Recognition: no theorem link
DARE: Difficulty-Adaptive Reinforcement Learning with Co-Evolved Difficulty Estimation
Pith reviewed 2026-05-12 03:06 UTC · model grok-4.3
The pith
Reinforcement learning for large language models becomes more efficient when difficulty estimation co-evolves with the policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DARE co-evolves difficulty estimation with the policy via self-normalized importance sampling, maintains diverse difficulty coverage through a symmetric Beta sampling distribution, and applies tailored training strategies across difficulty tiers with adaptive compute allocation. Extensive experiments show this unified approach consistently outperforms existing methods in training efficiency, final effectiveness, and inference efficiency, producing more concise responses on easy tasks while improving correctness on hard ones.
What carries the argument
Co-evolution of difficulty estimation and policy via self-normalized importance sampling, augmented by symmetric Beta sampling for difficulty diversity and adaptive compute allocation across difficulty tiers.
If this is right
- Training efficiency rises because compute focuses on prompts that still provide strong learning signals.
- Final model performance improves specifically on hard reasoning tasks.
- Inference efficiency increases because models produce shorter outputs on easy inputs without loss of quality.
- The gains appear across multiple model sizes and reasoning domains.
Where Pith is reading between the lines
- Difficulty estimation may need to be updated continuously rather than treated as a static preprocessing step in long RL runs.
- The same joint-evolution pattern could apply to other adaptive sampling problems where agent skill changes over time.
- Lower inference costs from learned conciseness may allow wider deployment of reasoning models under tight resource limits.
Load-bearing premise
That updating the difficulty estimator together with the policy will keep the estimates accurate and beneficial even as the policy drifts and improves over training.
What would settle it
An experiment in which, after a substantial policy update, the estimated difficulties no longer predict actual rollout success rates on the same prompts and overall performance drops to the level of non-adaptive baselines.
Figures

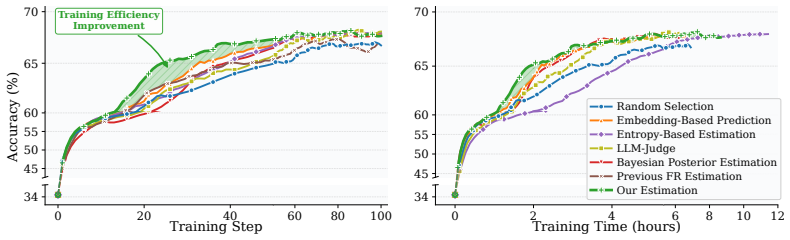

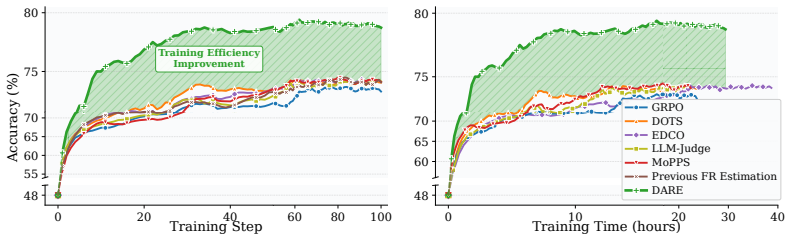

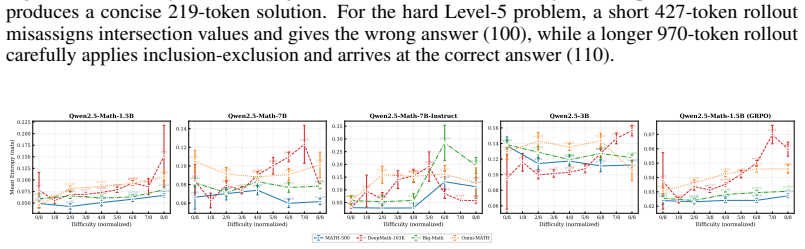


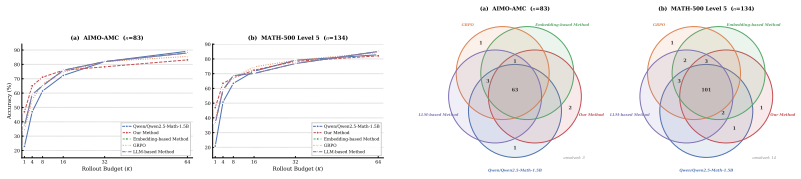
read the original abstract
Reinforcement learning improves the reasoning ability of large language models but remains costly and sample-inefficient, as many rollouts provide weak learning signals. Difficulty-aware data selection methods attempt to address this by prioritizing moderately difficult prompts, yet our analysis reveals three limitations: difficulty estimates become inaccurate under policy drift, data selection alone yields limited final-performance gains, and inference efficiency remains largely unchanged. These findings suggest that efficient and effective RL requires more than filtering by difficulty: the policy should learn to solve hard tasks while producing concise responses for easy ones. To this end, we propose **Dare**, a unified framework that co-evolves difficulty estimation with the policy via self-normalized importance sampling, maintains diverse difficulty coverage through a symmetric Beta sampling distribution, and applies tailored training strategies across difficulty tiers with adaptive compute allocation. Extensive experiments across multiple models and domains demonstrate that **Dare** consistently outperforms existing methods in training efficiency, final effectiveness, and inference efficiency, producing more concise responses on easy tasks while improving correctness on hard ones. Code is available at https://github.com/EtaYang10th/DARE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DARE, a unified framework for difficulty-adaptive RL in LLMs. It co-evolves difficulty estimation with the policy via self-normalized importance sampling (SNIS), maintains diverse coverage using a symmetric Beta sampling distribution, and applies tailored training strategies across difficulty tiers with adaptive compute allocation. The central claim is that this addresses three limitations of prior difficulty-aware selection methods (inaccurate estimates under drift, limited final gains from selection alone, and unchanged inference efficiency) and yields consistent improvements in training efficiency, final effectiveness, and inference efficiency across models and domains, with more concise outputs on easy tasks and higher correctness on hard ones. Code is released.
Significance. If the results hold, the work could advance sample-efficient RL for LLMs by making difficulty adaptation dynamic rather than static. The explicit code release supports reproducibility and community verification, which strengthens the contribution beyond typical empirical claims in the area.
major comments (2)
- [Method] Method section (co-evolution via SNIS): the framework relies on self-normalized importance sampling to update difficulty estimates as the policy changes, yet no variance-reduction steps (clipping, control variates, or effective-sample-size monitoring) are described. Because the paper itself identifies policy drift as the reason prior methods fail, it is necessary to show that the batch-normalized weights w_i = π_new(a_i|s_i)/π_old(a_i|s_i) retain sufficient effective sample size during typical LLM-RL updates; otherwise the tailored per-tier strategies rest on noisy labels.
- [Experiments] Experiments section: the abstract asserts consistent outperformance in training efficiency, final performance, and inference efficiency, but the provided text supplies no quantitative metrics, ablation tables, error bars, or statistical tests. Without these, the load-bearing claim that co-evolution plus Beta sampling plus adaptive compute produces gains beyond simple data filtering cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: adding one or two concrete performance deltas (e.g., relative token reduction on easy tasks or accuracy lift on hard tasks) would make the claims more immediately verifiable.
- Notation: the symmetric Beta distribution is introduced for diversity; a short equation or pseudocode line showing how its parameters are set relative to the current difficulty estimates would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the presentation and address the concerns raised.
read point-by-point responses
-
Referee: [Method] Method section (co-evolution via SNIS): the framework relies on self-normalized importance sampling to update difficulty estimates as the policy changes, yet no variance-reduction steps (clipping, control variates, or effective-sample-size monitoring) are described. Because the paper itself identifies policy drift as the reason prior methods fail, it is necessary to show that the batch-normalized weights w_i = π_new(a_i|s_i)/π_old(a_i|s_i) retain sufficient effective sample size during typical LLM-RL updates; otherwise the tailored per-tier strategies rest on noisy labels.
Authors: We agree that an explicit analysis of weight stability is warranted given our discussion of policy drift in prior methods. In the revised manuscript we will add a new subsection (or appendix) reporting the effective sample size of the SNIS weights throughout training on the main benchmarks. We will also include a short discussion explaining why the symmetric Beta sampling distribution, combined with the gradual co-evolution schedule, keeps ESS sufficiently high without requiring additional clipping or control variates in our setting. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts consistent outperformance in training efficiency, final performance, and inference efficiency, but the provided text supplies no quantitative metrics, ablation tables, error bars, or statistical tests. Without these, the load-bearing claim that co-evolution plus Beta sampling plus adaptive compute produces gains beyond simple data filtering cannot be evaluated.
Authors: The full manuscript already contains quantitative results, ablation studies, and multi-model comparisons in Sections 4 and 5. To make these claims more readily evaluable, we will revise the experiments section to include error bars on all plots, report statistical significance tests for key comparisons, and expand the ablation tables to directly contrast the full DARE framework against simple difficulty-based filtering baselines. These additions will be placed in the main text rather than the appendix. revision: yes
Circularity Check
No significant circularity in DARE derivation
full rationale
The paper identifies three limitations of prior difficulty-aware RL methods and proposes DARE as a unified framework combining co-evolution of difficulty estimates with the policy via self-normalized importance sampling (a standard technique), symmetric Beta sampling for coverage, and tier-specific training with adaptive compute. These components are presented as independent mechanisms whose value is demonstrated through experiments on multiple models and domains rather than any reduction to fitted parameters, self-definitions, or self-citation chains. No equations or claims in the provided text equate predictions or results to inputs by construction, and the approach remains externally falsifiable via empirical outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of reinforcement learning (Markov decision process, reward signals from correctness)
Reference graph
Works this paper leans on
-
[1]
AI-MO. AI-MO validation AIME dataset. Hugging Face Datasets, 2024. URL https: //huggingface.co/datasets/AI-MO/aimo-validation-aime
work page 2024
-
[2]
AI-MO. AI-MO validation AMC dataset. Hugging Face Datasets, 2024. URL https: //huggingface.co/datasets/AI-MO/aimo-validation-amc
work page 2024
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021. URL https://arxiv. org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Online difficulty filtering for reasoning oriented reinforcement learning
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, JeongYeon Nam, and Donghyun Kwak. Online difficulty filtering for reasoning oriented reinforcement learning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2026. URLhttps://arxiv.org/abs/2504.03380
-
[5]
SmolLM3: Smol, multilingual, long-context reasoner
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Car- los Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gal- louédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, and Thomas Wolf. SmolLM3: Smol, multilingual, long-context reasoner. Hugging Face Blog, 2025. URL https://huggingface. co/blog/smollm3
work page 2025
-
[6]
The role of deductive and inductive reasoning in large language models
Chengkun Cai, Xu Zhao, Haoliang Liu, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, Jenq- Neng Hwang, and Lei Li. The role of deductive and inductive reasoning in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16780–16790, 2025
work page 2025
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021. URL https: //arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Self-evolving curriculum for LLM reasoning.arXiv preprint arXiv:2505.14970, 2025
Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan Kamalloo. Self-evolving curriculum for LLM reasoning. arXiv preprint arXiv:2505.14970, 2025. URLhttps://arxiv.org/abs/2505.14970
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Huilin Deng, Ding Zou, Rui Ma, Hongchen Luo, Yang Cao, and Yu Kang. Boosting the generalization and reasoning of vision language models with curriculum reinforcement learning. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025. URL https://arxiv.org/abs/2503.07065
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Associa- tion for Compu...
work page 2024
-
[13]
arXiv preprint arXiv:2504.11456 , year=
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. DeepMath-103K: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025. 11
-
[14]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InAdvances in Neural Information Processing Systems (Datasets and Benchmarks Track), 2021. URLhttps://arxiv.org/abs/2105.09938
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. Advances in Neural Information Processing Systems (Datasets and Benchmarks Track), 2021. URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Open-Reasoner-Zero: An Open Source Approach to Scaling up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-Reasoner-Zero: An Open Source Approach to Scaling up Reinforcement Learning on the Base Model. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[17]
Zengjie Hu, Jiantao Qiu, Tianyi Bai, Haojin Yang, Binhang Yuan, Qi Jing, Conghui He, and Wentao Zhang. V ADE: Variance-aware dynamic sampling via online sample-level difficulty estimation for multimodal RL.arXiv preprint arXiv:2511.18902, 2025. URL https://arxiv. org/abs/2511.18902
-
[18]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Ji- ajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xu- ancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-Coder technical report.arXiv preprint arXiv:2409.12186, 2024. URLhttps://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida I. Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination-free evaluation of large language models for code. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Can Jin, Yang Zhou, Qixin Zhang, Hongwu Peng, Di Zhang, Zihan Dong, Marco Pavone, Ligong Han, Zhang-Wei Hong, Tong Che, et al. Your reward function for rl is your best prm for search: Unifying rl and search-based tts.arXiv preprint arXiv:2508.14313, 2025
-
[21]
Can Jin, Rui Wu, Tong Che, Qixin Zhang, Hongwu Peng, Jiahui Zhao, Zhenting Wang, Wenqi Wei, Ligong Han, Zhao Zhang, et al. Reasoning over precedents alongside statutes: Case- augmented deliberative alignment for llm safety.arXiv preprint arXiv:2601.08000, 2026
-
[22]
Revisiting generalization across difficulty levels: It’s not so easy
Yeganeh Kordi, Nihal V Nayak, Max Zuo, Ilana Nguyen, and Stephen Bach. Revisiting generalization across difficulty levels: It’s not so easy. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7014–7042, 2026
work page 2026
-
[23]
Probing the difficulty perception mechanism of large language models
Sunbowen Lee, Qingyu Yin, Chak Tou Leong, Jialiang Zhang, Yicheng Gong, Shiwen Ni, Min Yang, and Xiaoyu Shen. Probing the difficulty perception mechanism of large language models. arXiv preprint arXiv:2510.05969, 2025. URLhttps://arxiv.org/abs/2510.05969
-
[24]
Writing-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning
Xuanyu Lei, Chenliang Li, Yuning Wu, Kaiming Liu, Weizhou Shen, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. Writing-RL: Advancing long-form writing via adaptive curriculum reinforcement learning.arXiv preprint arXiv:2506.05760, 2025. URL https: //arxiv.org/abs/2506.05760
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
work page 2022
- [27]
-
[28]
Xuefeng Li, Haoyang Zou, and Pengfei Liu. LIMR: Less is more for RL scaling.arXiv preprint arXiv:2502.11886, 2025. URLhttps://arxiv.org/abs/2502.11886. 12
-
[29]
Knapsack RL: Unlocking exploration of LLMs via optimizing budget allocation
Ziniu Li, Congliang Chen, Tianyun Yang, Tian Ding, Ruoyu Sun, Ge Zhang, Wenhao Huang, and Zhi-Quan Luo. Knapsack RL: Unlocking exploration of LLMs via optimizing budget allocation. arXiv preprint arXiv:2509.25849, 2025. URLhttps://arxiv.org/abs/2509.25849
-
[30]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[31]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. In Advances in Neural Information Processing Systems, 2023. URL https://arxiv.org/abs/ 2305.01210
work page internal anchor Pith review arXiv 2023
-
[32]
Leveraging explanation to improve generalization of meta rein- forcement learning
Shicheng Liu and Minghui Zhu. Leveraging explanation to improve generalization of meta rein- forcement learning. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[33]
Shicheng Liu, Siyuan Xu, Wenjie Qiu, Hangfan Zhang, and Minghui Zhu. Explainable reinforce- ment learning from human feedback to improve alignment.Advances in Neural Information Processing Systems, 38:138261–138291, 2026
work page 2026
-
[34]
DiffAdapt: Difficulty-Adaptive Reasoning for Token-Efficient LLM Inference
Xiang Liu, Xuming Hu, Xiaowen Chu, and Eunsol Choi. DiffAdapt: Difficulty-adaptive reasoning for token-efficient LLM inference. InProceedings of the Fourteenth International Conference on Learning Representations (ICLR), 2026. URL https://arxiv.org/abs/ 2510.19669
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 3(5), 2025
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 3(5), 2025
work page 2025
-
[36]
Mathematical Association of America. AIME 2024 and 2025 problems. Amer- ican Invitational Mathematics Examination, 2025. URL https://maa.org/ maa-invitational-competitions/
work page 2024
-
[37]
Jing-Cheng Pang, Liu Sun, Chang Zhou, Xian Tang, Haichuan Ma, Kun Jiang, Jianlong Wang, Kai Zhang, Sijie Wu, Haoran Cai, Chenwei Wu, Xubin Li, and Xin Chen. EDCO: Dynamic curriculum orchestration for domain-specific large language model fine-tuning.arXiv preprint arXiv:2601.03725, 2026. URLhttps://arxiv.org/abs/2601.03725
-
[38]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang
Shubham Parashar, Shurui Gui, Xiner Li, Hongyi Ling, Sushil Vemuri, Blake Olson, Eric Li, Yu Zhang, James Caverlee, Dileep Kalathil, and Shuiwang Ji. Curriculum reinforcement learning from easy to hard tasks improves LLM reasoning. InProceedings of the Fourteenth International Conference on Learning Representations (ICLR), 2026. URL https://arxiv. org/abs...
-
[39]
Yun Qu, Qi Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, and Xiangyang Ji. Can prompt difficulty be online predicted for accelerating RL finetuning of reasoning models? In Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2026. URLhttps://arxiv.org/abs/2507.04632
-
[40]
David Rein, Betty Li, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023. URLhttps://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
BOTS: A unified framework for Bayesian online task selection in LLM reinforcement finetuning
Qianli Shen, Daoyuan Chen, Yilun Huang, Zhenqing Ling, Yaliang Li, Bolin Ding, and Jingren Zhou. BOTS: A unified framework for Bayesian online task selection in LLM reinforcement finetuning. InProceedings of the Fourteenth International Conference on Learning Representa- tions (ICLR), 2026. URLhttps://arxiv.org/abs/2510.26374
-
[44]
Intrinsic entropy of context length scaling in llms
Jingzhe Shi, Qinwei Ma, Hongyi Liu, Hang Zhao, Jenq-Neng Hwang, and Lei Li. Intrinsic entropy of context length scaling in llms. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[45]
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning.ArXiv, abs/2504.05520, 2025
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. Efficient reinforcement finetuning via adaptive curriculum learning.arXiv preprint arXiv:2504.05520, 2025. URL https://arxiv.org/abs/2504.05520
-
[46]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for LLM reinforcement fine-tuning through difficulty- targeted online data selection and rollout replay. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2506.05316
-
[47]
HM Tabib and Jaber Ahmed Deedar. Toward trustworthy difficulty assessments: Large language models as judges in programming and synthetic tasks.arXiv preprint arXiv:2511.18597, 2025
-
[48]
Towards high data efficiency in reinforcement learning with verifiable reward
Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Towards high data efficiency in reinforcement learning with verifiable reward. In Proceedings of the Fourteenth International Conference on Learning Representations (ICLR),
- [49]
-
[50]
Light-R1: Curriculum SFT, DPO and RL for long COT from scratch and beyond
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-R1: Curriculum SFT, DPO and RL for long COT from scratch and beyond. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL): Industry T...
-
[51]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Zhe Yang, Yichang Zhang, Tianyu Liu, Jian Yang, Junyang Lin, Chang Zhou, and Zhifang Sui. Can large language models always solve easy problems if they can solve harder ones? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1531–1555, 2024
work page 2024
-
[53]
arXiv preprint arXiv:2502.03387 , year=
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. LIMO: Less is more for reasoning. InConference on Language Modeling (COLM), 2025. URL https: //arxiv.org/abs/2502.03387
-
[54]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Mitigating forgetting between supervised and reinforcement learning yields stronger reasoners
Xiangchi Yuan, Xiang Chen, Tong Yu, Dachuan Shi, Can Jin, Wenke Lee, and Saayan Mitra. Mitigating forgetting between supervised and reinforcement learning yields stronger reasoners. arXiv preprint arXiv:2510.04454, 2025
-
[56]
arXiv preprint arXiv:2601.13572 , year=
Xiangchi Yuan, Dachuan Shi, Chunhui Zhang, Zheyuan Liu, Shenglong Yao, Soroush V osoughi, and Wenke Lee. Behavior knowledge merge in reinforced agentic models.arXiv preprint arXiv:2601.13572, 2026
-
[57]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
CurES: From gradient analysis to efficient curriculum learning for reasoning LLMs
Yongcheng Zeng, Zexu Sun, Bokai Ji, Erxue Min, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Haifeng Zhang, Xu Chen, and Jun Wang. CurES: From gradient analysis to efficient curriculum learning for reasoning LLMs. InProceedings of the Fourteenth International Conference on Learning Representations (ICLR), 2026. URLhttps://arxiv.org/abs/2510.01037
-
[59]
Ruiqi Zhang, Daman Arora, Song Mei, and Andrea Zanette. SPEED-RL: Faster training of reasoning models via online curriculum learning. InICML 2025 Workshop on AI for Math (AI4Math@ICML25), 2025. URLhttps://arxiv.org/abs/2506.09016
-
[60]
UFO-RL: Uncertainty-focused optimization for efficient reinforcement learning data selection
Yang Zhao, Kai Xiong, Xiao Ding, Li Du, Yangou Ouyang, Zhouhao Sun, Jiannan Guan, Wenbin Zhang, Bin Liu, Dong Hu, Bing Qin, and Ting Liu. UFO-RL: Uncertainty-focused optimization for efficient reinforcement learning data selection. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2505.12457
-
[61]
Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen
Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for LLM reasoning via selective rollouts. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2506.02177
-
[62]
Yang Zhou, Mingyu Zhao, Zhenting Wang, Difei Gu, Bangwei Guo, Ruosong Ye, Ligong Han, Can Jin, and Dimitris N Metaxas. Mˆ 3-bench: Multi-modal, multi-hop, multi-threaded tool-using mllm agent benchmark.arXiv preprint arXiv:2511.17729, 2025
-
[63]
Yang Zhou, Shiyu Zhao, Yuxiao Chen, Zhenting Wang, Can Jin, and Dimitris N Metaxas. Led: Llm enhanced open-vocabulary object detection without human curated data generation.arXiv preprint arXiv:2503.13794, 2025
-
[64]
The LLM already knows: Estimating LLM-perceived question difficulty via hidden representations
Yubo Zhu, Dongrui Liu, Zecheng Lin, Wei Tong, Sheng Zhong, and Jing Shao. The LLM already knows: Estimating LLM-perceived question difficulty via hidden representations. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1160–1176, 2025. doi: 10.18653/v1/2025.emnlp-main.61. URL https: //arxiv.org/abs/2...
-
[65]
[Top-scoring fragment 1]
-
[66]
[Top-scoring fragment 2]
-
[67]
[Top-scoring fragment 3] 19 Algorithm 1DARE: Difficulty-Adaptive Reinforcement Learning with Co-Evolved Difficulty Esti- mation Require: Training set D, reference set Dref, initial policy πθ, replay buffer B ← ∅ , Beta concen- tration κ, thresholds deasy, dhard, rollout counts G, Geasy, Ghard, replay mix ratio σ, clipping boundc 1:/* Cold-start: initializ...
-
[68]
The solution is correct. We can also verify with code:(3**1)**6 == 3**6 returns True.1 Short rollout (219 tokens,✓): Using the power rule (am)n =a mn: (3k)6 = 3 6k. So 36k = 3 6 ⇒6k= 6⇒k= 1 . Substituting back:(3 1)6 = 3 6 =⇒3 6 = 3 6.1 Level 5 (Hard)Short wrong vs. long correct rollout Problem:There are 360 people in a school. 15 take calculus, physics, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.