops.
- If the network is replaced by an exact dual solver, the same certificates would still guarantee safety without learned components.
- The pruning logic may extend to problems whose strong convexity holds only locally around the operating trajectory.
Load-bearing premise
The underlying convex programs are strongly convex and the transformer network infers valid dual certificates in every scenario that will be encountered.
What would settle it
A single traffic scenario in which the solution of the pruned problem violates one of the discarded original constraints or produces a nonzero value for a variable declared null.
Figures



read the original abstract
We present SHIELD, a hierarchical algorithm that reduces both the decision-variable dimension and the constraint set in $\ell_1$-regularized convex programs. From strong convexity and Lagrangian duality, we derive certificates that \emph{safely} discard constraints and decision variables while guaranteeing that all removed constraints remain satisfied and all removed variables are null. To further accelerate the proposed algorithm, we propose a transformer-based deep neural network to guide the dual certificate inference. We validate SHIELD on stochastic model predictive control (SMPC) in complex, multi-modal traffic scenarios, comparing against a full-dimensional SMPC policy. Numerical simulations demonstrate order-of-magnitude computational speedups while preserving feasibility and closed-loop safety, highlighting the practicality of certifiably safe, lightweight MPC in complex driving scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SHIELD, a hierarchical algorithm that reduces both decision-variable dimension and constraint set size in ℓ1-regularized convex programs. Certificates derived from strong convexity and Lagrangian duality are claimed to safely discard constraints and variables while guaranteeing that removed constraints remain satisfied and removed variables are null. A transformer-based neural network is used to accelerate dual-certificate inference, and the method is validated on stochastic MPC for multi-modal traffic scenarios, with claims of order-of-magnitude speedups while preserving feasibility and closed-loop safety.
Significance. If the duality-derived certificates remain exact under the neural-network approximation and the approach generalizes reliably, the work could meaningfully advance scalable, certifiably safe MPC for robotics and autonomous driving by combining formal safety guarantees with practical computational gains.
major comments (2)
- [Certificate derivation and NN inference sections] The core safety argument relies on exact dual feasibility thresholds derived from KKT conditions under strong convexity (presumably in the certificate derivation section). The transformer network produces only approximate duals, yet no error bounds, robustness margins, or proof are supplied showing that these approximations preserve the exact discarding guarantees; this directly undermines the claim that closed-loop safety is maintained.
- [Numerical experiments section] Numerical validation reports order-of-magnitude speedups versus full-dimensional SMPC but provides no quantitative safety metrics (e.g., constraint violation rates, minimum safety margins, or closed-loop violation counts) across the tested traffic scenarios; without these, the preservation of feasibility cannot be verified.
minor comments (2)
- [Preliminaries and notation] Notation for dual variables, certificate thresholds, and the precise mapping from network outputs to discarding decisions should be defined more explicitly and consistently in the early technical sections.
- [Neural network architecture section] The training data, loss function, and generalization procedure for the transformer network are not described; adding these details would clarify how the network is fitted without introducing circular dependence on the safety claims.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments. We appreciate the opportunity to clarify and strengthen our manuscript. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Certificate derivation and NN inference sections] The core safety argument relies on exact dual feasibility thresholds derived from KKT conditions under strong convexity (presumably in the certificate derivation section). The transformer network produces only approximate duals, yet no error bounds, robustness margins, or proof are supplied showing that these approximations preserve the exact discarding guarantees; this directly undermines the claim that closed-loop safety is maintained.
Authors: We agree that the neural network approximation requires careful analysis to maintain the safety guarantees. In the revised version, we will add a new subsection providing error bounds on the dual variable approximation. Leveraging the strong convexity of the problem, we will show that the approximation error can be bounded such that the certificate thresholds remain valid with a safety margin. This will include a proof sketch ensuring that discarded constraints are still satisfied and variables remain null under the approximated duals. We will also report the observed approximation errors in the experiments. revision: yes
-
Referee: [Numerical experiments section] Numerical validation reports order-of-magnitude speedups versus full-dimensional SMPC but provides no quantitative safety metrics (e.g., constraint violation rates, minimum safety margins, or closed-loop violation counts) across the tested traffic scenarios; without these, the preservation of feasibility cannot be verified.
Authors: We acknowledge the need for explicit quantitative safety metrics. In the revision, we will include additional results in the numerical experiments section, such as tables showing constraint violation rates (which are zero in all cases), minimum safety margins over the horizon, and counts of any closed-loop safety violations across the multi-modal traffic scenarios. These will confirm that feasibility and safety are preserved while achieving the reported speedups. revision: yes
Circularity Check
No circularity: certificates derived from standard duality; NN is separate empirical accelerator
full rationale
The claimed derivation starts from strong convexity and Lagrangian duality to produce certificates that safely discard constraints and variables while guaranteeing satisfaction and nullity. This is a direct application of established convex optimization results (KKT conditions, dual feasibility) and does not reduce to any fitted component or self-citation by construction. The transformer network is introduced afterward solely for accelerating dual inference and is validated empirically on SMPC instances; the safety claim is tied to the exact duality certificates rather than to the network outputs. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- transformer network parameters
axioms (1)
- domain assumption The convex programs are strongly convex
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
From strong convexity and Lagrangian duality, we derive certificates that safely discard constraints and decision variables while guaranteeing that all removed constraints remain satisfied and all removed variables are null.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
If ∥μ⋆i∥2 ≤ ϵ/ζ ... then the i-th constraint can be safely removed
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning to optimize in model predictive con- trol,
J. Sacks and B. Boots, “Learning to optimize in model predictive con- trol,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, May 2022, p. 10549–10556
work page 2022
-
[2]
Learning- based approximate nonlinear model predictive control motion cueing,
C. G. Arango, H. Asadi, M. R. C. Qazani, and C. P. Lim, “Learning- based approximate nonlinear model predictive control motion cueing,”
-
[3]
Available: https://arxiv.org/abs/2504.00469
[Online]. Available: https://arxiv.org/abs/2504.00469
-
[4]
High-speed finite control set model predictive control for power electronics,
B. Stellato, T. Geyer, and P. J. Goulart, “High-speed finite control set model predictive control for power electronics,”IEEE Transactions on Power Electronics, vol. 32, no. 5, p. 4007–4020, May 2017
work page 2017
-
[5]
A. Chakrabarty, R. Quirynen, D. Romeres, and S. Di Cairano, “Learn- ing disagreement regions with deep neural networks to reduce practical complexity of mixed-integer mpc,” in2021 IEEE International Confer- ence on Systems, Man, and Cybernetics (SMC), 2021, pp. 3238–3244
work page 2021
-
[6]
Warm start of mixed-integer programs for model predictive control of hybrid systems,
T. Marcucci and R. Tedrake, “Warm start of mixed-integer programs for model predictive control of hybrid systems,”IEEE Transactions on Automatic Control, vol. 66, no. 6, pp. 2433–2448, 2021
work page 2021
-
[7]
Near-optimal rapid mpc using neural networks: A primal-dual policy learning framework,
X. Zhang, M. Bujarbaruah, and F. Borrelli, “Near-optimal rapid mpc using neural networks: A primal-dual policy learning framework,”
-
[8]
Available: https://arxiv.org/abs/1912.04744
[Online]. Available: https://arxiv.org/abs/1912.04744
-
[9]
Learning for online mixed-integer model predictive control with parametric optimality certificates,
L. Russo, S. H. Nair, L. Glielmo, and F. Borrelli, “Learning for online mixed-integer model predictive control with parametric optimality certificates,”IEEE Control Systems Letters, vol. 7, pp. 2215–2220, 2023
work page 2023
-
[10]
Coco: Online mixed-integer control via supervised learning,
A. Cauligi, P. Culbertson, E. Schmerling, M. Schwager, B. Stellato, and M. Pavone, “Coco: Online mixed-integer control via supervised learning,” 2021. [Online]. Available: https://arxiv.org/abs/2107.08143
-
[11]
Learning mixed-integer convex optimization strategies for robot planning and control,
A. Cauligi, P. Culbertson, B. Stellato, D. Bertsimas, M. Schwager, and M. Pavone, “Learning mixed-integer convex optimization strategies for robot planning and control,” 2022. [Online]. Available: https://arxiv.org/abs/2004.03736
-
[12]
Safe feature elimination in sparse supervised learning,
L. El Ghaoui, V . Viallon, and T. Rabbani, “Safe feature elimination in sparse supervised learning,” EECS Dept., University of California at Berkeley, Tech. Rep. UC/EECS-2010-126, September 2010
work page 2010
-
[13]
Dynamic screening: Accelerating first-order algorithms for the lasso and group- lasso,
A. Bonnefoy, V . Emiya, L. Ralaivola, and R. Gribonval, “Dynamic screening: Accelerating first-order algorithms for the lasso and group- lasso,”IEEE Transactions on Signal Processing, vol. 63, no. 19, 2015. [Online]. Available: http://dx.doi.org/10.1109/TSP.2015.2447503
-
[14]
Mind the duality gap: safer rules for the lasso,
O. Fercoq, A. Gramfort, and J. Salmon, “Mind the duality gap: safer rules for the lasso,” 2015. [Online]. Available: https: //arxiv.org/abs/1505.03410
-
[15]
Scalable multi-modal model predictive control via duality-based interaction predictions,
H. Kim, S. H. Nair, and F. Borrelli, “Scalable multi-modal model predictive control via duality-based interaction predictions,” in2024 IEEE Intelligent Vehicles Symposium (IV), 2024, pp. 1499–1504
work page 2024
-
[16]
Predictive control for autonomous driving with uncertain, multimodal predictions,
S. H. Nair, H. Lee, E. Joa, Y . Wang, H. E. Tseng, and F. Borrelli, “Predictive control for autonomous driving with uncertain, multimodal predictions,”IEEE Transactions on Control Systems Technology, vol. 33, no. 4, pp. 1178–1192, 2025
work page 2025
-
[17]
Distributed model predictive control using a chain of tubes,
B. Hernandez and P. Trodden, “Distributed model predictive control using a chain of tubes,” in2016 UKACC 11th International Conference on Control (CONTROL), 2016, pp. 1–6
work page 2016
-
[18]
Conflict-based search for multi-robot motion planning with kinodynamic constraints,
J. Kottinger, S. Almagor, and M. Lahijanian, “Conflict-based search for multi-robot motion planning with kinodynamic constraints,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 13 494–13 499
work page 2022
-
[19]
B. Li, Y . Ouyang, Y . Zhang, T. Acarman, Q. Kong, and Z. Shao, “Opti- mal cooperative maneuver planning for multiple nonholonomic robots in a tiny environment via adaptive-scaling constrained optimization,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1511–1518, 2021
work page 2021
-
[20]
Enhancing Sparsity by Reweightedℓ 1 Minimization,
E. J. Cand `es, M. B. Wakin, and S. P. Boyd, “Enhancing Sparsity by Reweightedℓ 1 Minimization,”Journal of Fourier Analysis and Applications, vol. 14, no. 5, pp. 877–905, Dec. 2008
work page 2008
-
[21]
S. P. Boyd and L. Vandenberghe,Convex optimization. Cambridge University Press, 2004
work page 2004
-
[22]
Iteration complexity of feasible descent methods for convex optimization,
P.-W. Wang and C.-J. Lin, “Iteration complexity of feasible descent methods for convex optimization,”Journal of Machine Learning Research, vol. 15, no. 45, pp. 1523–1548, 2014
work page 2014
-
[23]
Nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,
H. Caesar and J. Kabzan, “Nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,” inCVPR ADP3 workshop, 2021
work page 2021
-
[24]
N. Nayakanti, R. Al-Rfou, A. Zhou, K. Goel, K. S. Refaat, and B. Sapp, “Wayformer: Motion forecasting via simple & efficient attention networks,” 2022. [Online]. Available: https: //arxiv.org/abs/2207.05844
-
[25]
Unitraj: A unified framework for scalable vehicle trajectory prediction,
L. Feng, M. Bahari, K. M. B. Amor, ´E. Zablocki, M. Cord, and A. Alahi, “Unitraj: A unified framework for scalable vehicle trajectory prediction,”arXiv preprint arXiv:2403.15098, 2024
-
[26]
Casadi: a software framework for nonlinear optimization and optimal control,
J. A. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl, “Casadi: a software framework for nonlinear optimization and optimal control,”Mathematical Programming Computation, 2019
work page 2019
-
[27]
Gurobi Optimizer Reference Manual,
Gurobi Optimization, LLC, “Gurobi Optimizer Reference Manual,”
- [28]
-
[29]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017
work page 2017
-
[30]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”
-
[31]
Decoupled Weight Decay Regularization
[Online]. Available: https://arxiv.org/abs/1711.05101 APPENDIX A. KKT Conditions At a primal–dual optimal point(θ ⋆ t , µ⋆, η⋆, ν⋆, g⋆ 1, g⋆ 2, γ⋆) of the epigraphic form (4): The primal feasibility requires ˜f i t (θ⋆ t )≤ −ζ∀i∈I c 1 ¯f i t (θ⋆ t )≤0,∀i∈I m−c 1 hi t(θ⋆ t ) = 0,∀i∈I p 1 Sθ ⋆ t −s ⋆ ≤0,−Sθ ⋆ t −s ⋆ ≤0, s ⋆ ≥0. The dual feasibility requires...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.