Recognition: no theorem link
CATS: Curvature Aware Temporal Selection for efficient long video understanding
Pith reviewed 2026-05-12 03:02 UTC · model grok-4.3
The pith
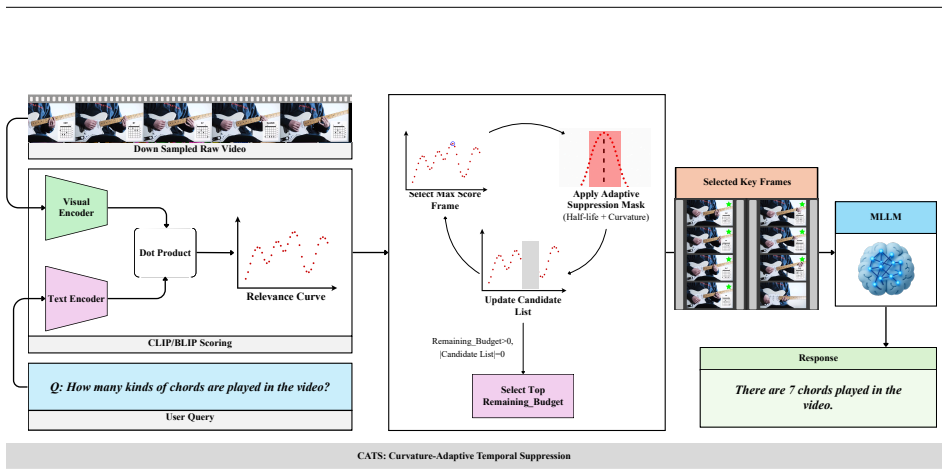
CATS selects long-video frames by tracking curvature in query-relevance scores over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CATS explicitly models the temporal geometry of query-frame relevance scores via curvature to adapt selection density, thereby capturing both abrupt transitions and gradually evolving content while suppressing redundant frames.
What carries the argument
Temporal curvature of the sequence of query-frame relevance scores, which determines local selection density.
If this is right
- Under a fixed backbone and frame budget, CATS outperforms prior lightweight approaches such as AKS on LongVideoBench and VideoMME.
- CATS retains 93-95% of MIRA's performance while using only 3-4% of its preprocessing cost.
- CATS yields more coherent and informative description outputs than baselines when evaluated by an LLM-as-a-judge protocol.
Where Pith is reading between the lines
- The same curvature signal could be applied to other time-ordered inputs such as audio streams or sensor logs.
- Lower preprocessing cost may make long-video analysis feasible on devices with limited compute.
- Curvature could be combined with motion or object cues to further refine selection without raising cost much.
Load-bearing premise
Curvature in relevance scores will reliably mark the locations of important events and needed context without systematically dropping critical information across different video types.
What would settle it
A video-query pair in which key facts sit inside a long low-curvature stretch that the method samples sparsely, producing a wrong answer.
Figures





read the original abstract
Understanding long videos with multimodal large language models (MLLMs) requires selecting a small subset of informative frames under strict computational budgets, where exhaustive processing is infeasible and optimal selection is combinatorial. We propose CATS, a curvature-aware frame selection method that explicitly models the temporal geometry of query-frame relevance to identify salient events and their surrounding context. By leveraging temporal curvature to adapt selection density, CATS captures both abrupt transitions and gradually evolving content while suppressing redundant frames. Under a fixed backbone and frame budget, CATS consistently outperforms prior lightweight approaches such as AKS on LongVideoBench and VideoMME. While multi-stage methods such as MIRA achieve higher absolute accuracy, they incur substantial computational overhead; in contrast, CATS retains approximately 93-95% of MIRA's performance while requiring only 3-4% of its preprocessing cost, yielding a favorable efficiency-accuracy trade-off. Beyond answer accuracy, we evaluate description generation using an LLM-as-a-judge protocol, and the obtained results show that CATS produces more coherent and informative outputs, indicating improved grounding in visual evidence. These results position CATS as a computationally efficient and principled approach to long-video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CATS, a curvature-aware temporal selection method for efficient long-video understanding with multimodal LLMs. It computes temporal curvature on query-frame relevance scores to adaptively select frames, capturing both abrupt transitions and gradually evolving content while suppressing redundancy. Under fixed backbone and frame budget, CATS is claimed to outperform lightweight baselines such as AKS on LongVideoBench and VideoMME, while retaining 93-95% of MIRA's accuracy at only 3-4% of its preprocessing cost. The work also reports improved description generation quality via an LLM-as-a-judge protocol.
Significance. If the central claims hold under rigorous verification, CATS would provide a lightweight, principled alternative for frame selection in long-video MLLM pipelines, improving the accuracy-efficiency frontier relative to both uniform/lightweight selectors and expensive multi-stage pipelines. The explicit use of temporal geometry (curvature) to handle diverse event dynamics is a potentially reusable idea for other temporal selection tasks.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): Performance numbers (outperformance over AKS, 93-95% retention of MIRA) are stated without implementation details, statistical tests, error bars, ablation studies on curvature threshold or relevance-score noise, or reproducibility information, so the central efficiency-accuracy claims cannot be verified from the manuscript.
- [§3] §3 (Method): The temporal curvature formulation (second derivative or discrete curvature of the 1D relevance curve) is described at a high level but lacks an explicit equation or pseudocode; without this, it is impossible to assess whether the selection rule systematically under-samples low-curvature gradual context or rare events, which is the weakest assumption underlying the reported gains.
- [§4.1, Table 1] §4.1 and Table 1: No ablation isolates the contribution of curvature-based density adaptation versus simpler heuristics (e.g., uniform sampling or first-derivative change detection), so it remains unclear whether the claimed superiority over AKS is load-bearing on the curvature signal or on other unstated design choices.
minor comments (2)
- [Abstract, §4.3] The abstract mentions 'LLM-as-a-judge protocol' for description generation but provides no details on the judge model, prompt, or inter-judge agreement; this should be expanded in §4.3.
- [§3] Notation for relevance scores and curvature is introduced without a clear table of symbols or consistent use across equations and text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity, verifiability, and experimental rigor. We address each major comment point by point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): Performance numbers (outperformance over AKS, 93-95% retention of MIRA) are stated without implementation details, statistical tests, error bars, ablation studies on curvature threshold or relevance-score noise, or reproducibility information, so the central efficiency-accuracy claims cannot be verified from the manuscript.
Authors: We agree that the current presentation of results limits independent verification. In the revised version, §4 will be expanded to include full implementation details (relevance score computation, curvature parameters, and frame selection procedure), error bars computed over multiple random seeds, statistical significance tests for key comparisons, and dedicated ablations on curvature threshold sensitivity and relevance-score noise. Reproducibility artifacts (hyperparameters, code pointers) will also be added. revision: yes
-
Referee: [§3] §3 (Method): The temporal curvature formulation (second derivative or discrete curvature of the 1D relevance curve) is described at a high level but lacks an explicit equation or pseudocode; without this, it is impossible to assess whether the selection rule systematically under-samples low-curvature gradual context or rare events, which is the weakest assumption underlying the reported gains.
Authors: We accept that an explicit formulation is required for rigorous assessment. The curvature is realized via a discrete approximation of the second derivative of the relevance curve, scaled by a normalization term to emphasize inflection points. The revised §3 will contain the precise equation together with pseudocode for the full selection pipeline, enabling direct evaluation of behavior on gradual versus abrupt content. revision: yes
-
Referee: [§4.1, Table 1] §4.1 and Table 1: No ablation isolates the contribution of curvature-based density adaptation versus simpler heuristics (e.g., uniform sampling or first-derivative change detection), so it remains unclear whether the claimed superiority over AKS is load-bearing on the curvature signal or on other unstated design choices.
Authors: We will add a targeted ablation study in the revised §4.1 that directly compares the full curvature-based selector against controlled variants using uniform sampling and first-derivative change detection, all under identical frame budgets and backbones. This will quantify the incremental benefit attributable to the second-order curvature signal versus simpler alternatives. revision: yes
Circularity Check
No significant circularity; CATS method and results are empirically grounded without self-referential reduction.
full rationale
The paper introduces CATS as a curvature-aware temporal selection method that models the temporal geometry of query-frame relevance scores to select frames under budget constraints. No equations, derivations, or first-principles results are shown that reduce the reported performance (outperformance of AKS, 93-95% retention of MIRA accuracy at 3-4% cost) to fitted parameters, self-definitions, or self-citation chains. The central claims rest on external benchmark evaluations (LongVideoBench, VideoMME) and efficiency measurements, which are independent of the method's construction. The approach is presented as a principled heuristic rather than a closed-form prediction derived from its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Wang, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos. arXiv preprint arXiv:2408.10188,
-
[3]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Yizhou Wang, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238,
work page internal anchor Pith review arXiv
-
[4]
Bo Fang, Wenhao Wu, Qiangqiang Wu, Yuxin Song, and Antoni B. Chan. Threading keyframe with narratives: Mllms as strong long video comprehenders.arXiv preprint arXiv:2505.24158, 2025a. URL https://arxiv.org/abs/2505.24158. H. Fang et al. Nar-kfc: Threading keyframes with narratives for long video comprehension, 2025b. Preprint. Chaoyou Fu et al. Videomme: ...
-
[6]
Presented at LLM4Eval Workshop (SIGIR 2024)
URLhttps://arxiv.org/abs/2407.13166. Presented at LLM4Eval Workshop (SIGIR 2024). Rui Li, Xiaohan Wang, Yuhui Zhang, Zeyu Wang, and Serena Yeung-Levy. Temporal preference optimization for long-form video understanding.arXiv preprint arXiv:2501.13919, 2025a. Z. Li et al. Preference-aware long video reasoning with supervised fine-tuning and direct preferenc...
-
[7]
Liu et al. Bolt: Efficient keyframe extraction via relevance distribution modeling.arXiv preprint, 2025a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
XiaoqianShen, YunyangXiong, ChangshengZhao, LemengWu, JunChen, ChenchenZhu, ZechunLiu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spatiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434,
-
[9]
Adaptive keyframe sampling for long video understanding.arXiv preprint arXiv:2502.21271, 2025a
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive keyframe sampling for long video understanding.arXiv preprint arXiv:2502.21271, 2025a. Z. Tang et al. Tspo: Temporal agent training via group relative policy optimization for long video reasoning, 2025b. Preprint. Wang et al. Videotree: Hierarchical keyframe search for lon...
-
[10]
Preprint. Y. Wang et al. Adaretake: Adaptive token compression for efficient long video understanding, 2025b. Preprint. Xinxin Wu et al. Longvideobench: A benchmark for long-form video understanding.arXiv preprint arXiv:2406.14514,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
J. Xu et al. Sf-llava: Semantic-free lunch for video large language models, 2024a. Preprint. Minghao Xu et al. Pllava: Parameter-efficient large language and vision assistant for video understanding. arXiv preprint arXiv:2404.02123, 2024b. Z. Xu et al. E-vrag: Hierarchical filtering and self-reflection for efficient long video comprehension,
-
[12]
Jinhui Ye, Zihan Wang, Haosen Sun, Keshigeyan Chandrasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, Jiajun Wu, and Manling Li. T*: Re-thinking temporal search for long-form video understanding.arXiv preprint arXiv:2504.02259, 2025a. URLhttps: //arxiv.org/abs/2504.02259. T. Ye et al. Multi-round tem...
- [13]
-
[14]
URL https://doi.org/10.1561/1500000081
doi: 10.1561/1500000081. URL https://doi.org/10.1561/1500000081. Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025...
-
[15]
Yifan Zhang, Chunyuan Li, Haotian Liu, et al
URLhttps://aclanthology.org/2025.findings-naacl.51/. Yifan Zhang, Chunyuan Li, Haotian Liu, et al. Llava-video: Large language-and-vision assistant for video understanding.arXiv preprint arXiv:2405.03715, 2024a. Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024b. URLhttps://a...
-
[16]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaohui Shen, et al. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Evaluate how additional visible elements from the same scene/domain (question topic or related topic) are included that could support future questions on the same topic. Score higher for: •More exhaustive coverage of other objects, steps, contextual elements, variations, or supporting details inside the exact same scene (even if not needed for the current...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.