Recognition: 2 theorem links
· Lean TheoremSelect-then-differentiate: Solving Bilevel Optimization with Manifold Lower-level Solution Sets
Pith reviewed 2026-05-12 02:59 UTC · model grok-4.3
The pith
Uniqueness of the optimistic selection suffices for differentiability of the hyper-objective in bilevel optimization with manifold lower-level solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a local Polyak-Łojasiewicz condition, the hyper-objective in optimistic bilevel optimization is differentiable whenever the optimistic selection from the lower-level solution manifold is unique. This yields an explicit pseudoinverse-based hyper-gradient formula. Non-degeneracy of the selected minimizer ensures local smoothness, while non-uniqueness can introduce non-differentiable points and non-degeneracy can eliminate Hölder regularity.
What carries the argument
The unique optimistic selection from the manifold of lower-level minimizers, which permits computation of the hyper-gradient via the pseudoinverse of the Jacobian of the selected point's stationarity conditions.
If this is right
- The hyper-objective is locally smooth if the selected minimizer is non-degenerate.
- Non-uniqueness of the optimistic selection creates multiple points where the hyper-objective is non-differentiable.
- Failure of non-degeneracy destroys all positive Hölder regularity of the hyper-gradient.
- HG-MS converges to a stationary point of the optimistic objective with iteration complexity governed by the intrinsic dimension of the solution manifold.
Where Pith is reading between the lines
- This framework could apply to bilevel problems in machine learning involving symmetries or multiple equivalent solutions at the lower level.
- Numerical verification of the hyper-gradient formula on low-dimensional manifold examples would provide a direct test.
- The select-then-differentiate idea might combine with manifold optimization algorithms for further speedups in high-dimensional settings.
- In the LLM reweighting application, it suggests robustness to cases where source models have equivalent performance optima.
Load-bearing premise
The lower-level objective satisfies a local Polyak-Łojasiewicz condition and admits a unique non-degenerate optimistic selection from its manifold of minimizers.
What would settle it
A concrete counterexample lower-level function with a line of minimizers where two points tie for the optimistic upper-level value, showing the hyper-objective has a kink or non-differentiable point at the corresponding upper-level input.
Figures


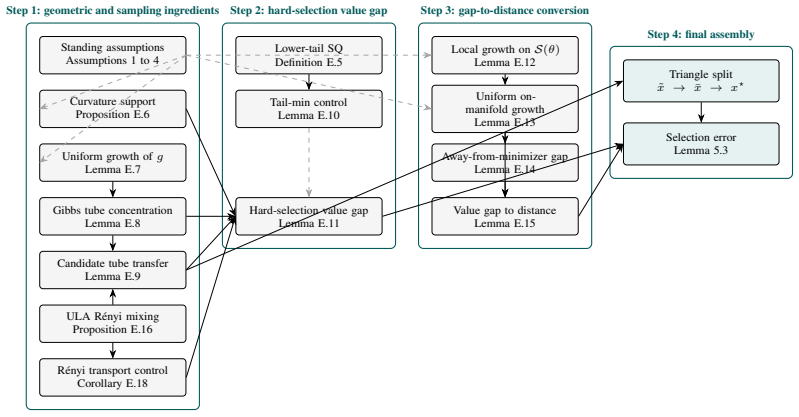
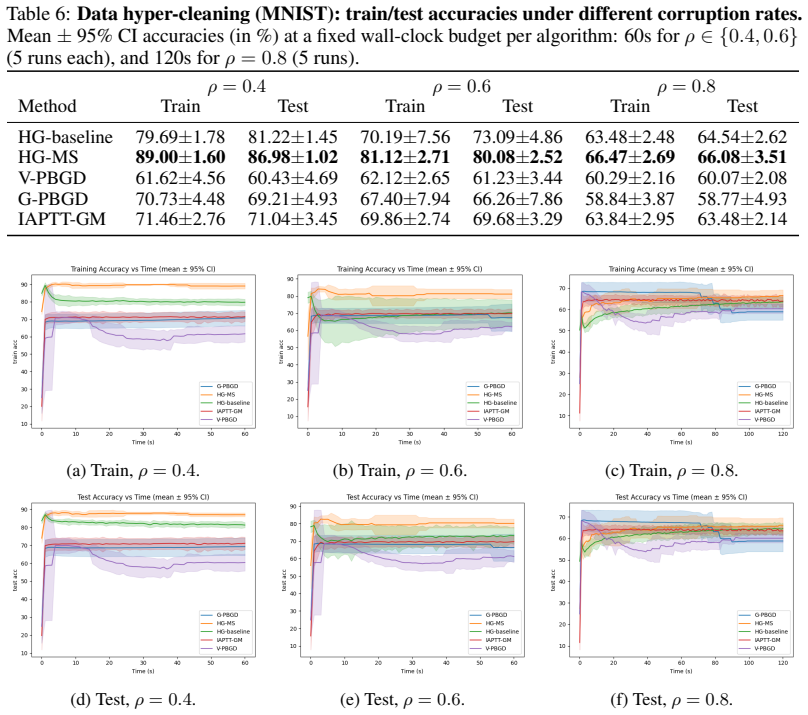

read the original abstract
We study optimistic bilevel optimization when the lower-level problem has a non-isolated manifold of minimizers. In this setting, the hyper-objective may be non-differentiable because the upper-level criterion must choose among multiple lower-level solutions. Under a local Polyak--{\L}ojasiewicz (P{\L}) condition, we show that differentiability does not require the lower-level solution set to be a singleton: uniqueness of the optimistic selection is sufficient. This yields an explicit pseudoinverse-based hyper-gradient formula extending the classical singleton-minimizer result. We further characterize the regularity of the hyper-objective: non-degeneracy of the selected minimizer along the solution manifold yields local smoothness, while failure of uniqueness can create many non-differentiable points and failure of non-degeneracy can destroy all positive H\"older regularity of the hyper-gradient. Motivated by this theory, we propose HG-MS, a select-then-differentiate method combining explicit optimistic selection with efficient pseudoinverse-based hyper-gradient computation. Despite the nonconvex nature of optimistic selection over the lower-level solution manifold, we show that HG-MS converges to a stationary point of the optimistic objective with complexity governed by the intrinsic dimension of the solution manifold rather than its ambient dimension. Empirically, we test a practical variant of HG-MS for matched-budget LLM source reweighting. This variant preserves the select-then-differentiate principle and obtains the best GSM8K/MATH scores across the tested backbones, along with competitive or best MT-Bench instruction-following results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies optimistic bilevel optimization when the lower-level problem has a non-isolated manifold of minimizers. Under a local Polyak-Łojasiewicz condition, it shows that differentiability of the hyper-objective requires only uniqueness of the optimistic selection (rather than a singleton lower-level solution set) and derives an explicit pseudoinverse-based hyper-gradient formula. It further characterizes regularity: non-degeneracy of the selected point yields local smoothness while degeneracy can destroy Hölder regularity. The paper proposes the HG-MS algorithm (select-then-differentiate with pseudoinverse gradients), proves convergence to a stationary point of the optimistic objective with complexity scaling in the intrinsic dimension of the manifold, and reports empirical results on a practical variant for matched-budget LLM source reweighting.
Significance. If the central claims hold, the work meaningfully extends differentiable bilevel optimization to manifold-valued lower-level solution sets, a setting that arises in many applications. The explicit pseudoinverse formula and the intrinsic-dimension complexity bound are concrete technical advances over classical singleton results. The empirical demonstration on LLM reweighting provides evidence of practical utility. The combination of local PL analysis, selection uniqueness, and manifold-aware convergence is a clear strength.
minor comments (3)
- The statement of the local PL condition and the precise definition of the optimistic selection operator should be cross-referenced to the main theorem on differentiability (likely around the hyper-gradient formula) to make the logical dependence explicit.
- In the empirical section on LLM source reweighting, the description of the practical HG-MS variant would benefit from a short paragraph clarifying how the manifold selection step is approximated under the matched-budget constraint, including any discretization or sampling used.
- A few sentences comparing the derived pseudoinverse formula to existing implicit-differentiation approaches for non-unique lower-level problems would help situate the contribution for readers.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. The report highlights the key contributions on pseudoinverse hyper-gradients under manifold lower-level solutions and the intrinsic-dimension complexity of HG-MS, which aligns with our intent. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper derives differentiability of the hyper-objective from the local PL condition plus uniqueness of the optimistic selection, yielding a pseudoinverse hyper-gradient that reduces to the classical singleton case by standard sensitivity analysis on the tangent space. Convergence of HG-MS follows directly from manifold geometry and intrinsic dimension after selection, with no reduction of any claim to a fitted parameter, self-definition, or load-bearing self-citation. All steps are self-contained against implicit-function and manifold sensitivity results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local Polyak-Łojasiewicz (PL) condition on the lower-level problem
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearUnder a local Polyak–Łojasiewicz (PŁ) condition, we show that differentiability does not require the lower-level solution set to be a singleton: uniqueness of the optimistic selection is sufficient. This yields an explicit pseudoinverse-based hyper-gradient formula
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearS(θ) is a connected compact C² embedded submanifold of R^d without boundary
Reference graph
Works this paper leans on
-
[1]
Criscitiello, Chris and Rebjock, Quentin and Boumal, Nicolas , title =
-
[2]
Foundations of Computational Mathematics , pages=
Analysis of langevin monte carlo from poincare to log-sobolev , author=. Foundations of Computational Mathematics , pages=. 2024 , publisher=
work page 2024
-
[3]
arXiv preprint arXiv:2409.10323 , year=
On the Hardness of Meaningful Local Guarantees in Nonsmooth Nonconvex Optimization , author=. arXiv preprint arXiv:2409.10323 , year=
-
[4]
The Thirty Sixth Annual Conference on Learning Theory , pages=
Deterministic nonsmooth nonconvex optimization , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
work page 2023
-
[5]
International Conference on Machine Learning , pages=
On the finite-time complexity and practical computation of approximate stationarity concepts of lipschitz functions , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[6]
Advances in Neural Information Processing Systems , volume=
Oracle complexity in nonsmooth nonconvex optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Machine Learning , pages=
Complexity of finding stationary points of nonconvex nonsmooth functions , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[8]
arXiv preprint arXiv:1611.01540 , year=
Topology and geometry of half-rectified network optimization , author=. arXiv preprint arXiv:1611.01540 , year=
-
[9]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Empirical analysis of the hessian of over-parametrized neural networks , author=. arXiv preprint arXiv:1706.04454 , year=
-
[10]
arXiv preprint arXiv:1802.06384 , year=
Spurious valleys in two-layer neural network optimization landscapes , author=. arXiv preprint arXiv:1802.06384 , year=
-
[11]
International Conference on Machine Learning , pages=
Understanding the loss surface of neural networks for binary classification , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[12]
Advances in neural information processing systems , volume=
Loss surfaces, mode connectivity, and fast ensembling of dnns , author=. Advances in neural information processing systems , volume=
-
[13]
International conference on machine learning , pages=
On connected sublevel sets in deep learning , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[14]
Advances in neural information processing systems , volume=
Explaining landscape connectivity of low-cost solutions for multilayer nets , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:2404.06391 , year=
Exploring Neural Network Landscapes: Star-Shaped and Geodesic Connectivity , author=. arXiv preprint arXiv:2404.06391 , year=
-
[16]
Advances in neural information processing systems , volume=
On the local minima of the empirical risk , author=. Advances in neural information processing systems , volume=
-
[17]
arXiv preprint arXiv:2501.00429 , year=
Poincare Inequality for Local Log-Polyak-Lojasiewicz Measures: Non-asymptotic Analysis in Low-temperature Regime , author=. arXiv preprint arXiv:2501.00429 , year=
- [18]
-
[19]
Mathematical programming , volume=
Smooth minimization of non-smooth functions , author=. Mathematical programming , volume=. 2005 , publisher=
work page 2005
-
[20]
SIAM Journal on Optimization , volume=
Smoothing and first order methods: A unified framework , author=. SIAM Journal on Optimization , volume=. 2012 , publisher=
work page 2012
-
[21]
Mathematical Programming , volume=
Cubic regularization of Newton method and its global performance , author=. Mathematical Programming , volume=. 2006 , publisher=
work page 2006
-
[22]
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
work page 2019
-
[23]
arXiv preprint arXiv:1501.01571 , year=
An introduction to matrix concentration inequalities , author=. arXiv preprint arXiv:1501.01571 , year=
-
[24]
Statistics & probability letters , volume=
On the best constant in Marcinkiewicz--Zygmund inequality , author=. Statistics & probability letters , volume=. 2001 , publisher=
work page 2001
-
[25]
arXiv preprint arXiv:2107.11433 , year=
A general sample complexity analysis of vanilla policy gradient , author=. arXiv preprint arXiv:2107.11433 , year=
-
[26]
Reinforcement learning: An introduction , author=. 2018 , publisher=
work page 2018
-
[27]
SIAM Journal on Control and Optimization , volume=
Global convergence of policy gradient methods to (almost) locally optimal policies , author=. SIAM Journal on Control and Optimization , volume=. 2020 , publisher=
work page 2020
-
[28]
International conference on machine learning , pages=
Hessian aided policy gradient , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[29]
arXiv preprint arXiv:2012.01491 , year=
Sample complexity of policy gradient finding second-order stationary points , author=. arXiv preprint arXiv:2012.01491 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
An improved analysis of (variance-reduced) policy gradient and natural policy gradient methods , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2110.10116 , year=
On the Global Convergence of Momentum-based Policy Gradient , author=. arXiv preprint arXiv:2110.10116 , year=
-
[32]
Journal of Machine Learning Research , volume=
On the theory of policy gradient methods: Optimality, approximation, and distribution shift , author=. Journal of Machine Learning Research , volume=. 2021 , publisher=
work page 2021
-
[33]
arXiv preprint arXiv:2106.04096 , year=
Linear convergence of entropy-regularized natural policy gradient with linear function approximation , author=. arXiv preprint arXiv:2106.04096 , year=
-
[34]
Neural policy gradient methods: Global optimality and rates of convergence , author=. arXiv preprint arXiv:1909.01150 , year=
-
[35]
Approximately optimal approximate reinforcement learning , author=. In Proc. 19th International Conference on Machine Learning , year=
-
[36]
Zhurnal Vychislitel'noi Matematiki i Matematicheskoi Fiziki , volume=
Gradient methods for minimizing functionals , author=. Zhurnal Vychislitel'noi Matematiki i Matematicheskoi Fiziki , volume=. 1963 , publisher=
work page 1963
-
[37]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
work page 2016
-
[38]
Advances in neural information processing systems , volume=
Convergence analysis of two-layer neural networks with relu activation , author=. Advances in neural information processing systems , volume=
-
[39]
arXiv preprint arXiv:1609.05191 , year=
Gradient descent learns linear dynamical systems , author=. arXiv preprint arXiv:1609.05191 , year=
-
[40]
IEEE Transactions on information Theory , volume=
Median-truncated nonconvex approach for phase retrieval with outliers , author=. IEEE Transactions on information Theory , volume=. 2018 , publisher=
work page 2018
-
[41]
Identity matters in deep learning
Identity matters in deep learning , author=. arXiv preprint arXiv:1611.04231 , year=
-
[42]
Applied and computational harmonic analysis , volume=
Rapid, robust, and reliable blind deconvolution via nonconvex optimization , author=. Applied and computational harmonic analysis , volume=. 2019 , publisher=
work page 2019
-
[43]
Advances in Neural Information Processing Systems , volume=
Uniform convergence of gradients for non-convex learning and optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:1612.00547 , year=
Gradient descent efficiently finds the cubic-regularized non-convex Newton step , author=. arXiv preprint arXiv:1612.00547 , year=
-
[45]
Advances in neural information processing systems , volume=
Stochastic cubic regularization for fast nonconvex optimization , author=. Advances in neural information processing systems , volume=
-
[46]
The Annals of Probability , volume=
Matrix concentration inequalities via the method of exchangeable pairs , author=. The Annals of Probability , volume=. 2014 , publisher=
work page 2014
-
[47]
Better theory for SGD in the nonconvex world , author=. arXiv preprint arXiv:2002.03329 , year=
-
[48]
Fast exact multiplication by the Hessian , author=. Neural computation , volume=. 1994 , publisher=
work page 1994
- [49]
-
[50]
The 22nd International Conference on Artificial Intelligence and Statistics , pages=
Stochastic variance-reduced cubic regularization for nonconvex optimization , author=. The 22nd International Conference on Artificial Intelligence and Statistics , pages=. 2019 , organization=
work page 2019
-
[51]
Conference on Learning Theory , pages=
Convergence rates and approximation results for SGD and its continuous-time counterpart , author=. Conference on Learning Theory , pages=. 2021 , organization=
work page 2021
-
[52]
Advances in Neural Information Processing Systems , volume=
Convergence of cubic regularization for nonconvex optimization under KL property , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
Tight dimension independent lower bound on the expected convergence rate for diminishing step sizes in SGD , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
arXiv preprint arXiv:1611.01146 , year=
Finding approximate local minima for nonconvex optimization in linear time , author=. arXiv preprint arXiv:1611.01146 , year=
-
[55]
Mathematical Programming , volume=
A linear-time algorithm for trust region problems , author=. Mathematical Programming , volume=. 2016 , publisher=
work page 2016
-
[56]
arXiv preprint arXiv:1710.05782 , year=
Second-order methods with cubic regularization under inexact information , author=. arXiv preprint arXiv:1710.05782 , year=
-
[57]
Part I: motivation, convergence and numerical results , author=
Adaptive cubic regularisation methods for unconstrained optimization. Part I: motivation, convergence and numerical results , author=. Mathematical Programming , volume=. 2011 , publisher=
work page 2011
-
[58]
arXiv preprint arXiv:1710.04788 , year=
A unified scheme to accelerate adaptive cubic regularization and gradient methods for convex optimization , author=. arXiv preprint arXiv:1710.04788 , year=
-
[59]
International Conference on Machine Learning , pages=
Sub-sampled cubic regularization for non-convex optimization , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[60]
Proceedings of the 2020 SIAM International Conference on Data Mining , pages=
Second-order optimization for non-convex machine learning: An empirical study , author=. Proceedings of the 2020 SIAM International Conference on Data Mining , pages=. 2020 , organization=
work page 2020
-
[61]
Advances in Neural Information Processing Systems , volume=
Variational policy gradient method for reinforcement learning with general utilities , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Advances in Neural Information Processing Systems , volume=
On the convergence and sample efficiency of variance-reduced policy gradient method , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
International Conference on Machine Learning , pages=
Global convergence of policy gradient methods for the linear quadratic regulator , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[64]
International Conference on Machine Learning , pages=
On the global convergence rates of softmax policy gradient methods , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[65]
Introductory lectures on convex optimization: A basic course , author=. 2003 , publisher=
work page 2003
-
[66]
International Conference on Machine Learning , pages=
An asynchronous parallel stochastic coordinate descent algorithm , author=. International Conference on Machine Learning , pages=. 2014 , organization=
work page 2014
-
[67]
Mathematical Programming , volume=
Linear convergence of first order methods for non-strongly convex optimization , author=. Mathematical Programming , volume=. 2019 , publisher=
work page 2019
-
[68]
Journal of the Operations Research Society of China , volume=
On the linear convergence of a proximal gradient method for a class of nonsmooth convex minimization problems , author=. Journal of the Operations Research Society of China , volume=. 2013 , publisher=
work page 2013
-
[69]
Foundations of Computational Mathematics , volume=
A geometric analysis of phase retrieval , author=. Foundations of Computational Mathematics , volume=. 2018 , publisher=
work page 2018
-
[70]
INFORMS Journal on Optimization , volume=
Adaptive stochastic variance reduction for subsampled Newton method with cubic regularization , author=. INFORMS Journal on Optimization , volume=. 2022 , publisher=
work page 2022
-
[71]
International Conference on Machine Learning , pages=
Stochastic variance-reduced cubic regularized Newton methods , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[72]
Conference on Learning Theory , pages=
Second-order information in non-convex stochastic optimization: Power and limitations , author=. Conference on Learning Theory , pages=. 2020 , organization=
work page 2020
-
[73]
arXiv preprint arXiv:1902.02388 , year=
Inexact proximal cubic regularized newton methods for convex optimization , author=. arXiv preprint arXiv:1902.02388 , year=
-
[74]
GitHub repository , howpublished =
Zuo, Xingdong , title =. GitHub repository , howpublished =. 2018 , publisher =
work page 2018
-
[75]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
Mujoco: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
work page 2012
-
[76]
International Conference on Machine Learning , pages=
Momentum-based policy gradient methods , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[77]
Advances in neural information processing systems , volume=
Momentum-Based Variance Reduction in Non-Convex SGD , author=. Advances in neural information processing systems , volume=
-
[78]
International Conference on Artificial Intelligence and Statistics , pages=
Stochastic recursive variance-reduced cubic regularization methods , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
work page 2020
-
[79]
The Masked Sample Covariance Estimator: An Analysis via Matrix Concentration Inequalities. arXiv e-print , author=. arXiv preprint arXiv:1109.1637 , year=
-
[80]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.