Recognition: 2 theorem links
· Lean TheoremHow Much is Brain Data Worth for Machine Learning?
Pith reviewed 2026-05-12 03:57 UTC · model grok-4.3
The pith
Brain data can be exchanged for a quantifiable number of task samples in machine learning training, depending on alignment and noise levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a multimodal estimator trained on both brain data and task labels in a linear Gaussian model, performance follows scaling laws with sample numbers. Relative value and exchange rates between brain and task samples are derived as functions of task-brain alignment, neural and task noise, latent dimension, and brain sample size. Conditions for robustness gains under distribution shift are identified, along with regimes where brain data is worth collecting under a fixed budget.
What carries the argument
Linear Gaussian model of task targets and neural recordings, used to derive scaling laws and exchange rates for brain versus task samples.
If this is right
- Performance scales predictably with numbers of brain and task samples according to the derived laws.
- Brain data provides value equivalent to extra task samples, modulated by alignment and noise.
- Brain-regularized learning can improve robustness to test distribution shifts via learned invariances.
- Under fixed budget, there are specific regimes favoring collection of brain data over additional task labels.
Where Pith is reading between the lines
- These exchange rates could inform decisions on data collection strategies in NeuroAI experiments.
- Testing the predictions on real neural datasets would validate or refine the model assumptions.
- Similar value calculations might apply to other auxiliary data sources like eye tracking or physiological signals.
Load-bearing premise
The linear Gaussian abstraction of task targets and neural recordings is accurate enough that its exchange rates and robustness conditions will guide real-world use of brain data in machine learning.
What would settle it
Compare the actual performance gain from adding brain data in a controlled experiment to the gain predicted by the exchange rate formula for given alignment and noise levels; mismatch would falsify the practical applicability.
Figures


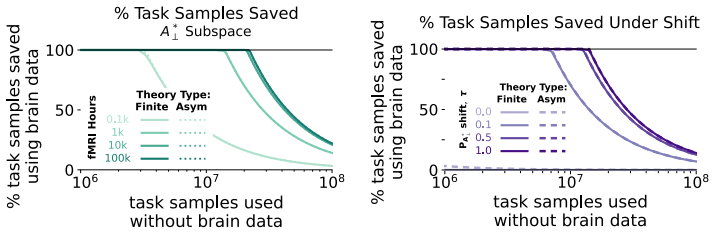




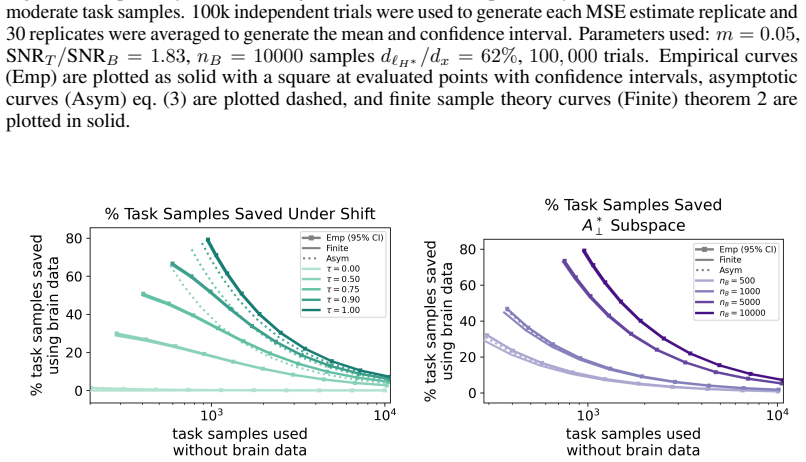

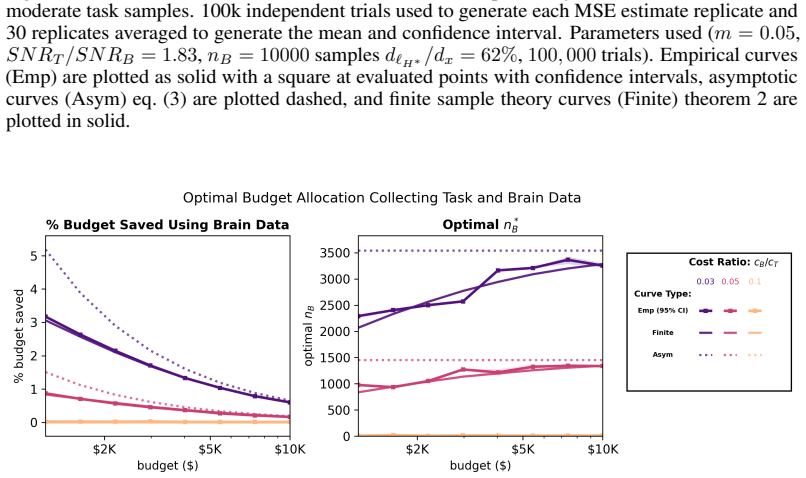
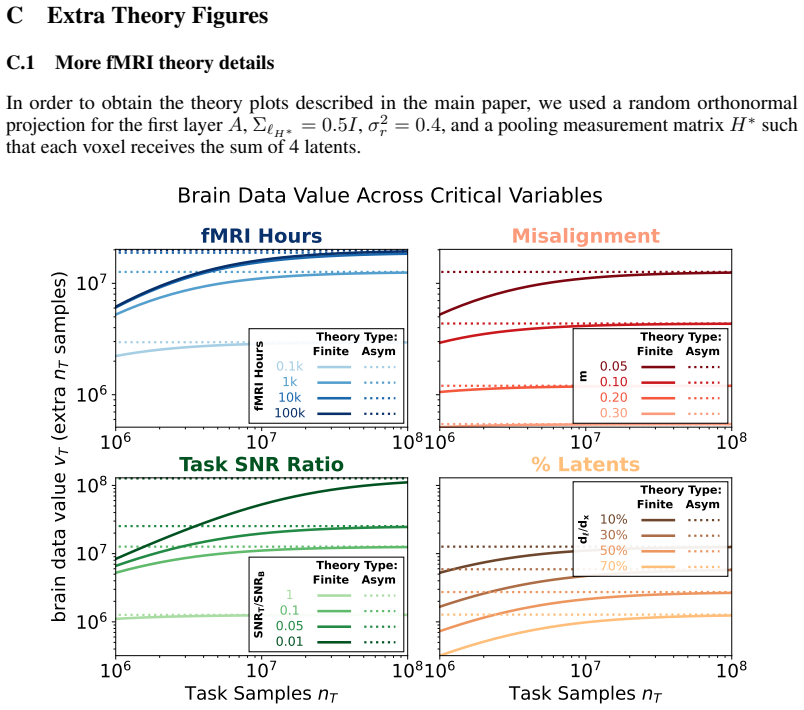
read the original abstract
If a person can solve a task, can measuring their brain make it easier to train a model to solve that task too? Recent NeuroAI work suggests that supplementing task training with neural recordings can modestly improve model performance and robustness. However, it is unclear when there should be a benefit from using neural data and how much benefit to expect. We formulate this question mathematically, and begin to address it theoretically using a simple, analytically tractable linear gaussian model of task targets and neural recordings. For a multimodal estimator trained on both brain data and task labels, we derive scaling laws for how performance scales with the numbers of brain and task samples. From these laws we derive relative value and exchange rates between brain samples and task samples, quantifying how much extra task samples neural data is worth as a function of task-brain alignment, neural and task noise, latent dimension, and brain data sample size. We also analyze test distribution shift, to identify conditions where brain-regularized learning can produce substantial robustness gains through learned invariances. Finally, under a fixed collection budget, we characterize the regimes in which brain data is worth collecting. Our results provide a foundation for understanding how valuable brain data could be for improving machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the utility of brain data for machine learning as a theoretical question and addresses it via an analytically tractable linear Gaussian model of task targets and neural recordings. For a multimodal estimator, it derives scaling laws for performance as a function of the numbers of brain and task samples; from these it obtains relative value and exchange rates between brain and task samples that depend on task-brain alignment, neural and task noise, latent dimension, and brain sample size. It further derives conditions under which brain-regularized learning yields robustness gains under test distribution shift and characterizes regimes in which brain data is worth collecting under a fixed budget.
Significance. If the derivations hold, the work supplies an explicit, parameter-dependent theoretical foundation for NeuroAI that quantifies sample trade-offs and robustness conditions inside a stated model. The analytic scaling laws and exchange-rate expressions constitute a strength, offering falsifiable predictions and guidance for experimental design once the linear-Gaussian abstraction is validated or relaxed.
major comments (2)
- [§3 (Model and Estimator)] §3 (Model and Estimator): the exchange-rate formula is derived under the assumption that alignment is an exogenous fixed parameter; if alignment itself improves with additional brain samples (a plausible empirical regime), the reported break-even points between brain and task data would shift, altering the budget-allocation conclusions in §6.
- [§5 (Distribution Shift)] §5 (Distribution Shift): the robustness gain is shown to arise from learned invariances only when the shift is confined to the task-latent subspace orthogonal to the brain-aligned directions; the paper should state explicitly whether this condition is necessary or merely sufficient, because the claim that brain data can produce “substantial robustness gains” rests on it.
minor comments (3)
- [Abstract] The abstract states that results are “derived … as a function of … brain data sample size,” yet the dependence on sample size appears only in the large-sample asymptotic regime; a brief remark on finite-sample corrections would improve clarity.
- [Notation] Notation for noise variances (σ_n², σ_t²) is introduced in §2 but reused without redefinition in the scaling-law appendices; a short notation table would prevent reader confusion.
- [Figure 3] Figure 3 caption should indicate whether the plotted curves are exact analytic expressions or numerical evaluations of the derived formulas.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. We address each major comment below and will incorporate clarifications to improve the manuscript.
read point-by-point responses
-
Referee: [§3 (Model and Estimator)] the exchange-rate formula is derived under the assumption that alignment is an exogenous fixed parameter; if alignment itself improves with additional brain samples (a plausible empirical regime), the reported break-even points between brain and task data would shift, altering the budget-allocation conclusions in §6.
Authors: We agree that the model treats alignment as a fixed exogenous parameter of the joint distribution. The exchange-rate derivations in §3 are conditional on this fixed alignment, and the break-even points in §6 follow directly from that assumption. If additional brain samples improved alignment (e.g., via better estimation of shared latents), the value of brain data would exceed the reported figures and could shift the budget-allocation recommendations. Extending the framework to dynamic, sample-dependent alignment would require a more complex model and is left for future work. In the revision we will add a paragraph in §3 and a brief note in §6 explicitly stating the fixed-alignment assumption and its implications for the conclusions. revision: partial
-
Referee: [§5 (Distribution Shift)] the robustness gain is shown to arise from learned invariances only when the shift is confined to the task-latent subspace orthogonal to the brain-aligned directions; the paper should state explicitly whether this condition is necessary or merely sufficient, because the claim that brain data can produce “substantial robustness gains” rests on it.
Authors: The referee correctly identifies that the robustness gains arise from invariances learned in the brain-aligned directions, which are effective only when the shift occurs in the orthogonal subspace. Within our linear-Gaussian model this condition is sufficient for the substantial robustness gains shown via the invariance mechanism. We do not claim it is necessary for robustness under all possible mechanisms or outside the model. We will revise §5 to state explicitly that the condition is sufficient for the reported gains and will qualify the scope of the claim to reflect the precise regime analyzed. revision: yes
Circularity Check
No significant circularity: derivations follow directly from stated linear Gaussian model
full rationale
The paper explicitly constructs a linear Gaussian model of task targets and neural recordings, treating alignment, noise levels, latent dimension, and sample sizes as free input parameters. Scaling laws for multimodal estimator performance, relative value/exchange rates between brain and task samples, and robustness conditions under distribution shift are then obtained by direct algebraic derivation from the model's joint distribution and estimator equations. No parameter is fitted to data and then re-used as a 'prediction'; no load-bearing step relies on self-citation; no ansatz is smuggled in; and no known empirical pattern is merely renamed. The central claims are therefore self-contained mathematical consequences of the model's assumptions rather than tautological restatements of inputs.
Axiom & Free-Parameter Ledger
free parameters (4)
- task-brain alignment
- neural noise variance
- task noise variance
- latent dimension
axioms (2)
- domain assumption Task targets and neural recordings are generated as noisy linear projections of the same latent variables.
- domain assumption The estimator is a multimodal linear Gaussian model trained on both data sources.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formulate this question mathematically... using a simple, analytically tractable linear gaussian model of task targets and neural recordings... derive scaling laws... exchange rate ρ... v_T = ρ·n_B... δ... misalignment m
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearBEFS estimator... ˆβ_BEFS = arg min 1/n_T ∥y−Xβ∥² + λ∥(I−P_Â)β∥²... generalized ridge... projection penalty
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Callie Federer, Haoyan Xu, Alona Fyshe, and Joel Zylberberg. Improved object recognition using neural networks trained to mimic the brain’s statistical properties.Neural Networks, 131:103–114, 2020
work page 2020
-
[3]
Zhe Li, Wieland Brendel, Edgar Walker, Erick Cobos, Taliah Muhammad, Jacob Reimer, Matthias Bethge, Fabian Sinz, Zachary Pitkow, and Andreas Tolias. Learning from brains how to regularize machines.Advances in neural information processing systems, 32, 2019
work page 2019
-
[4]
Using human brain activity to guide machine learning.Scientific reports, 8(1):5397, 2018
Ruth C Fong, Walter J Scheirer, and David D Cox. Using human brain activity to guide machine learning.Scientific reports, 8(1):5397, 2018
work page 2018
-
[5]
Zhe Li, Josue Ortega Caro, Evgenia Rusak, Wieland Brendel, Matthias Bethge, Fabio Anselmi, Ankit B Patel, Andreas S Tolias, and Xaq Pitkow. Robust deep learning object recognition models rely on low frequency information in natural images.PLOS Computational Biology, 19(3):e1010932, 2023
work page 2023
-
[6]
Spartan books Washington, DC, 1962
Frank Rosenblatt et al.Principles of neurodynamics: Perceptrons and the theory of brain mechanisms, volume 55. Spartan books Washington, DC, 1962. 10
work page 1962
-
[7]
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
work page 1982
-
[8]
Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biological cybernetics, 36(4):193–202, 1980
work page 1980
-
[9]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[10]
Samuel Schmidgall, Catherine Schuman, and Maryam Parsa. Biological connectomes as a representation for the architecture of artificial neural networks.arXiv preprint arXiv:2209.14406, 2022
-
[11]
Mariya Toneva and Leila Wehbe. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain).Advances in neural information processing systems, 32, 2019
work page 2019
-
[12]
Jonas Kubilius, Martin Schrimpf, Kohitij Kar, Rishi Rajalingham, Ha Hong, Najib Majaj, Elias Issa, Pouya Bashivan, Jonathan Prescott-Roy, Kailyn Schmidt, et al. Brain-like object recognition with high-performing shallow recurrent anns.Advances in neural information processing systems, 32, 2019
work page 2019
-
[13]
Yuchen Zhou, Emmy Liu, Graham Neubig, Michael J Tarr, and Leila Wehbe. Divergences between language models and human brains.Advances in neural information processing systems, 37:137999–138031, 2024
work page 2024
-
[14]
Omer Moussa, Dietrich Klakow, and Mariya Toneva. Improving semantic understanding in speech language models via brain-tuning.arXiv preprint arXiv:2410.09230, 2024
-
[15]
Nishitha Vattikonda, Aditya R Vaidya, Richard J Antonello, and Alexander G Huth. Brain- wavlm: Fine-tuning speech representations with brain responses to language.arXiv preprint arXiv:2502.08866, 2025
-
[16]
Maelle Freteault, Maximilien Le Clei, Loic Tetrel, Lune Bellec, and Nicolas Farrugia. Alignment of auditory artificial networks with massive individual fmri brain data leads to generalisable im- provements in brain encoding and downstream tasks.Imaging Neuroscience, 3:imag_a_00525, 2025
work page 2025
-
[17]
Patrick J. Mineault, Thomas L. Griffiths, and Sean Escola. Cognitive dark matter: Measuring what ai misses. 2026
work page 2026
-
[18]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Joel Ye, Jennifer Collinger, Leila Wehbe, and Robert Gaunt. Neural data transformer 2: multi- context pretraining for neural spiking activity.Advances in Neural Information Processing Systems, 36:80352–80374, 2023
work page 2023
-
[20]
Mehdi Azabou, Vinam Arora, Venkataramana Ganesh, Ximeng Mao, Santosh Nachimuthu, Michael Mendelson, Blake Richards, Matthew Perich, Guillaume Lajoie, and Eva Dyer. A unified, scalable framework for neural population decoding.Advances in Neural Information Processing Systems, 36:44937–44956, 2023
work page 2023
-
[21]
Scaling laws for decoding images from brain activity.arXiv preprint arXiv:2501.15322, 2025
Hubert Banville, Yohann Benchetrit, Stéphane d’Ascoli, Jérémy Rapin, and Jean-Rémi King. Scaling laws for decoding images from brain activity.arXiv preprint arXiv:2501.15322, 2025
-
[22]
Richard Antonello, Aditya Vaidya, and Alexander Huth. Scaling laws for language encoding models in fmri.Advances in Neural Information Processing Systems, 36:21895–21907, 2023
work page 2023
-
[23]
Scaling laws for generative mixed-modal language models
Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. Scaling laws for generative mixed-modal language models. InInternational Conference on Machine Learning, pages 265–279. PMLR, 2023. 11
work page 2023
-
[24]
Ridge regression: Biased estimation for nonorthogonal problems.Technometrics, 12(1):55–67, 1970
Arthur E Hoerl and Robert W Kennard. Ridge regression: Biased estimation for nonorthogonal problems.Technometrics, 12(1):55–67, 1970
work page 1970
-
[25]
Denny Wu and Ji Xu. On the optimal weighted ell-2 regularization in overparameterized linear regression.Advances in neural information processing systems, 33:10112–10123, 2020
work page 2020
-
[26]
Yanhao Jin, Krishnakumar Balasubramanian, and Debashis Paul. Meta-learning with generalized ridge regression: High-dimensional asymptotics, optimality and hyper-covariance estimation. arXiv preprint arXiv:2403.19720, 2024
-
[27]
Projection penalties: dimension reduction without loss
Yi Zhang and Jeff G Schneider. Projection penalties: dimension reduction without loss. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pages 1223–1230, 2010
work page 2010
-
[28]
Restricted ridge estimation.Statistics & probability letters, 65(1):57–64, 2003
Jürgen Groß. Restricted ridge estimation.Statistics & probability letters, 65(1):57–64, 2003
work page 2003
-
[29]
Alessandro T Gifford, Radoslaw M Cichy, Thomas Naselaris, and Kendrick Kay. A 7 t fmri dataset of synthetic images for out-of-distribution modeling of vision.Nature communications, 2026
work page 2026
-
[30]
Jacob S Prince, Ian Charest, Jan W Kurzawski, John A Pyles, Michael J Tarr, and Kendrick N Kay. Improving the accuracy of single-trial fmri response estimates using glmsingle.Elife, 11:e77599, 2022
work page 2022
-
[31]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page Pith review arXiv 2013
-
[32]
Meng Ding, Kaiyi Ji, Di Wang, and Jinhui Xu. Understanding forgetting in continual learning with linear regression.arXiv preprint arXiv:2405.17583, 2024
-
[33]
Rylan Schaeffer, Mikail Khona, Zachary Robertson, Akhilan Boopathy, Kateryna Pistunova, Ja- son W Rocks, Ila Rani Fiete, and Oluwasanmi Koyejo. Double descent demystified: Identifying, interpreting & ablating the sources of a deep learning puzzle.arXiv preprint arXiv:2303.14151, 2023
-
[34]
Neuroai for ai safety.arXiv preprint arXiv:2411.18526, 2024
Patrick Mineault, Niccolò Zanichelli, Joanne Zichen Peng, Anton Arkhipov, Eli Bingham, Julian Jara-Ettinger, Emily Mackevicius, Adam Marblestone, Marcelo Mattar, Andrew Payne, et al. Neuroai for ai safety.arXiv preprint arXiv:2411.18526, 2024
-
[35]
Sho Matsumoto. General moments of the inverse real wishart distribution and orthogonal weingarten functions.Journal of Theoretical Probability, 25(3):798–822, 2012
work page 2012
-
[36]
Moritz Jirak and Martin Wahl. Perturbation bounds for eigenspaces under a relative gap condition.Proceedings of the American Mathematical Society, 148(2):479–494, 2020. 12 Appendix A Code All code used to run simulations and generate the figures is provided at https://github.com/ LaneLewis/brain-distillation-theory. The codebase contains a readme with the...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.