Recognition: 2 theorem links
· Lean TheoremKinetic theory for Transformers and the lost-in-the-middle phenomenon
Pith reviewed 2026-05-12 02:32 UTC · model grok-4.3
The pith
Causal self-attention dynamics produce a U-shaped retrieval profile that explains lost-in-the-middle for uniform tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
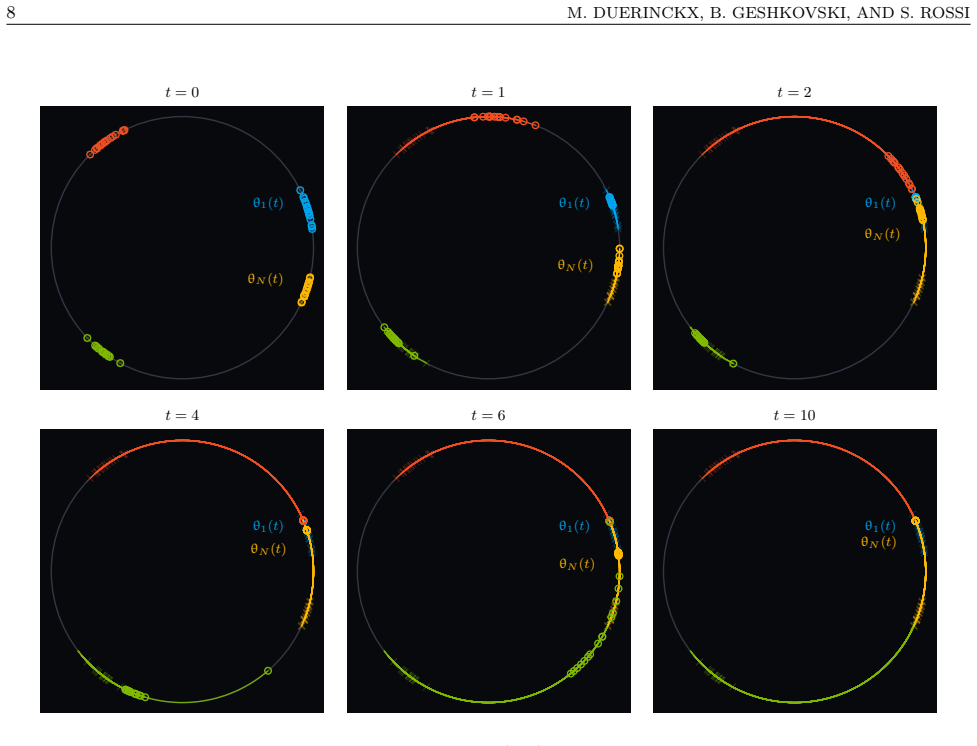
By viewing causal self-attention as a non-exchangeable particle system and performing a quantitative mean-field limit, the authors obtain a closed-form expression for the limiting pairwise correlations when tokens are iid uniform. These correlations determine the token retrieval profile, which is provably U-shaped with primacy and recency effects and a unique interior minimum under an explicit smallness condition on the model parameters.
What carries the argument
The limiting correlation equation obtained from the mean-field limit of the causal self-attention particle system, solved in closed form for iid uniform tokens.
If this is right
- Retrieval probability is strictly higher for tokens near the beginning or end of the prompt than for those in the middle.
- The interior minimum is unique once the smallness condition on parameters is met.
- The U-shaped profile arises directly from the triangular causal dependency structure of the attention mechanism.
- Quantitative bounds control the distance between the finite-particle system and its mean-field limit.
Where Pith is reading between the lines
- Architectural changes that reduce the effective interaction strength might flatten the U and improve middle-context recall.
- The same mean-field analysis could be applied to non-uniform token distributions to predict how vocabulary statistics affect the lost-in-the-middle effect.
- The kinetic-theory perspective suggests analogous limits for other attention variants or for encoder-decoder models with different dependency graphs.
- Empirical checks of the smallness condition on real trained models could indicate whether the derived regime is the one governing practical lost-in-the-middle failures.
Load-bearing premise
Input tokens are independent and identically distributed uniformly, together with a smallness condition on the interaction strength that permits the closed-form solution.
What would settle it
A direct numerical computation of attention weights on long sequences of iid uniform tokens that yields a retrieval profile without a unique interior minimum, or without the predicted U-shape, would contradict the closed-form result.
Figures


read the original abstract
We study causal self-attention dynamics -- a toy model for decoder Transformers -- which we interpret as a non-exchangeable interacting particle system. Adapting cumulant expansions to the triangular causal dependency structure of the model, and appealing to non-hierarchical methods to estimate correlations using Glauber calculus, we prove a quantitative mean-field limit result and a next-order characterization of correlations. For iid uniformly distributed tokens, the limiting correlation equation can be solved in closed form and we obtain a rigorous explanation of the empirically observed \emph{lost-in-the-middle} phenomenon: the token retrieval profile, as a function of the source position in the prompt, is $\mathsf{U}$-shaped, with primacy, recency, and a unique interior minimum under an explicit smallness condition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript models causal self-attention in decoder Transformers as a non-exchangeable interacting particle system. By adapting cumulant expansions to the triangular causal structure and using Glauber calculus for non-hierarchical correlation estimates, it proves a quantitative mean-field limit together with a next-order characterization. For iid uniformly distributed tokens the limiting correlation equation is solved in closed form, yielding a U-shaped token retrieval profile (primacy, recency, unique interior minimum) that explains the lost-in-the-middle phenomenon under an explicit smallness condition.
Significance. If the mean-field limit and closed-form solution hold, the work supplies a rigorous, essentially parameter-free mathematical account of an empirically important Transformer behavior using tools from kinetic theory. The adaptation of cumulant methods to causal triangular structures is technically novel and the closed-form derivation strengthens explanatory power; these features could seed further PDE-based analysis of attention dynamics.
major comments (2)
- [Abstract] Abstract and statement of the main quantitative limit: the smallness condition is load-bearing both for closed-form solvability of the limiting correlation equation and for the validity of the mean-field approximation via cumulant expansions; the manuscript provides no explicit scaling of this condition with sequence length N, leaving open whether the U-shaped profile remains valid at the moderate prompt lengths (N ~ 10^2–10^3) where lost-in-the-middle is routinely observed.
- [Limiting correlation equation] Derivation of the limiting correlation equation (via adapted cumulant expansions): the quantitative error bounds rely on the smallness assumption being satisfied; the paper should supply a concrete test or counter-example showing whether the U-shape persists when the smallness parameter is only marginally satisfied, as this directly affects the claimed rigorous explanation.
minor comments (2)
- [Introduction] Notation for the non-exchangeable particle system and the causal triangular structure could be introduced more explicitly in the introduction to aid readers outside kinetic theory.
- [Discussion] A short discussion of how the iid-uniform assumption might be relaxed while retaining the qualitative U-shape would strengthen the link to practical Transformers.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We appreciate the positive assessment of the work's significance and novelty in adapting kinetic theory tools to causal self-attention. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and statement of the main quantitative limit: the smallness condition is load-bearing both for closed-form solvability of the limiting correlation equation and for the validity of the mean-field approximation via cumulant expansions; the manuscript provides no explicit scaling of this condition with sequence length N, leaving open whether the U-shaped profile remains valid at the moderate prompt lengths (N ~ 10^2–10^3) where lost-in-the-middle is routinely observed.
Authors: We thank the referee for pointing out this aspect. The smallness condition is independent of the sequence length N, as it ensures the convergence of the cumulant expansion in the mean-field limit taken as N tends to infinity. The quantitative mean-field limit provides error bounds that vanish as N increases under this condition, which supports the relevance of the U-shaped profile for large but finite N such as 10^2 to 10^3. We will revise the abstract and add a discussion in the introduction on the finite-N implications to make the applicability clearer, without claiming validity outside the smallness regime. revision: partial
-
Referee: [Limiting correlation equation] Derivation of the limiting correlation equation (via adapted cumulant expansions): the quantitative error bounds rely on the smallness assumption being satisfied; the paper should supply a concrete test or counter-example showing whether the U-shape persists when the smallness parameter is only marginally satisfied, as this directly affects the claimed rigorous explanation.
Authors: We agree that understanding the behavior at the boundary of the smallness condition is important. However, the manuscript provides a rigorous explanation precisely when the smallness condition is satisfied, leading to the closed-form U-shape. When the parameter is only marginally satisfied, the error bounds in the mean-field limit may not be small, and the profile could deviate, but this is consistent with the statement of the result. As the work is a theoretical derivation using PDE and kinetic theory methods, we do not include numerical tests or counter-examples. We will add a remark clarifying that the U-shape is a feature of the limiting equation under the smallness assumption and that violations may lead to different behaviors, but the current analysis does not extend there. revision: partial
Circularity Check
No significant circularity: derivation proceeds from particle system to mean-field limit to closed-form PDE solution
full rationale
The paper defines a causal self-attention particle system, adapts cumulant expansions to its triangular structure, proves a quantitative mean-field limit, and then solves the resulting limiting correlation equation in closed form for iid uniform tokens under an explicit smallness condition. The U-shaped retrieval profile (primacy, recency, interior minimum) is obtained by direct solution of that PDE rather than by fitting, renaming, or self-referential definition. No load-bearing step reduces to a prior self-citation, fitted parameter, or ansatz smuggled from the authors' own work; the smallness condition is an explicit hypothesis required for both the limit and the closed form, not a hidden tautology. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tokens are iid and uniformly distributed on the vocabulary.
- ad hoc to paper The interaction strength satisfies an explicit smallness condition.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearVolterra–Hardy equation... ga(t,σ;σ0)=... I1(2√(at Y(σ;σ0)))... modified Bessel functions
Reference graph
Works this paper leans on
-
[1]
Antonio Álvarez-López, Borjan Geshkovski, and Domènec Ruiz-Balet. Perceptrons and localization of attention’s mean-field landscape. arXiv preprint arXiv:2601.21366 , 2026
work page internal anchor Pith review arXiv 2026
-
[2]
Bronstein, Petar Veličković, and Razvan Pascanu
Federico Barbero, Álvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael M. Bronstein, Petar Veličković, and Razvan Pascanu. Why do LLMs attend to the first token? InConference on Language Modeling , 2025
work page 2025
-
[3]
A duality method for mean-field limits with singular interactions
Didier Bresch, Mitia Duerinckx, and Pierre-Emmanuel Jabin. A duality method for mean-field limits with singular interactions. Preprint, arXiv:2402.04695
-
[4]
A new approach to the mean-field limit of Vlasov-Fokker- Planck equations
Didier Bresch, Pierre-Emmanuel Jabin, and Juan Soler. A new approach to the mean-field limit of Vlasov-Fokker- Planck equations. Anal. PDE, 18(4):1037–1064, 2025
work page 2025
-
[5]
Mean field limit and quantitative estimates with singular attractive kernels
Didier Bresch, Pierre-Emmanuel Jabin, and Zhenfu Wang. Mean field limit and quantitative estimates with singular attractive kernels. Duke Mathematical Journal , 172(13):2591 – 2641, 2023
work page 2023
-
[6]
Emergence of meta-stable clustering in mean-field transformer models
Giuseppe Bruno, Federico Pasqualotto, and Andrea Agazzi. Emergence of meta-stable clustering in mean-field transformer models. InThe Thirteenth International Conference on Learning Representations , 2025
work page 2025
-
[7]
A multiscale analysis of mean-field transformers in the moderate interaction regime
Giuseppe Bruno, Federico Pasqualotto, and Andrea Agazzi. A multiscale analysis of mean-field transformers in the moderate interaction regime. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025
work page 2025
-
[8]
A Unified Perspective on the Dynamics of Deep Transformers.arXiv preprint arXiv:2501.18322, 2025
Valérie Castin, Pierre Ablin, José Antonio Carrillo, and Gabriel Peyré. A unified perspective on the dynamics of deep transformers. arXiv preprint arXiv:2501.18322 , 2025
-
[9]
Quantitative Clustering in Mean-Field Transformer Models
Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Quantitative clustering in mean-field transformer models. arXiv preprint arXiv:2504.14697 , 2025. 2Views and opinions expressed are however those of the authors only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency. Neither the Eur...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Borun D Chowdhury. Lost in the middle at birth: An exact theory of transformer position bias.arXiv preprint arXiv:2603.10123, 2026
-
[11]
Bronstein, Yann LeCun, and Ravid Shwartz-Ziv
Enrique Queipo de Llano, Alvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael M. Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in LLMs are two sides of the same coin. InThe Fourteenth International Conference on Learning Representations , 2026
work page 2026
-
[12]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. InInternational conference on machine learning , pages 2793–2803. PMLR, 2021
work page 2021
-
[13]
Mitia Duerinckx. On the size of chaos via Glauber calculus in the classical mean-field dynamics.Communications in Mathematical Physics , 382(1):613–653, 2021
work page 2021
-
[14]
MitiaDuerinckxandPierre-EmmanuelJabin.CorrelationestimatesforBrownianparticleswithsingularinteractions. Preprint, arXiv:2510.01507
-
[15]
Clustering in Deep Stochastic Transformers.arXiv preprint arXiv:2601.21942, 2026
Lev Fedorov, Michaël E Sander, Romuald Elie, Pierre Marion, and Mathieu Laurière. Clustering in deep stochastic transformers. arXiv preprint arXiv:2601.21942 , 2026
-
[16]
Dynamic metastability in the self-attention model.arXiv preprint arXiv:2410.06833, 2024
Borjan Geshkovski, Hugo Koubbi, Yury Polyanskiy, and Philippe Rigollet. Dynamic metastability in the self- attention model. arXiv preprint arXiv:2410.06833 , 2024
-
[17]
Advances in Neural Information Processing Systems , 36:57026–57037, 2023
BorjanGeshkovski, CyrilLetrouit, YuryPolyanskiy, andPhilippeRigollet.Theemergenceofclustersinself-attention dynamics. Advances in Neural Information Processing Systems , 36:57026–57037, 2023
work page 2023
-
[18]
A mathematical perspective on trans- formers
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. A mathematical perspective on trans- formers. Bulletin of the American Mathematical Society , 62(3):427–479, 2025
work page 2025
-
[19]
Measure-to-measure inter- polation using transformers.arXiv preprint arXiv:2411.04551, 2024
Borjan Geshkovski, Philippe Rigollet, and Domènec Ruiz-Balet. Measure-to-measure interpolation using transform- ers. arXiv preprint arXiv:2411.04551 , 2024
-
[20]
On the dynamics of large particle systems in the mean field limit
François Golse. On the dynamics of large particle systems in the mean field limit. In Adrian Muntean, Jens Rademacher, and Antonios Zagaris, editors, Macroscopic and Large Scale Phenomena: Coarse Graining, Mean Field Limits and Ergodicity , pages 1–144. Springer International Publishing, Cham, 2016
work page 2016
-
[21]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[22]
A residual-aware theory of position bias in transformers
Hanna Herasimchyk, Robin Labryga, Tomislav Prusina, and Sören Laue. A residual-aware theory of position bias in transformers. arXiv preprint arXiv:2602.16837 , 2026
-
[23]
Higher-order propagation of chaos inL2 for interacting diffusions
Elias Hess-Childs and Keefer Rowan. Higher-order propagation of chaos inL2 for interacting diffusions. Probab. Math. Phys., 6(2):581–646, 2025
work page 2025
-
[24]
Found in the middle: Calibrating positional attention bias improves long context utilization
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and Tomas Pfister. Found in the middle: Calibrating positional attention bias improves long context utilization. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Comput...
work page 2024
-
[25]
Pierre-Emmanuel Jabin, David Poyato, and Juan Soler. Mean-field limit of non-exchangeable systems.Communi- cations on Pure and Applied Mathematics , 78(4):651–741, 2025
work page 2025
-
[26]
Mean field limit for stochastic particle systems
Pierre-Emmanuel Jabin and Zhenfu Wang. Mean field limit for stochastic particle systems. In Nicola Bellomo, Pierre Degond, and Eitan Tadmor, editors,Active Particles, Volume 1 : Advances in Theory, Models, and Applications , pages 379–402. Springer International Publishing, Cham, 2017
work page 2017
-
[27]
LongLLMLin- gua: Accelerating and enhancing LLMs in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLin- gua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Lon...
work page 2024
-
[28]
Nikita Karagodin, Yury Polyanskiy, and Philippe Rigollet. Clustering in causal attention masking.Advances in neural information processing systems , 37:115652–115681, 2024
work page 2024
-
[29]
Homogenized Transformers.arXiv preprint arXiv:2604.01978, 2026
Hugo Koubbi, Borjan Geshkovski, and Philippe Rigollet. Homogenized transformers. arXiv preprint arXiv:2604.01978, 2026
-
[30]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics , 12:157–173, 2024
work page 2024
-
[31]
Lorenzo Noci, Sotiris Anagnostidis, Luca Biggio, Antonio Orvieto, Sidak Pal Singh, and Aurelien Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse.Advances in Neural Information Processing Systems, 35:27198–27211, 2022
work page 2022
-
[32]
T. Paul, M. Pulvirenti, and S. Simonella. On the Size of Chaos in the Mean Field Dynamics.Arch. Ration. Mech. Anal., 231(1):285–317, 2019
work page 2019
-
[33]
Synchronization of mean-field models on the circle.arXiv preprint arXiv:2507.22857, 2025
Yury Polyanskiy, Philippe Rigollet, and Andrew Yao. Synchronization of mean-field models on the circle.arXiv preprint arXiv:2507.22857, 2025. 24 M. DUERINCKX, B. GESHKOVSKI, AND S. ROSSI
-
[34]
Train short, test long: Attention with linear biases enables input length extrapolation
Ofir Press, Noah Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In International Conference on Learning Representations , 2022
work page 2022
-
[35]
Global-in-time mean-field convergence for singular Riesz-type diffusive flows
Matthew Rosenzweig and Sylvia Serfaty. Global-in-time mean-field convergence for singular Riesz-type diffusive flows. The Annals of Applied Probability , 33(2):954 – 998, 2023
work page 2023
-
[36]
Mean field limit for Coulomb-type flows.Duke Mathematical Journal , 169(15):2887–2935, 2020
Sylvia Serfaty. Mean field limit for Coulomb-type flows.Duke Mathematical Journal , 169(15):2887–2935, 2020
work page 2020
-
[37]
Roformer: Enhanced transformer with rotary position embedding, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2024
work page 2024
-
[38]
Attention is all you need.Advances in Neural Information Processing Systems , 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems , 30, 2017
work page 2017
-
[39]
On the emergence of position bias in transformers
Xinyi Wu, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the emergence of position bias in transformers. In Forty-second International Conference on Machine Learning , 2025
work page 2025
-
[40]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations , 2024
work page 2024
-
[41]
Deepvit: Towards deeper vision transformer.arXiv preprint arXiv:2103.11886 , 2021
Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xiaochen Lian, Zihang Jiang, Qibin Hou, and Jiashi Feng. Deepvit: Towards deeper vision transformer.arXiv preprint arXiv:2103.11886 , 2021. Mitia Duerinckx Département de Mathémathiques Université Libre de Bruxelles Boulevard du Triomphe B-1050 Bruxelles, Belgium e-mail: mitia.duerinckx@ulb.be Borjan Ges...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.